@coder-pig
2018-04-02T03:54:53.000000Z
字数 7581
阅读 2662
小猪的Python学习之旅 —— 7.Python并发之threading模块(1)
Python
引言:
从本节开始的连续几节我们都会围绕着Python并发进行学习,
本节学习的是 threading 这个线程相关模块,附上官方文档:
https://docs.python.org/3/library/threading.html
跟官方文档走最稳健,网上的文章都是某一时期的产物,IT更新
换代那么快,过了一段时间可能就改得面目全非了,然后你看了
小猪现在的文章然后写代码,这不行那不行就开始喷起我来了,我表示

另外,在查阅相关资料的时候发现很多文章还是用的 thread模块,
在高版本中已经使用threading来替代thread了!!!如果你在
Python 2.x版本想使用threading的话,可以使用dummy_threading
话不多说开始本节内容~
1.threaing模块提供的可直接调用函数
- active_count():获取当前活跃(alive)线程的个数;
- current_thread():获取当前的线程对象;
- get_ident():返回当前线程的索引,一个非零的整数;(3.3新增)
- enumerate():获取当前所有活跃线程的列表;
- main_thread():返回主线程对象,(3.4新增);
- settrace(func):设置一个回调函数,在run()执行之前被调用;
- setprofile(func):设置一个回调函数,在run()执行完毕之后调用;
- stack_size():返回创建新线程时使用的线程堆栈大小;
- threading.TIMEOUT_MAX:堵塞线程时间最大值,超过这个值会栈溢出!
2.线程局部变量(Thread-Local Data)
先说个知识点:
在一个进程内所有的线程共享进程的全局变量,线程间共享数据很方便
但是每个线程都可以随意修改全局变量,可能会引起线程安全问题,
这个时候,可以对全局变量进行加锁来解决。对于线程私有数据可以
通过使用局部变量,只有线程自身可以访问,其他线程无法访问,
除此之外,Python还给我们提供了ThreadLocal变量,本身是一个全局
变量,但是线程们却可以使用它来保存私有数据。
用法也很简单,定义一个全局变量:data = thread.local(),然后就可以
往里面存数据啦,比如data.num = xxx,写个简单例子来验证下:
注:如果data没有设置对应的属性,直接取会报AttributeError异常,
使用时可以捕获这个异常,或者先调用hasattr(对象,属性)判断对象中
是否有该属性!

输出结果:

厉害了,不同线程访问果然是返回的不同值,小猪这种求知欲
旺盛的人肯定是要扒一波看看是怎么实现的啦,跟源码会比较
枯燥,先简单说下实现套路:
threading.local()实例化一个全局对象,这个全局对象里有
一个大字典,键值为两个弱引用对象 {线程对象,字典对象},
然后可以通过current_thread()获得当前的线程对象,然后根据
这个对象可以拿到对应的字典对象,然后进行参数的读或者写。
是的大概套路就是这样,接下来就是剖析源码环节了,挺枯燥的,
可以不看,看的话,相信你会收获非常多,小猪昨天下午开始看
_threading_local.py这个模块的源码,仅仅246行,却看到了晚上
十点才舍得回家,收益颇丰,Get了N多知识点,至少在那些什么
Python教程里没看到过,每弄懂一个都会忍不出发出:

这样的感叹!快上老司机小猪的车吧,上车只需五个滑稽币:
*3._threading_local源码解析
按住ctrl点local()方法,会进到threading.py模块,会定位到这一行:
_thread 模块上节也说了threading模块的基础模块,应该尽量使用
threading 模块替代,而我们代码里也没导入这个模块,所以会走
_threading_local ,点进去看下这个模块,246行代码,不多,嘿嘿,
点击PyCharm左侧的Structure看看代码结构

