@mShuaiZhao
2018-02-17T14:36:08.000000Z
字数 7558
阅读 644
week03.Ng's Sequence Model Course
2018.02 Coursera
Various sequence to sequence architectures
1. Basic Models
sequence to sequence model
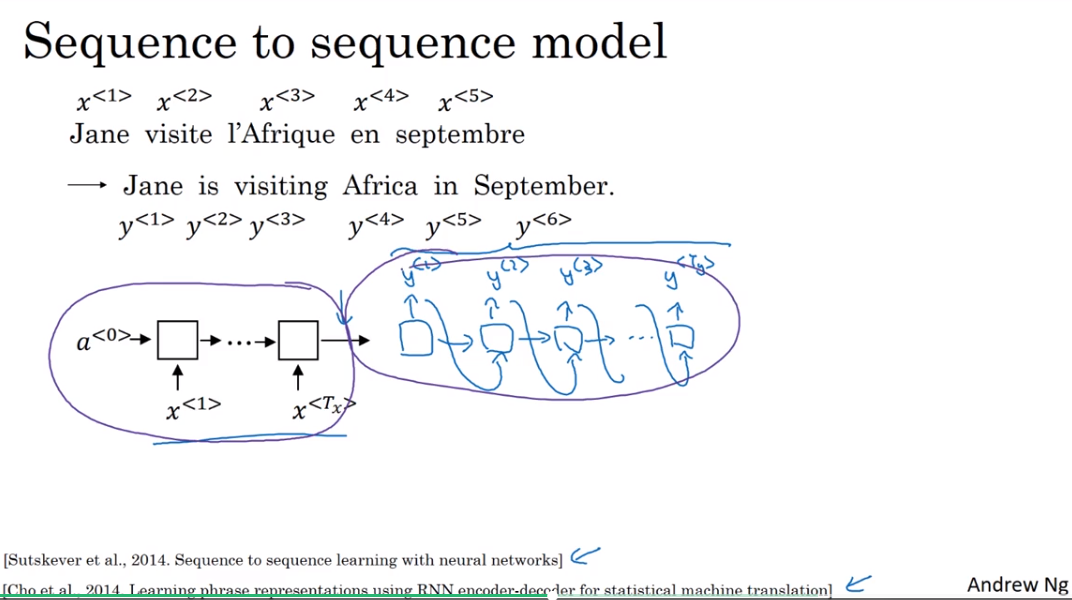
- encoder and decoder,this model works
image captioning
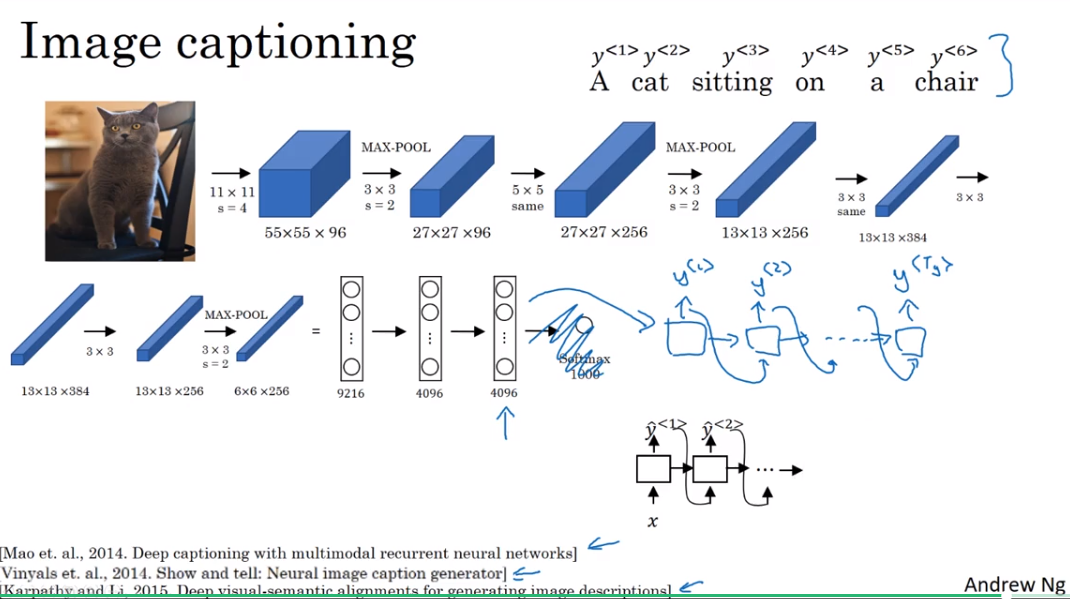
- 前面的ConvNets可以当作encoder,后面接一个RNN model作decoder
2. Picking the most likely sentence
