@mShuaiZhao
2018-02-10T16:09:21.000000Z
字数 10903
阅读 584
week02.Ng's Sequence Model Course
2018.02 Coursera
Introduction to Word Embedding
1. Word Respresentation
Word representation
vocabulary
one-hot vector的表示形式
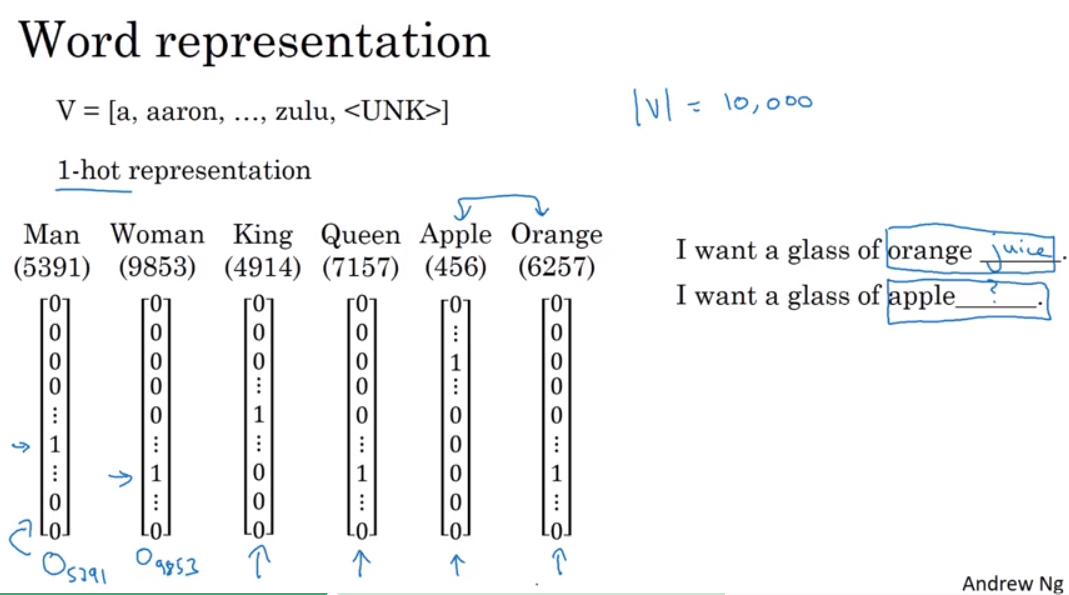
这种方法最大的缺点是,每个word都是独立的个体,相互之间没有联系。
例如apple和orange之间的相似度是要比apple和queen之间的相似度大的,但是这种表示方法并没有体现这一点。
Featurized representation : word embedding

每个word都有它自身的特征,可以用这些来表示这个word
这些特征也是可以通过算法学习到的
Visualizing word embeddings
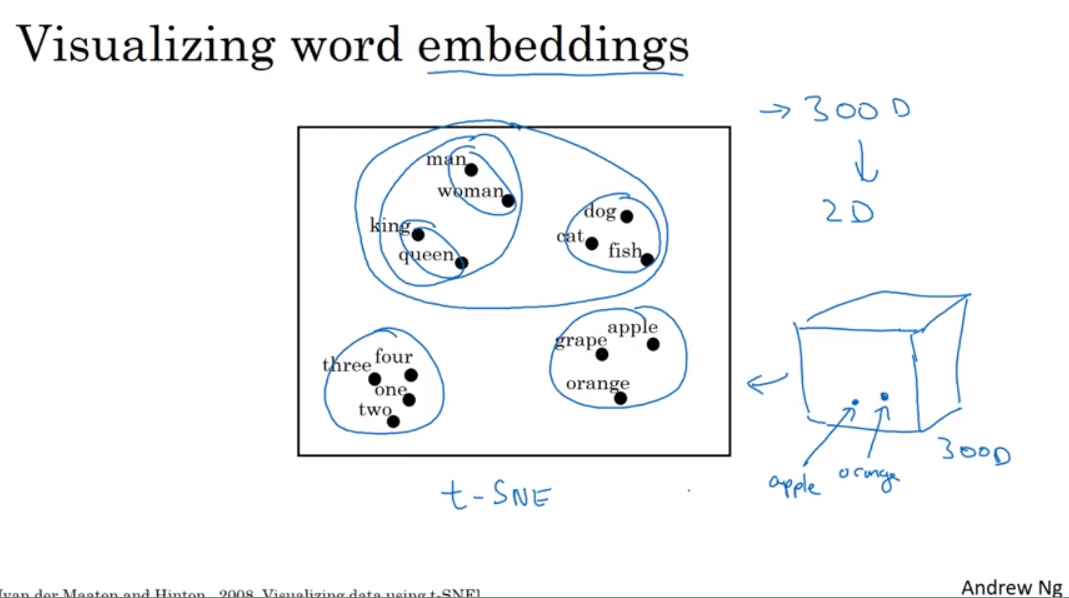
为什么叫embedding呢?
