@mShuaiZhao
2018-02-03T08:01:46.000000Z
字数 7133
阅读 523
week01.Ng's Sequence Model Course
2018.02 Coursera
- week01.Ng's Sequence Model Course
- Recurrent Neural Networks
- 1. Why sequence models?
- 2. Notation
- 3. Recurrent Neural Network Model
- 4. Backpropagation through time
- 5. Different types of RNNs
- 6. Language model and sequence generation
- 7. Sampling novel sequences
- 8. Vanishing gradients with RNNs
- 9. Gated Recurrent Unit
- 10. Long Short Term Memory
- 11. Bidirectional RNN
- 12. Deep RNNs
Recurrent Neural Networks
1. Why sequence models?
Examples of sequence data

sentiment classification 情感判断
machine translation
video activity recognition
name entity recognition
2. Notation
motivation examples
representing words

需要有一个vocabulary(或者称为dictionary),这是一个记录了所有用到的词汇的list。这个vocabulary可以根据对样本的词汇统计,选出其中出现得最频繁的前多少words构成。
然后将每个word表示为一个one-hot vector
如果一个词没有出现在词汇表中,那么可以用unkown word(UNK)或类似的事物来指代。
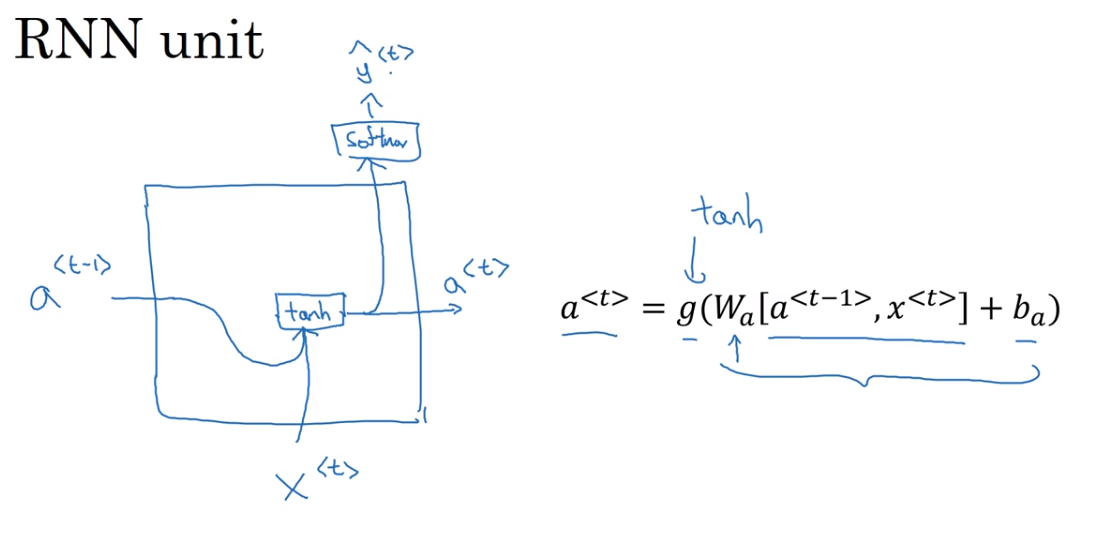
3. Recurrent Neural Network Model
Why not a standard network?
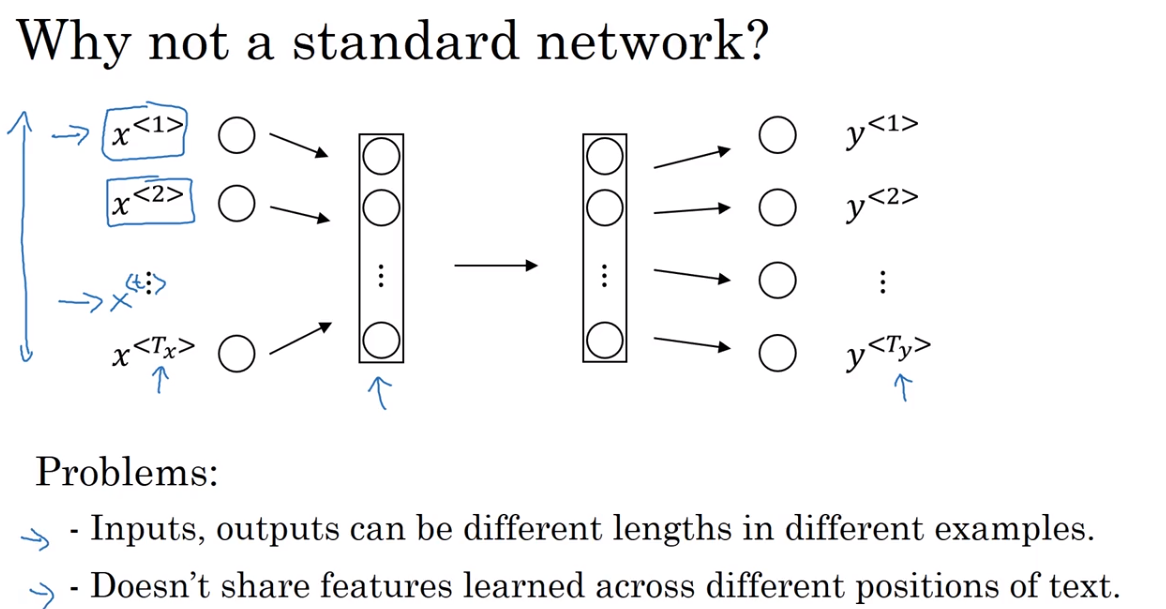
RNNs
And so, at each time-step, the recurrent neural network passes on this activation to the next time-step for it to use. And to kick off the whole thing, we'll also have some made up activation at time zero. This is usually the vector of zeroes.
