@mShuaiZhao
2018-01-30T04:54:19.000000Z
字数 6204
阅读 1482
计算机体系结构论文阅读
2018.01 ComputerArchitecture
2017_ISCA_SCNN
SCNN:An Accelerator for Compressed-sparse Convolutional Neural Networks
Abstract
这篇论文提出了一种稀疏CNN(SCNN)加速结构,通过利用值为零的网络权重和值为零的网络激活函数值来提升网络的性能。
SCNN实现了一种新的dataflow来对稀疏权重和稀疏激活函数值进行编码,消除了不必要的数据转换并减少了存储开销。
1. Introduction
论文的背景是深度学习的火热,以及CNNs在很多复杂问题上的优秀表现,诸如图像识别,语音处理,自然语言处理,语言翻译,以及自动驾驶等等。
CNNs网络的使用可以分为两个步骤
训练(training)
通过大量的数据样本来进行训练,网络的参数在这个过程中进行迭代更新。
推断(Inference)
模型被付诸实用并对观察到的数据给出判断结果
CNNs网络中有两个问题
网络中有大量的冗余参数
可以消除这些冗余参数,但最后并不影响系统的性能
从以后的经验来看,网络中的激活函数值50%~70%都为0.
在网络的推断过程中,和权重相关的乘法和求激活函数的值是主要的运算开销。
2. Motivation
CNNs网络结构的稀疏性
CNNs网络中单层的稀疏性可以定义为这层的权重矩阵和输入矩阵中为零的值的数目的占比,占比越大越稀疏。
相对的概念是网络的稠密性,这是与稀疏性相对的概念。
GoogLeNet中有些层有些层的稠密度只有30%左右。
参考文献[17]提出了一种剪枝算法(prune),第一,讲绝对值接近0的权重置为0;第二步,重新训练网络,保证网络的精度。
最后得到一个小很多的网络,但是在性能上与原网络极为接近。利用网络稀疏性
两个方向
压缩数据
0数据其实是没有意义的。
减少运算数目
同上,用0数据进行运算是没有意义的
SCNN同时利用了权重和网络激活函数值的稀疏性,并使用了一种原创性的笛卡尔积dataflow。
3. SCNN
一般的卷积操作是一个7层的循环
CNNs网络中最重要的运算就是卷积运算。
一个CNN的dataflow定义了这些循环的顺序、划分结构和并行结构。
在一个CNN的架构中,dataflow的选择可能是最具意义最重要的环节。
这篇paper提出了一种叫做PlanarTiled-InputStationaryCartesianProduct-sparse, or PT-IS-CP-sparse的dataflow。
3.1 The PT-IS-CP-dense Dataflow
Single-multiplier temporal dataflow.
IS(input-stationary)指的是输入的计算顺序不变。所有的输入对输出的每一个通道都相关。
更改了loop的嵌套顺序
将K个输出通道划分为个group
Intra-PE parallelism
利用笛卡尔积的形式(CP)实现空间并行。
Inter-PE parallelism
大小的activation plane被划分为 大小
Each tile extends fully into the input-channel dimension C, resulting in an input-activation volume of assigned to each PE.
因为有卷积的存在(cross-tile),这样的划分并不是很合理的。
data halos,两个解决方案
Input halos
将每个PE的input size buffer设计得比大一些。
output halos
将每个PE的输出累加器的buffer设计得比大一些。自后多个PE进行通信完成最后的累加。
3.2 The PT-IS-CP-sparse Dataflow
PT-IS-CP-sparse dataflow, 专为压缩后的稀疏权重和稀疏激活函数值设计。
对稀疏矩阵进行编码的主要目的是要得到一个非零值和它对应的索引。
输入的都是压缩后的非零的数据及其索引
输出就不一定了,任何位置都有可能出现非零值
为了适应这种稀疏结构,利用交叉开关(crossbar switch)实现一个scatter network,基于输出的索引来进行累加得到最后的输出值。
4. SCNN ACCELERATOR ARCHITECTURE
4.1 Tiled Architecture
平铺结构
每个PE有接受weights、input activations的通道和输出output activations的通道。
每个PE都和附近的PEs相连,以在卷积过程中交换halo value。
4.2 PE的结构
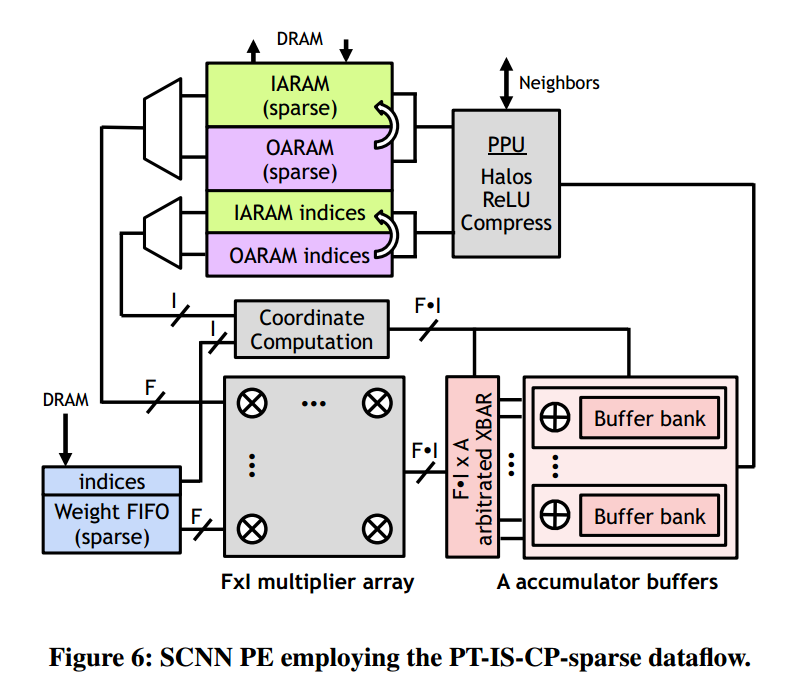
including a weight buffer, input/output activation RAMs (IARAM and
OARAM), a multiplier array, a scatter crossbar, a bank of accumulator buffers, and a post-processing unit (PPU).
Input weights and activations
输入的权重及其索引,输入的激活函数值及其索引,进入乘法阵列作笛卡尔积产生输出值,由输入权重索引和输入输入激活函数值索引计算得到输出索引。
累加
乘法阵列的值被输入到累加缓存中,根据输出的索引完成累加工作。
后期处理
后处理主要完成三个工作
完成对halo values的处理(相邻的PE交换部分和),得到最后的输出
作ReLU操作
压缩输出,并将其写入OARAM
压缩
压缩格式:索引向量的第一个值记录了非零值得数目,后面的数值表示对应的非零值之前的0的数目
4.3 全连接层
全连接层在现在使用的网络中占比很少
也可以将全连接层转化为卷积层
对卷积使用SCNN,对全连接层使用例如EIE等针对全连接层进行了优化的结构。
4.4 对较大模型的暂时性分割
权重和输入函数值太多,不能一次性装入IARAM和weight buffer。对层进行分割。
4.5 SCNN结构的配置
5. EVALUATION
有效的加速了网络的运行速度,减少了能量消耗,
2017_MICRO_Cambricon-X
Cambricon-X: An Accelerator for Sparse Neural Networks
0. 摘要
神经网络的火热,利用网络本身的稀疏性和不规律性。
1.Introduction
稀疏MLP
移除值为0的神经元。
有些时候并没有效,因为0值还是进行了运算。
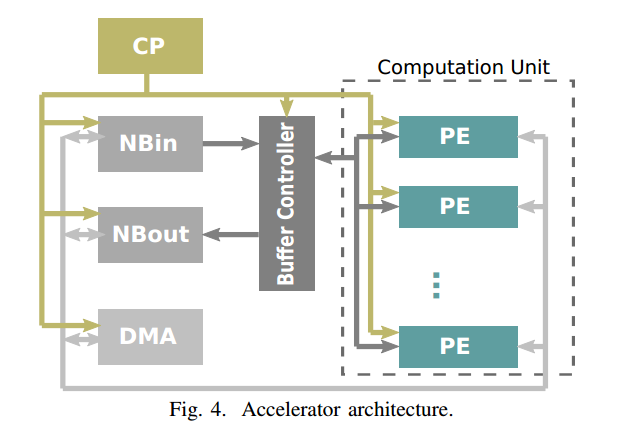
PE-based的结构
由多个PE及与其成对的缓存控制器(BC)组成
2.背景和动机
state-of-the-art的神经网络
稀疏神经网络的研究
本文中神经元指的就是网络的神经元,突触指的是连接神经元的边,就是权重。
motivation
缺少专门针对神经网络模型的稀疏结构和不规则性设计的专用器件。
之前的架构,如DianNao和DaDianNao,(1)是用0简单替代了被剪枝掉的突触,计算次数并没有减少,造成了计算资源的浪费;(2)是DianNao和DaDianNao的架构,并不能很好的适应网络的不规则结构。
3.加速器设计
3.1 总体架构
缓存控制器的架构
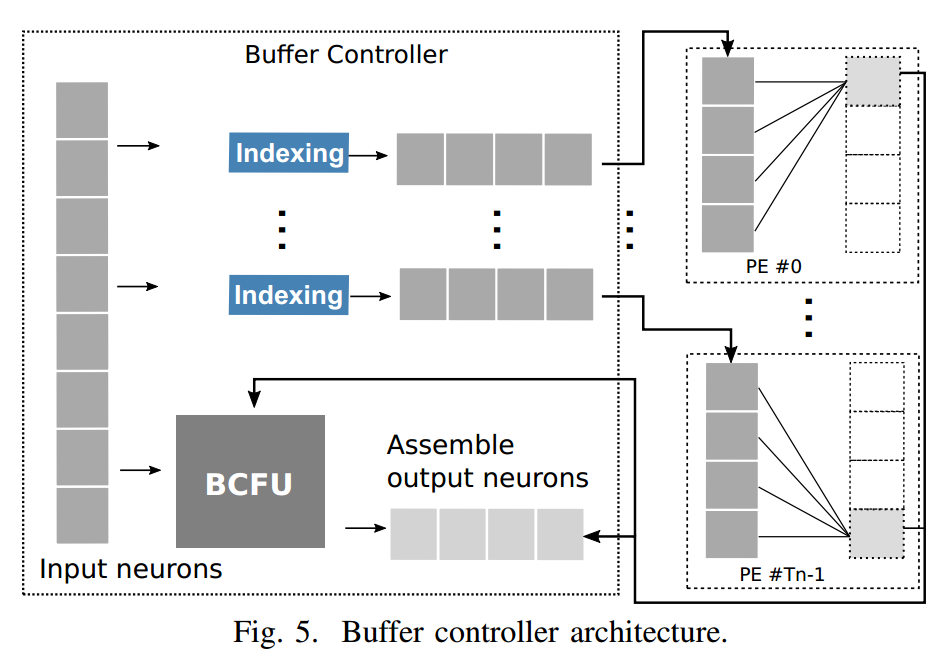
有个排序单元
使用的都是16位的定点运算单元
4. note
这篇文章看完也并没有什么感觉,可能拖的时间太长了,也可能是没有看懂。
这篇文章主要针对sparse neural network设计了一种加速器,取名为Cambricon-X。总体架构上并没有什么特别创新的地方,最创新的地方应该是针对sparse neural network设计的缓存控制器中,有一个专门设计的indexing单元,这个单元起到了压缩稀疏神经网络的作用,极大的减少了运算量。
还有一个特别之处在于使用了Fat-tree总线来连接所有的PE单元,有效避免了写阻塞。
由于Cambricon-X自身的并行设计,对于普通的dense neural network,也有较好的加速性能。
文章的出发点也是利用了sparse neural network自身的稀疏性,这是很多网络加速器的出发点,是一个值得研究的方向。很多工作都基于此展开。有后续研究的价值。
2016_ISCA_Cnvlutin
Cnvlutin: Ineffectual-Neuron-Free Deep Neural Network Computing
这篇文章怎么说呢,是基于DaDianNao加速器的一种改进,在DaDianNao加速器的基础上避免了0值的运算。
motivation
背景当然还是深度学习的火热,然后为了加速神经网络出来了很多的加速器架构。像DianNao,DaDianNao等等。
但是这些加速器,只是从并行计算的角度来考虑问题,并没有消除网络中的很多不必要的0值得运算。
这篇文章的作者注意到,现代的DNNs模型中,44%左右的运算都是有0值参与的运算,这是没有意义的,作者从此出发提出了一个叫做Cnvlutin的加速器架构。methodology
这篇文章加速的架构相对于DaDianNao而言,将并行计算的思想贯彻得更加彻底。
将单个filter的计算,都拆开来了。文章最主要的创新点在于,在NBin中,记录了非0值得神经元的offset这使得计算编码后的稀疏矩阵成为可能。依据设计好的结构,提出了对应的数据压缩的方法。
通过以上提升了模型的计算速度,减少了能量消耗。note
这篇文章的出发点还是从网络模型运算过程中产生的大量不必要的0值出发,设计了一种加速结构,这是较为热门的一个方向,也具有较大的研究价值。
2017_ISCA_Maximizing CNN Accelerator Efficiencey Through Resource Partitioning
motivation
背景呢还是深度学习的火热,卷积神经网络的大量应用。
这篇文章的motivation在于增大加速器的吞吐量。
卷积神经网络的计算过程中,如果不做一些特殊的分解或者优化,那么整个模型要完成的计算量其实是固定的。文章作者由此出发,最大化计算资源的利用,增大加速器的吞吐量,一次来实现对于模型的运算速度的加速。methodology
之前已经有convolutional layer processor(CLP)的相关工作,作者从之前的一个工作出发,分析了使用单个CLP器件的不足。
单个的CLP器件在做卷积运算时,会将原来的循环再切分为多个小的循环,以此来提高并行性,最后达到提高吞吐量的目的。但是神经网络模型中,每一层的参数和输入都是不同的,针对某层设计好的方案并不一定能在另外的层上取得很好的效果。
作者从这点出发,提出了使用多个CLP器件的方法,对每个layer都有一个CLP器件,有对应的优化后的并行方案。同时借鉴了流水线的思想,将每个CLP器件看成是一个segment,类似于流水线中的时钟周期,以此来最大化吞吐量。
作者还设计了一个动态的调度算法来寻找对于每个CLP最优的数据分配方案。note
在组成流水线时,每个segment的运算时间是不相等的,不知道作者是采取了什么样的措施来实现流水线的。
这篇文章设计加速器的思路与之前的文章并不相同,没有从减少计算量的角度出发,而是从增大加速器的吞吐量的角度出发,这是另外一种可行的思路非常具有启发性。
我认为可以和减少数据量的方法适当结合,或许有更好的效果。
2016_ISCA_Minerva
motivation
深度学习的火热,神经网络模型的广泛应用。
希望设计一种加速器架构,能够在实现加速的同时有效的减少能量的消耗。
methodology
以以往的加速器架构为基础,设计了一个非常完整的加速器架构。这个架构可以分为五个stage。
首先探索整个的训练空间,不同的超参数会产生不同的网络模型,这个阶段比较所有的模型并选择表现最好的那个。
第二个阶段完成主要的加速器架构的实现,在这个阶段,作者实现了多个数据通路(datapath)用于计算网络中单元的值,对于每个数据通路,又将其处理过程分为5个阶段,并采用了流水线技术来最大化吞吐量。
第三个阶段,作者最数据类型和结构进行了优化,不同于一般的用16位的定点数在保证精度的情况下提高运算速度的方法,作者探索了不同位长的定点数对模型最后表现的影响,平衡了运算速度和模型表现之后做出了选择。
第四个阶段,考虑到模型中很多运算都是0值相关的运算,这些是没有意义的,这个阶段作者对模型进行了动态剪枝,避免了0值运算。
最后一个阶段,作者为了避免在存取过程中可能出现的读写错误,又对数据做了校验和纠正处理。note
这篇文章是非常全面的,实验也非常可靠细致,考虑的问题也非常全面。无论是资源的最大化利用,还是对于稀疏模型的特性的利用,甚至于可能出现的数据错误,都作了考虑。是一篇价值较高的论文。很多思想也很有启发性,有较大的研究价值。
2016_ISCA_ISAAC
motivaion
深度学习的火热,设计神经网络专用的加速器。
methodology
作者首先设计了一个专用的矩阵乘法器件,这个矩阵乘法器件是一个忆阻器阵列,可以同时实现乘法运算和结果存储。
忆阻器阵列加上必要的存储器、输入输出缓存和ADC转换器、DAC转换器就可以了构成一个现场累加器(In-Situ Multiply Accumulate,IMA)。多个现场累加器(现场累加器阵列)和其他的一些器件,如池化单元、eDRAM缓存等构成了一个加速器单元。ISAAC利用多个这样的加速器单元构造了一个加速器。
ISAAC的优点在于它使用了忆阻器阵列来完成乘法运算,比常规的利用专门的乘法器来实现要快很多,而且也可以实现存储结果的作用,方便累加。
ISAAC高度应用了流水线,每个加速器单元都都应用了流水线,包括对于数据的读入和ADC转换操作。
除了以上的并行设计,在减少缓存开销方面,作者对网络的权重参数进行了编码;在计算方面,考虑到了符号的问题,设计了符号位。note
这篇文章也是基于DaDianNao结构的一篇文章,独特之处在于采用了一个忆阻器矩阵乘法器件,同时实现了计算和存储累加。高度并行化,但是并没有在数据的压缩方面做很多工作,还有可以做的工作。