Machine translation as building a conditional language model
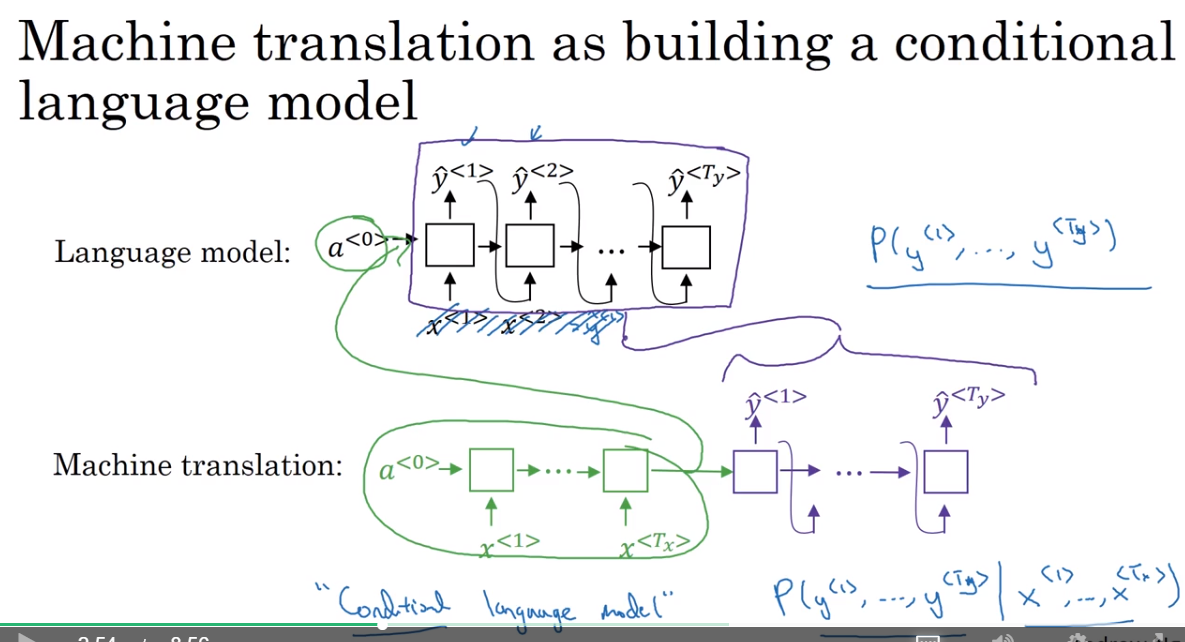
- machine translation像一个conditional language model
Finding the most likely translation

Why not a greedy search

- 为什么不使用greedy search呢?就是分别地选择每个最有可能的word,最后组成一个句子。
3. Beam search
Beam saearch algorithm
step 1
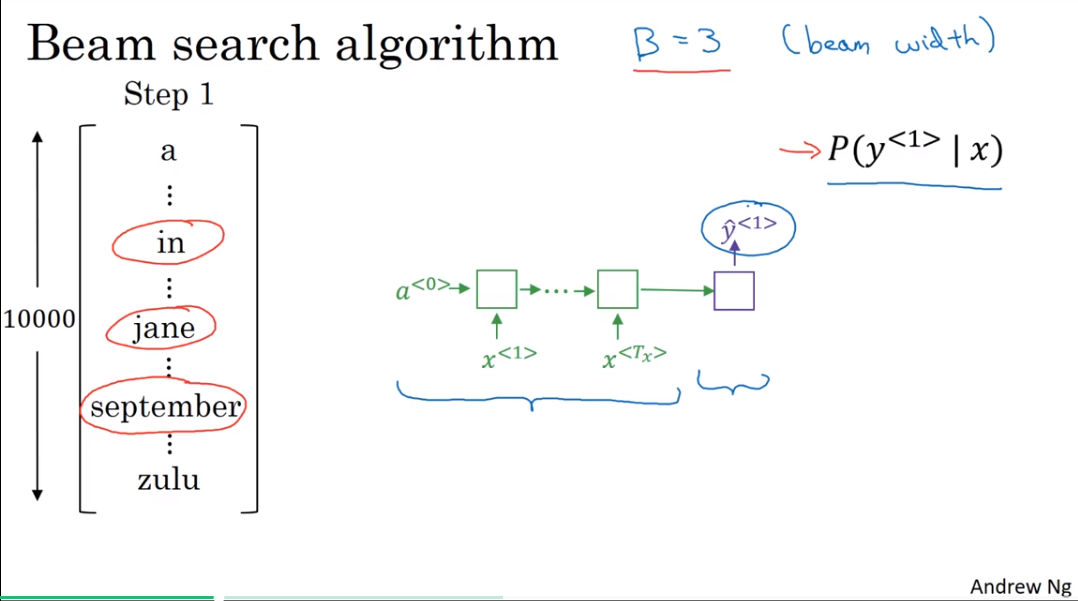
B = 3的情况
Then you would take those 10,000 possible outputs and keep in memory which were the top three.
