@coder-pig
2023-02-03T03:39:28.000000Z
字数 4685
阅读 1069
Van♂Python | 对春联?我无敌,你随意~
van♂Python
0x0、事出必有因
新年开工第一周,节后综合征,无心工作~

(图片出处:深圳卫健委公号),大家都讨了多少开门红包哇?说粗来,让杰哥酸一下~

记得春节前最后一周,本想玩小游戏消磨时间,结果却被一个 "孤岛求生" 的玩法拿捏,一怒之下 手搓"辅助",利用 "科技" 降维打击,直接屠榜,最后还写了一篇文章 《手搓游戏"辅助",你怎么跟我玩?》 记录具体的实践过程 。
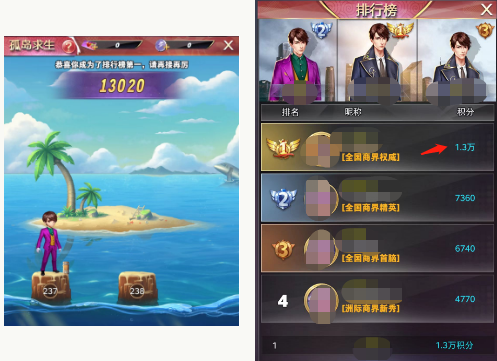
分数是 第二名的两倍,你怎么跟我玩?

然后,这小游戏过年的时候很接地气地推出了一系列 "春节活动",其中有个模式叫 "以诗会友",玩法如下:

em?这不纯纯的 对春联 吗?(也叫对对子、对春等),根据上联对出下联。而在游戏里的规则是这样的 :
系统给出 完整上联、部分下联 (也可能全不给) 及一些 备选词,玩家根据这些 猜出完整下联,然后 将对应备选词拖拽到正确的框框中 补全下联。下联正确获得积分,切到下一题,如此循环,直至倒计时完,游戏结束。
简单,在下可是 七省文状元兼参谋将军,绰号对王之王的对穿肠,会怕这个?直接开对~

在经历了好几局一个都对不出来后,杰哥:

em... 智力不够科技凑,老老实实想办法整个 辅助 吧!
思路分析
对春联的玩法本质上就是常见的 问答类游戏,记得之前有段时间,这类小游戏超火,什么全民答题赢现金,当时涌现了不少的 "辅助"。剖析下这类辅助的实现原理,可以简单拆解成这三步:
- 识别问题:原生类-拿到问题组件直接提取文本,非原生类-截图然后进行OCR文字识别;
- 检索答案:利用搜索引擎、问答机器人、查题API、题库等获取问题的正确答案;
- 自动答题:拿着检索到的答案模拟用户答题,如填空、点击选项、勾选、拖拽点击等;
思路非常清晰,接着就是根据这款小游戏的实际情况,来开发对春联的 "辅助" 了~

0x1、问题识别
小游戏非原生,直接 无脑OCR,截个屏,丢 chineseocr_lite 识别看下效果:

还可以,上联正确识别,下联只错了一个字。拿上下联的大概坐标区域 裁剪 一下,排除无关项提高识别速度之余,看能否提高准确度~
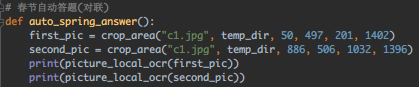
裁剪后的图片:
速度好像快了,但识别率反而降低了:

转灰度后依旧如此:

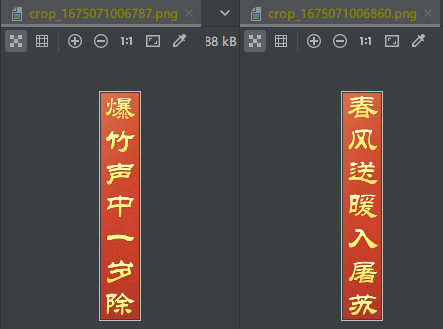
我又写了一个拼接图片的方法,尝试将上下联水平拼接一波:
间距设置为400,识别结果如下:

神奇,竟然好一点,再灰度化下试试看:

更好了,换成其它对联试试:

识别结果:

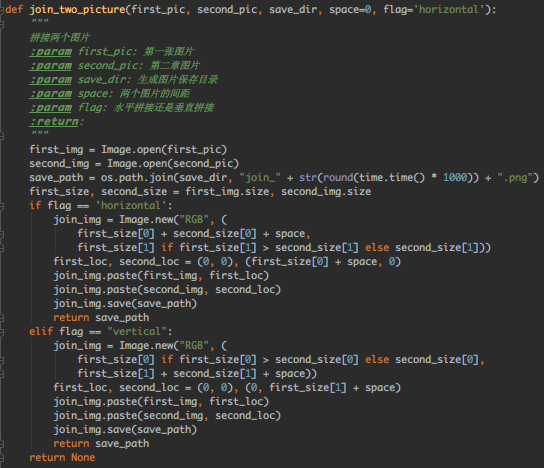
擦,因为填空的框框,上下联直接被拆散了,所以为了保险点,还要对识别结果做下处理:
根据坐标判断是上联还是下联,正则提取中文(有时会识别出一些标点符号),最后拼接
具体代码如下:

运行看看效果:

可以,又试了几个样本发现都能比较准确地拿到上下联~
0x2、检索答案
上联拿到了,接着就是检索答案了,杰哥的思路有三:搜索引擎、ChatGPT API、题库,一一尝试~
① 搜索引擎
没找到直接能用的搜索API,只能 浏览器访问咯,一种最粗暴的方式就是用 webbrowser 请求URL,以百度搜索为例:
while True:input() # 控制台每按一次回车触发一次检索first_couplet = extract_couplet() # 解析当前上联# 搜索下联webbrowser.open("https://www.baidu.com/s?wd={}的下联".format(first_couplet))
运行后,每次回车都会打开浏览器检索:
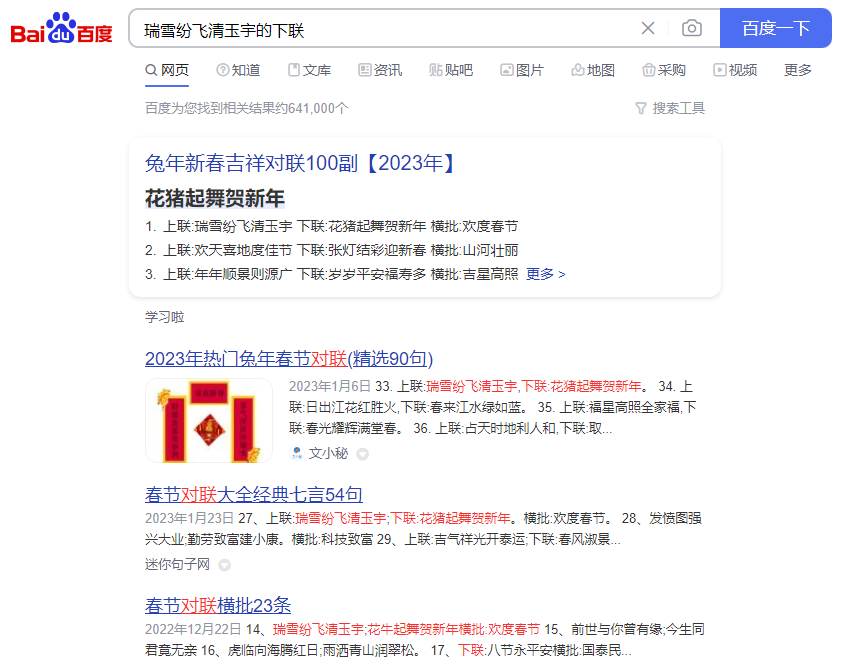
从搜索结果中,杰哥发现了一个问题:一个上联可能有多个匹配的下联,但游戏里只有 "一个正确答案",这就需要我们用肉眼 + 脑子来筛选出匹配的下联。费时费力,难顶...