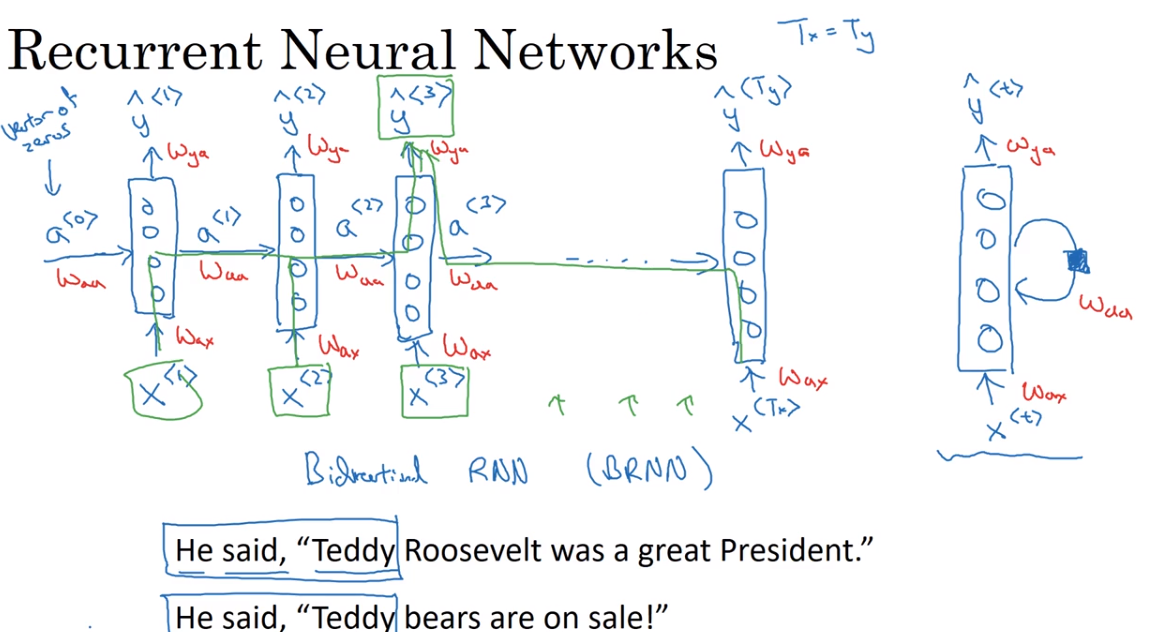
将上一次time-step产生的activation values输入到下一次time-step
都是相同的参数
靠左边的图是右边的展开形式
Now one weakness of this RNN is that it only uses the information that is earlier in the sequence to make a prediction, in particular, when predicting Y3, it doesn't use information about the words X4, X5, X6 and so on.
- 这种架构的RNN,在预测当前输入的时候,只用到了当前输入之前的信息,并没有利用当前输入之后的信息。如图片中举的两个例子。前三个单词一样但表示的意思完全不同。
Forward Propagation
RNN的前向传播过程
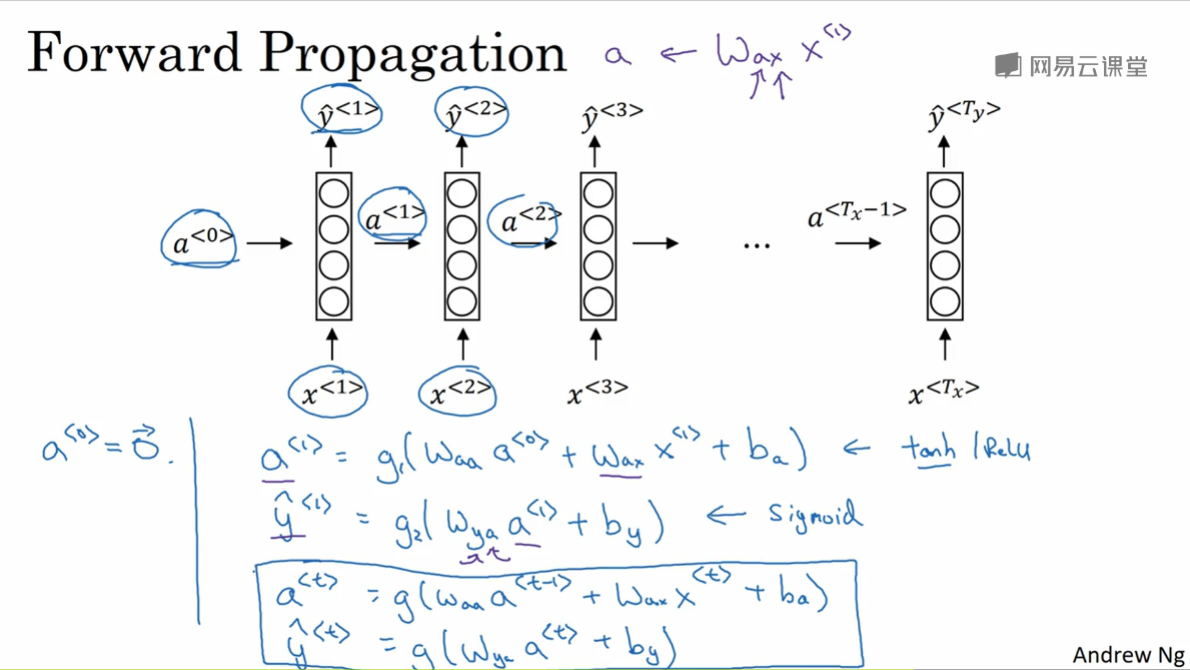
- 激活函数多用tanh,也有用ReLU或者Sigmoid。
Simplified RNN notation
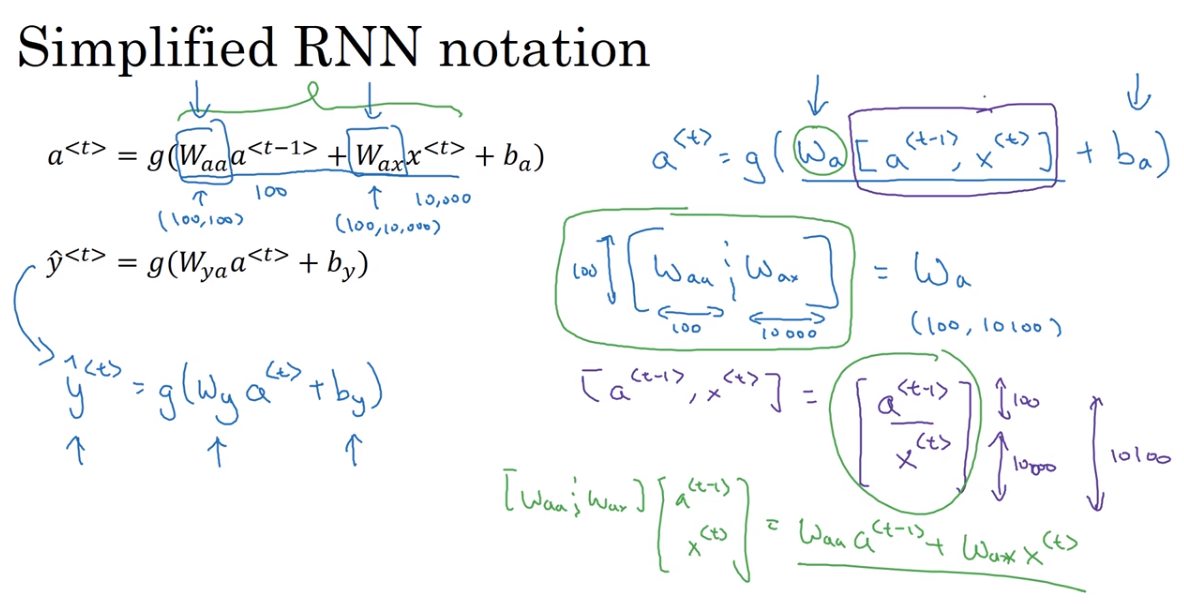
RNN的简化式子,为了适应更加复杂的模型的表示
question:有一个疑问,所有的bias参数都是一样的吗?