假设一个300维的特征空间,那么apple就是embed到其中的一个点,所以取名如此。
t-SNE算法
http://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf
2. Using word embeddings
Name entity recognition example
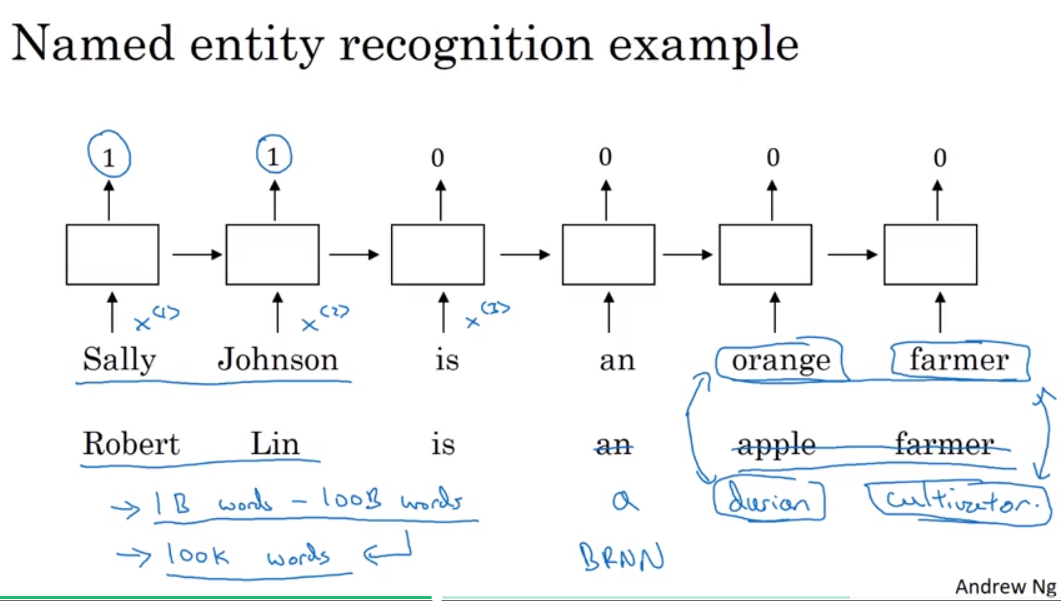
- 从大的语料库中可以学习到丰富的信息,并用于transfer learning。
transfer learning and word embeddings

可以使用别的学习好的embeddings来进行transfer learning
如果你的在第二步中的数据集比较大,也可以在别的学习好的word embeddings上进行finetune;如果你的数据集比较小,不建议这样做。
可能原来的10000-D的one hot vector变成了300-D 的dense vector。
和face encoding的联系
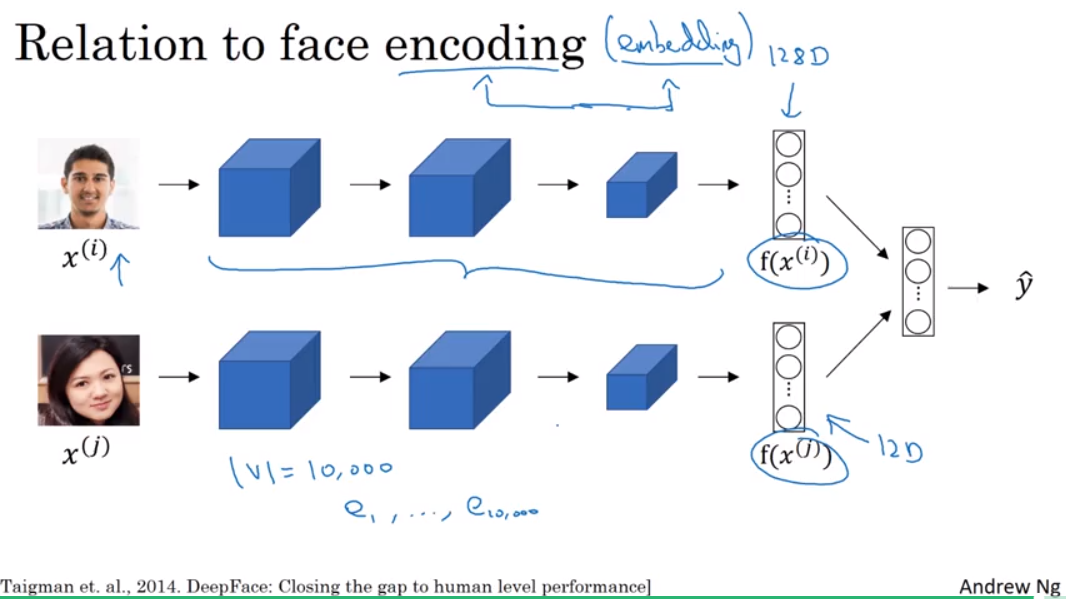