关注点在_localimpl和local两个类上,我们先把这个模块的源码
全选,然后新建一个Python文件,把内容粘贴到里面,为什么要
这样做呢?
答:因为这样方便我们进行代码执行跟踪啊,Debug调试
或打Log跟踪方法运行顺序,或者查看某个时刻某些变量的值!
很多小伙伴可能只会print不会使用Debug调试,这里顺道简单
介绍下怎么用,掌握这个对跟源码非常有用,务必掌握!!!
1.PyCharm调试速成
点击左侧边栏可以下断点,在调试模式下运行的话,运行到
这一行的时候会暂时挂起,并激活调试器窗口:
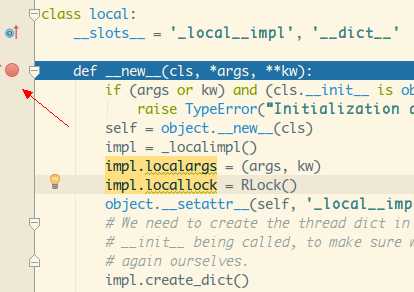
点击顶部的小虫子标记即可进入调试模式:
运行到我们埋下断点的这一行后,就会挂起并激活下面这个
调试器窗口:
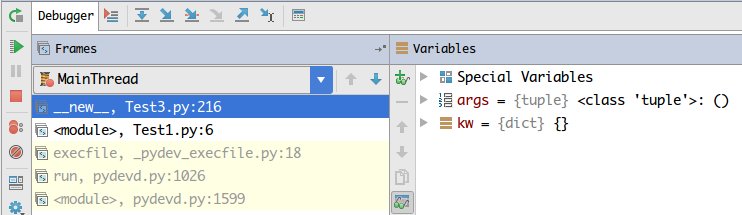
MainThread这个表示当前断点上的线程,下面是该线程的堆栈帧
右侧Variables是变量调试窗口,可以查看此时的变量情况!
接着就来一一说下一些调试技巧吧:
单步调试, ,Step Over(F8),程序向下执行一行,如果该行
,Step Over(F8),程序向下执行一行,如果该行
函数被调用,直接执行完返回,然后执行下一行;
当单步调试执行到某一个函数,如果你不想直接运行完,切到下
一行而是想看进去这个函数的运行过程的话,可以点击
 Step Into(F7) ;
Step Into(F7) ;
上面这一步,遇到官方类库的函数也会进去,如果只想在碰到
自己定义函数才进去的话,可以点击
 Step Into My Code(Alt + Shift + F7)
Step Into My Code(Alt + Shift + F7)
进入函数后确定没什么问题了,可以点击  Step Out(Shift + F8)
Step Out(Shift + F8)
跳出这个函数,返回该函数被调用处的下一行语句。
如果想快速执行到下一个断点的位置,可以点击
 Run to Cursor(Alt + F9)
Run to Cursor(Alt + F9)
跨断点调试,点击左侧栏的: ,直接跳过当前断点,
,直接跳过当前断点,
进入下一个断点。
监视变量,有时右侧Variables,显示的变量有很多时,而你
想关注某一个变量而已,可以点击这个小眼镜: ,然后
,然后
输入你想监视的变量名,如果名字太长或者懒,可以直接右键
变量,Add To Watches即可!不想监视时可右键Remove Watch。
停止调试,点击左侧红色按钮即可跳过调试,不是停止程序!:
断点设置,点击左侧: ,可以打开断点设置窗口,可以在此
,可以打开断点设置窗口,可以在此
看到所有的断点,设置条件断点(满足某个条件时,暂停程序执行),
删除断点,或者临时禁用断点等。
好的,关于PyCharm调试就先说这么多,基本够用了,
回到我们的源码,我们使用了threading.local()初始化了实例,
按照我们第一节学的类内容,类会走构造函数__init__()对吧?
然而,在local类里,并没有发现这个函数,只有一个__new__(cls, *args, **kw),
这又是一个新的知识点了!
2.Python中的经典类和新式类
在Python 2.x中默认都是经典类,除非显式继承object才是新式类;
而在Python 3.x中默认都是新式类,不用显式继承object;
新式类相比经典类增加了很多内置属性,比如__class__
获得自身类型(type),__slots__内置属性,还有这里的
__new__()函数等。
3.__new__() 函数
在调用__init__()方法前,__new__(cls, *args, **kw)可决定是否使用该
__init__()方法,可以调用其他类的构造方法或者直接返回别的对象
来作为本类的实例。cls表示需要实例化的类,该参数在实例化时由
Python解释器自动提供。另外还要注意一点,__new__必须有返回值,
可以返回父类__new__()出来的实例 或 object的__new__()出来的实例
如果new()没有成功返回cls类型的对象,是不会调用__init__()
来对对象进行初始化的!!!
卧槽,骚气,代码里也刚好这样做了,返回的是一个_localimpl()对象:

直接实例化的_localimpl(),然后设置了localargs,locallock
以及调用了create_dict()方法。先定位到_localimpl类的localargs

又触发新知识点:黑魔法__slots__
4.Python黑魔法__slots__内置属性
作用是阻止在实例化类时为实例分配dict,使用这个东西会带来:
更快的属性访问速度 和 减少内存消耗。此话怎么说?
默认情况下,Python的类实例都会有一个__dict__来存储实例的属性,
注意:只保存实例的变量,不会保存类属性!!!
可以调用内置属性__dict__进行访问,比如下面的例子:

输出结果:

看上去是挺灵活的,在程序里可以随意设置新属性,只是每次
实例化类对象的时候,都需要去分配一个新的dict,如果是对于
拥有固定属性的class来说,这就有点浪费内存了,特别是在需要
创建大量实例的时候,这个问题就尤为突出了。Python在新式类中给
我们提供了__slots__属性来帮助我们解决这个问题。
__slots__是一个元组,包括了当前能访问到的属性,定义后
slots中定义的变量变成了类的描述符,相当于java里的成员变量
声明,不能再增加新的变量。还有一点要注意:
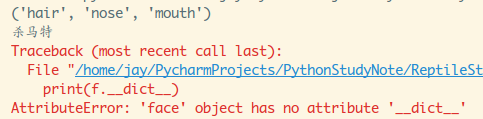
定义定义了__slots__后,就不再有__dict__!!!可以写个例子验证下:

输出结果:
Python内置的dict(字典) 本质是一个哈希表,通过空间换时间,
在实例化对象达到万级,和__slots__用元组对比耗费的内存就不是
一点半点了!另外属性访问速度也是比dict快的,相关对比以及
更多内容可见:https://www.cnblogs.com/rainfd/p/slots.html
和:Saving 9 GB of RAM with Python’s __slots__
了解完__slots__后,我们回到我们的源码,回到_localimpl的__init__()

设置了一个key,规则是:_threading_local._localimpl. 拼接上对象所在的内存地址
这里的id()函数作用是获得对象的内存地址。接着初始化了一个dicts,大词典,
拿来存放键值对的:(弱引用的线程对象,该线程在_localimpl对象里对应的数据字典)
就是每个线程对象,对应_localimp里不同的字典对象,这些字典对象都放在
大字典里。
接着回到local类的__new__() 函数,这里是一个设置属性的方法:

_local__impl属性在上面通过__slots__定义了

简单点理解就是为local设置了一个_localimpl对象,后面
可以根据根据这个name = _local__impl拿到对应的_localimpl对象!
而且这里没那么简单,local类里对这个函数进行了重写:

这里前面判断name是否为dict,猜测是权限控制,不允许
外部通过__setattr__或__delattr__来操作字典,只允许通过
_patch()方法来修改操作字典!
接着继续来跟下_patch()方法:

@contextmanager 又是什么东西???