4. Backpropagation through time
Forward propagation and backpropagation
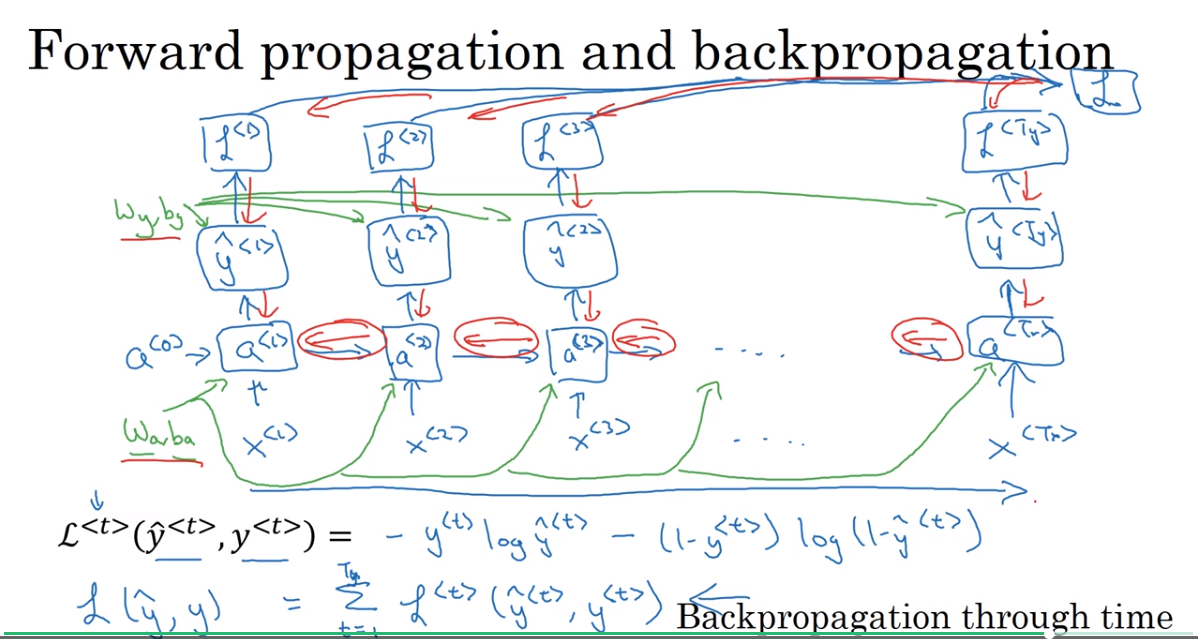
沿着时间反向传播。
最后反向传播的是总的loss
5. Different types of RNNs
有时输入序列的长度和输出序列的长度并不是完全一样的
一个blog
Examples of RNN architecture
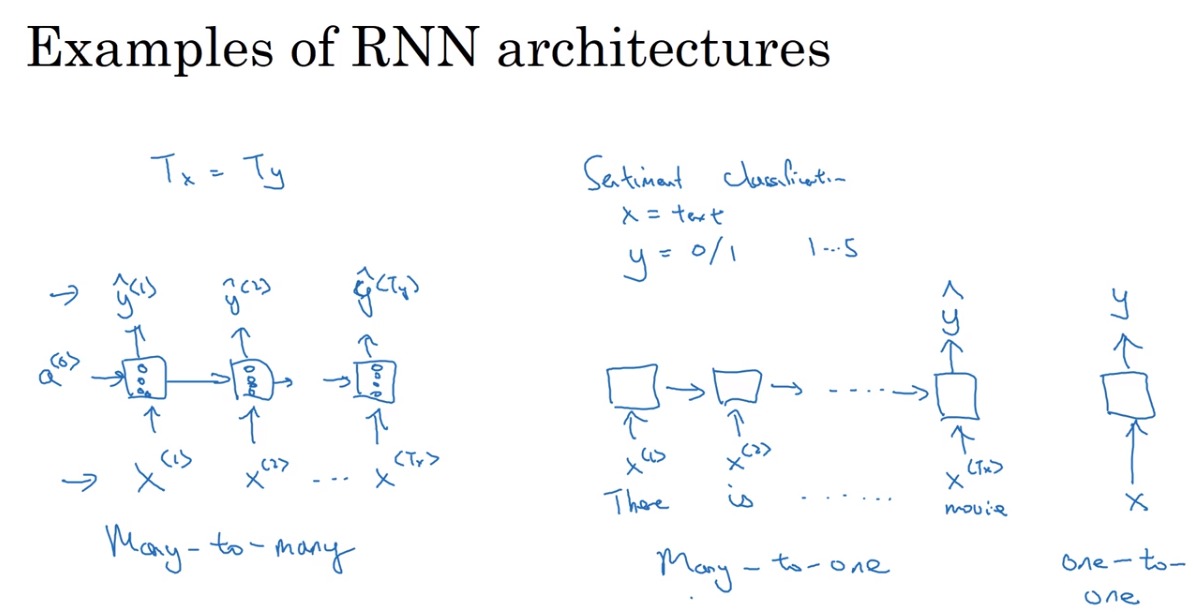
many-to-many architecture
有很多个输入,也有很多个输出
many-to-one architecture
例如sentiment classification(情感分类),输入一句话,判断这句话所表示的情感。
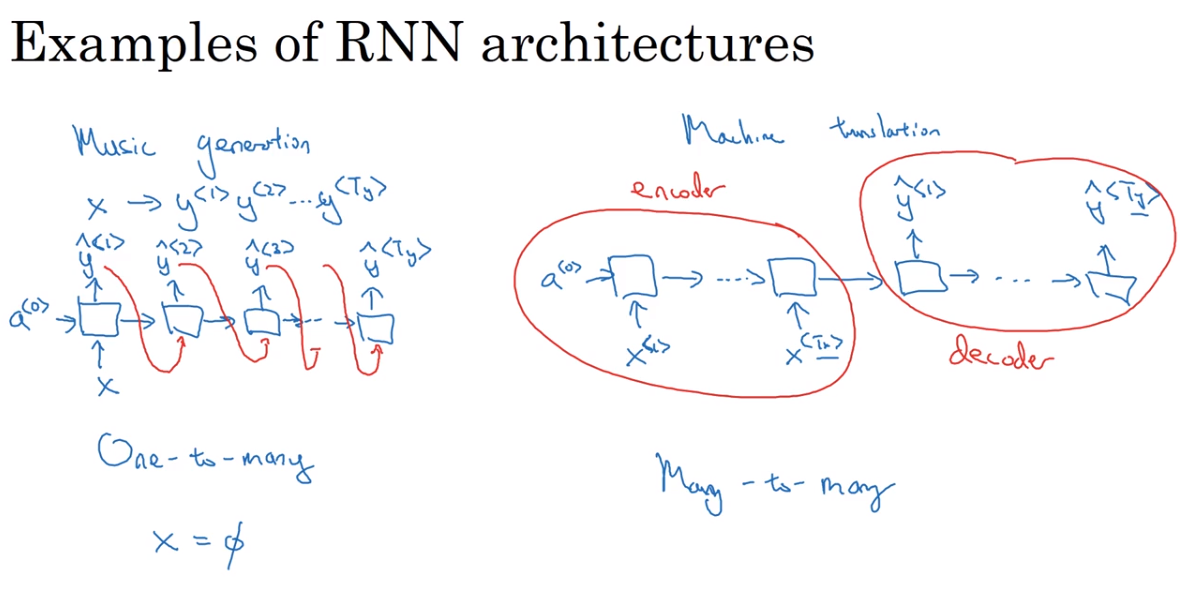
one-to-many architecture
例如music generation,没有输入会输入一个整数之类,产生音乐。
machine translation
这是一个输入和输出并不等长的系统,前面部分利用encoder编码,后半部分利用decoder解码。