embedding和encoding,某种程度上这两个词是可以交换的
这两个任务的一些区别在于,对于face recognition而言,我们希望学得一个网络模型,可以对所有的输入的图片都输出一个encoding后的向量;对于word embedding而言,有一个固定的vocabulary,我们希望对于有这个vocabulary中的每一个word,学习一个固定的encoding或embedding。
3. Properties of word embeddings
By now, you should have a sense of how word embeddings can help you build NLP applications. One of the most fascinating properties of word embeddings is that they can also help with analogy reasoning.
Analogies
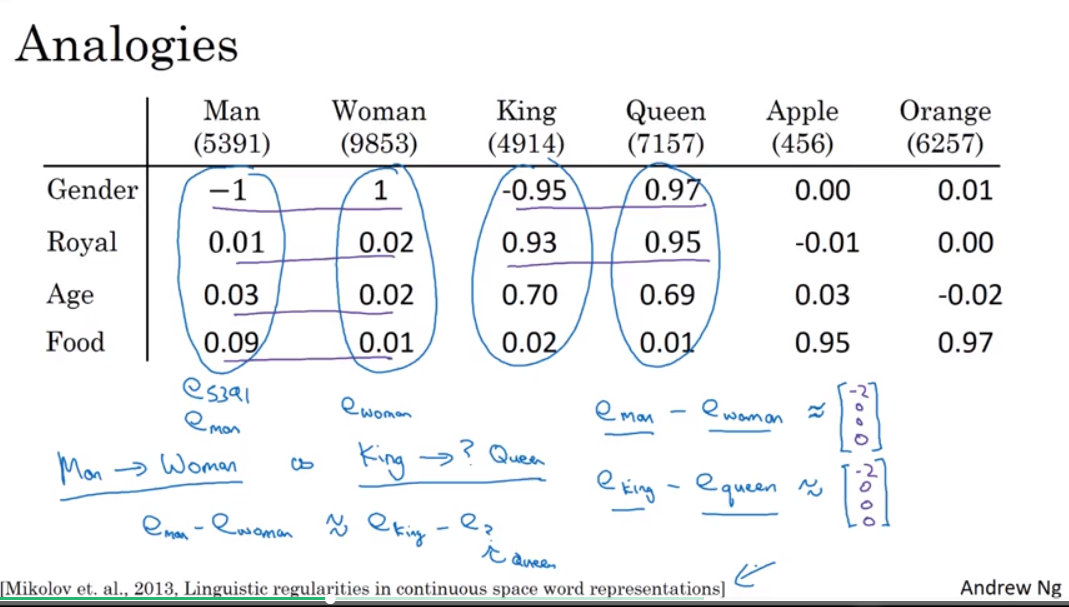
man 对应 woman,那么king对应什么?
