@coder-pig
2018-08-18T02:32:01.000000Z
字数 10167
阅读 2326
小猪的Python学习之旅 —— 20.抓取Gank.io所有数据存储到MySQL中
Python
一句话概括本文:
内容较多,建议先mark后看,讲解了一波MySQL安装,基本操作,语法速成,DataGrip使用,
链接远程数据库问题,爬取Gank.io API接口,存储到数据,还有遇到的三个问题。

引言:
失踪人口回归,工种从开发变成了打杂后,供自己学习和写文章的时间也没以前充裕了,
大部分时间都在处理一些琐事,唉...在学习Python以后,要处理什么问题,我第一个想起
的都是它。比如前段时间在玩的微信小游戏 "萌犬变变变",前身是网页版的,只是最近迁移
到了小程序上。
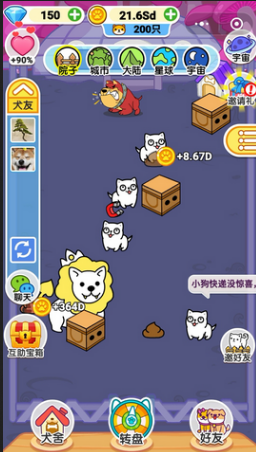
游戏大概玩法如下:
- 每隔一段时间,天上会掉下一个快递箱,用户需要用手点开;
- 点开后会有一只狗子,同样的狗子可以合并成一只更高级的狗子;
- 除了点箱子的方式手机狗,还可以直接在犬社用金币买狗合成;
- 一个星球里所有狗都集齐了,可以飞到下一个星球,继续合成不同的狗;
游戏的卖点:通过合成解锁各种各样有趣的狗子。
这样的小游戏看上去并不复杂,但是吸金数绝不可小觑,像我这种贫民玩家也
氪了30买月卡,然后排名5W开外:
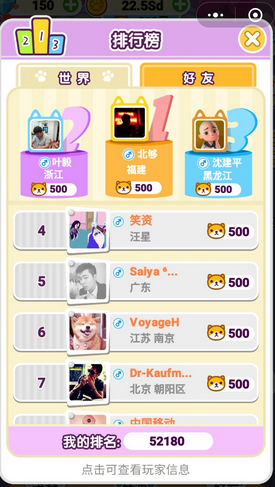
站在个人视角分析下这个游戏火的原因:
- 1.很多用户都有轻度的收集癖,会不遗余力地收集虚拟物品,以让自己获得更多
的满足感,数目越多,会觉得越刺激; - 2.诱导社交分享,通过游戏里轮盘抽奖,分享获得两倍收益的套路,以及各种分享
其他人点开能获得钻石,体力之类的套路;使得他在各种群聊扩散,还被微信禁止诱导分享过,
后来很快解封了,不知道是不是里面有什么py交易。 - 3.用户惰性,通过点快递箱子的方式获取狗子,后面升级科技满以后,每1s刷新一个箱子,
你觉得用户会一直点么?用户都是比较懒的,自动点箱子只需花30买,除了自动点还送钻石,
每天300钻石,这里又是一个套路,你需要登录才能领取,游戏又保证了用户日活。
绝大部分用户都会为这个便利买单,因为30真的不贵,殊不知掉入了更深的坑; - 4.如果你以为你花30买了个会员,挂着等狗子自动合成美滋滋,那你这是太naive了。我们
来算个数,比如合成2级的狗需要两只1级的狗,合成3级的狗需要4只1级的狗,算式就是2^(级别-1),
然后呢,每个星球有四个场景,每个场景有6种狗,最后的宇宙场景还要合成4次,计算下就是
通关一个星球你需要2^(6*4+4-1) = 2^27只一级狗,按照最快每1s生成一只狗的速度,你需要:
134217728秒=37282小时=1553天=4.25年,So,你会连续挂4年么?所以后面的合成基本都是靠
买狗,而且狗的价格不是恒定的,越买越贵,所以继续氪金吧,少年。 - 5.排行榜,刺激土豪用户虚荣心,数据库生成几个牛逼的账号霸榜,诱导前排玩家氪更多钱;
- 6.贫民玩家也不抛弃,通过轮盘或者各种任务可获得钻石,以此维持游戏日活。
以上就是个人的一些愚见,都差点忘记这个是个开发仔了,说回程序把,关于这个程序,
之前想到用Python做的两件事:
自动点箱子:
裁剪快递箱的顶部小角,通过adb命令每隔一秒截屏,利用opencv进行模板匹配,获取图片
中顶部小角的坐标数组,adb命令模拟点击;
轮盘自动点击:
先把轮盘的每种结果的执行流程都捋下,点哪里,跳那里,是否设置延时等,接着利用
adb截图,利用ocr图片识别关键字,比如'分享'自动关掉,'偷窃'点确定等。
因为觉得没什么意思,都不玩了,就没去整程序了,大概思路就是上面这样。
说这么多,只是想说明Python,真香。
嗯,扯得有点远了,前面的章节学爬虫,抓取到的数据存过txt,Excel和csv,
这三种对于非开发者来说挺友好的,对于开发仔来说,不存下数据库就说不过了。
数据库又分为两种:关系型数据库 和 非关系型数据库,
前者是基于关系模型的数据库,多个二维表通过表与表间的关联关系来组成一个数据库;
后者NoSQL是基于键值对的,数据间没有耦合性,非常高效;
本节使用的就是关系型数据库里的MySQL,相信很多童鞋都知道这个东东了,
编写一波gank.io的爬虫,爬取所有数据存起来,后续用Flask自己写接口玩玩~
1.MySQL安装
环境:阿里云服务器 Ubuntu 16.04
依次键入下述命令安装MySQL:
# 安装MySQL服务,输入Y后,如图会让你输入密码,重复输入确认sudo apt-get install mysql-server# 安装MySQL客户端sudo apt-get install mysql-client# 安装libmysqlclient,输入Ysudo apt-get install libmysqlclient-dev
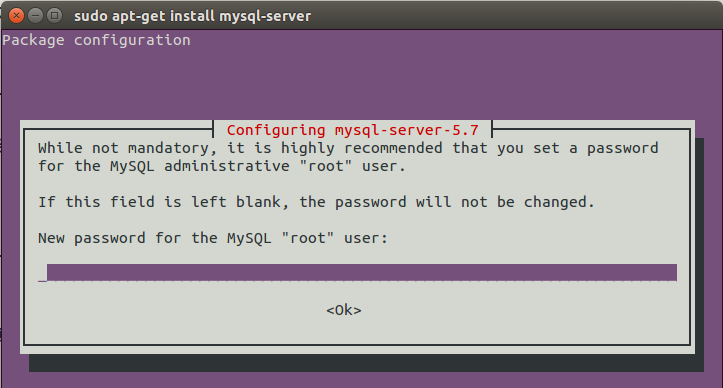
安装完后键入下述命令验证是否安装成功
sudo netstat -tap | grep mysql