Summary of RNN types
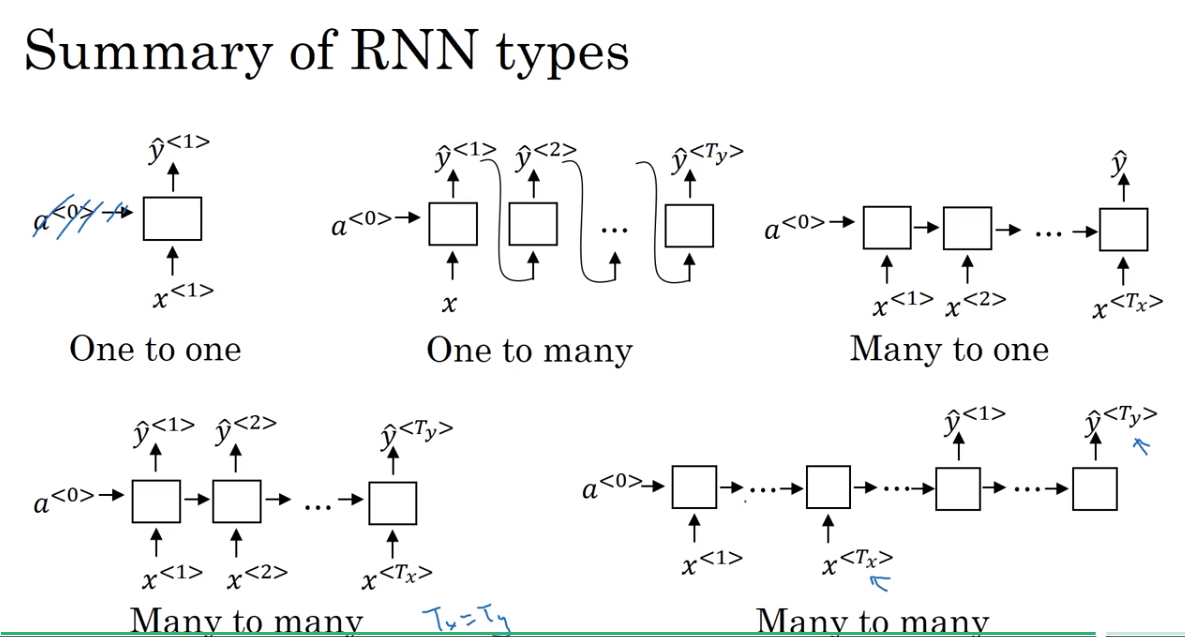
one-to-one 就是普通的neural network,没有用RNN的必要
one-to-many的结构注意输入传递的方式
右下角是另一种version的many-to-many结构,先encode再decode。
6. Language model and sequence generation
What is language modelling?

- speech recognition
Language modelling with an RNN
In this example, I'm just ignoring punctuation.
period n.周期,句点
Tokenize(形成vocabulary)
EOS(End of Sentence)
UNK stands for unknown word
RNN Model
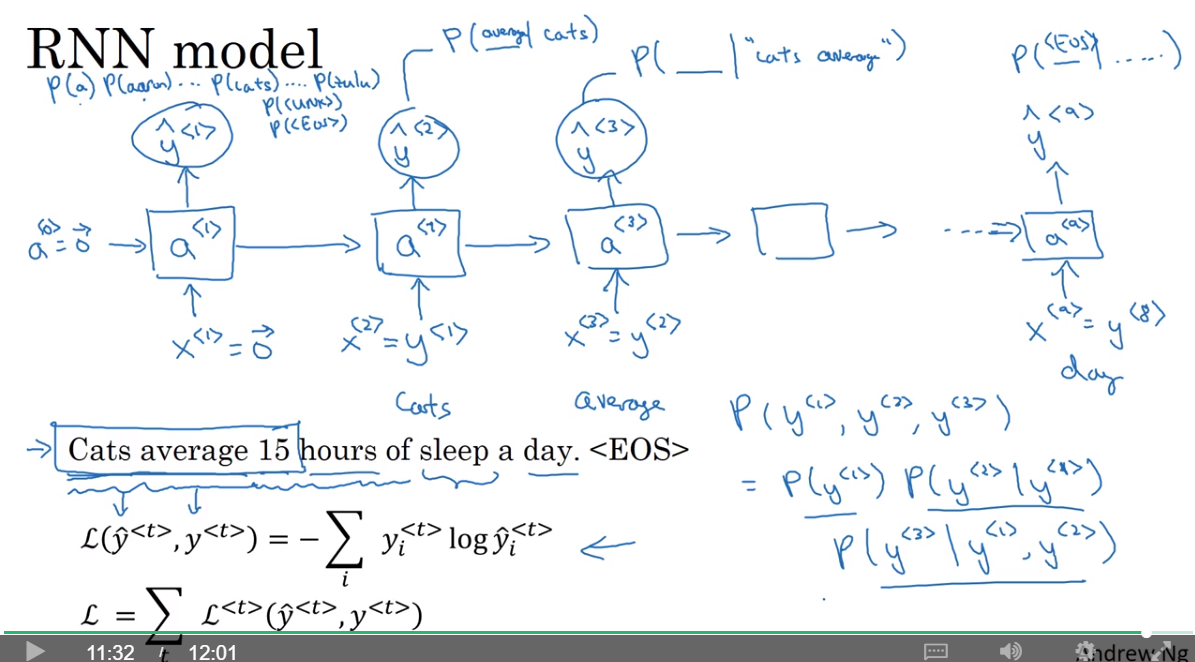
- 注意训练的时候,送入后一个单元的是正确的结果,e.g.
