@mShuaiZhao
2018-02-02T03:12:15.000000Z
字数 1148
阅读 485
EAST
PaperReading ObjectDetection 2018.01
1. abstract
a single neural network
任意方向、四边形的words或text line
2. motivation
以前的方法多事multi-stage的,比较耗时。
包括一系列的步骤, region proposal, false positive removing, candidate aggregaion, line information 和 word partition等。
作者提出的方法只需要经过一个multi-channel的FCN, 然后作NMS就好。
3. methodology
总体的框架如下
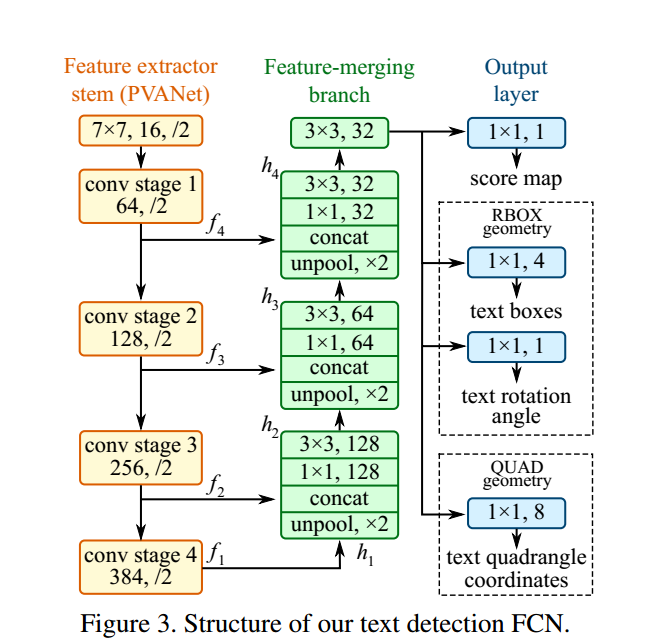
核心的思想还是不同尺度的feature的组合应用,因为word或者text line对象的大小并不确定且区别很大。
注意有一个unpool操作以保证维度相同。输出的设计
一种score map作为confidence
对于RBOX,4个channels预测对应point到text box四边的距离,一个channel预测旋转角度。
对于QUAD,8个channel预测每个点到图像四个顶点的偏移,有待考证代码。groundtruth的计算
groundtruth计算比较特殊的是作了一个shrink,为什么有待考证.
loss function的设计
对于score map,针对正负样本不平衡的问题,采取了class-balanced cross-entropy来解决这个问题。
对于bounding box
RBOX而言,采用了IoU loss。
QUAD而言,采用了改良的smoothed- loss.
4. Training
文章中采用的NMS并不是naive NMS,先按行进行NMS。这是为了减少计算量。
采用AdamOptimizer。
5. Experiment
感觉相较以前的state-of-the-art的方法,提升较大,过程也比较好理解。
6. Conclusion
文章最后说到,能够检测的文字的最大size是和网络的感受野相关的。
对于vertical text instance,也有可能出错。
curved text也是以后研究的一个点。
7. Note
这篇文章反复提到了word或者text line对象是一个尺度大小变化很大的对象,所以要组合网络模型中不同size的feature,作者的模型也是这样做的。从实验结果来看确实是很有道理的。
这篇paper的模型也说明了一个道理,只要给模型足够的信息(不同尺度的,但是只要保证信息的充足),神经网络模型就会达到你想要的一种映射。这是非常值得思考的。