又是新的知识点~
5.@contextmanager
这就涉及到我们以前学习的with结构了,在爬虫写入文件那里用过,
不用自己写finally,然后在里面去close()文件,以避免不必要的错误,
不知道你还记不记得,不记得的话回头翻翻吧。
对于类似于文件关闭这种不想遗忘的重要操作,我们可以自己封装
一个with结构来进行处理,封装也很简单,再定义你那个类的时候
重写__enter__方法和__exit__方法,比如文件关闭那个可以自定义
成这样的:
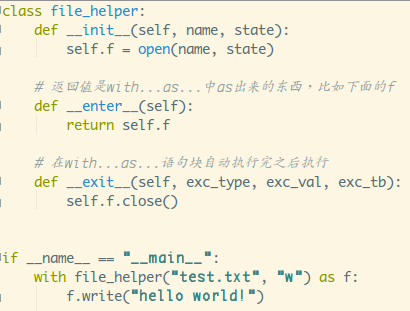
如果觉得上面这种实现起来比较麻烦的话,就可以用
@contextmanager啦,直接就一个方法,比定义类简单多了~
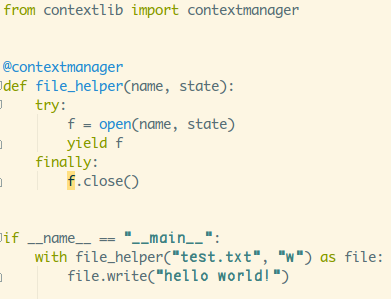
知道@contextmanager之后,继续来分析_patch()方法,先根据
_local__impl这个值拿到了local里的_localimpl对象,然后
调用impl的get_dict()想获得一个数据字典:

current_thread()获得当前线程,然后获得线程的内存地址,查找dicts里
此线程对应的字典,此时,如果dicts里没有这个线程对应的数据字典,
会引发KeyError异常,执行:
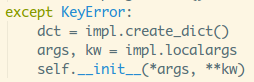
调用create_dict()方法创建字典:

创建空字典,设置key,获得当前线程,获得当前线程的内存地址;
就是做一些准备工作,接着看到定义了两个方法,先跳过,往下看:

然后又是新的知识点:Python弱引用函数ref()!
6.Python弱引用函数ref()
ref()这个函数是weakref模块 提供的用于创建一个弱引用的函数,
参数异常是想建立弱引用的对象,当弱引用的对象被删除后的回调函数
为什么要用弱引用?
Python和其他高级语言一样,使用垃圾回收器来自动销毁不再使用的对象,
每个对象都有一个引用计数,当这个计数为0时,Python才能够安全地销毁
这个对象,当对象只剩下弱引用时也会回收!
这里的local_deleted()和thread_deleted() 这两个回调参数
就是在_localimpl对象和线程对象被回收时触发:

localimpl对象被回收时把线程里持有localimpl对象的弱引用删除掉,
线程对象对象被回收时,弹出大字典中该线程对应的数据字典;
剩下的三句就是保存_localimpl对象的弱引用到thread的__dict__里,
localimpl对象添加键值对(线程弱引用,线程对应的数据字典)到
大字典中,然后返回线程对应的数据字典。
又回到_patch()方法,拿到参数,然后又调用__init__函数
然后调用了__init__函数,这里不是很明白动机,猜测是如果
另外重写了local的__init__函数,可以调用一些其他的操作吧。
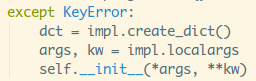
再接着又有一个知识点了,操作数据字典时的加锁,正常来说
私用Lock或RLock,需要自己去调用acquire()和release(),
而使用with关键字,就无需你自己去操心了,原因是RLock
类里重写了__enter__和__exit__函数。

最后yield返回一个生成器对象。
到此,_threading_local模块的完整的源码实现套路就浮出水面了,
不错,Get了很多新的姿势,如果你还有些疑惑的话,可以自己Debug,
跟跟方法的调用顺序,慢慢体会。
4.线程对象(threading.Thread)
使用threading.Thread创建线程:
可以通过下面两种方法创建新线程:
- 1.直接创建threading.Thread对象,并把调用对象作为参数传入;
- 2.继承threading.Thread类,重写run()方法;
这里写代码测试个东西:到底使用多线程快还是单线程快~