step 2
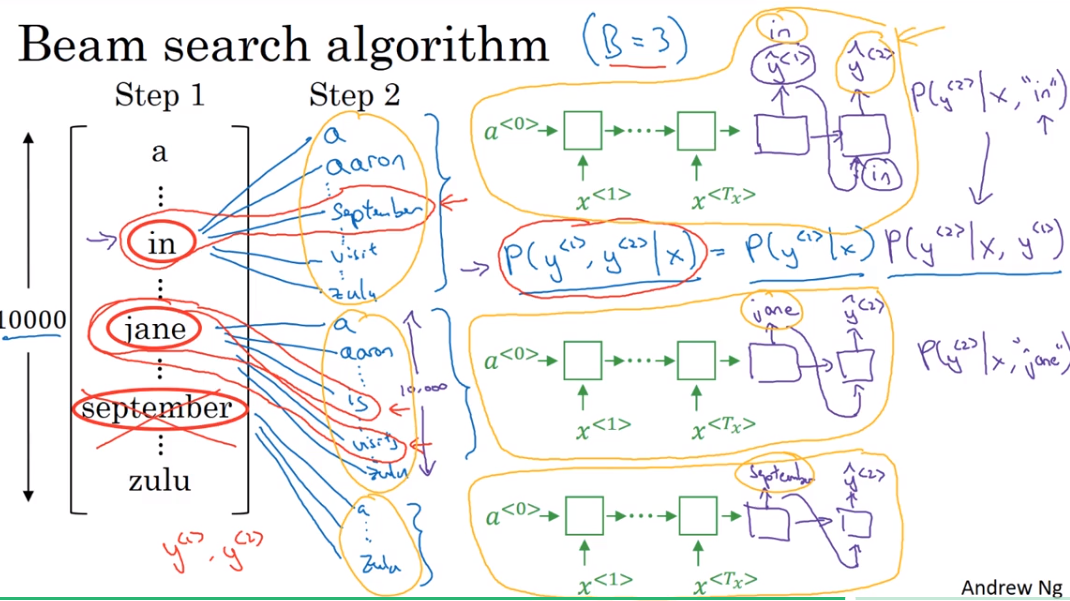
And it's because of beam width is equal to three that you have three copies of the network with different choices for the first words, but these three copies of the network can be very efficiently used to evaluate all 30,000 options for the second word. So just don't instantiate 30,000 copies of the network or three copies of the network to very quickly evaluate all 10,000 possible outputs at that softmax output say for Y2.
每次只保留3个最有可能的选择,B=3.