7. Sampling novel sequences
sampling a sequence from a trained RNN
So remember that a sequence model, models the chance of any particular sequence of words as follows, and so what we like to do is sample from this distribution to generate noble sequences of words.
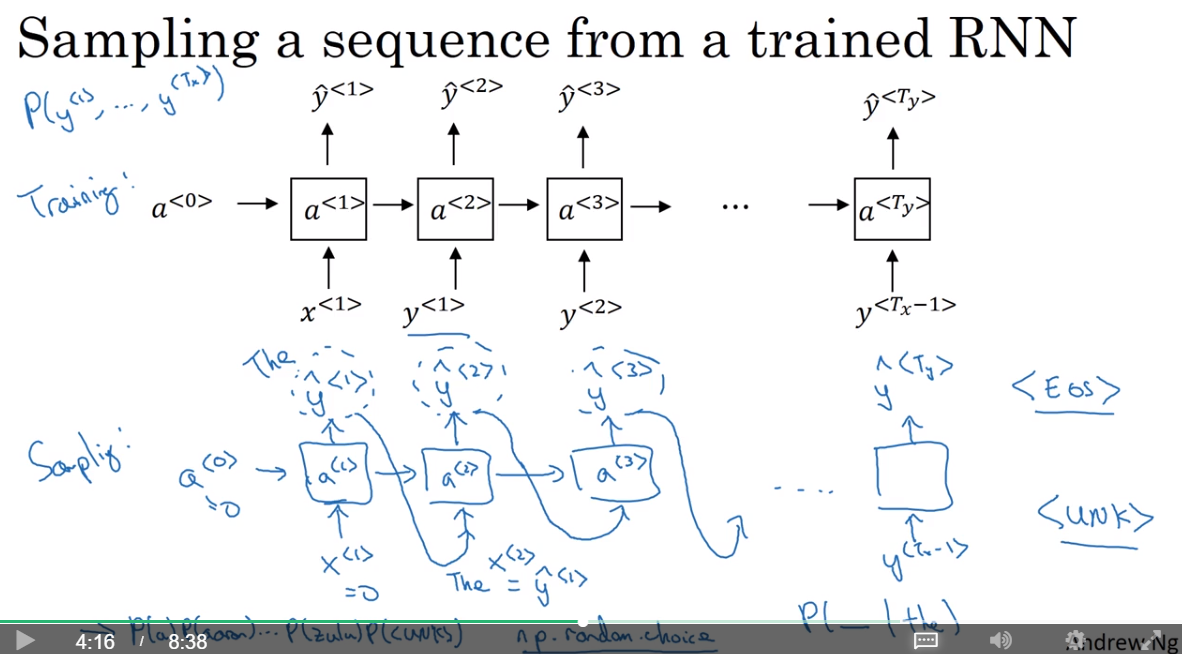
送入第一个输入,产生它可能是各个word的概率,然后再基于这个概率去随机选择word;将本次产生的结果送入到下一个模块当中,产生后一个输入可能是各个word的概率,重复这个过程。
最后可以指定产生的word数或者是产生了EOS之后就停止。
加入sampling到了UNK,那么就取决于是否你的决策,进行resample或者就保留UNK。
这是word-level的RNN
character-level language model
But the main disadvantage of the character level language model is that you end up with much longer sequences. So many english sentences will have 10 to 20 words but may have many, many dozens of characters. And so character language models are not as good as word level language models at capturing long range dependencies between how the the earlier parts of the sentence also affect the later part of the sentence. And character level models are also just more computationally expensive to train. So the trend I've been seeing in natural language processing is that for the most part, word level language model are still used, but as computers gets faster there are more and more applications where people are, at least in some special cases, starting to look at more character level models. But they tend to be much hardware, much more computationally expensive to train, so they are not in widespread use today. Except for maybe specialized applications where you might need to deal with unknown words or other vocabulary words a lot. Or they are also used in more specialized applications where you have a more specialized vocabulary.