2.MySQL基本操作
用户登录
# 回车后,需要输入在安装那里设置的密码mysql -u root -p
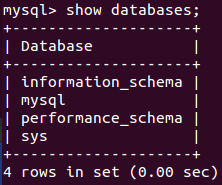
查看数据库
show databases;
选择数据库
use 数据库名

查看数据库里的所有表
show tables;
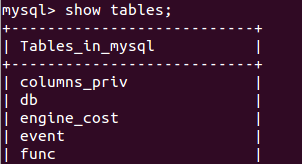
停止,开始和重启MySQL服务
# 开始服务/etc/init.d/mysql stop# 停止服务/etc/init.d/mysql start# 重启服务/etc/init.d/mysql restart
基本的操作就这些,对于数据库的相关操作,再进入数据库
后就可以通过数据库语句完成相关操作了。
3.MySQL数据库语法速成
MySQL数据类型
# 整型(取值范围如果加了unsigned,则最大值翻倍)TINYINT(m) 1个字节 范围(-128~127);SMALLINT(m) 2个字节 范围(-32768~32767);MEDIUMINT(m) 3个字节 范围(-8388608~8388607);INT(m) 4个字节 范围(-2147483648~2147483647);BIGINT(m) 8个字节 范围(+-9.22*10的18次方);# 浮点型FLOAT(m,d) 单精度浮点型 8位精度(4字节) m总个数,d小数位;DOUBLE(m,d) 双精度浮点型 16位精度(8字节) m总个数,d小数位;# 字符串# 1.char(n)若存入字符小于n,以空格补齐后面,查询时再将空格去掉,所以char类型存储# 的字符串末尾不能有空格。# 2.char(n)固定长度,不管存几个字符,都占用n个字节# 3.varchar(n)可变长度,存入的实际字符数+1个字节(n<=255)或2个字节(n>255)# 4.char类型的字符串检索速度要比varchar类型的快# 5.text类型不能有默认值,varchar查询速度快于textCHAR(n) 固定长度,最多255个字符;VARCHAR(n) 可变长度,最多65535个字符;TINYTEXT 可变长度,最多255个字符;TEXT 可变长度,最多65535个字符;MEDIUMTEXT 可变长度,最多2的24次方-1个字符;LONGTEXT 可变长度,最多2的32次方-1个字符;# 二进制数据_BLOB 以二进制方式存储,不分大小写,不用指定字符集,只能整体读出;_TEXT 以文本方式存储,英文存储区分大小写,可以指定字符集;# 日期时间类型DATE 日期TIME 时间DATETIME 日期时间TIMESTAMP 自动存储记录修改时间
数据类型的属性
NULL 数据列可包含NULL值NOT NULL 数据列不允许包含NULL值DEFAULT 默认值PRIMARY KEY 主键AUTO_INCREMENT 自动递增,适用于整数类型UNSIGNED 无符号CHARACTER SET name 指定一个字符集
库操作相关
# 建库CREATE DATABASE 数据库名;# 删库(删除数据库无法恢复!!!),删除不存在的库会报# database doesn't exist的错误,故先用IF EXISTS判断下。DROP DATABASE IF EXISTS 数据库名;
表操作相关
# 建表,比如CREATE TABLE test(_id VARCHAR(50) NOT NULL PRIMARY KEY,dsec TEXT NULL,images TEXT NULL,url TEXT NULL,type VARCHAR(50) DEFAULT '' NULL);# 清空表数据,整体删除,速度较快,会重置Identity(标识列、自增字段)TRUNCATE 表名# 删除表中数据,逐条删除,速度较慢,不会重置Identity,配合WHERE关键字可以删除部分DELETE FROM 表名# 删表DROP TABLE 表名# 重命名表ALTER TABLE 原表名 RENAME 新表名;RENAME TABLE 原表名 TO 新表名;# 增加列ALTER TABLE 表名 Add column 新字段 数据类型 AFTER 在哪个字段后添加# 删除列ALTER TABLE 表名 DROP 字段名;# 重命名列/数据类型ALTER TABLE 表名 CHANGE 原列名 新列名 数据类型;# 增加主键ALTER TABLE 表名 ADD PRIMARY KEY (主键名);# 删除主键ALTER TABLE 表名 DROP PRIMARY KEY;# 添加唯一索引ALTER TABLE 表名 ADD UNIQUE 索引名 (列名);# 添加普通索引ALTER TABLE 表名 ADD INDEX 索引名 (列名);# 删除索引ALTER TABLE 表名 DROP INDEX 索引名;# 把表默认的字符集和所有字符列(CHAR, VARCHAR, TEXT)改为新的字符集:ALTER TABLE 表名 CONVERT TO CHARACTER SET utf8;# 修改表某一列的编码ALTER TABLE 表名 CHANGE 列名 varchar(255) CHARACTER SET utf8;# 仅仅改变一个表的默认字符集ALTER TABLE 表名 DEFAULT CHARACTER SET utf8;
增删改查(INSERT,DELETE,UPDATE,SELECT)
关键词就上面几个,通过一个完整示例来快速上手MySQL
# 建新数据库CREATE DATABASE test# 新建一个表person,字段有(自增id,名字,年龄,性别)CREATE TABLE person(id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(30) NOT NULL DEFAULT '',age INT,sex CHAR(2));# 往表中插入5条数据INSERT INTO person (name, age, sex) VALUES ('小明', 8, '男');INSERT INTO person (name, age, sex) VALUES ('小红', 14, '女');INSERT INTO person (name, age, sex) VALUES ('小白', 4, '男');INSERT INTO person (name, age, sex) VALUES ('小宝', 6, '男');INSERT INTO person (name, age, sex) VALUES ('小莉', 16, '女');# 更新表中数据(不添加WHERE子句筛选,更新的会是整个表的某列)UPDATE person SET age = 10, sex = '女' WHERE name = '小明';# 往表里插入数据,如果某自动已存在则更新数据INSERT INTO person (id,name, age, sex) VALUES (1,'小明', 20, '男') ON DUPLICATE KEY UPDATE age = '20';# 删除特定记录DELETE FROM person WHERE age < 10;# 查询数据SELECT * FROM person; #查询所有数据SELECT name,age FROM person; #查询特定列SELECT name AS '姓名',age AS '年龄'FROM person; #为检索出来的列设置别名SELECT name FROM person WHERE age > 15 AND age <=20; # 条件查询SELECT name FROM person WHERE age BETWEEN 15 AND 20; # 范围查询# 数据求总和,平均值,最大,最小值,记录数SELECT SUM(age),AVG(age), MAX(age),MIN(age), COUNT(age) FROM person;# 查询的时候排序:升序(ASC),降序(DESC)SELECT * FROM person ORDER BY age ASC;
事务
BEGIN # 开始一个事务COMMIT # 事务确认ROLLBACK # 事务回滚
关于MySQL的基本语法就到这里,本节够用了,其他的后续用到再讲~
4.数据库图形化工具——DataGrip
一般来讲数据库操作很少写命令,基本都会依赖一些图形化工具来提高效率,
关于MySQL的图形化工具,网上貌似挺多的,大部分用的貌似是Navicat for mysql
(我司后台用的就是这个),不过我还是选择了idea全家桶里的DataGrip,没有为什么...
建立数据库关联
依次点击 New -> DataSource -> MySQL
如图依次配置下Host,Database,User,Password,然后Test Connection测试是否
连接成功,成功的话点击Ok**粗体文本**。