step 3
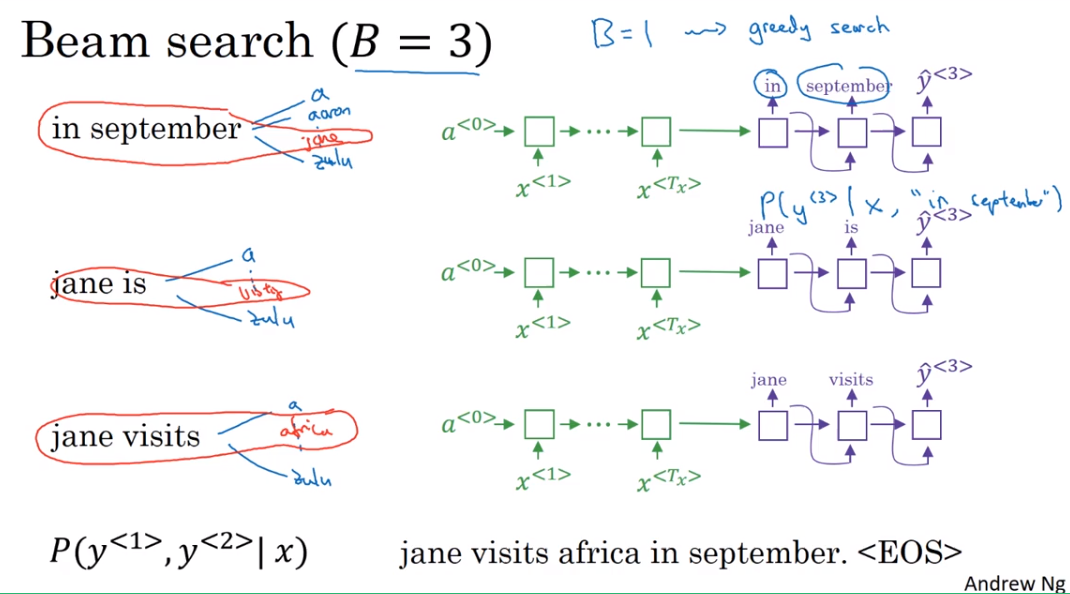
- 当B = 1时,就和之前提到的greedy search一样。
4. Refinements to Beam Search
Length normalization

Now, if you're implementing these, these probabilities are all numbers less than 1. Often they're much less than 1. And multiplying a lot of numbers less than 1 will result in a tiny, tiny, tiny number, which can result in numerical underflow. Meaning that it's too small for the floating part representation in your computer to store accurately. So in practice, instead of maximizing this product, we will take logs.
if you have a very long sentence, the probability of that sentence is going to be low, because you're multiplying as many terms here. Lots of numbers are less than 1 to estimate the probability of that sentence. And so if you multiply all the numbers that are less than 1 together, you just tend to end up with a smaller probability.
And so this objective function has an undesirable effect, that maybe it unnaturally tends to prefer very short translations. It tends to prefer very short outputs.
Because the probability of a short sentence is determined just by multiplying fewer of these numbers are less than 1.
And so the product would just be not quite as small.
And by the way, the same thing is true for this. The log of our probability is always less than or equal to 1. You're actually in this range of the log. So the more terms you have together, the more negative this thing becomes.
是为了解决machine translation偏向于更短的sentence的问题,这是因为概率连乘所产生的问题
因子的使用完全是因为在实践中work
Beam Search discussion

如何选择合适的参数B? 较大的B有更多的选择可能,速度比较慢。
So that's how you implement beam search, and you get to play this yourself in this week's problem exercise. Finally, a few implementational details, how do you choose the beam width B? The larger B is, the more possibilities you're considering, and does the better the sentence you probably find. But the larger B is, the more computationally expensive your algorithm is, because you're also keeping a lot more possibilities around. All right, so finally, let's just wrap up with some thoughts on how to choose the beam width B.
Beam Search最后的到的结果不一定是最优值。它只考虑了到当前为止的结果。
5. Error analysis in beam search
Now, beam search is an approximate search algorithm, also called a heuristic search algorithm. And so it doesn't always output the most likely sentence. It's only keeping track of B equals 3 or 10 or 100 top possibilities.
Example

So it turns out that the most useful thing for you to do at this point is to compute using this model to compute P(y* given x) as well as to compute P(y-hat given x) using your RNN model. And then to see which of these two is bigger. So it's possible that the left side is bigger than the right hand side. It's also possible that P(y*) is less than P(y-hat) actually, or less than or equal to, right? Depending on which of these two cases hold true, you'd be able to more clearly ascribe this particular error, this particular bad translation to one of the RNN or the beam search algorithm being had greater fault.
Error analysis on beam search

case 1
Beam search 并没有找到真正的最优解。case 2
Beam search 正常的工作,找到了它认为的合理解,RNN model有错。
Error analysis process

- 找出到底是在哪里出错了,作对应性的更改。
6. Bleu Score
One of the challenges of machine translation is that, given a French sentence, there could be multiple English translations that are equally good translations of that French sentence. So how do you evaluate a machine translation system if there are multiple equally good answers, unlike, say, image recognition where there's one right answer? You just measure accuracy. If there are multiple great answers, how do you measure accuracy? The way this is done conventionally is through something called the BLEU score.
And the intuition is so long as the machine generated translation is pretty close to any of the references provided by humans, then it will get a high BLEU score.