得把这个过程自动化,自动解析结果并识别出合适对联,思路马上来:获得网页源码 + 正则提取,先试下 request库 直接请求URL:
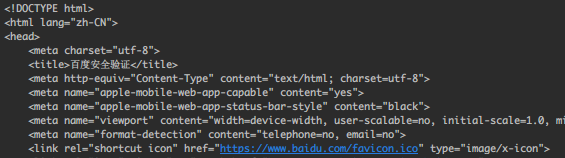
情理之中,直接触发了 百度安全验证,那就浏览器模拟访问吧。直接 Puppeteer库 走一波,这库之前介绍过了:
Puppeteer 是Google官方出品的通过DevTools协议口控制headless Chrome的 NodeJS 库,通过其提供的API可直接控制Chrome模拟大部分用户操作,来进行UI Test、爬虫访问页面采集数据。而 Pyppeteer 则是Puppeteer的Python实现,背后也是依赖类似于Chrome的浏览器 → Chromium 来模拟。
直接写代码拿到网页源码:

运行下看看:

可以,成功拿到网页源码,接着就是思考如何 写正则 了,直接写出最粗暴的匹配表达式 (应该能看懂吧~):
# 上联 → 要么是中英文逗号中的一个,要么没有 → 中文{上联的长度}match_pattern = re.compile(r"{}[,,]?([\u4e00-\u9fa5]{{{count}}})".format(first_couplet, count=len(first_couplet)), re.S)
匹配下试试,同时把结果放到set中间接 去重:
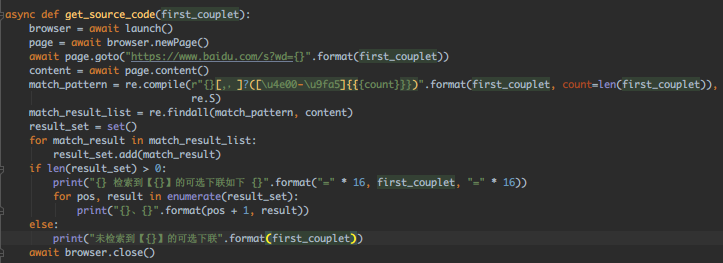
运行看看:

效果很赞,再往下细化就是:遍历 部分下联+可选词,然后计算每个下联中出现这些字的比重(个数),最高的那个就是 "正确答案" 啦!

搜索引擎这Part就到这,接着试试 ChatGPT ~
② ChatGPT API
ChatGPT就不用介绍了,前阵子火得一塌糊涂,注册方法可以看我之前写的《无聊试试最近很火的ChatGPT (附:注册方法)》,或者某宝直接买别人注册好的。
这里不需要像百度搜索一样通过浏览器访问,因为它提供了API,注册完账号,登录后打开 API keys,点击 Create new secret key,创建一个秘钥:
注意,这个Secret Key要自己存好!网站不提供后续查看,忘记了的话只能删掉重新创建。先pip装下库:
pip install openai# 如果很慢的话,可以用清华镜像源# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openai
直接copy样例:
import openaistart_sequence = "\nA:"restart_sequence = "Q: "# Replace `<your_api_key>` with your actual OpenAI API keyopenai.api_key = "<your_api_key>"prompt = " "while len(prompt) != 0:# Ask a questionprompt = input(restart_sequence)# prompt = "tell me in Chinese:" + input("\n请输入要翻译的内容:")# Get my answerresponse = openai.Completion.create(engine="text-davinci-003",prompt=prompt,temperature=1,max_tokens=2000,frequency_penalty=0,presence_penalty=0)# Print my answerprint(start_sequence, response["choices"][0]["text"].strip())
运行,尝试提问:

这啥?AI自己乱编?调整话术再次试探:
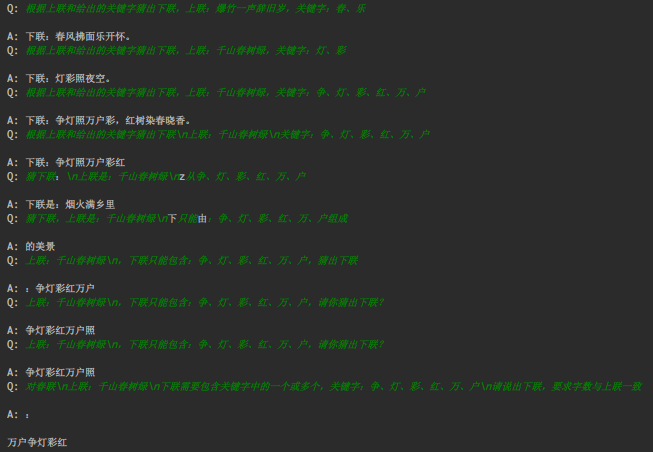
啊,这...我多嘴问了两句:

牛,直接把我整无语了,可能我需要学习下《提问的艺术》吧,看来ChatGPT的创造性不太适合我们的业务场景...