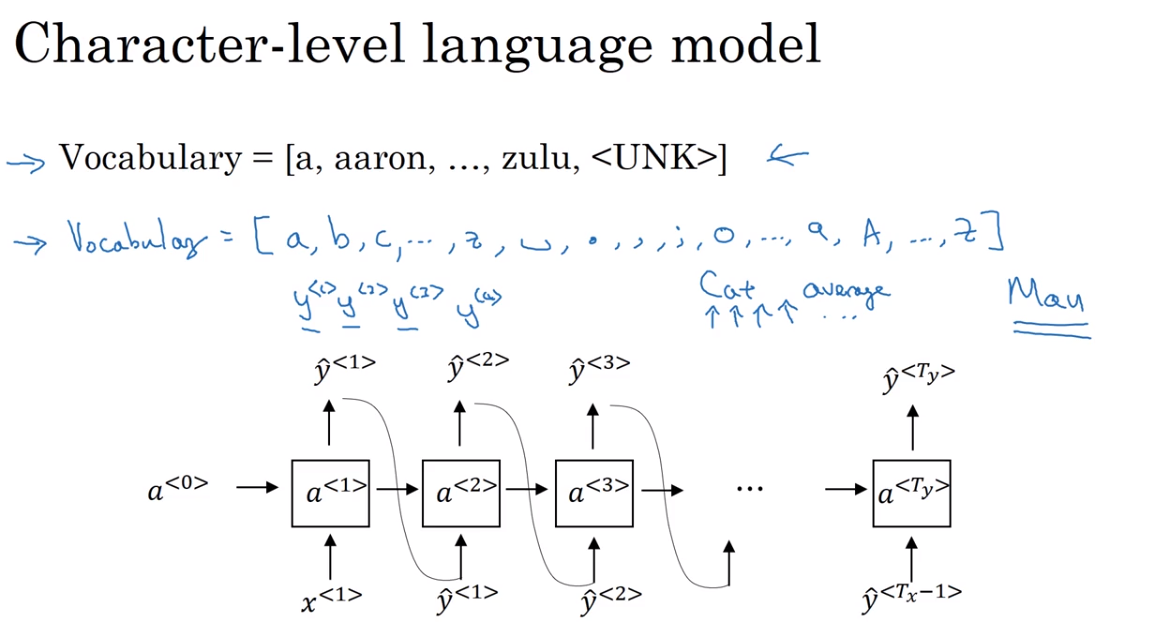
- 基于字母层面来构造RNN model,就是将vocabulary换成字母、数字的组合并进行用模型进行预测
sequence generation

8. Vanishing gradients with RNNs
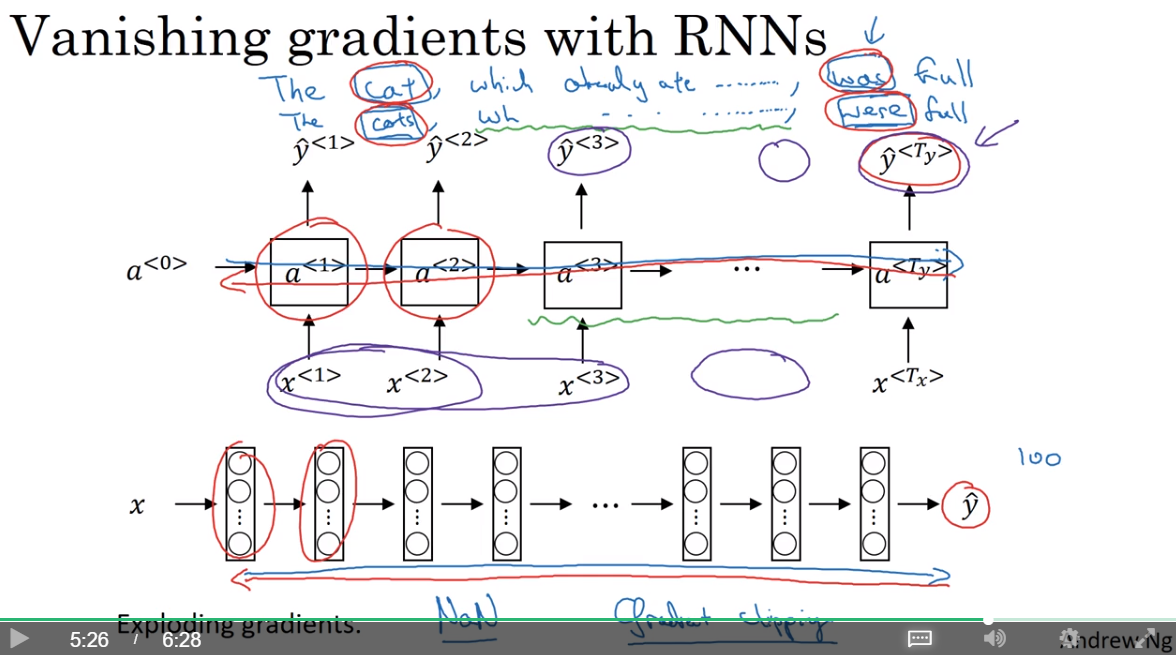
word与word之间的依赖关系
word与word之间的依赖关系,是比较复杂的,如cat与was、cats与were之间的关系,中间隔了很多个单词。
假如两个存在相关关系的词之间距离非常远,那么
图中所示的RNN结构,一个单元受其之前的附近的单元的影响更为强烈(这一点如何从公式上体现呢?存疑)。更远的单元对其影响有限。这是这种RNN结构的局限性。
9. Gated Recurrent Unit
In this video, you learn about the Gated Recurrent Unit which is a modification to the RNN hidden layer that makes it much better capturing long range connections and helps a lot with the vanishing gradient problems.
RNN Unit
GRU(simplified)
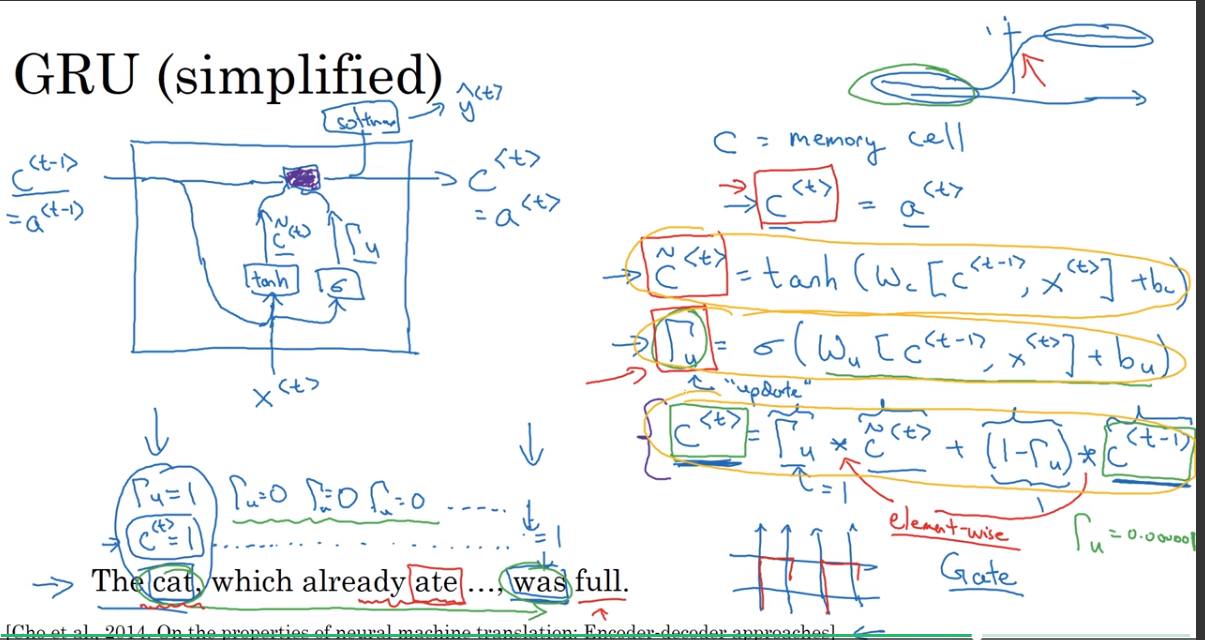
增加了一个memory cell,
And every time-step, we're going to consider overwriting the memory cell with a value c tilde of t. So this is going to be a candidate for replacing c of t.