BLEU, by the way, stands for bilingual evaluation,
Evaluating machine translation

Bleu score on bigrams

Bleu score on unigrams

Bleu details

- 也是为了避免短的翻译结果最后得到较高的分数
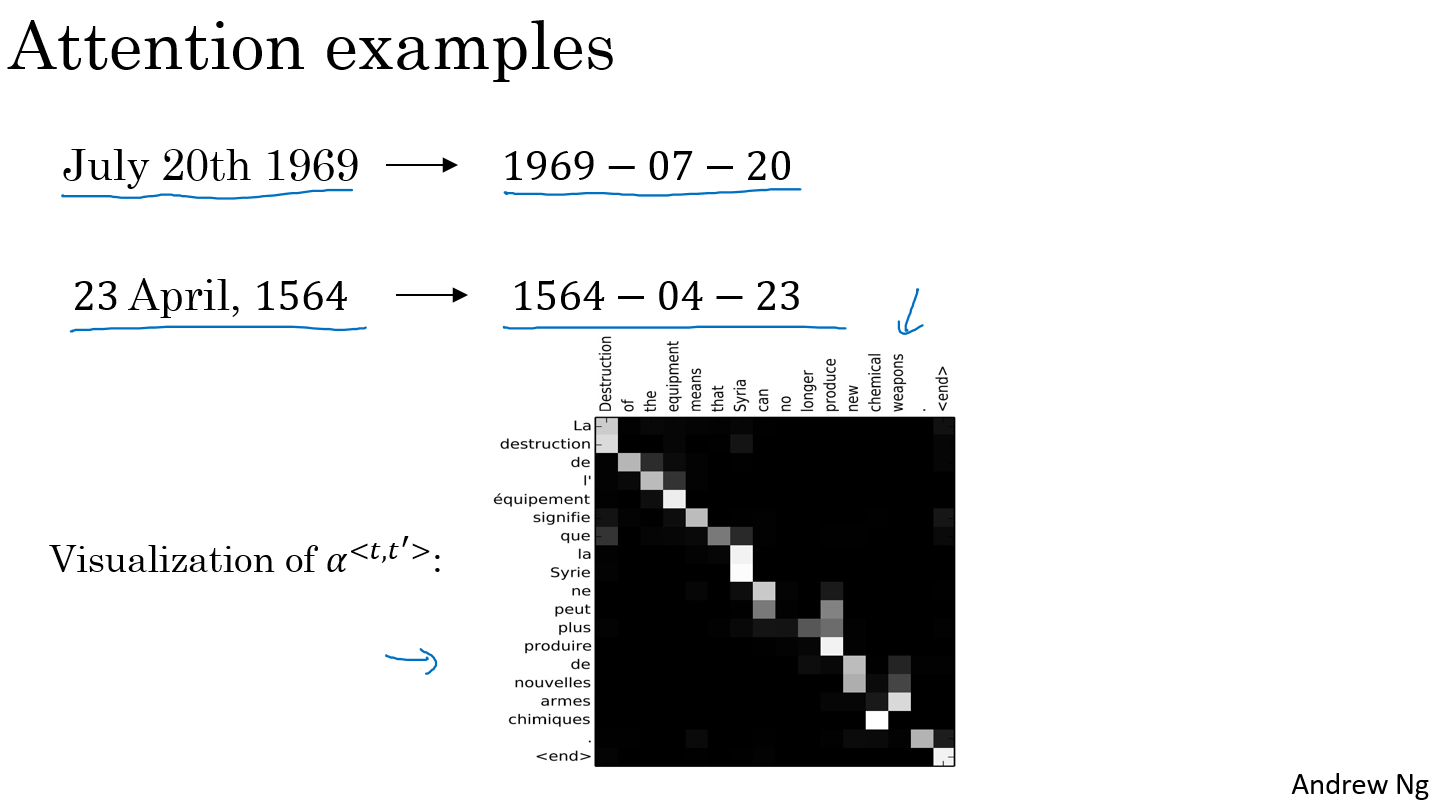
7. Attention Model Intuition
the problem of long sequences
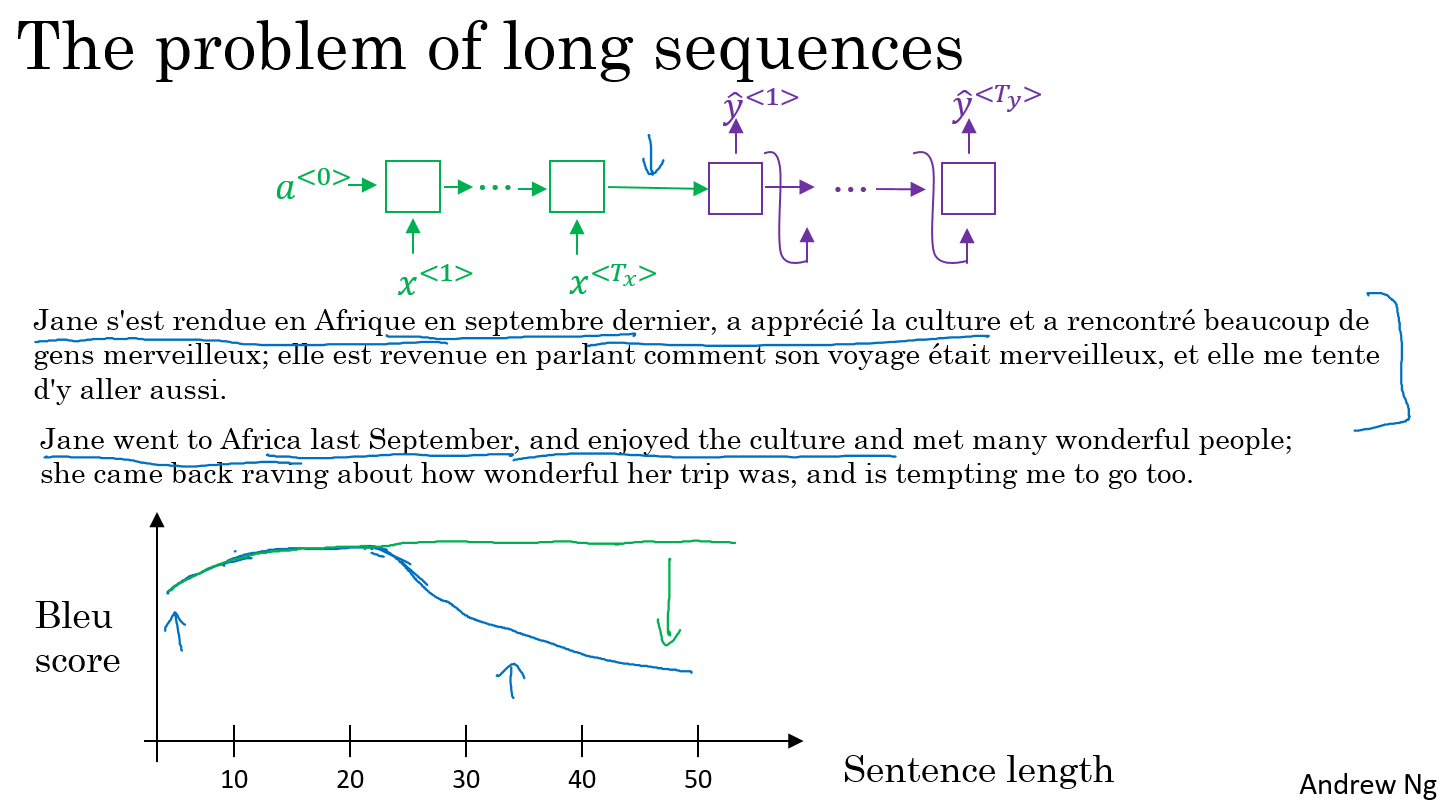
- 人在翻译一个很长的句子的时候,并不是一口气读完然后再进行翻译的,而是边读边进行翻译。
Attention Model Intuition
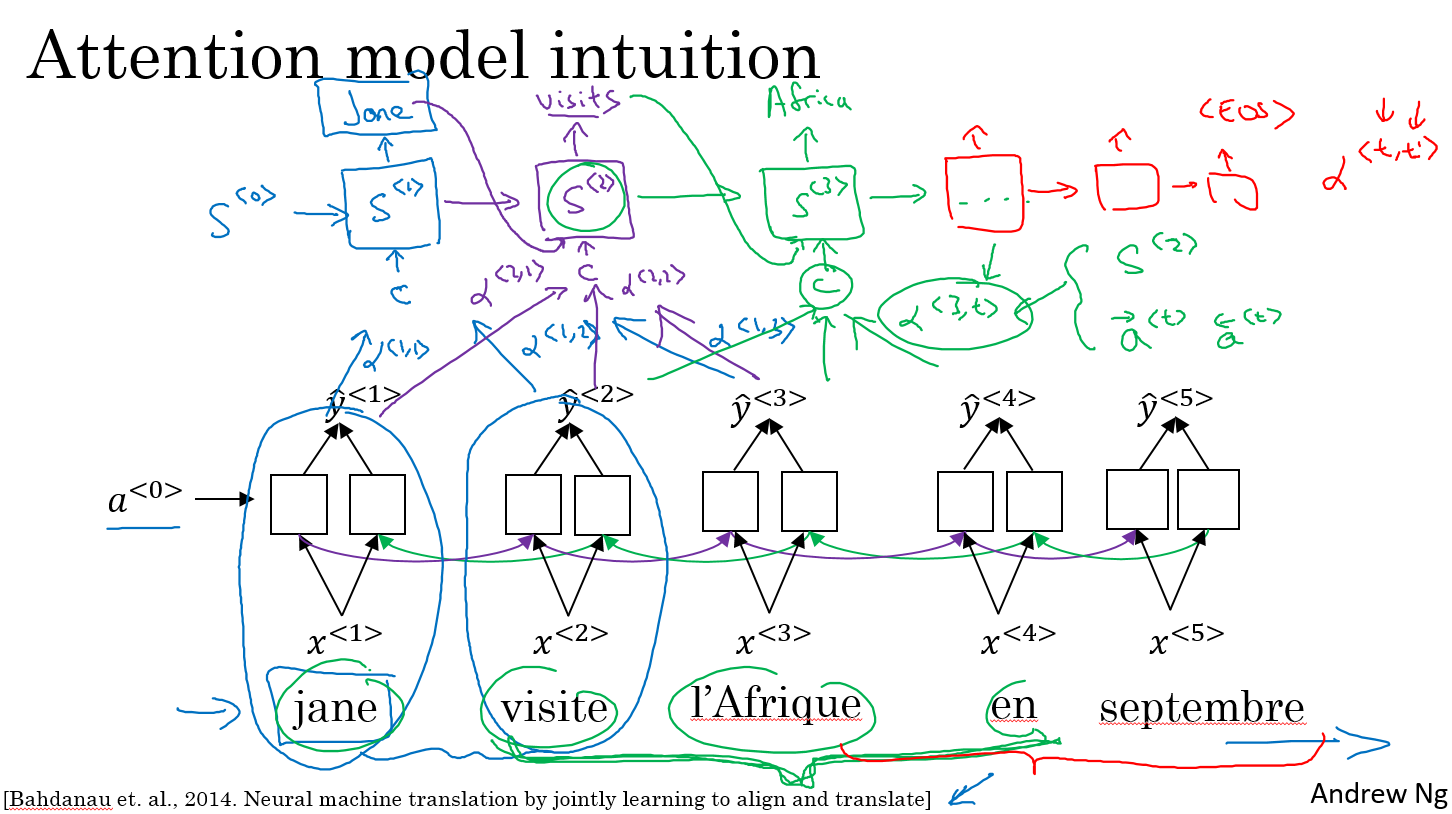
Now, the question is, when you're trying to generate this first word, this output, what part of the input French sentence should you be looking at? Seems like you should be looking primarily at this first word, maybe a few other words close by, but you don't need to be looking way at the end of the sentence. What the Attention Model would be computing is a set of attention weights and we're going to use Alpha one, one to denote when you're generating the first words, how much should you be paying attention to this first piece of information here. And then we'll also come up with a second that's called Attention Weight, Alpha one, two which tells us what we're trying to compute the first work of Jane, how much attention we're paying to this second work from the inputs and so on and the Alpha one, three and so on, and together this will tell us what is exactly the context from denoter C that we should be paying attention to, and that is input to this R and N unit to then try to generate the first words. That's one step of the R and N, we will flesh out all these details in the next video.
For the second step of this R and N, we're going to have a new hidden state S two and we're going to have a new set of the attention weights. We're going to have Alpha two, one to tell us when we generate in the second word. I guess this will be visits maybe that being the ground trip label. How much should we paying attention to the first word in the french input and also, Alpha two, two and so on. How much should we paying attention the word visite, how much should we pay attention to the free and so on. And of course, the first word we generate in Jane is also an input to this, and then we have some context that we're paying attention to and the second step, there's also an input and that together will generate the second word and that leads us to the third step, S three, where this is an input and we have some new context C that depends on the various Alpha three for the different time sets, that tells us how much should we be paying attention to the different words from the input French sentence and so on.