两次运行结果采集:

测试环境:Ubuntu 14.04 为了尽量公平,把单线程运行那个也另外放到
一个线程中,结果发现,多线程并没有比单线程快,反而还慢了一些。
出现这个原因是以为Python中的:全局解释器锁(GIL),上一节已经
介绍过了,这里就不再复述了。
Thread类构造函数

参数依次是:
- group:线程组
- target:要执行的函数
- name:线程名字
- args/kwargs:要传入的函数的参数
- daemon:是否为守护线程
相关属性与函数:
- start():启动线程,只能调用一次;
- run():线程执行的操作,可继承Thread重写,参数可从args和kwargs获取;
- join([timeout]):堵塞调用线程,直到被调用线程运行结束或超时;如果
没设置超时时间会一直堵塞到被调用线程结束。 - name/getName():获得线程名;
- setName():设置线程名;
- ident:线程是已经启动,未启动会返回一个非零整数;
- is_alive():判断是否在运行,启动后,终止前;
- daemon/isDaemon():线程是否为守护线程;
- setDaemon():设置线程为守护线程;
3.Lock(指令锁)与RLock(可重入锁)
上节就说过了,多个线程并发地去访问临界资源可能会引起线程同步
安全问题,这里写个简单的例子,多线程写入同一个文件:

打开test.txt,发现结果并没有按照我们预想的1-20那样顺序打印,而是乱的。

在threading模块中提供了两个类来确保多线程共享资源的访问:
Lock 和 RLock
Lock:指令锁,有两种状态(锁定与非锁定),以及两个基本函数:
使用acquire()设置为locked状态,使用release()设置为unlocked状态。
acquire()有两个可选参数:blocking=True:是否堵塞当前线程等待;
timeout=None:堵塞等待时间。如果成功获得lock,acquire返回True,
否则返回False,超时也是返回False。
使用起来也很简单,在访问共享资源的地方acquire一下,用完release就好:

这里把循环次数改成了100,test.txt中写入顺序也是正确的,有效~
另外需要注意:如果锁的状态是unlocked,此时调用release会
抛出RuntimeError异常!
RLock:可重入锁,和Lock类似,但RLock却可以被同一个线程请求多次!
比如在一个线程里调用Lock对象的acquire方法两次:

你会发现程序卡住不动,因为已经发生了死锁...但是在都在同一个主线程里,
这样不就很搞笑吗?这个时候就可以引入RLock了,使用RLock编写一样代码:
 输出结果:
输出结果:
并没有出现Lock那样死锁的情况,但是要注意使用RLock,acquire与release需要
成对出现,就是有多少个acquire,就要有多少个release,才能真正释放锁!
有点意思,点进去看看源码是怎么实现的,显示acquire方法:

如果调用acquire方法是同一线程的话,计数器_count加1;在看下release:
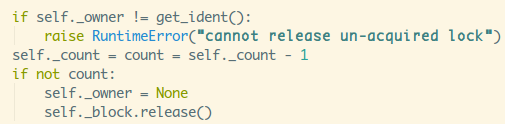
哈哈,一样的套路,_count减1。
小结
本节我们开始来啃Python并发里的threading,在学习线程局部变量的时候,
顺道把模块源码撸了一遍,而且还Get了很多以前没学过的东西,开森,
本节要消化的内容已经挺多的了,就先写那么多吧~

参考文献:
来啊,Py交易啊
想加群一起学习Py的可以加下,智障机器人小Pig,验证信息里包含:
Python,python,py,Py,加群,交易,屁眼 中的一个关键词即可通过;

验证通过后回复 加群 即可获得加群链接(不要把机器人玩坏了!!!)~~~
欢迎各种像我一样的Py初学者,Py大神加入,一起愉快地交流学♂习,van♂转py。