可以通过embedding向量之间的difference来进行类比推理
Analogies using word vectors
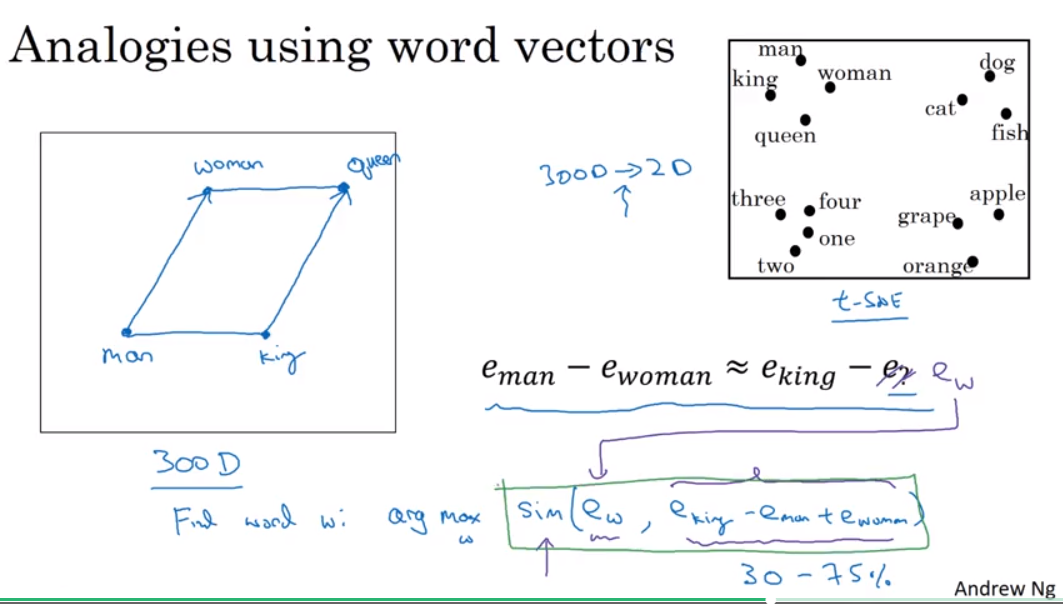
- 用word vector进行推理,选出其中具有最大相似度(注意这里的相似度指的的是哪两个对象之间的相似度)的word。
Cosine similarity

cosine相似度,同方向为1,垂直为0,反方向-1。比较流行的相似度指标。分子作的是inner product。
还有平方不相似度
4. Embedding matrix
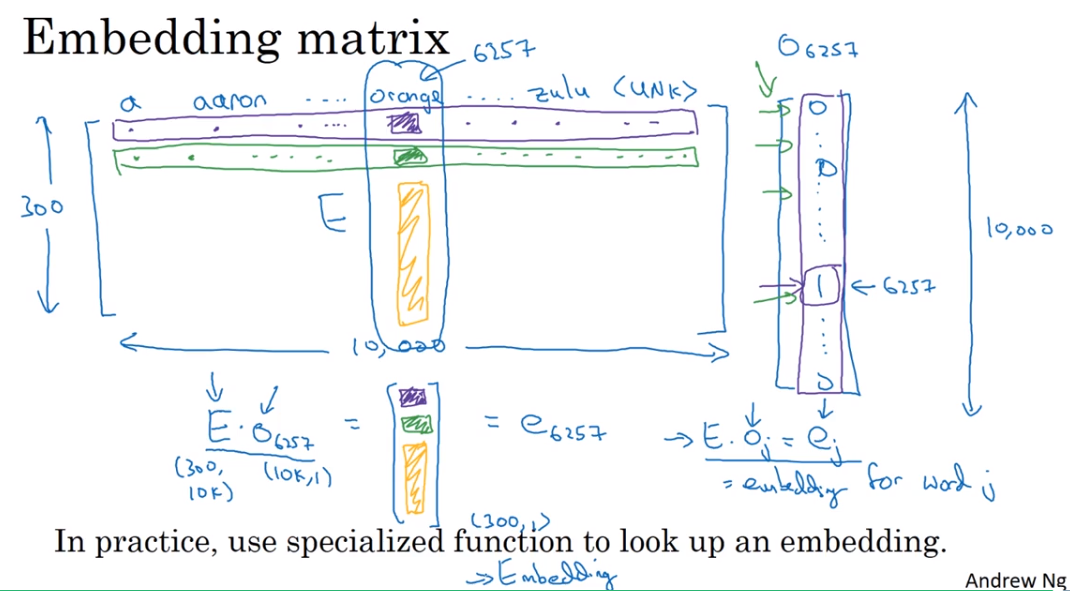
- 可以利用矩阵乘法取对应列的列向量,实际中远不用这么复杂。
Learning Word Embeddings: Word2vec & GloVe
1. Learning word embedding
Neural language model
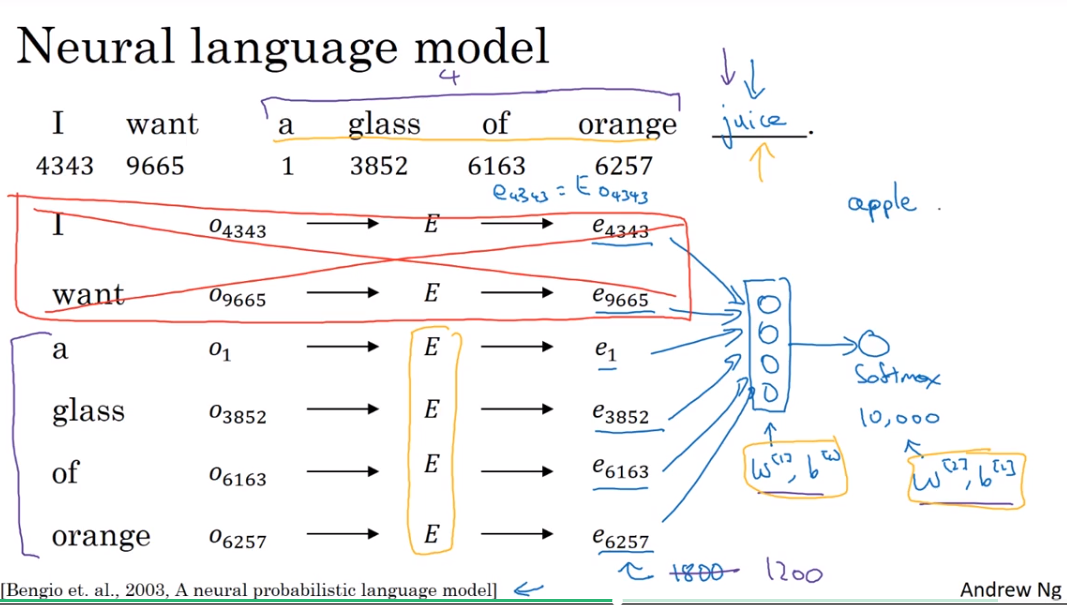
相当于是输入,是参数,利用反向传播更新。
可以只取取一定数量的words输入
Other context/target pairs

So what researchers found was that if you really want to build a language model, it's natural to use the last few words as a context. But if your main goal is really to learn a word embedding, then you can use all of these other contexts and they will result in very meaningful work embeddings as well.
2. Word2Vec
Skip-grams

And so we'll set up a supervised learning problem where given the context word, you're asked to predict what is a randomly chosen word within say, a plus minus ten word window, or plus minus five or ten word window of that input context word. And obviously, this is not a very easy learning problem, because within plus minus 10 words of the word orange, it could be a lot of different words. But a girl that's setting up this supervised learning problem, isn't to do well on the supervised learning problem per se, it is that we want to use this learning problem to learn good word embeddings.
- 给定一个context word,随机的选择一个target word,那么,这个target word会是哪一个呢?