8. Attention Model
attention model
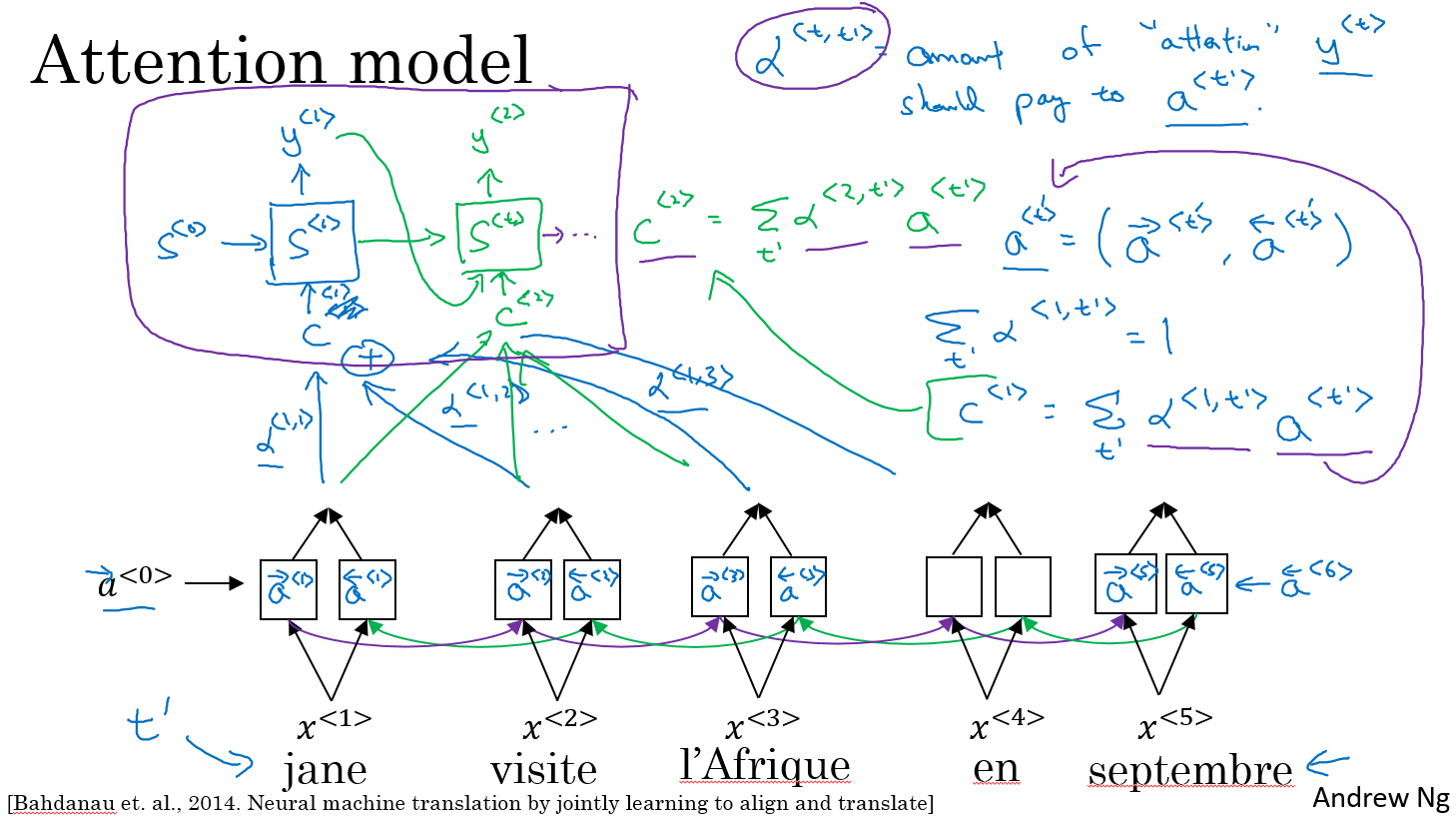
注意attention model的总和为1。
computing attention
如何计算attention weight

And the intuition is, if you want to decide how much attention to pay to the activation of t_prime. Well, the things that seems like it should depend the most on is what is your own hidden state activation from the previous time step. You don't have the current state activation yet because of context feeds into this so you haven't computed that.
So it seems pretty natural that alpha(t, t_prime) and e(t, t_prime) should depend on these two quantities. But we don't know what the function is. So one thing you could do is just train a very small neural network to learn whatever this function should be. And trust that obligation trust wait and descent to learn the right function. And it turns out that if you implemented this whole model and train it with gradient descent, the whole thing actually works.
Now, one downside to this algorithm is that it does take quadratic time or quadratic cost to run this algorithm. If you have tx words in the input and ty words in the output then the total number of these attention parameters are going to be tx times ty. And so this algorithm runs in quadratic cost. Although in machine translation applications where neither input nor output sentences is usually that long maybe quadratic cost is actually acceptable. Although, there is some research work on trying to reduce costs as well.
attention examples