增加了一个gate,
And then the key, really the important idea of the GRU it will be that we have a gate. So the gate, I'm going to call gamma u. This is the capital Greek alphabet gamma subscript u, and u stands for update gate, and this will be a value between zero and one.
And to develop your intuition about how GRUs work, think of gamma u, this gate value, as being always zero or one. Although in practice, your compute it with a sigmoid function applied to this. So remember that the sigmoid function looks like this. And so it's value is always between zero and one. And for most of the possible ranges of the input, the sigmoid function is either very, very close to zero or very, very close to one. So for intuition, think of gamma as being either zero or one most of the time. And this alphabet u stands for- I chose the alphabet gamma for this because if u look at a gate fence, looks a bit like this I guess, then there are a lot of gammas in this fence. So that's why gamma u, we're going to use to denote the gate. Also Greek alphabet G, right. G for gate. So G for gamma and G for gate.
注意是element-wise的乘法
有多个隐藏单元的时候,每个隐藏单元都有自己对应的memroy cell
是用Sigmoid计算的,大多是情况下,非常接近0或非常接近,可以把它认为是一个门(作选择的门)。(Sigmoid函数在自变量为-3和+3的时候分别约等于0.0474和0.952,-2和+2的时候分别约等于0.119和0.881。)
=1时,,update;
=0时,, do not update。决定了是否用更新。
举例:当你得到这个句子,看到短语the cat的时候,知道subject是cat,这个时候可以update memory cell中对应的bit。然后the cat之后的一长串,没有意义,这个时候就不用记住这些是什么。然后直到was的位置依然记得cat是singular的,所以是was。(大部分翻译,仅供参考)
GRU也是为了解决vanishing gradient的问题(有待继续学习)
Full GRU
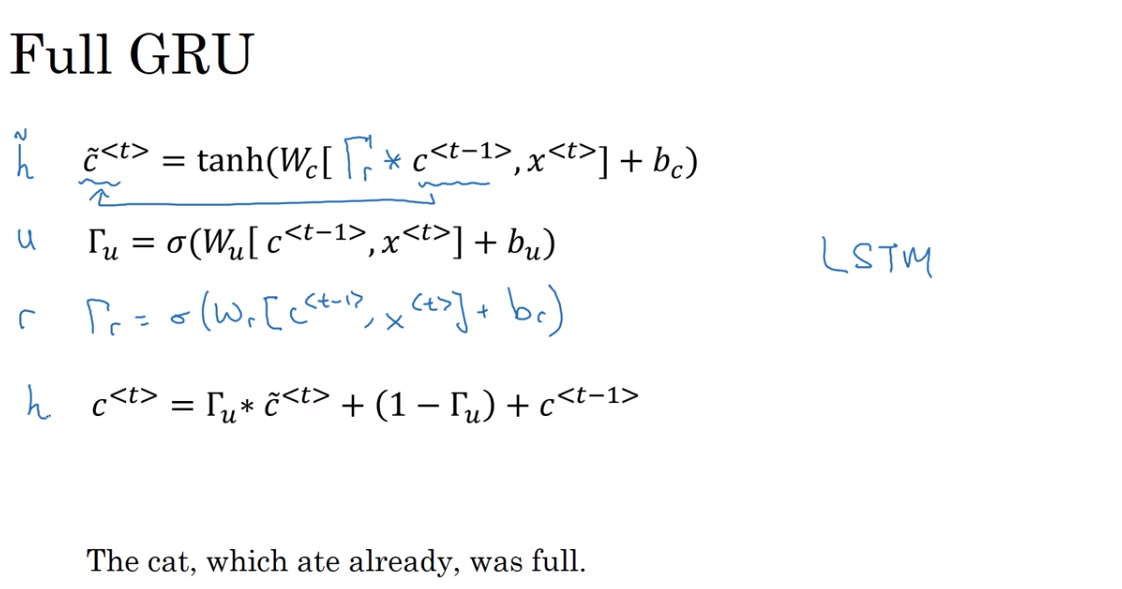
这里最下面一行的式子有错误,应该是乘号,和上一页slide一样。
增加了一个gate
I'm going to add one more gate.So this is another gate gamma r. You can think of r as standing for relevance.So this gate gamma r tells you how relevant is c minus one to computing the next candidate for c.And this gate gamma r is computed pretty much as you'd expect with a new parameter matrix Wr, and then the same things as input x plus br.
实际中发现是很有用的。
在常见的论文中,表示的符号有差异。
10. Long Short Term Memory
GRU and LSTM

LSTM相比GRU,有三个门,并且不再存在
新加的三个门是update gate、forget gate、output gate,每个gate都有不同的参数。(这样增加了学习能力和适应性吗?)
LSTM in pictures
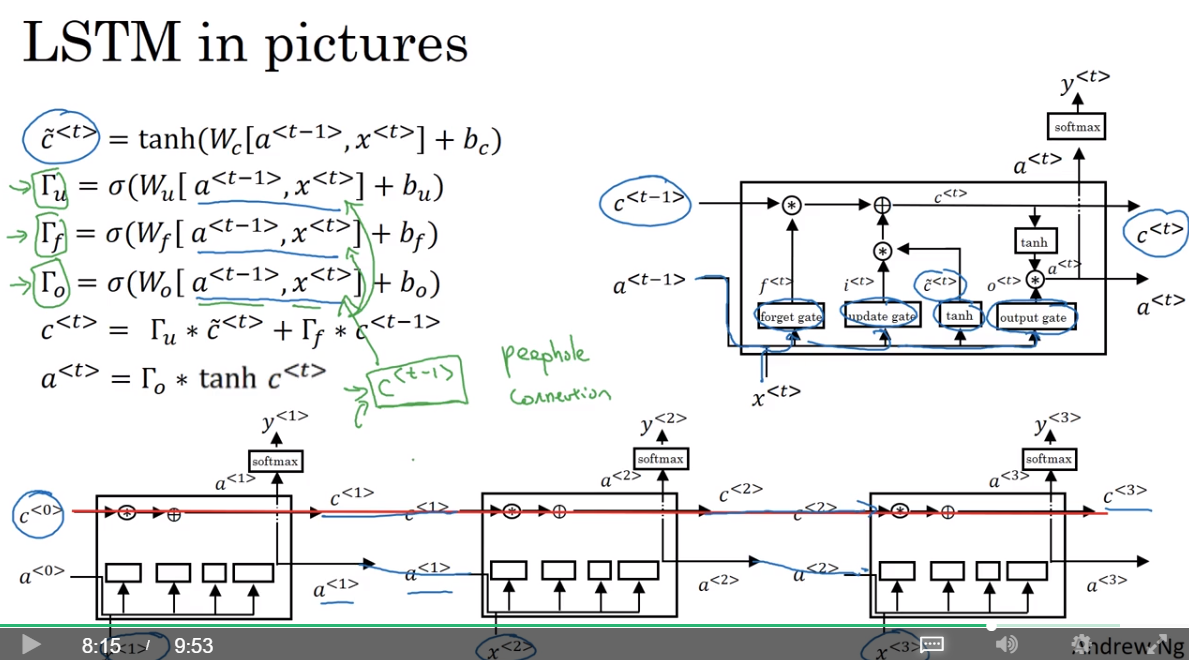
And one cool thing about this you'll notice is that there's this line at the top that shows how, so long as you set the forget and the update gate appropriately, it is relatively easy for the LSTM to have some value c_0 and have that be passed all the way to the right to have your, maybe, c_3 equals c_0. And this is why the LSTM, as well as the GRU, is very good at memorizing certain values even for a long time, for certain real values stored in the memory cell even for many, many timesteps.