附:几个基本参数的含义
- model → 要使用的模型的 ID,访问 OpenAI Docs Models 页面可以查看全部可用的模型
- prompt → 生成结果的提示文本,即你想要得到的内容描述
- max_tokens → 生成结果时的最大 tokens 数,不能超过模型的上下文长度,可以把结果内容复制到 OpenAI Tokenizer 来了解 tokens 的计数方式
- temperature → 控制结果的随机性,如果希望结果更有创意可以尝试 0.9,或者希望有固定结果可以尝试 0.0
- top_p → 一个可用于代替 temperature 的参数,对应机器学习中 nucleus sampling,如果设置 0.1 意味着只考虑构成前 10% 概率质量的 tokens
- frequency_penalty → -2.0 ~ 2.0 之间的数字,正值会根据新 tokens 在文本中的现有频率对其进行惩罚,从而降低模型逐字重复同一行的可能性
- presence_penalty → -2.0 ~ 2.0 之间的数字,正值会根据到目前为止是否出现在文本中来惩罚新 - tokens,从而增加模型谈论新主题的可能性
- stop → 最大长度为 4 的字符串列表,一旦生成的 tokens 包含其中的内容,将停止生成并返回结果
③ 题库
问答类游戏,基本都是有题库的,玩了几局发现 重复率还挺高,说明规模不大 (估计30条左右)。然后,这模式随时可以玩,非实时 (所有玩家同时参与),试了下断网还能下一题,猜测是提前把题库下到本地,然后随机抽取生成问题。
综上,很大概率就是本地计算最后提交成绩,如果能 拿到提交成绩的接口,还对个屁春联,直接跳过答题环节。
只可惜,杰哥过年没带 "开发鸡" 回家,抓不了包,同理,没办法抓到题库。
没法直接获取,就只能自己 手动采集 了,自己玩,配合 搜索引擎,把做过的题目记下来。

在记的时候,杰哥又想到了一个 "骚操作",其实只需要关注 上联的第一个字 + 备选词 就可以猜到下联了。直接写出代码:

比如识别到"爆"字,直接输出下联:

接着就是把 下联和备选词 也抠出来了,计算出现的比重(次数),最高的就是正确的下联。同样写出代码:

试验下这三个样本:

运行输出结果如下:
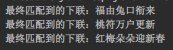
牛批,此处应有掌声!!!

当然,优化空间还有很多,比如将要识别的文字都拼接到一张图再识别,减少识别次数也会快上不少~
0x3、自动答题
滑动的话,adb模拟滑动即可,直接给出工具代码:
def swipe(start_x, start_y, end_x, end_y):"""滑动,从起始坐标点滑动到终点坐标:param start_x: 起始坐标点x坐标:param start_y: 起始坐标点y坐标:param end_x: 终点坐标点x坐标:param end_y: 终点坐标点y坐标:return:"""return start_cmd('adb shell input swipe %d %d %d %d' % (start_x, start_y, end_x, end_y))
起始坐标,OCR那里能拿到,剩下的难点就是拿到 放置框的坐标,这个也不难,最简单的方法就是:
手动抠坐标点写,死几个组合,根据上联确定是几个字的组合(五六七),然后判断备选词对应第几个字,直接拿到坐标。
当然也可以搞得复杂点,动态计算,先找个合适的阈值二值化图片 (如130):