本地是这样,如果你的数据库不在本机而是在云服务器上,就要另外折腾了。
设置mysql允许远程访问
mysql默认是不允许远程访问的,笔者用的是阿里云的服务器,在连接远程仓库
的时候也遇到一些问题,顺带记录下,方便后来者。(下述操作发生在服务器上已经安装了mysql环境后!)
Step 1:云服务器开启安全组里的3306端口
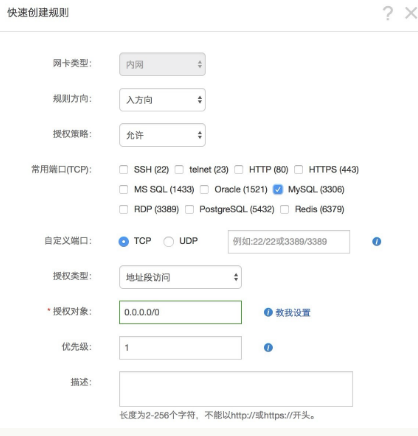
Step 2:停止mysql服务
/etc/init.d/mysql stop
Step 3:修改my.cnf文件,注释掉bind-address = 127.0.0.1,键入sq保存退出;
vim /etc/mysql/my.cnf
Step 4:启动mysql服务
/etc/init.d/mysql start
Step 5:输入下述命令查看当前3306端口的状态
netstat -an|grep 3306

Step 6:修改访问权限
mysql -u root -p # 用户登录use mysql; # 选中mysql数据库GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION; # 授权FLUSH PRIVILEGES; # 更新权限EXIT # 退出mysql
PS:上面设置的结果是所有ip都能访问数据库,如需指定特定ip才能访问的话,
可以把'@'%改成特定ip。还有这里用的是root账户,你可以通过下述命令
创建一个新的用户,然后用这个用户进行访问,可以由此做一些权限控制操作。
CREATE USER 新用户 IDENTIFIED BY '密码';GRANT ALL PRIVILEGES ON *.* TO '新用户'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION; # 授权FLUSH PRIVILEGES;
Step 7:连接远程mysql
这里用的是DataGrip进行连接,右键,new -> Data Source -> MySQL
这里要先配置SSH或者SSL,端口默认是22

再接着配置远程数据库相关,端口3306

配置完后点击Test Connection成功后,点击OK即可。

中途如果出现了异常,比如SSH Auth ERROR可能就是SSH密码错误;
除此之外的MySQL异常或问题可自行查阅:
云服务器 ECS Linux MySQL 无法远程连接问题常见错误及解决办法
5.编写爬虫程序
准备得差不多了,接着来编写爬虫程序了,因为代码家已经提供了
API接口,这里就不一个个网页爬取了,直接抓接口。
分析下接口:
有六种不同类型的数据:Android, iOS, 休息视频, 福利, 拓展资源, 前端, 瞎推荐, App
然后每个接口取五个需要的字段:_id, dsec, images, url, type
所以要做的第一件事:循环建表

接着定义一个Gank类
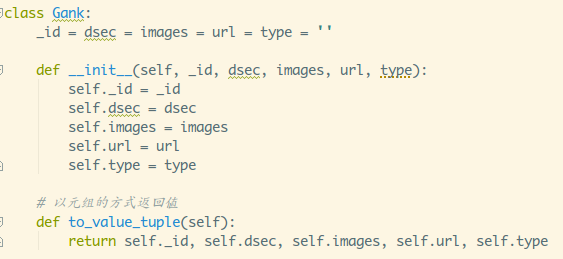
再接着定义一个网数据库里插入数据的函数(参数是一个gank对象列表):
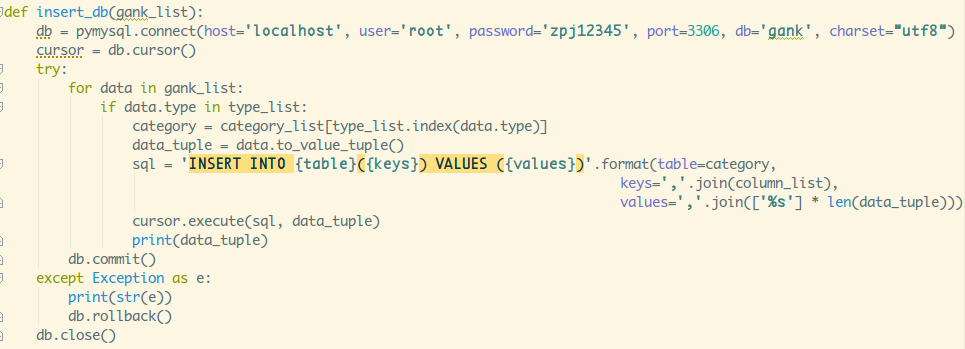
再定义一个爬取接口数据的方法
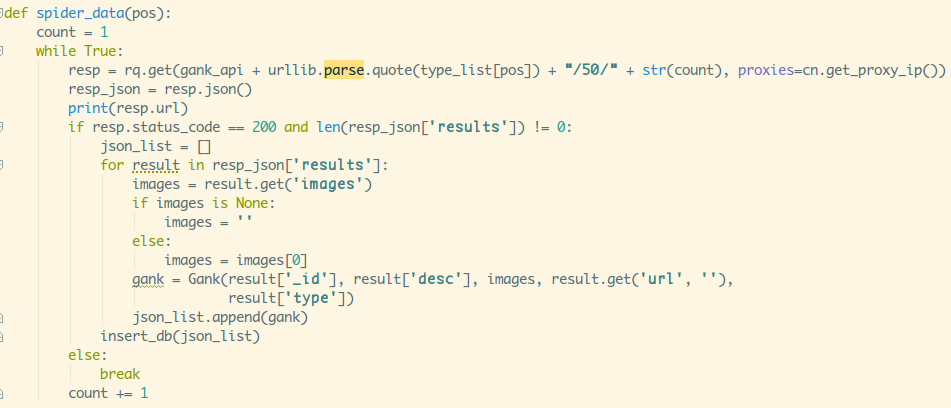
接着main函数调用下,
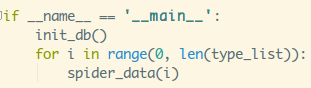
运行等待程序抓取完成,完成后可以直接代码查询:


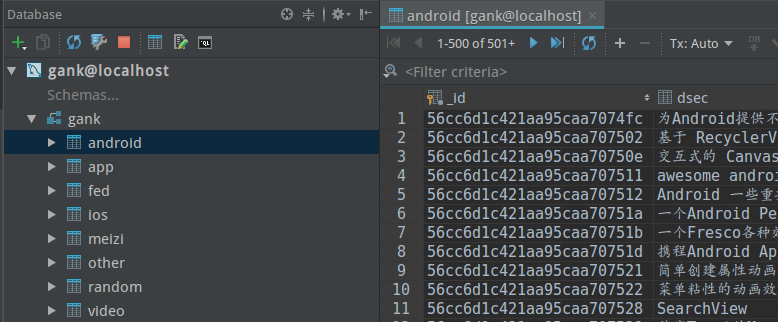
或者直接通过DataGrip查看:
6.遇到的三个问题
字段长度不够
接口返回的数据里有些字段比如标题和URL巨长,一开始用了varchar(250)的,
报错提示某列什么错误,后来就全改成TEXT了。
特殊符号和表情问题
因为有些标题里包含特殊符号和表情,在插入数据的时候报错,大概是这样的:
Incorrect string value: '\xF0\x9F...' for column 'XXX' at row 1
原因是:UTF-8编码有可能是两个、三个、四个字节。Emoji表情或者某些特殊字符是4个字节,
而Mysql的utf8编码最多3个字节,所以数据插不进去。MySQL在5.5.3版本之后增加了
utf8mb4的编码,专门用来兼容四字节的unicode。理论上将字符集修改为utf8mb4
不会对已有的utf8编码读取产生任何问题。官方解释:
10.9.1 The utf8mb4 Character Set (4-Byte UTF-8 Unicode Encoding)
解决过程:
Step 1:打开终端,键入:locale my.cnf 定位到文件位置(window下是my.ini):

Step 2:vim etc/mysql/my.cnf 追加下述内容,wq保存:
[mysqld]character-set-server=utf8mb4[client]default-character-set=utf8mb4[mysql]default-character-set=utf8mb4
Step 3:重启MySQL服务器
Step 4:进入mysql,然后键入show variables like '%character%';确认设置是否生效

Step 5:更改数据库,表,列编码
ALTER DATABASE 数据库名 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;ALTER TABLE 表名 CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;ALTER TABLE 表名 CHANGE 列名 VARCHAR(191) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
到此问题就解决了,此时打开数据库表可以看到对应记录已存入,不过是显示成问号
的形式,读取到数据显示到支持emoji表情的页面上就可以了,比如手机。
DataGrip只能存500条记录?
打开一个表看到里面的数据只有500条,试了几次还是这样,以为DataGrip只能存储500条数据,
后来发现这里有个501+,分页,so,点击右面那个类似于播放的按钮就可以切换区间了!
小结
开头扯了一下犊子,接着详细讲解了一波MySQL相关的东西,接着写了一波简单爬虫
爬取gank.io,存储数据的方式又新增了数据库一种~

参考文献:
附:最终代码(都可以在:https://github.com/coder-pig/ReptileSomething 找到):

# 抓取Gank.io所有文章的爬虫import pymysqlimport requests as rqimport urllibimport coderpig_n as cngank_api = "http://gank.io/api/data/"# 各种分类的表名:Android,iOS,休息视频,福利,拓展资源,前端,瞎推荐,Appcategory_list = ["android", "ios", "video", "meizi", "other", "fed", "random", "app"]type_list = ["Android", "iOS", "休息视频", "福利", "拓展资源", "前端", "瞎推荐", "App"]column_list = ('_id', 'dsec', 'images', 'url', 'type')def init_db():db = pymysql.connect(host='localhost', user='root', password='zpj12345', port=3306, db='gank', charset="utf8")cursor = db.cursor()try:for category in category_list:sql = "CREATE TABLE IF NOT EXISTS %s (" \"_id VARCHAR(50) NOT NULL," \"dsec TEXT," \"images TEXT," \"url TEXT," \"type VARCHAR(50) DEFAULT ''," \"PRIMARY KEY (_id))" % categorycursor.execute(sql)db.close()except:passclass Gank:_id = dsec = images = url = type = ''def __init__(self, _id, dsec, images, url, type):self._id = _idself.dsec = dsecself.images = imagesself.url = urlself.type = type# 以元组的方式返回值def to_value_tuple(self):return self._id, self.dsec, self.images, self.url, self.typedef insert_db(gank_list):db = pymysql.connect(host='localhost', user='root', password='zpj12345', port=3306, db='gank', charset="utf8")cursor = db.cursor()try:for data in gank_list:if data.type in type_list:category = category_list[type_list.index(data.type)]data_tuple = data.to_value_tuple()sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=category,keys=','.join(column_list),values=','.join(['%s'] * len(data_tuple)))cursor.execute(sql, data_tuple)print(data_tuple)db.commit()except Exception as e:print(str(e))db.rollback()db.close()def spider_data(pos):count = 1while True:resp = rq.get(gank_api + urllib.parse.quote(type_list[pos]) + "/50/" + str(count), proxies=cn.get_proxy_ip())resp_json = resp.json()print(resp.url)if resp.status_code == 200 and len(resp_json['results']) != 0:json_list = []for result in resp_json['results']:images = result.get('images')if images is None:images = ''else:images = images[0]gank = Gank(result['_id'], result['desc'], images, result.get('url', ''),result['type'])json_list.append(gank)insert_db(json_list)else:breakcount += 1if __name__ == '__main__':init_db()for i in range(0, len(type_list)):spider_data(i)db = pymysql.connect(host='localhost', user='root', password='zpj12345', port=3306, db='gank', charset="utf8")cursor = db.cursor()cursor.execute('SELECT * FROM android')print(cursor.rowcount)results = cursor.fetchall()for result in results:print(result)cursor.close()
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。