可以解决较远单词之间的依赖关系(同GRU)
也有添加peephole connection的操作,将也添加进去用于更新门参数
如果有多个hidden units,注意与memnry cell的一一对应,不要对不相关的memory cell产生影响
实际中如何选择?
GRU是近些年(2014年左右)的研究成果,这是一个更简单的模型,只有两个门参数,适用于构建更大的模型。
LSTM是较早的成果,但是具有更加强大的学习能力,因为它有三个门参数,学习能力更强。但相对而言更复杂。
LSTM是现在使用得较多的选择,但GRU也在慢慢流行起来。
没有明确的选择法则。
11. Bidirectional RNN
Getting information from the future

不只利用之前出现过的信息,还要利用之后的信息(infromation from the future)
可以是RNN单元、GRU单元、LSTM单元等
Bidirectional RNN(BRNN)
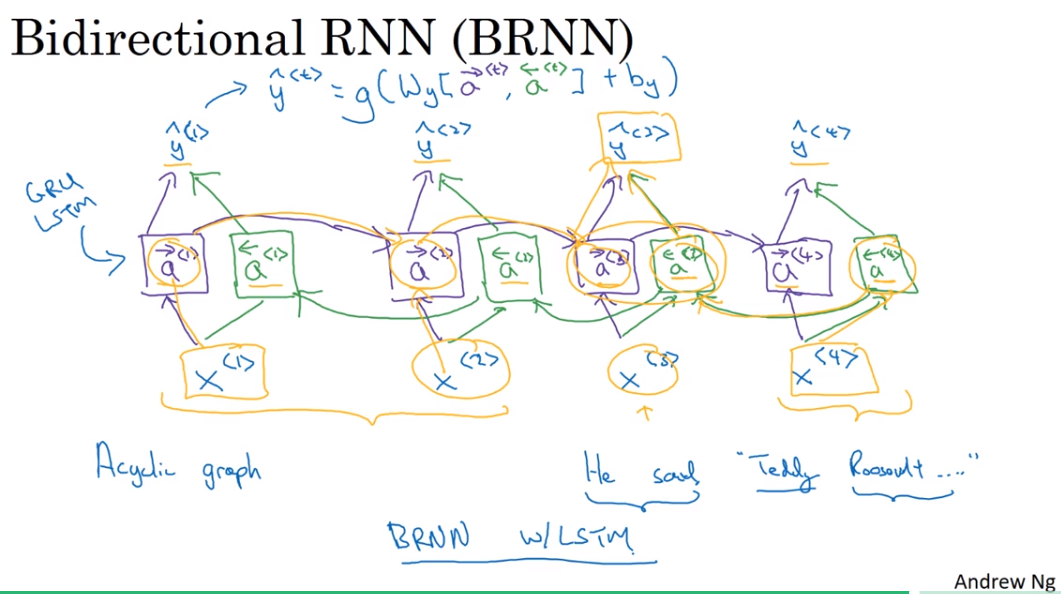
利用了整个序列的信息,前向传播+反向传播,综合二者的信息。
缺点就是做出决策之前需要整个序列的数据
12. Deep RNNs
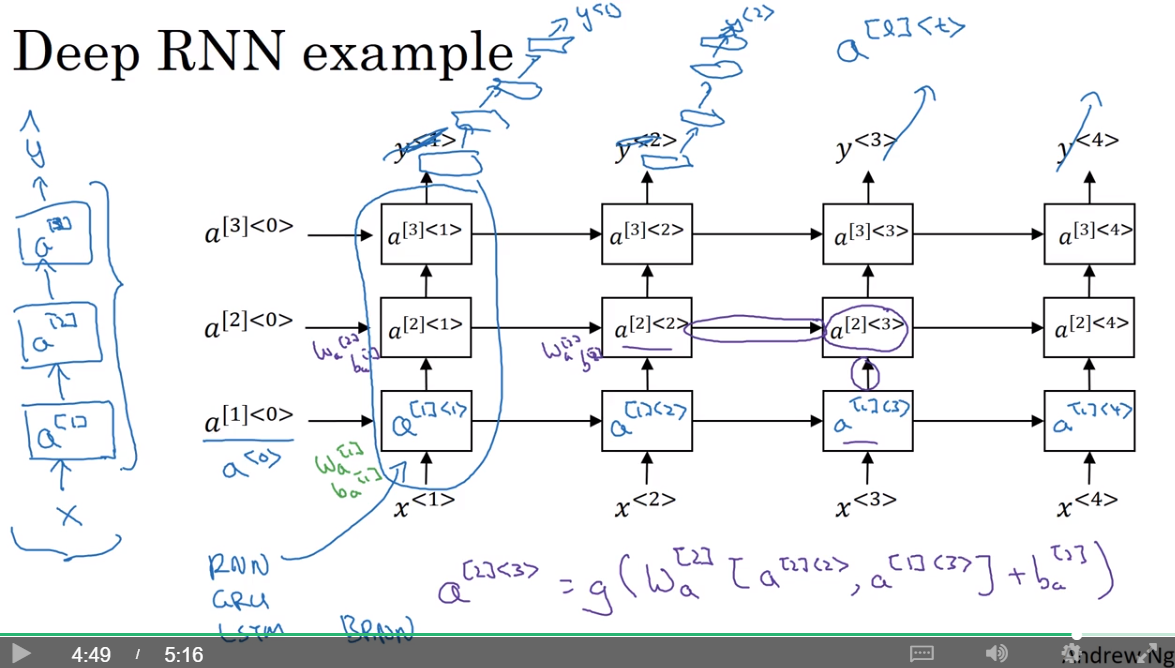
每一层都有自己的参数
一般没有想CNNs中那样深层的网络模型
