@coder-pig
2019-01-24T04:28:17.000000Z
字数 21567
阅读 3084
偷个懒,公号抠腚早报80%自动化——2.手撕新闻爬虫
2019
简述
在上一节《偷个懒,公号抠腚早报80%自动化——1.批量生成微信封面图》中,我们利用opencv库
与PIL库生成半年分量的微信封面图,每次发布直接选图,美滋滋。按照剧本,本节我们的目标是:
编写爬虫定时去爬取新闻,保存到本地数据库中
具体点:
- 1.编写爬取新闻站点的爬虫;
- 2.把爬取到的新闻保存到数据库中;
- 3.脚本定时执行,每天早上8点清空前一天的数据,再去爬取新闻;
说到爬虫,不得不提「爬虫五步曲」:明确爬取目标,分析请求,模拟请求,解析数据,保存数据。
本节以「澎湃新闻和爬取各类日报微博」为例讲解,其他的站点也是大同小异,有兴趣的读者自行扩展。

不多哔哔,直接开始本节内容。

1.爬取澎湃新闻
0x1 明确爬取目标
爬取站点:澎湃新闻:https://www.thepaper.cn/,网页界面如下:
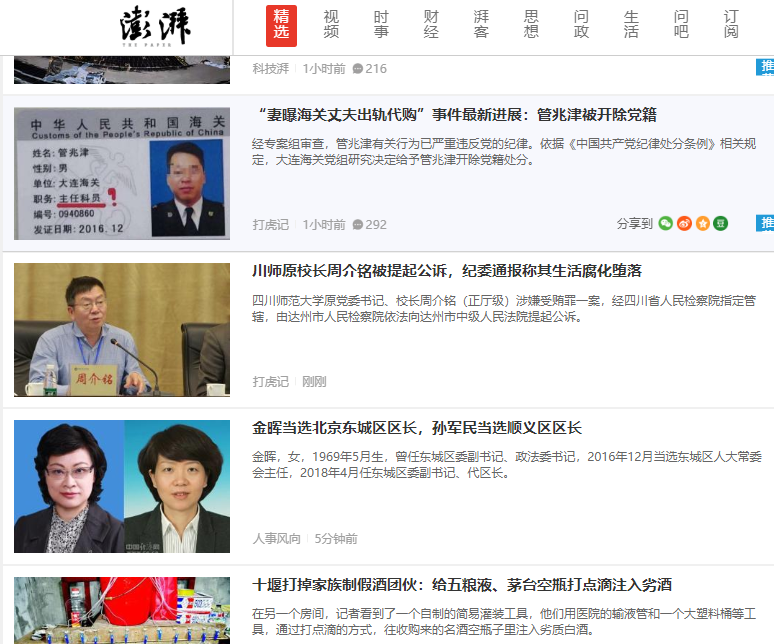
确定爬取目标:爬取首页精选里的新闻,采集新闻标题,概述,链接,来源等到数据库中。
0x2 分析请求
首页,滚动到底部,会加载更多,猜测是Ajax动态加载,F12打开开发者工具,过滤XHR选项,
抓一波包,选项卡中出现一个请求:
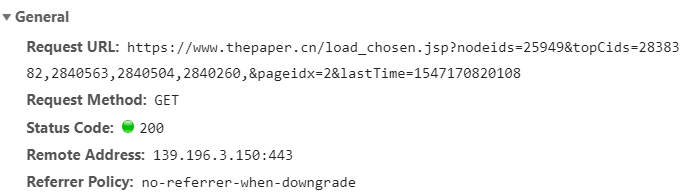
切换到Response选项卡,看下请求的响应数据:

行吧,XML类型的数据,接着开始分析URL的规则,滚动到底部几次,采集下请求的URL:
https://www.thepaper.cn/load_chosen.jsp?nodeids=25949&topCids=2838382,2840563,2840504,2840260,&pageidx=2&lastTime=1547170820108https://www.thepaper.cn/load_chosen.jsp?nodeids=25949&topCids=2838382,2840563,2840504,2840260,&pageidx=3&lastTime=1547170216130https://www.thepaper.cn/load_chosen.jsp?nodeids=25949&topCids=2838382,2840563,2840504,2840260,&pageidx=4&lastTime=1547166699225
不难看出,https://www.thepaper.cn/load_chosen.jsp 是 Ajax接口的基地址;pageidx是页码;lastTime是
时间戳;至于中间的中间这段:nodeids=25949&topCids=2838382,2840563,2840504,2840260,&pageidx=2,
可能需要我们猜测一下。nodeids猜测是分类id?首页瞎点一下其他的分类,发现有两类链接:
https://www.thepaper.cn/channel_26916https://www.thepaper.cn/list_26912
em...也是五位的数字,分别替换25949成试试?果然,channel_25949显示的内容和精选的内容一致。
而在这个页面滚动到底部同样会加载更多,Ajax的请求URL为:
https://www.thepaper.cn/load_index.jsp?nodeids=&topCids=&pageidx=2&lastTime=1547175167792
So,nodeids=25949就是固定的咯,然后是topCids=2838382,2840563,2840504,2840260,回到精选页:
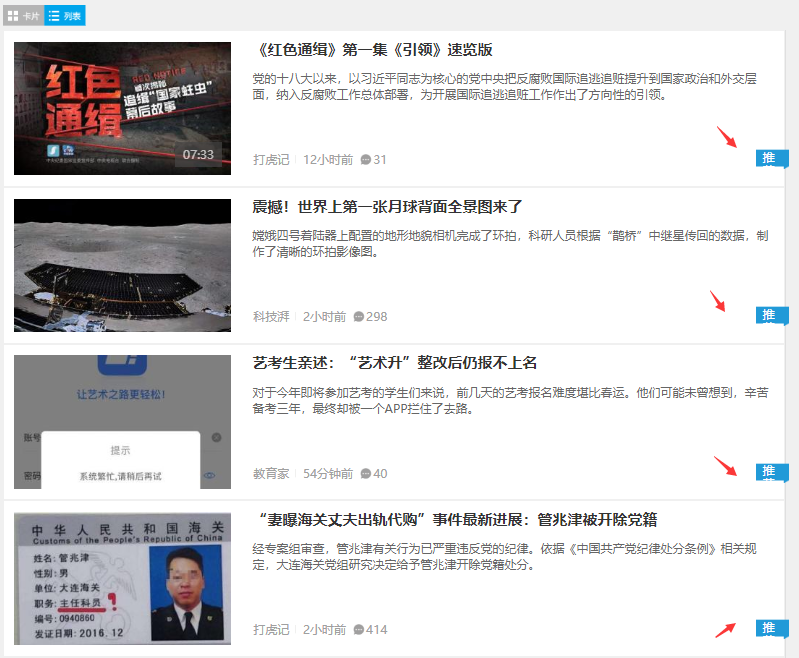
这四个推,引起我的注意了,看下标题结点对应的HTML代码:


啧啧啧,行吧,这个topCids就是顶部的四个推荐对应的id,到此,请求URL的规则就摸清楚了。
另外,试了下把pageidx=2改成1,响应的结果和2一样。所以还需要分两步走:
- 采集首页未分页。
- 加载的数据,然后再去请求Ajax的请求解析数据。
接着是请求头:
referer: https://www.thepaper.cn/user-agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 Safari/537.36x-requested-with: XMLHttpRequest
0x3 模拟请求
使用PostMan模拟下请求URL,加上请求头,可以,能拿到数据。
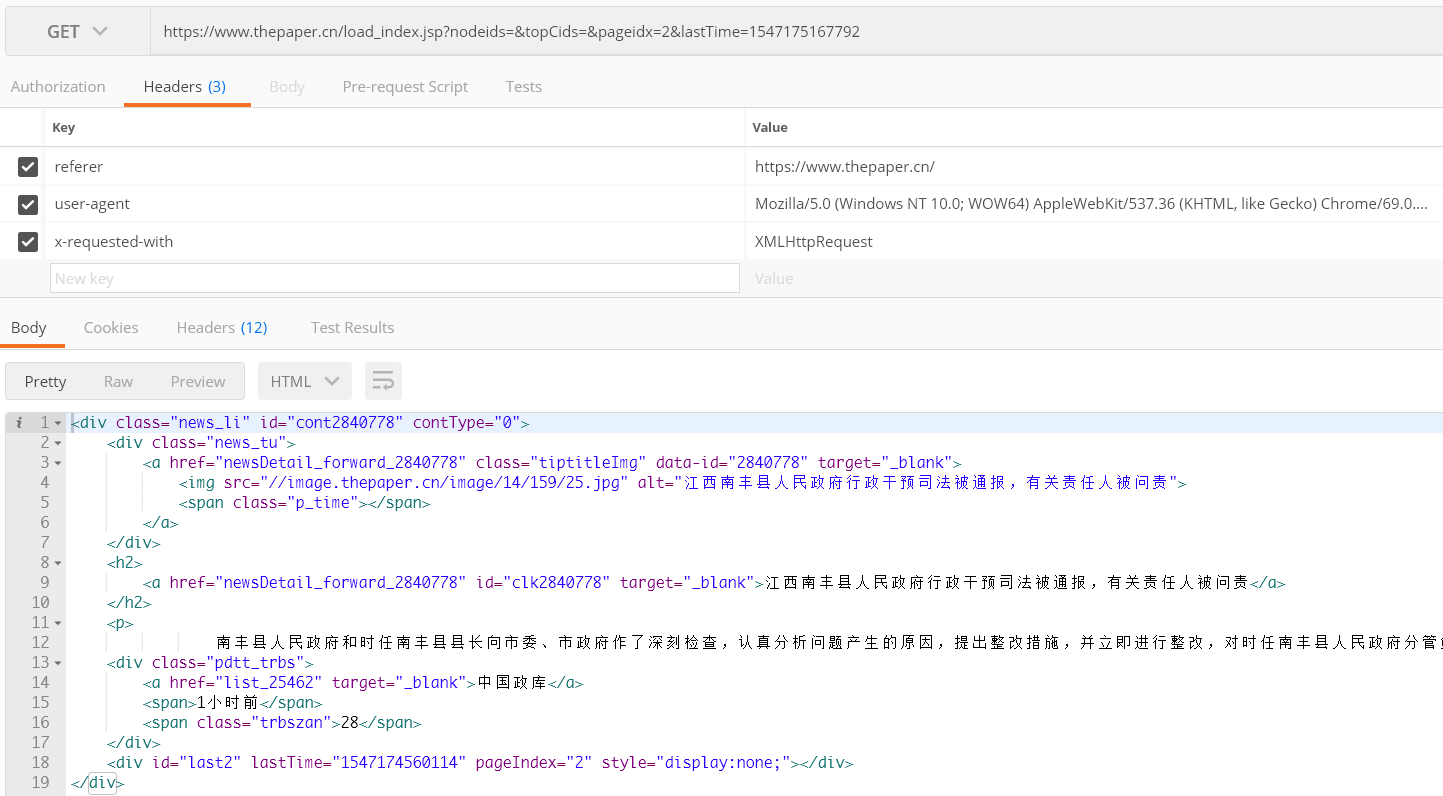
行吧,写成Python代码:
import timeimport requests as rindex_url = "https://www.thepaper.cn/"ajax_base_url = "https://www.thepaper.cn/load_chosen.jsp?"headers = {'referer': 'https://www.thepaper.cn/','user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 ''Safari/537.36','x-requested-with': 'XMLHttpRequest'}# 获取Ajax数据def fetch_ajax_data():ajax_params = {'nodeids':25949,'topCids':'2840959,2840504,2840804,2841177,','pageidx': 2,'lastTime': int(round(time.time() * 1000))}resp = r.get(ajax_base_url, params=ajax_params, headers=headers).textprint(resp)
0x4 解析数据
数据拿到了,接着就到解析数据了,数据是XML格式的,截取其中一部分来分析:
<div class="news_li" id="cont2840440" contType="91"><div class="news_tu"><a href="newsDetail_forward_2840440" class="tiptitleImg" data-id="2840440" target="_blank"><img src="//image.thepaper.cn/image/14/160/210.jpg" alt="云南副厅级官员因迎接迟到大骂县委书记,他为何敢这么狂?"><span class="p_time"></span></a></div><h2><a href="newsDetail_forward_2840440" id="clk2840440" target="_blank">云南副厅级官员因迎接迟到大骂县委书记,他为何敢这么狂?</a></h2><p>和建,是一个怎样的人?他为什么在退休前后仍对权力恋恋不舍?从他的个案中可以汲取什么启示和教训?</p><div class="pdtt_trbs"><a href="govAffairs_index.jsp?nodeId=" target="_blank" class="govname">澎湃问政</a><span>2小时前</span><span class="trbszan">62</span></div><div id="last2" lastTime="1547174986415" pageIndex="2" style="display:none;"></div></div>
关于XML的解析,Python中可以通过SAX,DOM,以及ElementTree三种方式来进行解析。
但是有个问题,这XML有点不对劲,所有元素都必须有关闭标签,但是那里的标签并没有
结束标记。直接用ElementTree解析,直接就报错了。如果想正常解析需要为每个img标签
都加上'/',处置之外,你还要在外层裹一层标签比如<start>数据</start>。那么繁琐,
直接写个正则来提取我们想要的数据吧。先明确下我们想提取的数据结果:
新闻标题,新闻描述,新闻图片链接,新闻链接,新闻来源,新闻发布时间。
接着利用正则表达式分组来提取数据:
ajax_pattern = re.compile(r'<a href="(.*?)".*?img src="(.*?)" alt="(.*?)".*?<p>(.*?)</p>.*?_blank">(.*?)</a>.*?<span>(.*?)</span>', re.S)def fetch_ajax_data():ajax_params = {'nodeids': 25949,'topCids': '2840959,2840504,2840804,2841177,','pageidx': 2,'lastTime': int(round(time.time() * 1000))}resp = r.get(ajax_base_url, params=ajax_params, headers=headers).textresults = ajax_pattern.findall(resp)for result in results:print("\n新闻地址:", index_url + result[0])print("图片地址:", 'http:' + result[1])print("新闻标题:", result[2])print("新闻描述:", result[3].replace('\n', '').replace(' ', ''))print("新闻来源:", result[4])print("新闻时间:", result[5])
运行后的部分输出结果如下:
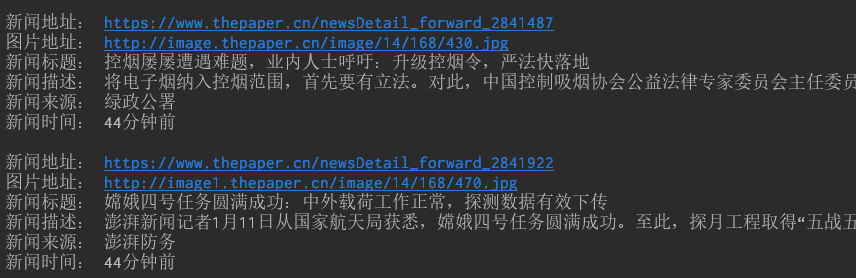
可以的,数据获取到了,接着完善下这个方法,循环去获取直到数据中出现1天前。
另外,为了避免访问过于频繁导致被封,每次访问随缘休眠0-3秒,因为脚本是早上
8j点定时去爬取的,采集完可能我可能都还没醒,耗时一点也没啥,就不上代理了。
修改完后的代码:
def fetch_ajax_data():ajax_params = {'nodeids': 25949,'topCids': '2840959,2840504,2840804,2841177,',}pageidx = 2news_list = [] # 新闻列表while True:ajax_params['pageidx'] = pageidxajax_params['lastTime'] = int(round(time.time() * 1000))resp = r.get(ajax_base_url, params=ajax_params, headers=headers)resp_content = resp.textprint(resp.url)results = ajax_pattern.findall(resp_content)for result in results:if result[5] == '1天前':return news_listelse:news_list.append([index_url + result[0], 'http:' + result[1], result[2],result[3].replace('\n', '').replace(' ', ''), result[4], result[5]])pageidx += 1time.sleep(random.randint(0, 2))
部分输出结果如下:

前面也说了Ajax的接口并不能获取所有数据,还需要去解析一波首页,拿两个东西:
- 1.首页进来后加载的数据
- 2.顶部的几个topCids参数
新闻的结点结构r
<div class="news_li" id="cont2845046" conttype="0"><div class="news_tu"><a href="newsDetail_forward_2845046" class="tiptitleImg" data-id="2845046" target="_blank"> <img src="//image1.thepaper.cn/image/14/202/688.jpg" alt="《红色通缉》第二集:织网"><span class="p_time"></span></a></div><h2><a href="newsDetail_forward_2845046" id="clk2845046" target="_blank">《红色通缉》第二集:织网</a></h2><p>2015年4月25日,“百名红通人员”名单公布仅三天,就传来了首名嫌犯落网的消息,速度之快出人意料,也让落网的第一人戴学民备受舆论关注。</p><div class="pdtt_trbs"><a href="list_25424" target="_blank">一号专案</a><span>59分钟前</span><div class="trbstxt">推荐</div></div>
使用lxml库来解析:
# 提取topCids的正则cids_pattern = re.compile('&topCids=(.*?)&', re.S)# 提取首页的新闻数据index_resp = r.get(index_url).textindex_html = etree.HTML(index_resp)news_urls = index_html.xpath('//div[@class="news_li"]/div[@class="news_tu"]/a') # 新闻链接列表imgs_urls = index_html.xpath('//div[@class="news_li"]/div[@class="news_tu"]/a/img') # 新闻图片列表overviews = index_html.xpath('//div[@class="news_li"]/p') # 新闻简介列表times = index_html.xpath('//div[@class="pdtt_trbs"]/span') # 时间列表origins = index_html.xpath('//div[@class="pdtt_trbs"]/a') # 来源列表for i in range(0, int(len(news_urls) / 2)):print(index_url + news_urls[i].get('href'))print('http:' + imgs_urls[i].get('src'))print(imgs_urls[i].get('alt'))print(overviews[i].text.replace('\n', '').replace(' ', ''))print(times[i].text)print(origins[i].text)# 正则提取topCidstopCids = cids_pattern.search(index_resp)if topCids is not None:print('topCids:', topCids.group(1))
部分输出结果如下:
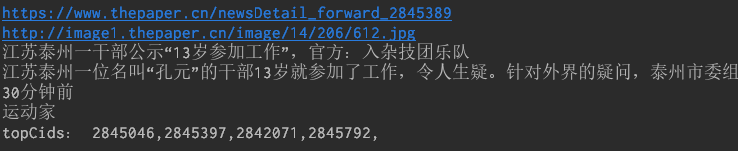
然后再自行整合下代码,把采集到的新闻都放到同一个列表中,返回。
0x5 保存数据
数据解析完了,接着就到数据存储了,这里我们使用MySQL来保存数据,每次都传字符有点繁琐。
直接定义成一个类:
# 新闻类class News:def __init__(self, title, overview, url, image, create_time, origin):self.title = titleself.overview = overviewself.url = urlself.image = imageself.create_time = create_timeself.origin = origindef to_dict(self):return {'title': self.title, 'overview': self.overview, 'url': self.url, 'image': self.image,'create_time': self.create_time, 'origin': self.origin}
接着写一个数据库操作类,Python中操作MySQL需要安装一波pymysql库:
pip install pymysql
然后定义几个操作数据库的函数,显示创建库,表,以及删除表:
# 创建数据库def create_db(self):cursor = self.db.cursor()cursor.execute("CREATE DATABASE IF NOT EXISTS news CHARACTER SET UTF8MB4")cursor.close()# 创建表def create_table(self):self.db = pymysql.connect('localhost', user='root', password='Jay12345', port=3306, db='news')cursor = self.db.cursor()cursor.execute("CREATE TABLE IF Not Exists news(""id INT AUTO_INCREMENT PRIMARY KEY,""title TEXT NOT NULL,""overview TEXT,""url TEXT NOT NULL,""image TEXT NOT NULL,""create_time TEXT NOT NULL,""origin TEXT NOT NULL)")cursor.close()# 删除表def delete_table(self):self.db = pymysql.connect('localhost', user='root', password='Jay12345', port=3306, db='news')cursor = self.db.cursor()cursor.execute("DROP TABLE news")cursor.close()
接着是插入数据,不难写出如下这样的插入语句:
sql = "INSERT INTO news(title,overview,url,image,create_time,origin) VALUES(" + title + "," + overview + "," + url + "," + image + "," + create_time + "," + create_time + ")"
这样拼接除了长不好看,还繁琐,容易出错,我们可以使用格式化符%s来替代,然后在调用execute()
函数时把value值通过元组的方式传入,优化下:
sql = "INSERT INTO news(title,overview,url,image,create_time,origin) VALUES (%s, %s, %s, %s, %s, %s)"cursor.execute(sql, (title,overview,url,image,create_time,origin))
还有个小的问题是,如果新增或删除字段,数据库语句又要更改,传入的元组也要改。
其实可以变通下,传入一个动态变化的字典,然后SQL语句根据字典动态构造。
keys = ','.join(self.news_column_list)values = ','.join(['%s'] * len(self.news_column_list))sql = 'INSERT INTO news ({keys}) VALUES ({values})'.format(keys=keys, values=values)cursor.execute(sql, tuple(news.to_dict().values()))jb
调整后的代码:
def __init__(self):self.db = pymysql.connect('localhost', user='root', password='Jay12345', port=3306)self.news_column_list = ['title', 'overview', 'url', 'image', 'create_time', 'origin']self.create_db()self.create_table()# 插入一条新闻def insert_news(self, news):cursor = self.db.cursor()try:keys = ','.join(self.news_column_list)values = ','.join(['%s'] * len(self.news_column_list))sql = 'INSERT INTO news ({keys}) VALUES ({values})'.format(keys=keys, values=values)cursor.execute(sql, tuple(news.to_dict().values()))self.db.commit()except Exception as e:print(str(e))self.db.rollback()finally:cursor.close()# 插入多条新闻def insert_some_news(self, some_news):cursor = self.db.cursor()try:keys = ','.join(self.news_column_list)values = ','.join(['%s'] * len(self.news_column_list))sql = 'INSERT INTO news ({keys}) VALUES ({values})'.format(keys=keys, values=values)for news in some_news:cursor.execute(sql, tuple(news.to_dict().values()))self.db.commit()except Exception as e:print(str(e))self.db.rollback()finally:cursor.close()
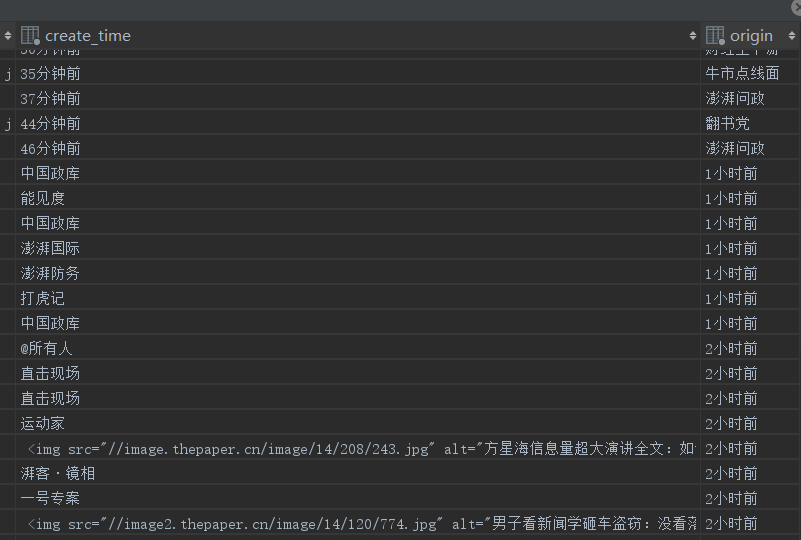
接着把前面直接print的都换成News类,传参,添加到列表中,返回,然后调用批量插入函数,运行后可以在
数据库中看到我们爬取到的新闻内容:

em...数据是爬取到了,但是貌似有些问题,除了上面的创建时间不对外,还有:
把提取的正则改下:
r'<a href="(.*?)".*?img src="(.*?)" alt="(.*?)".*?<p>(.*?)</p>.*?pdtt_trbs".*?<a.*?>(.*?)</a>.*?<span>(.*?)</span>', re.S)
接着再次审视下看看爬取到的数据,到此,澎湃新闻的爬取完成,除了这个站点外,读者还可j以如法炮制
爬取类似的新闻站点,比如下面的这些,这里就不再做重复劳动的事咯~
- 新华社:http://www.xinhuanet.com/
- i黑马:http://www.iheima.com/
- 第一财经周刊:https://www.cbnweek.com/
- 36氪:https://36kr.com/
- 亿欧:https://www.iyiou.com/
- 创业邦:https://www.cyzone.cn/
- IT桔子观察(融资):https://www.itjuzi.com/
- TechWeb:http://www.techweb.com.cn/
- 界面新闻:https://www.jiemian.com/
- 联商网(新零售,商业地产):http://www.linkshop.com.cn/
- 芥末堆(教育):https://www.jiemodui.com/
- 鲸媒体(教育):http://www.jingmeiti.com/
- 决胜网(教育):http://www.juesheng.com/
- 动脉网(医疗):https://vcbeat.net/
- Bianews(区块链):https://www.bianews.com/
- 巴比特(区块链):https://www.8btc.com/
- 盖世汽车资讯(汽车):http://auto.gasgoo.com/
- 第一电动(新能源):https://www.d1ev.com/
- 新旅界(旅游财经)http://www.lvjie.com.cn/
- 环球旅讯(旅游财经)https://www.traveldaily.cn/
2.抓取各类日报微博
0x1 明确抓取目标与请求分析
接着是爬取各类新闻日报的微博,爬取网站时,如果PC端的网页验证比较复杂,可以看看有没有
M端(手机网页端),试试从M端寻找突破口。比如新浪微博的M端:https://m.weibo.cn/
可以通过:https://m.weibo.cn/u/用户id 来打开某个用户的微博,比如:

接着打开抓包,过滤XHR,看下Ajax加载的请求URL:

看下返回的数据:
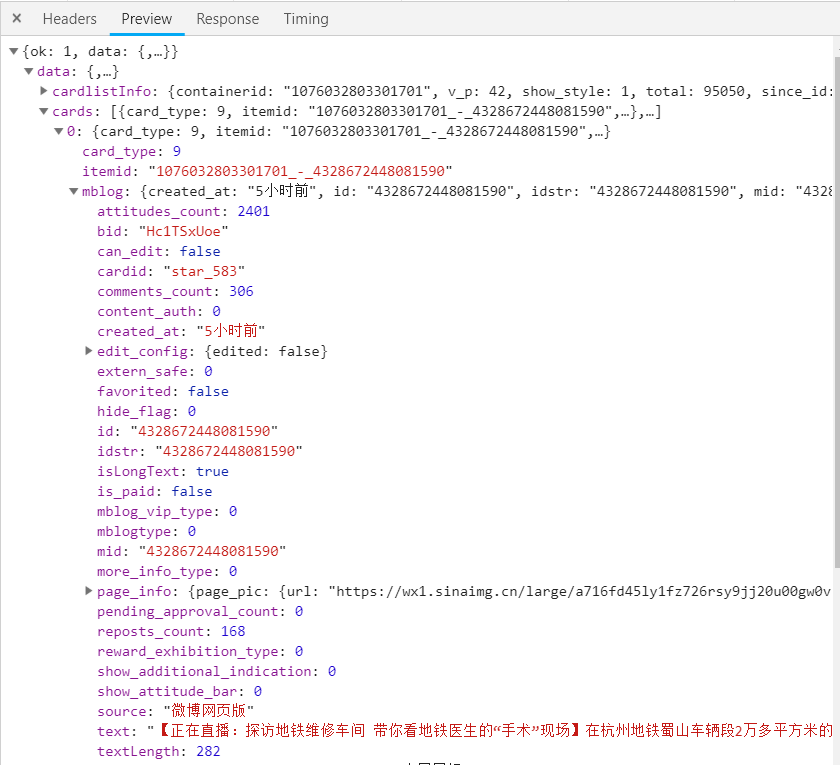
行吧,分析下URL的规律,基地址就不用说了:https://m.weibo.cn/api/container/getIndex
接着是参数,可以确定的参数有如下两个:
- type=uid,固定
- value=2803301701,用户id
剩下的containerid和since_id,要跟一跟,先确定是不是固定的,滚多几遍,看看新的URL:
https://m.weibo.cn/api/container/getIndex?type=uid&value=2803301701&containerid=1076032803301701&since_id=4328498967786823https://m.weibo.cn/api/container/getIndex?type=uid&value=2803301701&containerid=1076032803301701&since_id=4328416646208508
行吧containerid是不变的,而since_id应该是从上一个接口返回的,倒数第二请求搜下:4328416646208508,
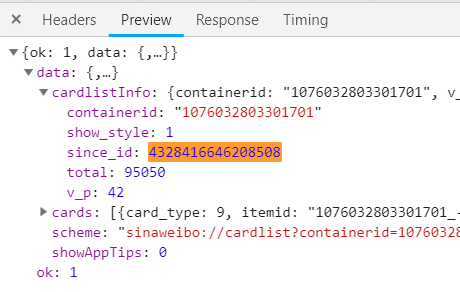
果然,那就剩下containerid咯,把所有请求都清了,接着刷新一波页面,搜下:1076032803301701:

但是这个URL中也有containerid啊,我都还没拿到,怎么拼URL?试试不加这个参数?访问:
https://m.weibo.cn/api/container/getIndex?type=uid&value=2803301701
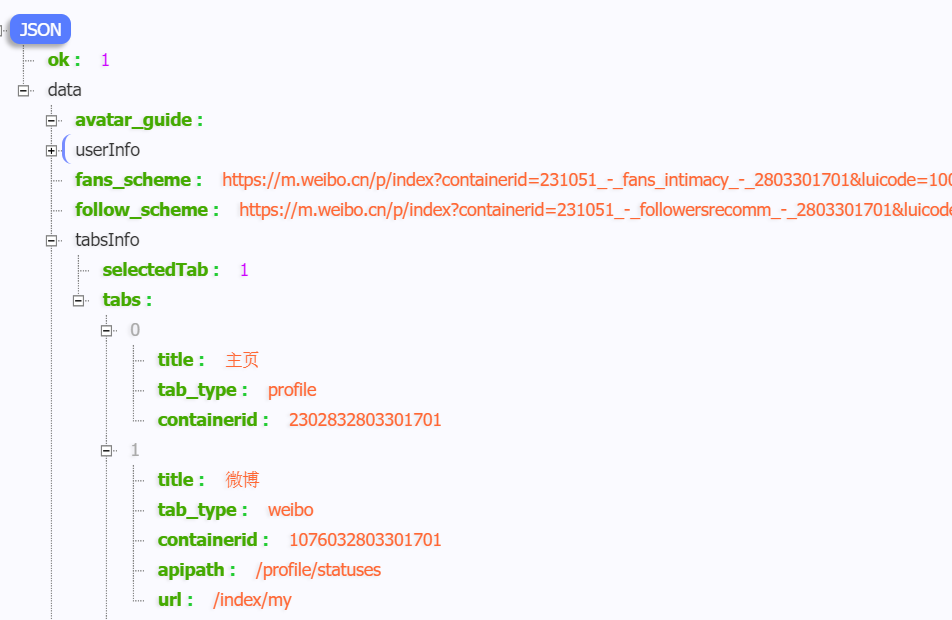
0x2 模拟请求
啧啧,拿到一样的数据,行吧,接着捋下模拟请求的流程:
- 1.先获取一波containerid
- 2.拿着这个containerid去执行ajax请求,同时解析获取since_id用作下次请求的参数。
先是获取containerid:
# 获取containeriddef fetch_container_id(userid):resp = r.get(ajax_url, headers=ajax_header, params={'type': 'uid', 'value': userid}).json()print(resp.get('data').get('tabsInfo').get('tabs')[1].get('containerid'))
运行结果:
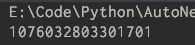
行吧,成功获取到containerid了,接着就是构造ajax请求了。第一个请求是没有since_id的,
而后续请求则从上一次的ajax结果中获取since_id作为下次请求的参数。
# 获取微博def fetch_weibo(userid, containerid):since_id = ''if since_id == '':resp = r.get(ajax_url, headers=ajax_header, params={'type': 'uid', 'value': userid, 'containerid':containerid}).json()cards = resp.get('data').get('cards')for card in cards:mblog = card.get('mblog')print("创建时间:", mblog.get('created_at'))print("text:", mblog.get('text'))
部分输出结果如下:

另外,在测试分页的时候,发现一个很奇怪的问题,since_id拿不到???同一个链接,Requests拿到的结果
和浏览器拿到的结果竟然不一样,尽管我已经设置了各种Header:
# 请求URLhttps://m.weibo.cn/api/container/getIndex?type=uid&value=2803301701&containerid=1076032803301701# Requests请求的响应结果{'ok': 1, 'data': {'cardlistInfo': {'containerid': '1076032803301701', 'v_p': 42, 'show_style': 1, 'total': 95084, 'page': 2}# 浏览器访问结果{"ok": 1, "data": {"cardlistInfo": {"containerid": "1076032803301701", "v_p": 42, "show_style": 1, "total": 95084, "since_id": 4328880058268227}
有知道怎么拿到since_id的童鞋可以在评论区留言。搜了下网上的方案,直接用page参数,而非since_id。
0x3 解析数据
一开始,我是想着去解析微博标题的,然后去解析标题,提取数据,但是处理起来有点繁琐。
后来想想还是算了,即刻APP也没做这个,点击新闻是直接跳微博详情的。
详情页的url规则:
https://m.weibo.cn/detail/{微博id}
所以这里要做只是解析:新闻标题,新闻创建时间,获取微博id拼接URL作为新闻详情页的链接。
先提取一波不同样式的微博信息:
【送别林清玄 重温他笔下的惬意与淡然】23日,台湾知名作家林清玄过世,终年65岁。他的作品常常出现在《读者》《青年文摘》上,每个青少年或许都曾读过。“所有时间里的事物,都永远不会回来了。”“和时间赛跑”的人,永远不会回来了。重温,送别!【教科书式教育!公交车礼让行人,家长教孩子鞠躬致谢<span class="url-icon"><img alt=[赞] src="//h5.sinaimg.cn/m/emoticon/icon/others/h_zan-6e88e6f51d.png" style="width:1em; height:1em;" /></span>】近日,山东青岛,一辆公交车在斑马线礼让行人时,一位家长牵着孩子过马路,一边跟孩子说着什么,一遍弯腰教孩子鞠躬致谢。公交公司的工作人员表示,平时礼让常遇到路人竖大拇指的、微笑的,第一次遇到教育孩子感恩的。<a data-url="http://t.cn/E5lZLD1" href="http://miaopai.com/show/23UZs~CF6PAqyDdQ25HYMatq5jujmg0BQ4yfsQ__.htm?showurl=http%3A%2F%2Fmiaopai.com%2Fshow%2F23UZs%7ECF6PAqyDdQ25HYMatq5jujmg0BQ4yfsQ__.htm&url_open_direct=1&toolbar_hidden=1&url_type=39&object_type=video&pos=1&containerid=230442744560b81311e0be36d04147970e4dcf&luicode=10000011&lfid=1076032803301701" data-hide=""><span class='url-icon'><img style='width: 1rem;height: 1rem' src='https://h5.sinaimg.cn/upload/2015/09/25/3/timeline_card_small_video_default.png'></span><span class="surl-text">微辣Video的秒拍视频</span></a><a href="https://m.weibo.cn/search?containerid=231522type%3D1%26t%3D10%26q%3D%23%E5%AE%88%E6%8A%A4%E5%AE%9D%E8%B4%9D%23&isnewpage=1&luicode=10000011&lfid=1076032803301701" data-hide=""><span class="surl-text">#守护宝贝#</span></a>【<span class="url-icon"><img alt=[话筒] src="//h5.sinaimg.cn/m/emoticon/icon/others/o_huatong-9f86617336.png" style="width:1em; height:1em;" /></span>急转寻人!福建12岁女孩昨日走失】陈燕娟(女,12岁),1月22日12时40分许,从福建莆田荔城区拱辰街道富力小区走失。走失时,她上身穿紫色外套,下身穿牛仔裤,戴粉色眼镜。如有线索,请迅速与警方联系:13799610199。速扩!<a href='/n/公安部儿童失踪信息紧急发布平台'>@公安部儿童失踪信息紧急发布平台</a>【奶白鲫鱼汤<span class="url-icon"><img alt=[馋嘴] src="//h5.sinaimg.cn/m/emoticon/icon/default/d_chanzui-ad3f4f182c.png" style="width:1em; height:1em;" /></span>】鲫鱼汤这样做,汤白如牛奶又没腥味,喝一口根本停不下来!赶紧马走试试~(吃货秘籍)【春运首日发送旅客6754.5万人次 你坐火车还是飞机回家?】21日,<a href="https://m.weibo.cn/search?containerid=231522type%3D1%26t%3D10%26q%3D%232019%E6%98%A5%E8%BF%90%23&luicode=10000011&lfid=1076032803301701" data-hide=""><span class="surl-text">#2019春运#</span></a>首日,全国铁路、道路、水路、民航共发送旅客6754.5万人次,比去年同期增长1.7%。其中铁路发送旅客953.2万人次,民航发送旅客166.2万人次。<a data-url="http://t.cn/E5TC2Xl" href="https://media.weibo.cn/article?object_id=1022%3A2309351000024331564912780165&extparam=lmid--4331573362959560&luicode=10000011&lfid=1076032803301701&id=2309351000024331564912780165" data-hide=""><span class='url-icon'><img style='width: 1rem;height: 1rem' src='https://h5.sinaimg.cn/upload/2015/09/25/3/timeline_card_small_article_default.png'></span><span class="surl-text">春运首日发送旅客6754.5万人次 你坐火车还是飞机回家</span></a> 千山万水,回家的路最美。今年,你的回家路,是什么?【画面引起极度舒适!这些<a href="https://m.weibo.cn/search?containerid=231522type%3D1%26t%3D10%26q%3D%23%E9%AB%98%E6%83%85%E5%95%86%E6%89%A7%E6%B3%95%E7%9E%AC%E9%97%B4%23&extparam=%23%E9%AB%98%E6%83%85%E5%95%86%E6%89%A7%E6%B3%95%E7%9E%AC%E9%97%B4%23&luicode=10000011&lfid=1076032803301701" data-hide=""><span class="surl-text">#高情商执法瞬间#</span></a>,真耐看<span class="url-icon"><img alt=[good] src="//h5.sinaimg.cn/m/emoticon/icon/others/h_good-55854d01bb.png" style="width:1em; height:1em;" /></span>】一则“交警要求司机捡起车窗抛出垃圾”的新闻引发好评。铁面无私、执法必严是警察的担当,而这些既讲道理又有温度的“高情商”更加珍贵,让人感觉极度舒适。人性化执法,有温度!<a data-url="http://t.cn/Eq8OzkF" href="http://miaopai.com/show/3W~4f56NCb1YfSaGEsG7jmTyiNYgVO3PiN7RDg__.htm?showurl=http%3A%2F%2Fmiaopai.com%2Fshow%2F3W%7E4f56NCb1YfSaGEsG7jmTyiNYgVO3PiN7RDg__.htm&url_open_direct=1&toolbar_hidden=1&url_type=39&object_type=video&pos=1&containerid=230442e07076f4d85282f6d54242841ee01b15&luicode=10000011&lfid=1076032803301701" data-hide=""><span class='url-icon'><img style='width: 1rem;height: 1rem' src='https://h5.sinaimg.cn/upload/2015/09/25/3/timeline_card_small_video_default.png'></span><span class="surl-text">人民日报的秒拍视频</span></a>
观察一波规律,不难发现标题都放在【】里,写个正则提取一波即可:
title_pattern = re.compile(r'【(.*?)】', re.S)
部分解析结果如下:
接着到数据清洗了,先过滤一波表情标签:
<span class="url-icon"><img alt=[赞] src="//h5.sinaimg.cn/m/emoticon/icon/others/h_zan-6e88e6f51d.png" style="width:1em; height:1em;" /></span>
直接编写正则,直接把这一部分替换为空字符串。
# 过滤emoji表情的正则emoji_filter_pattern = re.compile(r'<span class="url-icon">.*?</span>', re.S)# 把表情替换为空格title = emoji_filter_pattern.sub('', title)
行吧,替换完了,接着是下面这种标题的处理:
中国交通<a href="https://m.weibo.cn/search?containerid=231522type%3D1%26t%3D10%26q%3D%23%E5%8D%81%E5%B9%B4%E5%AF%B9%E6%AF%94%E6%8C%91%E6%88%98%23&extparam=%23%E5%8D%81%E5%B9%B4%E5%AF%B9%E6%AF%94%E6%8C%91%E6%88%98%23&luicode=10000011&lfid=1076032803301701" data-hide=""><span class="surl-text">#十年对比挑战#</span></a>
需要提取一波a标签里的,两个#号夹着的文本,依旧是正则提取一波:
a_surl_text_pattern = re.compile(r'(.*?)<a.*?<span class="surl-text">#(.*?)#</span></a>(.*?)')
提取后,发现还有下面这样的数据:

同样写个正则,过滤一波a标签,提取文本:
a_text_pattern = re.compile(r'(.*?)<a.*?>(.*?)</a>')
爬个30页看看结果标题是否正确,确认无问题后,接着就是获取日期和微博id咯:

0x4 保存数据
行吧,数据都拿到了,接着就是存数据库里咯,和上面那个一样,直接存数据库中。
比较简单,我们另外加一个字典,用来保存日报微博的名字和uid,比如这些:
news_ids = {'人民日报': '2803301701','广州日报': '1887790981','南方日报': '1682207150','中国日报': '1663072851','光明日报': '1402977920','央视新闻': '2656274875','环球时报': '1974576991','澎湃新闻': '5044281310','头题新闻': '1618051664',}
加上循环,最后的完整代码如下:
"""抓取新浪微博的爬虫"""import requests as rimport timeimport randomimport refrom DBHelper import News, DBHelperindex_url = 'https://m.weibo.cn/' # 首页基地址wb_detail_base_url = 'https://m.weibo.cn/detail/' # 微博详情页基地址ajax_url = index_url + 'api/container/getIndex' # ajax请求基地址ajax_header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.92 ''Safari/537.36','X-Requested-With': 'XMLHttpRequest'}news_ids = {'人民日报': '2803301701','广州日报': '1887790981','南方日报': '1682207150','中国日报': '1663072851','光明日报': '1402977920','央视新闻': '2656274875','环球时报': '1974576991','澎湃新闻': '5044281310','头题新闻': '1618051664',}title_pattern = re.compile(r'【(.*?)】', re.S) # 新闻标题获取正则emoji_filter_pattern = re.compile(r'<span class="url-icon">.*?</span>', re.S) # 新闻标题表情过滤正则a_surl_text_pattern = re.compile(r'(.*?)<a.*?<span class="surl-text">#(.*?)#</span></a>(.*?)') # 提取链接中的文本a_text_pattern = re.compile(r'(.*?)<a.*?>(.*?)</a>') # 提取链接中的文本abstract_pattern = re.compile(r'', re.S) # 新闻概述提取正则news_url_pattern = re.compile(r'<a\s+href="(.*)?".*?#(.*?)#', re.S) # 新闻概述提取正则# 获取containeriddef fetch_container_id(userid):resp = r.get(ajax_url, headers=ajax_header, params={'type': 'uid', 'value': userid}).json()return resp.get('data').get('tabsInfo').get('tabs')[1].get('containerid')# 获取微博def fetch_weibo(userid, containerid, username):news_list = []cur_page = 1while True:resp = r.get(ajax_url, headers=ajax_header, params={'type': 'uid', 'value': userid, 'containerid':containerid, 'page': cur_page})print('爬取【%s】:%s' % (username, resp.url))resp = resp.json()cards = resp.get('data').get('cards')for card in cards:mblog = card.get('mblog')text = mblog.get('text')title_result = title_pattern.search(text)if title_result is not None:title = title_result.group(1)# 过滤表情title = emoji_filter_pattern.sub('', title)# 过滤超链接a_text_result = a_surl_text_pattern.search(title)if a_text_result is not None:title = a_text_result.group(1) + a_text_result.group(2) + a_text_result.group(3)title = a_text_pattern.sub('', title)if mblog.get('created_at').find('前') == -1:return news_listnews_list.append(News(title, '', wb_detail_base_url + mblog.get('id'), '', mblog.get('created_at'), username))cur_page += 1time.sleep(random.randint(5, 10))if __name__ == '__main__':helper = DBHelper()for key, value in news_ids.items():result_list = fetch_weibo(value, fetch_container_id(value), key)helper.insert_some_news(result_list)
部分运行结果如下:

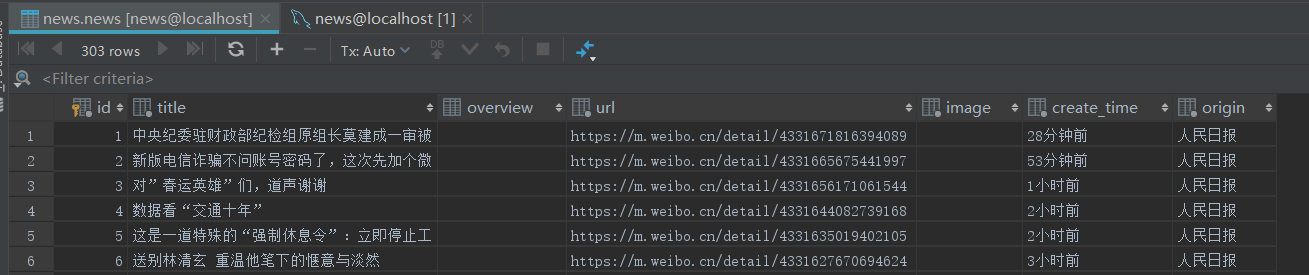
到此,各类日报的微博就爬取完了,另外每个微博号对应的containerid是不变的,
你还可以把这些直接存到数据库中,这样,就不用每次执行脚本都去请求一次了。
3.把脚本丢服务器上定时执行
0x1 安装MySQL
把代码丢到远程服务器上,笔者使用的是腾讯云主机,先执行一波下述命令安装MySQL:
# 安装MySQL服务,输入Y后,如图会让你输入密码,重复输入确认sudo apt-get install mysql-server# 安装MySQL客户端sudo apt-get install mysql-client# 安装libmysqlclient,输入Ysudo apt-get install libmysqlclient-dev
安装完后执行一波脚本,缺什么库装什么库,脚本跑起来就行。
0x2 DataGrip连接远程MySQL
MySQL默认是不允许远程访问的,下面简单说下使用DataGrip连接远程数据库的流程。
- 1.云服务器开启安全组里的3306端口,如图:

- 2.停止MySQL服务:
sudo /etc/init.d/mysql stop
- 3.修改my.cnf文件,注释掉bind-address = 127.0.0.1,键入wq保存退出;
vim /etc/mysql/my.cnf
- 4.启动mysql服务
/etc/init.d/mysql start
- 5.输入下述命令查看当前3306端口的状态
netstat -an|grep 3306
- 6.修改用户访问权限
mysql -u root -p # 用户登录use mysql; # 选中mysql数据库GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION; # 授权FLUSH PRIVILEGES; # 更新权限EXIT # 退出mysql
注:上面设置的结果是所有ip都能访问数据库,如需指定特定ip才能访问的话,
可以把'@'%改成特定ip。还有这里用的是root账户,你可以通过下述命令创建
一个新的用户,然后用这个用户进行访问,可以在此做一些权限控制操作。
CREATE USER 新用户 IDENTIFIED BY '密码';GRANT ALL PRIVILEGES ON *.* TO '新用户'@'%' IDENTIFIED BY '密码' WITH GRANT OPTION; # 授权FLUSH PRIVILEGES;
- 7.打开DataGrip,以此点击:File -> New -> DataSource -> MySQL,如图依次配置
General和SSH/SSL选项卡,接着点击Apply和Test Connection。


出现如图所示的Successful,代表连接成功。

0x3 使用crontab定时执行脚本
在linux中可以使用cron来执行一些定时任务,linux自带,默认开机就自动启动,
启动后会读取所有配置文件(全局配置文件/etc/crontab 和 每个用户的计划任务配置文件),
cron会根据命令和执行时间来调度工作任务。cron的常用命令如下:
sudo service cron restart # 重启cronsudo service cron stop # 停止cronsudo service cron start # 启动cronsudo service cron status # 查看cron状态
除此之外,还有下述命令可以操作crontab:
sudo crontab –l # 显示crontab文件sudo crontab –e # 修改crontab文件sudo crontab –r # 删除crontab文件sudo crontab –ir # 删除crontab文件前提醒用户
接着执行上面的sudo crontab –e命令,修改一波计划任务,命令的格式如下:
* * * * * command
参数依次为:
- 分:0 - 59
- 时:0 - 23
- 天:1 - 31
- 月:1 - 12
- 周:0 - 6
- 执行的命令
除此之外还可以使用通配符:
*(任意值,比如在天的位置写*代表每天),(允许在某一个位填多个值,表示某几个时间段执行,逗号分隔)/(斜线,配合*使用,代表每隔多长时间,比如在小时位写/2代表每隔两小时)
大概规则就这些,接着在配置文件中添加执行命令,8点钟删一波表,8点1分抓澎湃新闻,
8点15分抓新浪微博的新闻。具体内容如下:
0 8 * * * python3 /home/ubuntu/AutoNews/DBHelper.py > /home/ubuntu/AutoNews/db.txt1 8 * * * python3 /home/ubuntu/AutoNews/PenpaiSpider.py > /home/ubuntu/AutoNews/pp.txt15 8 * * * python3 /home/ubuntu/AutoNews/WeiboSpider.py > /home/ubuntu/AutoNews/wb.txt
配置完后,键入:sudo service cron restart,重启一波,然后就可以坐等第二天早上看看结果咯(日志文件的创建日期)。

如果你不想动/etc/crontab这个全局配置文件,也可以单独写一个cron的文件,比如:news.cron,
接着键入下述命令添加定时任务:
crontab news.cron > news.log
添加后可以键入:crontab -l 查看是否配置成功,或者看下/var/spool/cron目录下是否生成了对应的脚本。
(注:此方法会直接替换该用户下的crontabs,而不是新增)
行吧,本节的内容就这么多,有疑问的欢迎在评论区留言,谢谢~

Tips:公号目前只是坚持发早报,在慢慢完善,有点心虚,只敢贴个小图,想看早报的可以关注下~

