@coder-pig
2018-04-02T03:54:07.000000Z
字数 6741
阅读 2652
小猪的Python学习之旅 —— 9.爬虫实战:爬取花瓣网的小姐姐
Python
引言:
关于爬小姐姐的脚本示例,在我的Gayhub仓库:ReptileSomething
里已经有好几个了,基本都是没什么技术含量的,直接解析HTML拿到
图片的URL,然后下载,特别开一篇写爬取花瓣网的小姐姐的实战教程,
是因为爬这个网站的时候会遇到好几个问题,第一感受到了反爬虫的套路,
(折腾了我将近2天):
- 1.图片是瀑布流布局,通过Ajax动态加载数据的
- 2.在处理图片详情页的时候才发现了图片链接规则,前面做
了很多无谓的操作; - 3.最后获得了图片的正确url,但是根本下载不下来,不知道
是做了防盗链还是什么?或者要登录之类的,浏览器打开也无法下载,
打开超链接是这样的内容,但是当你右键保存的时候发现并不能下载:
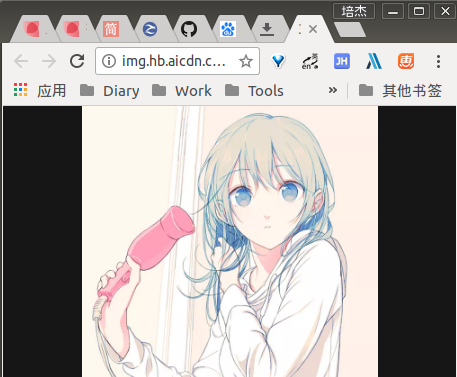

不信的话可以试试。
http://img.hb.aicdn.com/36b521f717741a4e3e024fd29606f61b8f960318f3763-WzUoLC_fw658
我觉得算是爬图片里稍微有点难度的站点了,强烈建议跟着我
一起回顾这个过程!
1.问题初现:瀑布流和Ajax动态加载数据
Chrome抓包的时候,抓到的数据和Elements的内容不一样,
js动态加载数据,前面已经见识过这种反爬虫的套路了,
有Selenium在手,根本不虚,模拟一波浏览器请求
加载下就能得到和Elements一样的内容了。
两个问题:瀑布流和Ajax动态加载数据。
怎么说?且听我一一道来:
没事喜欢练手的我意外发现了花瓣网,F12 Chrome抓一波包:
随手写个代码看看:
先Elements看下我们想扒的是什么:
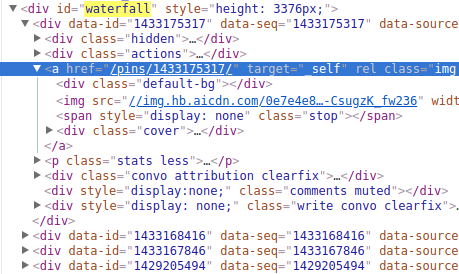
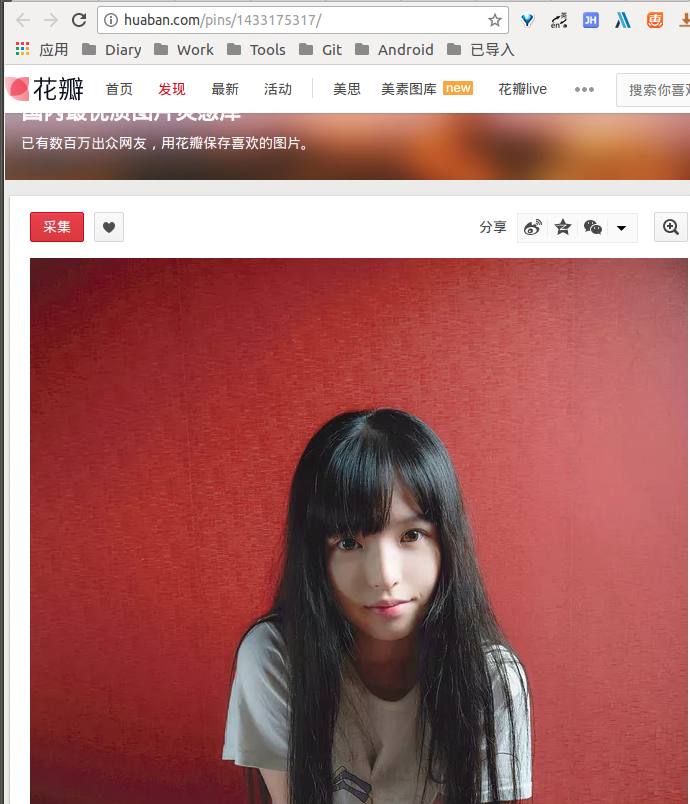
这里尽管有个img,但是明显是个小图,应该是要点开a那个
/pins/1433175317链接里才有大图,点开:
http://huaban.com/pins/1433175317/
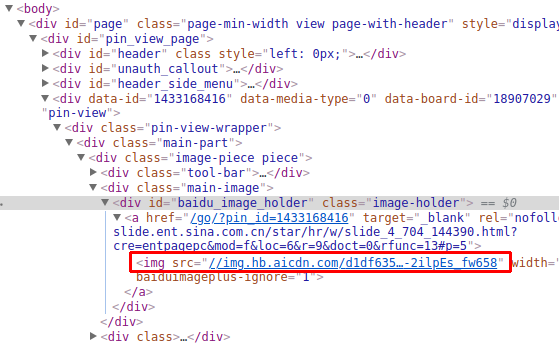
看下Elements,这个就是我们想要的图片url:
恩,一如既往的简单套路,搞到批量的列表url,然后下载图片。
看回我们的利用Selenium得到的网页代码,可以很稳。
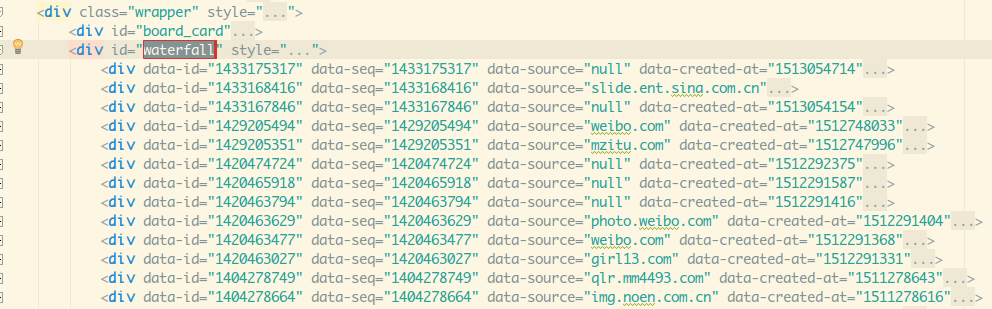
接下来的事情本该就水到渠成的了,然后这时候发生了一件
令人猝不及防的事情:

在网页那里滚到底部发现会加载更多的图片,越滚越多,但是
我们的Selenium只抓到了30个,咦,这种在之前抓某个网站
的时候就遇到过了,写个简单的滚动到底部的js,然后Selenium
循环执行这个脚本图片数/30次就好了,中途可以休眠1s给他加载,
执行完毕后,再去调用page_source得到最终的页面代码,然后走波
BeautifulSoup把我们1000多个小姐姐扒出来就好。

但是实际运行的结果却出乎我们的意料,最后得到的小姐姐列表
还是30个,卧槽,什么鬼,接着打开我们的浏览器,滚动的时候
发现,列表内容竟然是动态变化的,打开图片列表节点,滚动网
页,不禁又发出一句,卧槽,什么鬼,列表是动态变化的???
这些刚还不在的,突然就蹦出来了,就好像你刷着即刻刷着
刷着就蹦出一个x子。动态加载?想想野路子,要不我们自己
量化下滚动偏移量,比如滚动100,我们抓一波页面,存一下,
最后做下去重?这野路子不是一般的野:

单不说怎么量化这个偏移量了,浏览器宽度不一样时加载的
数目还不一定是30,然后那么多画板,你每个画板这样玩?
效率巨低。

苦苦寻觅后,发现了两个关键词:瀑布流和Ajax动态加载数据
2.解决问题
瀑布流:参差不齐的多栏布局以及到达底部自动加载的方式
Ajax动态加载数据:在不重新加载整个网页的情况下,对网页的某
部分进行更新
简单点说就是:
图片通过JS加载成瀑布流的形式,当到达底部后,会请求后台拿到更多
的数据,解析后通过Ajax,可以在不关闭不转跳不刷新浏览器的情况下
部分更新页面内容。
So,我们我们重新抓抓包,在滚动到底部的时候看下抓到的数据,
点击筛选XHR(XMLHttpRequest),这个是浏览器后台与服务之间
交换数据的文件,一般为json格式:

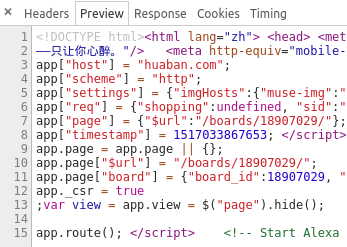
点开,右侧看看Headers,果然是json格式的:
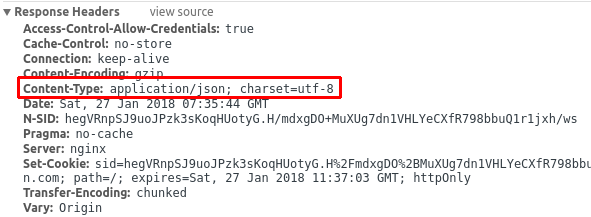
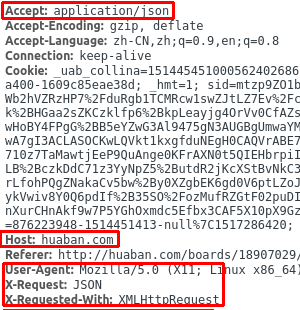
发现有这样的请求头,先放着,等下再研究规律:
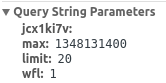
点开右侧Previews,发现了传回来的一大串Json,这里的
pins应该就是新增加的妹子图的相关数据了。

3.问题再现:猜测与试验,一步步解密规则
为了方便研究,我又滚动了几下,加载更多的数据,以方便
找出规律:

1.发起请求的规则

从上面我们可以得到一些这样的信息:
首先是Get请求,固定的基地址:http://huaban.com/boards/18907029/
这个18907029是画板id,后面的参数,jcx1ki7y和wfl=1应该是固定的,
limit这个是加载数量,一般是分页用的,就是一次加载20条新数据,
最后这个max:1348131400 暂时不知道是什么?不过应该是某个什么id
吧,看下第二个的max是1263961742,复制到第一个返回的json里搜搜:
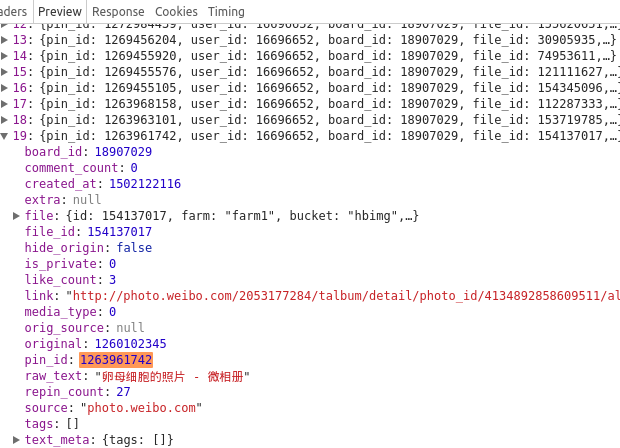
卧槽,刚好最后一个,不会那么巧吧?然后把第三个max:1247629077复制
到第二个的Json里看看:
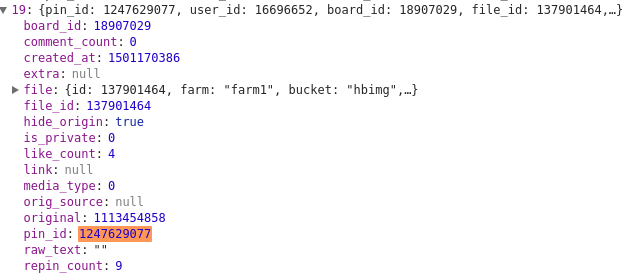
果然,好家伙,这个max就是每次拿到的最后一个图片的pin_id
知道规则了,模拟一波请求,解析一波json,每次拿到最后这个
pin_id,用作下次请求,当返回的pins里没东西,说明已经加载
完所有的了,来,写一波代码,先要处理刚进来时加载的列表,
得到最后的一个图的pin_id,然后才能开始执行上面那个拿
json的操作。
在我准备用Selenium模拟请求主页的时候,我发现了用urllib
模拟请求,里面就能拿到最后一个pin_id,只不过他是写在js里
的,我们可以通过正则表达式拿到我们想要的pin_id们:
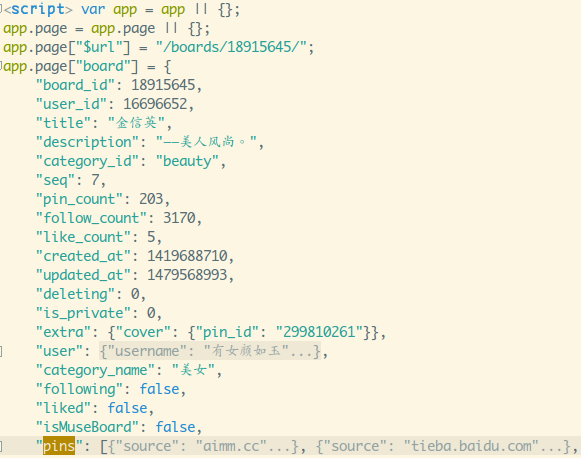
还有点开一个具体的大图页,发现他的url规则竟然是:
http://huaban.com/pins/926502853/
就是http://huaban.com/pins/ + pin_id,所以我们只要获得pin_id就可以了!
2.一步步写代码
规则清楚了,接下来一步步写代码来获取我们想要的数据吧!
1)首页数据的获取
进来的时候会加载一次,不是通过Ajax加载,默认是30个,需要处理
一波网页获得这个30个数据,然后30个数据的最后一个用于请求Ajax。
通过正则拿到pins这段json。
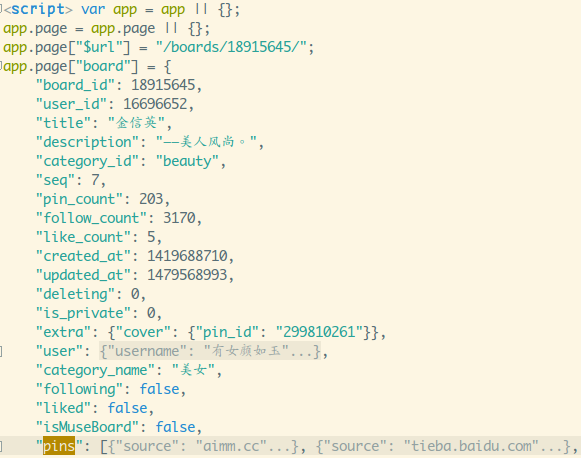
代码如下:


测试下代码:

打开网页加载更多确认下这个最后的pid是否正确:
可以正确,接着就来处理json数据了~
(这要注意正则匹配用的是search,我一开始没留意用的是match,
用一些真这个校验工具测试自己的正则一直是对的,但是丢程序
里缺一直不匹配,返回None,要注意!!!)
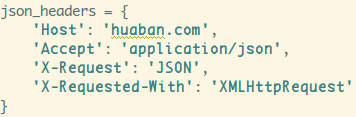
2)处理Ajax数据
首先是请求头的设置,和我们普通的请求不一样,如果你直接
用浏览器打开ajax加载数据的那个url发现返回的并不是json!!!
随手找个链接试试,就是解析json而已,

简单测试下:

运行结果:
可以,拿到数据了,接下来要优化下点东西,如果每次都要去拼接:
这串东西不就很麻烦了,可以通过正则来进行替换:

这里用到前面没有细讲的re.sub()替换方法和向前和向后界定
这两个东西什么时候用到,当前这个场景就能用到,比如我们想替换
pin_id,用一个括号括着想替换的部分,感觉应该就能替换了:

结果:

是的,前面一大段东西没了,如果你用了向前(?<=...)和向后界定(?=),
就可以让正则只匹配和替换这两个中间部分的字符串了~


好的,替换成功,小小整理一下代码:

好的,pin_id都能够拿到了,接下来通过这些想办法拿到图片啦,
点开一个图片的详情页,比如:
http://huaban.com/pins/1272982736/
查看页面结构,得到图片url:
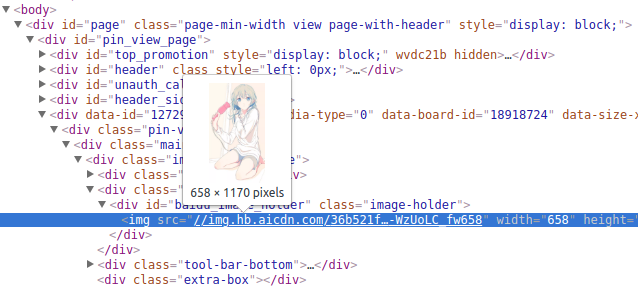
http://img.hb.aicdn.com/36b521f717741a4e3e024fd29606f61b8f960318f3763-WzUoLC_fw658
然后写个简单的模拟请求下这个网址,看下返回的数据有没有这个图片Url相匹配
的内容,全部搜没有,然后把后面的分成三段,一段段搜:
先搜:36b521f717741a4e3e024fd29606f61b8f960318f3763,秒找到,
有六处匹配的,这后面跟着-WzUoLC,就剩下最后的fw658,全局搜搜不到
难道是固定的?打开另一个详情页看看,果然,fw658是固定的:
http://img.hb.aicdn.com/7dc8cfc5e00f4cd78efba3f61c3b0b00f345a01a13b901-vaX0ho_fw658
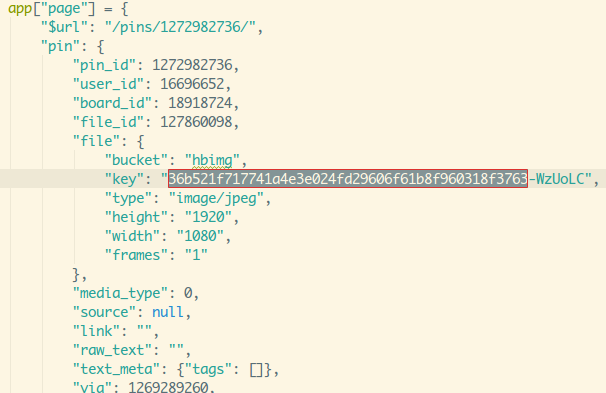
卧槽,key???前面拿json的数据就能拿到key,卧槽,该不会就
这样拼接就可以了吧,找到前面一个:


...令人无法接受,折腾了那么旧,原来拿到key就可以拼接得出图片url了

3.问题还现:我还是太naive了
啧啧,正确的图片url拿到了,浏览器打开也是没问题的,接着就是无脑
拼url,然后一个个下载了,正当我以为一切已经结束的时候,才发现了
最后的隐藏关卡:"图片并不能下载"???右键另存为保存直接失败,
py代码直接崩溃。

然后,在那个图片的详情页倒是可以下载,我的天,难不成要我每个
图片都用Selenium加载,然后处理页面数据,在这里下?
讲真,我是非常抗拒用Selenium的,慢不说,还耗内存,
代理也不怎么好设置,而且别人会说我low,百度谷歌搜了
一大堆,基本都是说了等于没说...正在我万念俱灰,想用回
Selenium这种Low比方式的时候,我萌生了一个想法:
会不会是需要登录后才能下载,于是乎我把链接发给我组
的UI,然后她默认浏览器竟然是ie,然后奇迹发现了,没有
登录,直接用ie浏览器打开了,然后他么的,可以右键保存
到本地?接着我又把链接发给我隔壁的后台小哥,同样用ie
打开,可以。此时熟悉的BGM响起:

真相:花瓣没有做ie系列浏览器的兼容
所以,模拟ie浏览器的User-Agent就可以下载图片了!!!
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)'
立马试试,当看到第一张图片下载到了我的仓库里的时候,
我就知道我猜对了:
剩下的就是组织一波代码,批量下载了~
4.完整代码
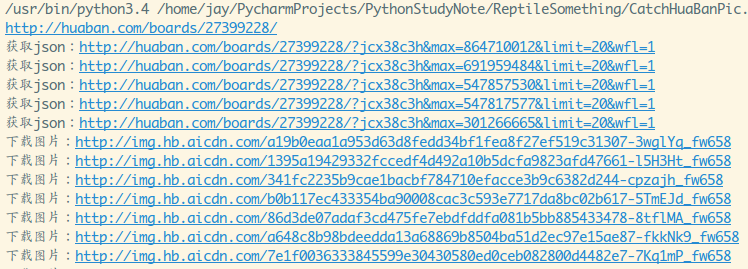
import urllib.requestimport urllib.errorimport reimport jsonimport coderpigimport os# 图片拼接url后,分别是前缀后缀img_start_url = 'http://img.hb.aicdn.com/'img_end = '_fw658'# 获取pins的正则boards_pattern = re.compile(r'pins":(.*)};')# 修改pin_id的正则max_pattern = re.compile(r'(?<=max=)\d*(?=&limit)')# 图片输出文件pin_ids_file = 'pin_ids.txt'# 图片输出路径pic_download_dir = 'output/Picture/HuaBan/'json_headers = {'Host': 'huaban.com','Accept': 'application/json','X-Request': 'JSON','X-Requested-With': 'XMLHttpRequest'}# 获得borads页数据,提取key列表写入到文件里,并返回最后一个pid用于后续查询def get_boards_index_data(url):print(url)proxy_ip = coderpig.get_proxy_ip()resp = coderpig.get_resp(url, proxy=proxy_ip).decode('utf-8')result = boards_pattern.search(resp)json_dict = json.loads(result.group(1))for item in json_dict:coderpig.write_str_data(item['file']['key'], pin_ids_file)# 返回最后一个pin_idpin_id = json_dict[-1]['pin_id']return pin_id# 模拟Ajax请求更多数据def get_json_list(url):proxy_ip = coderpig.get_proxy_ip()print("获取json:" + url)resp = coderpig.get_resp(url, headers=json_headers, proxy=proxy_ip).decode('utf-8')if resp is None:return Noneelse:json_dict = json.loads(resp)pins = json_dict['board']['pins']if len(pins) == 0:return Noneelse:for item in pins:coderpig.write_str_data(item['file']['key'], pin_ids_file)return pins[-1]['pin_id']# 下载图片的方法def download_pic(key):proxy_ip = coderpig.get_proxy_ip()coderpig.is_dir_existed(pic_download_dir)url = img_start_url + key + img_endresp = coderpig.get_resp(url, proxy=proxy_ip, ie_header=True)try:print("下载图片:" + url)pic_name = key + ".jpg"with open(pic_download_dir + pic_name, "wb+") as f:f.write(resp)except (OSError, urllib.error.HTTPError, urllib.error.URLError, Exception) as reason:print(str(reason))if __name__ == '__main__':coderpig.init_https()if os.path.exists(pin_ids_file):os.remove(pin_ids_file)# 一个画板链接,可自行替换boards_url = 'http://huaban.com/boards/27399228/'board_last_pin_id = get_boards_index_data(boards_url)board_json_url = boards_url + '?jcx38c3h&max=354569642&limit=20&wfl=1'while True:board_last_pin_id = get_json_list(max_pattern.sub(str(board_last_pin_id), board_json_url))if board_last_pin_id is None:breakpic_url_list = coderpig.load_data(pin_ids_file)for key in pic_url_list:download_pic(key)print("下载完成~")
输出结果:
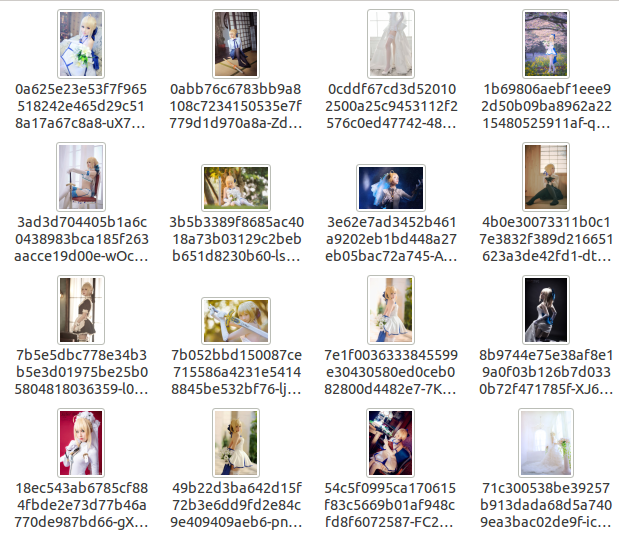
参见吾王~
5.小结:
磕磕碰碰,总算是把代码给撸出来了,成功又收获了一大波小姐姐,
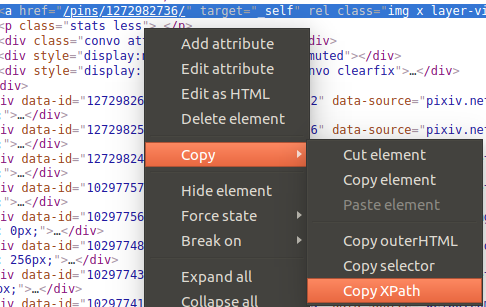
爬虫技能点+1,建议还是少用无脑Selenium吧,另外刚发现,
Chrome直接支持右键导出XPath,就不用自己慢慢扣了(如果你用lxml的话)。
好的,就说那么多~
====== 修正 ======
- 关于图片无法下载的问题,留言区 China卷柏 告知了原因:
请求头里的Referer,Chrome下载的时候自动填写为当前页面的URL
所以只需在请求头里设置Referer为空或者 http://huaban.com/
就可以了,实测可以,gayhub代码已更新,感谢~
阅读中遇到问题或者有写错的,欢迎提出一起讨论!
本节源码下载:
https://github.com/coder-pig/ReptileSomething
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