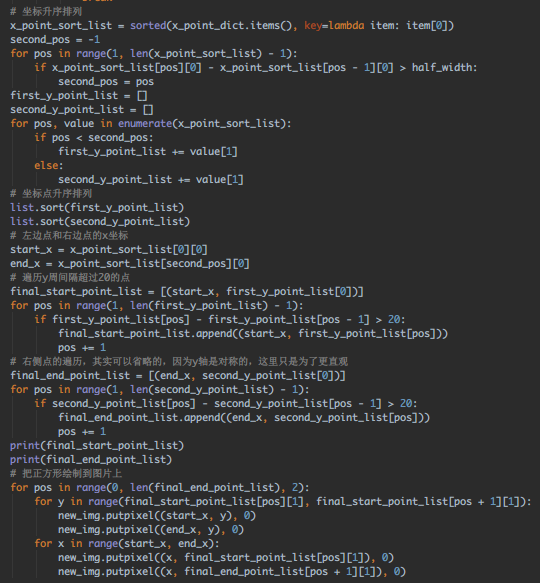
然后就是 水平和竖直方向遍历坐标点,找到闭合的正方形,直接写出遍历代码 (顺带画出来更直观):
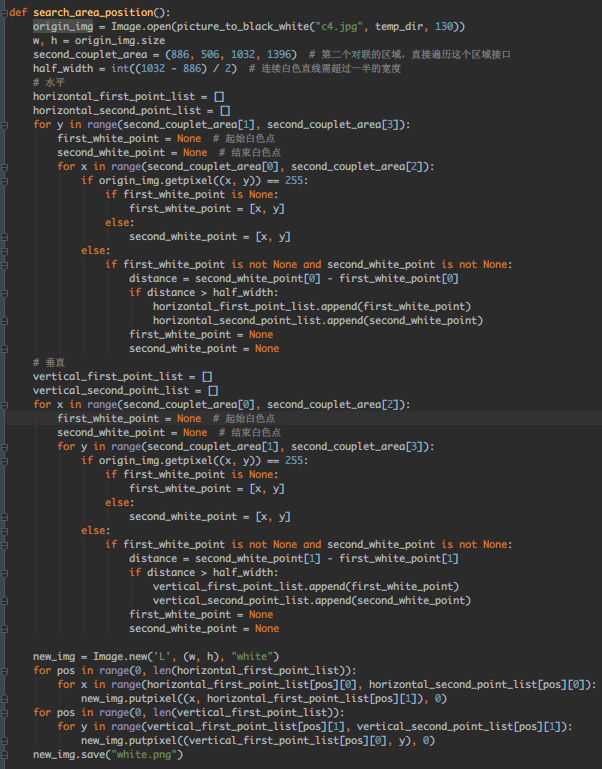
运行看下效果:
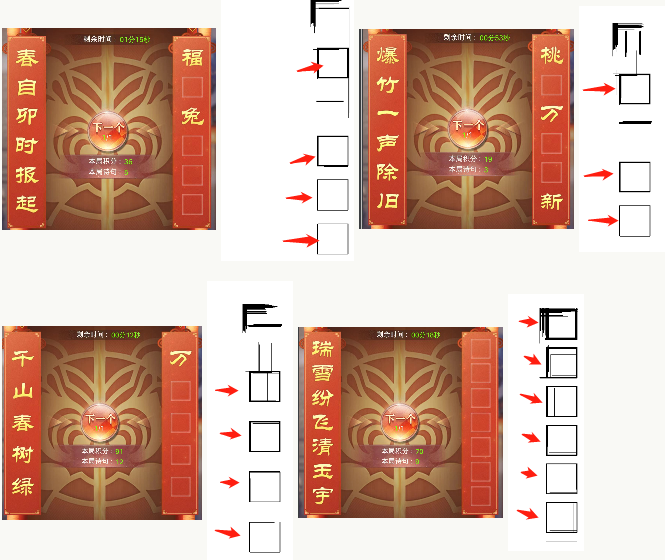
基本能看到矩形的雏形了,不过得干掉其它的干扰像素点,正方形的四个角 一定是水平和竖直方向相交的点:
处理后:

左边坐标点和有点坐标点肯定是对称的,处理下:

处理后:
可以,但还有瑕疵,把图片放大:

还得再处理下,去掉粘连的点,因为我们 只需要一个:
运行后可以看到要填 四个字的八个坐标点了,

同时也可以看到绘制出来的四个正方形:

同样试下其它几个样本:

牛逼,完美识别。拿到放置框的坐标,接着算出中心点,调用上面adb滑动的工具方法传参即可~

当然,动态计算这部分 并不优雅 甚至可以说有些 粗暴 了,用了很多集合和无脑遍历,但时间仓促,能用就行。
本来想录个自动对春联的视频 显摆显摆,可惜活动下架了,那只能靠各位读者自行脑补啦~
行吧,本节就到这,如果对你学习Android自动化有所帮助,欢迎三连,感谢~
参考文献:
