@mShuaiZhao
2018-03-11T10:01:30.000000Z
字数 21183
阅读 561
The Unix Workbench Week02
Coursera 2018.03
tutorial: https://www.coursera.org/learn/unix/supplement/9Dkik/self-help
1. Self-Help
自助查询,获取命令的帮助。
manuse (/) to start a search
Press the
nkey in order to search for the next occurrence of the word, and if you want to go to the previous occurrence typeShift + n. This method of searching also works with less.
When you’re finished looking at a man page typeqto get back to the prompt.
aproposYou can use apropos to search all of the available commands and their descriptions.
apropos editor## ed(1), red(1) - text editor## nano(1) - Nano's ANOther editor, an enhanced free Pico clone## sed(1) - stream editor## vim(1) - Vi IMproved, a programmers text editor
2. Get Wild
wildcard
通配符
A wildcard is a character that represents other characters, much like how joker in a deck of cards can represent other cards in the deck.
The * (“star”) wildcard represents zero or more of any character, and it can be used to match names of files and folders in the command line.
For example if I wanted to list all of the files in my Photos directory which have a name that starts with “2017” I could do the following:ls 2017*## 2017-01-02-hiking01.jpg## 2017-01-02-hiking02.jpg## 2017-02-10-hiking01.jpg## 2017-02-10-hiking02.jpg
Only the files starting with “2017” are listed! The command
ls 2017*literally means: list the files that start with “2017” followed by zero or more of any character.We could list only the files with names ending in .jpg:
ls 2016*## 2016-06-20-datasci01.png## 2016-06-20-datasci02.png## 2016-06-20-datasci03.png## 2016-06-21-lab01.jpg## 2016-06-21-lab02.jpg
In the case above the file name can start with a sequence of zero or more of any character, but the file name must end in .jpg. Or we could also list only the first photos from each set of photos:
ls *01.*## 2016-06-20-datasci01.png## 2016-06-21-lab01.jpg## 2017-01-02-hiking01.jpg## 2017-02-10-hiking01.jpg
Now we can move the photos using wildcards:
mv 2017-* 2017/ls## 2016## 2016-06-20-datasci01.png## 2016-06-20-datasci02.png## 2016-06-20-datasci03.png## 2016-06-21-lab01.jpg## 2016-06-21-lab02.jpg## 2017
3. Search
Regular Expression
bash shell
Bash treats different kinds of data differently, and we'll dive deeper into data types in Chapter 5.
For now all you need to know is that text data are called strings.
A string could be a word, a sentence, a book, or a file or folder name. One of the most effective ways to search through strings is to use regular expressions.
Regular expressions are strings that define patterns in other strings. You can use regular expressions to search for a sub-string contained within a larger string, or to replace one part of a string with another string.grepcommandOne of the most popular tools for searching through text files is grep. The simplest use of
greprequires two arguments: a regular expression and a text file to search.grep "x" states.txt## New Mexico## Texas
In the command above, the first argument to grep is the regular expression "x". The "x" regular expression represents one instance of the letter “x”. Every line of the states.txt file that contains at least one instance of the letter “x” is printed to the console.
Regular expressions are not limited to just being individual characters or words, they can also represent parts of words.
grep "nia" states.txt## California## Pennsylvania## Virginia## West Virginia
-v这个操作是取反,invert-match,寻找没有给出的字符的字符串。
metacharacters
元数据
Regular expressions aren't just limited to searching with characters and strings, the real power of regular expressions come from using metacharacters.
"
." (period)"
." (period) metacharacter, which represents any character
注意.也只能表示单个的characteregrep "i.g" states.txt## Virginia## Washington## West Virginia## Wyoming
The regular expression "i.g" matches the sub-string “irg” in Virginia, and West Virginia, and it matches the sub-string “ing” in Washington and Wyoming.
The period metacharacter is a stand-in for the “r” in “irg” and the “n” in “ing” in the example above.
The period metacharacter is extremely liberal, for example the command egrep "." states.txtwould return every line of states.txt since the regular expression "." would match one occurrence of any character on every line (there’s at least one character on every line).quantifiers
Besides characters that can represent other characters, there are also metacharacters called quantifiers which allow you to specify the number of times a particular regular expression should appear in a string.
+"
+" (plus) which represents one or more occurrences of the preceeding expression
For example the regular expression “s+as” means: one or more “s” followed by “as”. Let’s see if any of the state names match this expression:egrep "s+as" states.txt## Arkansas## Kansas
*"*" (star) metacharacter which represents zero or more occurrences of the preceding expression. Let’s see what happens if we change "s+as" to "s*as":
egrep "s*as" states.txt## Alaska## Arkansas## Kansas## Massachusetts## Nebraska## Texas## Washington
{}
You can use curly brackets ({ }) to specify an exact number of occurrences of an expression.
For example the regular expression "s{2}" specifies exactly two occurrences of the character “s”. Let’s try using this regular expression:egrep "s{2}" states.txt## Massachusetts## Mississippi## Missouri## Tennessee
Take note that the regular expression "s{2}" is equivalent to the regular expression "ss". We could also search for state names that have between two and three adjacent occurrences of the letter “s” with the regular expression "s{2,3}":
egrep "s{2,3}" states.txt## Massachusetts## Mississippi## Missouri## Tennessee
Of course the results are the same because there aren’t any states that have “s” repeated three times.
You can use a capturing group in order to search for multiple occurrences of a string.
You can create capturing groups within regular expressions by using parentheses ("( )"). For example if I wanted to search states.txt for the string “iss” occurring twice in a state name I could use a capturing group and a quantifier like so:egrep "(iss){2}" states.txt## Mississippi
We could combine more quantifiers and capturing groups to dream up even more complicated regular expressions. For example, the following regular expression describes three occurrences of an “i” followed by two of any character:
egrep "(i.{2}){3}" states.txt## Mississippi
character set
\wThe \w metacharacter corresponds to all “word” characters
\dthe \d metacharacter corresponds to all “number” characters
这个实验了存疑。sthe \s metacharacter corresponds to all “space” characters.
egrep "\w" small.txt## abcdefghijklmnopqrstuvwxyz## ABCDEFGHIJKLMNOPQRSTUVWXYZ## 0123456789## aa bb cc## rhythms## xyz## abc## tragedy + time = humor## http://www.jhsph.edu/egrep "\d" small.txt## 0123456789egrep "\s" small.txt## aa bb cc## tragedy + time = humor
As you can see in the example above, the
\wmetacharacter matches all letters, numbers, and even the underscore character (_).
注意是字符,数字和下划线。We can see the compliment of this grep by adding the -v flag to the command:
egrep -v "\w" small.txt## #%&-=***=-&%#
The
-vflag (which stands for invert match) makes grep return all of the lines not matched by the regular expression.
inverse match.不满足要求的项。补集。Note that the character sets for regular expressions also have their inverse sets: \W for non-words, \D for non-digits, and \S for non-spaces. Let’s take a look at using \W:
egrep "\W" small.txt## aa bb cc## tragedy + time = humor## http://www.jhsph.edu/## #%&-=***=-&%#
The returned strings all contain non-word characters. Note the difference between the results of using the invert flag -vversus using an inverse set regular expression.
[]In addition to general character sets we can also create specific character sets using square brackets ([ ]) and then including the characters we wish to match in the square brackets.
For example the regular expression for the set of vowels is [aeiou]. You can also create a regular expression for the compliment of a set by including a caret (
^) in the beginning of a set. For example the regular expression [^aeiou] matches all characters that are not vowels. Let’s test both on small.txt:egrep "[aeiou]" small.txt## abcdefghijklmnopqrstuvwxyz## aa bb cc## abc## tragedy + time = humor## http://www.jhsph.edu/
egrep "[^aeiou]" small.txt## abcdefghijklmnopqrstuvwxyz## ABCDEFGHIJKLMNOPQRSTUVWXYZ## 0123456789## aa bb cc## rhythms## xyz## abc## tragedy + time = humor## http://www.jhsph.edu/## #%&-=***=-&%#
Notice that the word “rhythms” does not appear in the result (it’s the longest word without any vowels that I could think of).
Every line in the file is printed, because every line contains at least one non-vowel!
-If you want to specify a range of characters you can use a hyphen (-) inside of the square brackets.
For example the regular expression [e-q] matches all of the lowercase letters between “e” and “q” in the alphabet inclusively. Case matters when you’re specifying character sets, so if you wanted to only match uppercase characters you’d need to use [E-Q].
To ignore the case of your match you could combine the character sets with the [e-qE-Q] regex (short for regular expression), or you could use the -i flag with grep to ignore the case. Note that the
-iflag will work for any provided regular expression, not just character sets. Let’s take a look at some examples using the regular expressions that we just described:egrep "[e-q]" small.txt## abcdefghijklmnopqrstuvwxyz## rhythms## tragedy + time = humor## http://www.jhsph.edu/egrep "[E-Q]" small.txt## ABCDEFGHIJKLMNOPQRSTUVWXYZegrep "[e-qE-Q]" small.txt## abcdefghijklmnopqrstuvwxyz## ABCDEFGHIJKLMNOPQRSTUVWXYZ## rhythms## tragedy + time = humor## http://www.jhsph.edu/
Escaping,Anchors,Odds,and Ends
Escaping
怎么搜索那些被用作正则表达式的字符呢?
One issue you may have thought about during our little exploration of regular expressions is how to search for certain punctuation marks in text considering that those same symbols are used as metacharacters!For example, how would you find a plus sign (+) in a line of text since the plus sign is also a metacharacter? The answer is simply using a backslash (\) before the plus sign in a regex, in order to “escape” the metacharacter functionality. Here are a few examples:
egrep "\+" small.txt## tragedy + time = humoregrep "\." small.txt## http://www.jhsph.edu/
anchor characters
There are three more metacharacters that we should discuss, and two of them come as a pair: the caret (^), which represents the start of a line, and the dollar sign ($) which represents the end of line.
These “anchor characters” only match the beginning and ends of lines when coupled with other regular expressions. For example, going back to looking at states.txt, I could search for all of the state names that begin with “M” with the following command:
egrep "^M" states.txt## Maine## Maryland## Massachusetts## Michigan## Minnesota## Mississippi## Missouri## Montana
There’s a mnemonic that I love for remembering which metacharacter to use for each anchor: "First you get the power, then you get the money."
The caret character is used for exponentiation in many programming languages, so "power" (^) is used for the beginning of a line and "money" ($) is used for the end of a line.管线
Finally, let’s talk about the "or" metacharacter (|), which is also called the “pipe” character. This metacharacter allows you to match either the regex on the right or on the left side of the pipe. Let’s take a look at a small example:egrep "North|South" states.txt## North Carolina## North Dakota## South Carolina## South Dakota
You can also use multiple pipe characters to, for example, search for lines that contain the words for all of the cardinal directions:
egrep "North|South|East|West" states.txt## North Carolina## North Dakota## South Carolina## South Dakota## West Virginia
Just two more notes on grep: you can display the line number that a match occurs on using the -n flag:
egrep -n "t$" states.txt## 7:Connecticut## 45:Vermont
And you can also grep multiple files at once by providing multiple file arguments:
egrep "New" states.txt canada.txt## states.txt:New Hampshire## states.txt:New Jersey## states.txt:New Mexico## states.txt:New York## canada.txt:Newfoundland and Labrador## canada.txt:New Brunswick
You now have the power to do some pretty complicated string searching using regular expressions! Imagine you wanted to search for all of the state names that both begin and end with a vowel. Now you can:
egrep "^[AEIOU]{1}.+[aeiou]{1}$" states.txt## Alabama## Alaska## Arizona## Idaho## Indiana## Iowa## Ohio## Oklahoma
搜索一个元音开头,元音结尾,中间至少有一个字符的字符串。
metacharacter简表
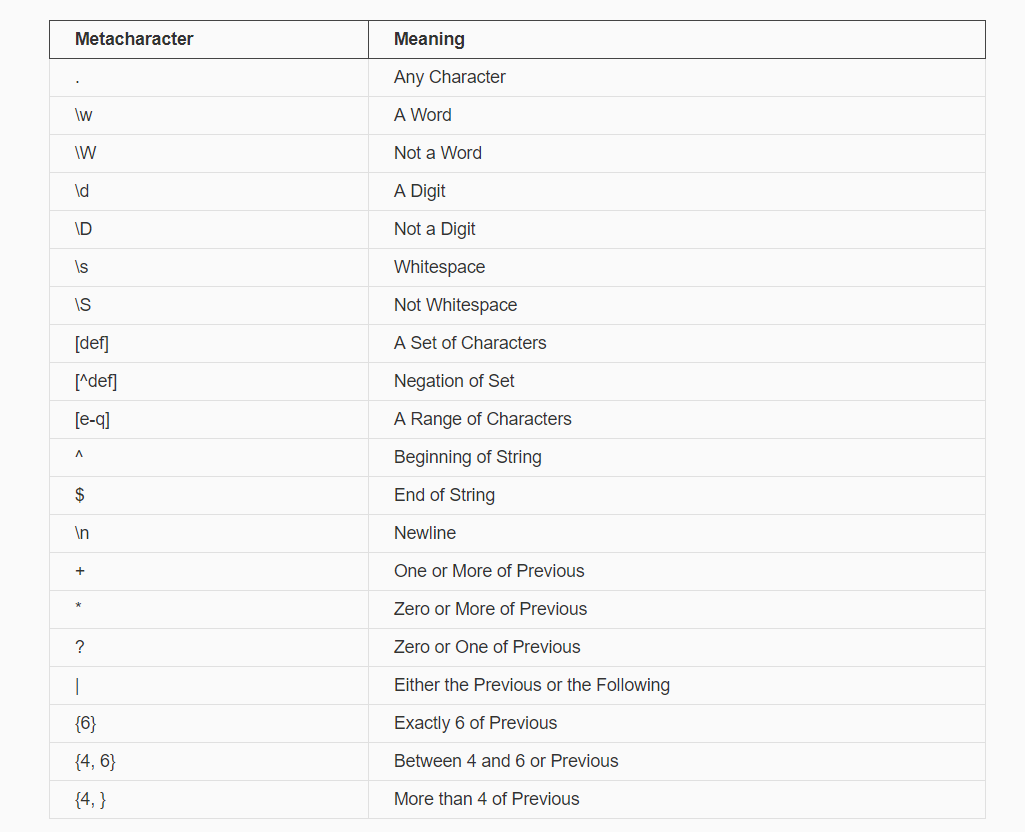
findIf you want to find the location of a file or the location of a group of files you can use the
findcommand.
This command has a specific structure where the first argument is the directory where you want to begin the search, and all directories contained within that directory will also be searched.
The first argument is then followed by a flag that describes the method you want to use to search. In this case we’ll only be searching for a file by its name, so we’ll use the-nameflag. The-nameflag itself then takes an argument, the name of the file that you’re looking for. Let’s go back to the home directory and look for some files from there:find . -name "*.jpg"## ./Photos/2016-06-21-lab01.jpg## ./Photos/2016-06-21-lab02.jpg## ./Photos/2017/2017-01-02-hiking01.jpg## ./Photos/2017/2017-01-02-hiking02.jpg## ./Photos/2017/2017-02-10-hiking01.jpg## ./Photos/2017/2017-02-10-hiking02.jpg
4. Configure
historyBash keeps track of all of your recent commands, and you can browse your command history two different ways.
The commands that we’ve used since opening our terminal can be accessed via the
historycommand.Whenever we close a terminal our recent commands are written to the ~/.bash_history file.
head -n 5 ~/.bash_history## echo "Hello World!"## pwd## cd## pwd## ls
Customizing Bash
Besides ~/.bash_history, another text file in our home directory that we should be aware of is ~/.bash_profile. The ~/.bash_profile is a list of Unix commands that are run every time we open our terminal, usually with a different command on every line.
One of the most common commands used in a ~/.bash_profile is the
aliascommand, which creates a shorter name for a command. Let’s take a look at a ~/.bash_profile:alias docs='cd ~/Documents'alias edbp='nano ~/.bash_profile'
注意也有可能是~/.bashrc文件。
. In order to make the changes to our ~/.bash_profile take effect we need to run
source ~/.bash_profilein the console.Differentiate
It’s important to be able to examine differences between files. First let’s make two small simple text files in the Documents directory.
比较文件间的差异。diffcd ~/Documentshead -n 4 states.txt > four.txthead -n 6 states.txt > six.txtdiff four.txt six.txt## 4a5,6## > California## > Colorado
sdiffsdiff four.txt six.txt## Alabama Alabama## Alaska Alaska## Arizona Arizona## Arkansas Arkansas## > California## > Colorado
md5
In a common situation you might be sent a file, or you might download a file from the internet that comes with code known as a checksum or a hash.
Hashing programs generate a unique code based on the contents of a file. People distribute hashes with files so that we can be sure that the file we think we’ve downloaded is the genuine file. One way we can prevent malicious individuals from sending us harmful files is to check to make sure the computed hash matches the provided hash. There are a few commonly used file hashes but we’ll talk about two called MD5 and SHA-1.
Since hashes are generated based on file contents, then two identical files should have the same hash. Let’s test this my making a copy of states.txt.
cp states.txt states_copy.txt
To compute the MD5 hash of a file we can use the md5 command:
md5 states.txt## MD5 (states.txt) = 8d7dd71ff51614e69339b03bd1cb86acmd5 states_copy.txt## MD5 (states_copy.txt) = 8d7dd71ff51614e69339b03bd1cb86ac
Debian下可以使用命令
md5sumAs we expected they’re the same! We can compute the SHA-1 hash using the shasum command:
shasum states.txt## 588e9de7ffa97268b2448927df41760abd3369a9 states.txtshasum states_copy.txt## 588e9de7ffa97268b2448927df41760abd3369a9 states_copy.txt
这些校验码的产生是基于文件内容的,内容变化校验码也会变化。
5. Pipes
管线命令
One of the most powerful features of the command line is skilled use of the pipe
(|)which you can usually find above the backslash () on your keyboard.
The pipe allows us to take the output of a command, which would normally be printed to the console, and use it as the input to another command.
It’s like fitting an actual pipe between the end of one program and connecting it to the top of another program!This output from cat canada.txt will go into our pipe, and we’ll attach the dispensing end of the pipe to head, which we use to look at the first few lines of a file:
cat canada.txt | head -n 5NunavutQuebecNorthwest TerritoriesOntarioBritish Columbia
Notice that this is the same result we would get from head -n 5 canada.txt, we just used cat to illustrate how the pipe works.
The general syntax of the pipe is [program that produces output] | [program uses pipe output as input instead of a file].
A more common and useful example where we could use the pipe is answering the question: “How many US states end in a vowel?” We could use grep and regular expressions to list all of the state names that end with a vowel, then we could use wc to count all of the matching state names:
grep "[aeiou]$" states.txt | wc -l## 32
The pipe can also be used multiple times in one command in order to take the output from one piped command and use it as the input to yet another program! For example we could use three pipes with ls, grep, and less so that we could scroll through the files in out current directory were created in February:
ls -al | grep "Feb" | less-rw-r--r-- 1 sean staff 472 Feb 22 13:47 states.txt
Remember you can use the Q key to quit less and return to the prompt.
6. Make
Once upon a time there were no web browsers, file browsers, start menus, or search bars. When somebody booted up a computer all they got a was a shell prompt, and all of the work they did started from that prompt.
Back then people still loved to share software, but there was always the problem of how software should be installed. The make program is the best attempt at solving this problem, and make’s elegance has carried it so far that it is still in wide use today.
The guiding design goal of make is that in order to install some new piece of software one would:
- Download all of the files required for installation into a directory.
- cd into that directory.
- Run make.
This is accomplished by specifying a file called makefile, which describes the relationships between different files and programs.
In addition to installing programs, make is also useful for creating documents automatically. Let’s build up a makefile that creates a readme.txtfile which is automatically populated with some information about our current directory.
Let’s start by creating a very basic makefile with nano:
cd ~/Documents/Journalnano makefiledraft_journal_entry.txt:touch draft_journal_entry.txt
The simple makefile above shows illustrates a rule which has the following general format:
[target]: [dependencies...][commands...]
依赖文件。
In the simple example we created draft_journal_entry.txt is the target, a file which is created as the result of the command(s).
It’s very important to note that any commands under a target must be indented with a Tab.
If we don’t use Tabs to indent the commands then make will fail. Let’s save and close the makefile, then we can run the following in the console:
ls## makefile
Let’s use the make command with the target we want to be “made” as the only argument:
make draft_journal_entry.txt## touch draft_journal_entry.txtls## draft_journal_entry.txt## makefile
The commands that are indented under our definition of the rule for the draft_journal_entry.txt target were executed, so now draft_journal_entry.txt exists! Let’s try running the same make command again:
make draft_journal_entry.txt## make: 'draft_journal_entry.txt' is up to date.
Since the target file already exists no action is taken, and instead we’re informed that the rule for draft_journal_entry.txt is “up to date” (there’s nothing to be done).
If we look at the general rule format we previously sketched out, we can see that we didn’t specify any dependencies for this rule.
上述命令没有添加任何依赖项。
A dependency is a file that the target depends on in order to be built. If a dependency has been updated since the last time make was run for a target then the target is not “up to date.”
依赖项有改变,命令重新执行。
This means that the commands for that target will be run the next time make is run for that target.
This way, the changes to the dependency are incorperated into the target. The commands are only run when the dependencies or change, or when the target doesn’t exist at all, in order to avoid running commands unnecessarily.
Let’s update our makefile to include a readme.txt that is built automatically. First, let’s add a table of contents for our journal:
echo "1. 2017-06-15-In-Boston" > toc.txt
Now let’s update our makefile with nano to automatically generate a readme.txt:
nano makefiledraft_journal_entry.txt:touch draft_journal_entry.txtreadme.txt: toc.txtecho "This journal contains the following number of entries:" > readme.txtwc -l toc.txt | egrep -o "[0-9]+" >> readme.txt
Take note that the -o flag provided to egrep above extracts the regular expression match from the matching line, so that only the number of lines is appended to readme.txt. Now let’s run make with readme.txt as the target:
make readme.txt## echo "This journal contains the following number of entries:" > readme.txt## wc -l toc.txt | egrep -o "[0-9]+" >> readme.txt
Now let’s take a look at readme.txt:
cat readme.txt## This journal contains the following number of entries:## 1
Looks like it worked! What do you think will happen if we run make readme.txt again?
make readme.txt## make: 'readme.txt' is up to date.
You guessed it: nothing happened! Since the readme.txt file still exists and no changes were made to any of the dependencies for readme.txt (toc.txt is the only dependency) make doesn’t run the commands for the readme.txt rule. Now let’s modify toc.txt then we’ll try running make again.
echo "2. 2017-06-16-IQSS-Talk" >> toc.txtmake readme.txt## echo "This journal contains the following number of entries:" > readme.txt## wc -l toc.txt | egrep -o "[0-9]+" >> readme.txt
Looks like it ran! Let’s check readme.txt to make sure.
cat readme.txt## This journal contains the following number of entries:## 2
It looks like make successfully updated readme.txt! With every change to toc.txt, running make readme.txt will programmatically update readme.txt.
In order to simplify the make experience, we can create a rule at the top of our makefile called all where we can list all of the files that are built by the makefile.
By adding the all target we can simply run make without any arguments in order to build all of the targets in the makefile. Let’s open up nano and add this rule:
nano makefileall: draft_journal_entry.txt readme.txtdraft_journal_entry.txt:touch draft_journal_entry.txtreadme.txt: toc.txtecho "This journal contains the following number of entries:" > readme.txtwc -l toc.txt | egrep -o "[0-9]+" >> readme.txt
While we have nano open let’s add another special rule at the end of our makefile called clean which destroys the files created by our makefile:
all: draft_journal_entry.txt readme.txtdraft_journal_entry.txt:touch draft_journal_entry.txtreadme.txt: toc.txtecho "This journal contains the following number of entries:" > readme.txtwc -l toc.txt | egrep -o "[0-9]+" >> readme.txtclean:rm draft_journal_entry.txtrm readme.txt
Let’s save and close our makefile then let’s test it out first let’s clean up our repository:
make cleanls## rm draft_journal_entry.txt## rm readme.txt## makefile## toc.txtmakels## touch draft_journal_entry.txt## echo "This journal contains the following number of entries:" > readme.txt## wc -l toc.txt | egrep -o "[0-9]+" >> readme.txt## draft_journal_entry.txt## readme.txt## makefile## toc.txt
Looks like our makefile works! The make command is extremely powerful, and this section is meant to just be an introduction. For more in-depth reading about make I recommend Karl Broman’s tutorial or Chase Lambert’s makefiletutorial.com.
summary
make is a tool for creating relationships between files and programs, so that files that depend on other files can be automatically rebuilt.
makefiles are text files that contain a list of rules.
Rules are made up of targets (files to be built), commands (a list of bash commands that build the target), and dependencies (files that the target depends on to be built).