Model
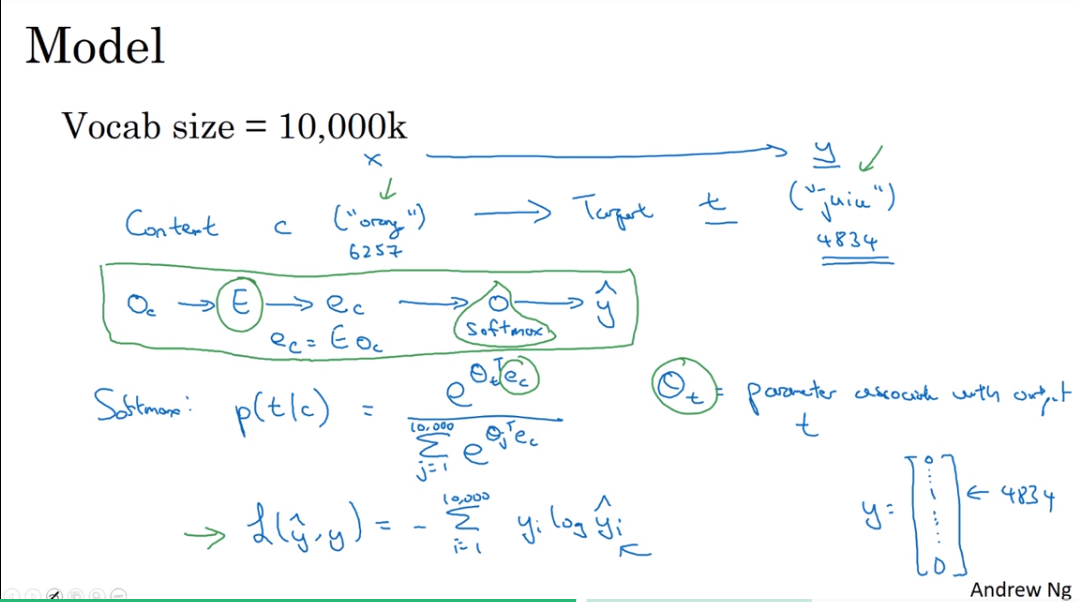
So this is called the skip-gram model because is taking as input one word like orange and then trying to predict some words skipping a few words from the left or the right side. To predict what comes little bit before little bit after the context words.
- 这张slide好像有问题,应该是 Vocab size = 10,000
Problems with softmax classification

And the primary problem is computational speed. In particular, for the softmax model, every time you want to evaluate this probability, you need to carry out a sum over all 10,000 words in your vocabulary. And maybe 10,000 isn't too bad, but if you're using a vocabulary of size 100,000 or a 1,000,000, it gets really slow to sum up over this denominator every single time. And, in fact, 10,000 is actually already that will be quite slow, but it makes even harder to scale to larger vocabularies.
计算开销大的问题
hierarchical softmax classifier
Imagine if you have one classifier, it tells you is the target word in the first 5,000 words in the vocabulary? Or is in the second 5,000 words in the vocabulary? And lets say this binary cost that it tells you this is in the first 5,000 words, think of second class to tell you that this in the first 2,500 words of vocab or in the second 2,500 words vocab and so on. Until eventually you get down to classify exactly what word it is, so that the leaf of this tree, and so having a tree of classifiers like this, means that each of the retriever nodes of the tree can be just a binding classifier.
In practice, the hierarchical software classifier can be developed so that the common words tend to be on top, whereas the less common words like durian can be buried much deeper in the tree. Because you see the more common words more often, and so you might need only a few traversals to get to common words like the and of. Whereas you see less frequent words like durian much less often, so it says okay that are buried deep in the tree because you don't need to go that deep. So there are various heuristics for building the tree how you used to build the hierarchical software spire.
如何sample context
But before moving on, one quick Topic I want you to understand is how to sample the context C. So once you sample the context C, the target T can be sampled within, say, a plus minus ten word window of the context C, but how do you choose the context C? One thing you could do is just sample uniformly, at random, from your training corpus. When we do that, you find that there are some words like the, of, a, and, to and so on that appear extremely frequently. And so, if you do that, you find that in your context to target mapping pairs just get these these types of words extremely frequently, whereas there are other words like orange, apple, and also durian that don't appear that often.
So in practice the distribution of words pc isn't taken just entirely uniformly at random for the training set purpose, but instead there are different heuristics that you could use in order to balance out something from the common words together with the less common words.
3. Negative Sampling
Defining a new learning problem
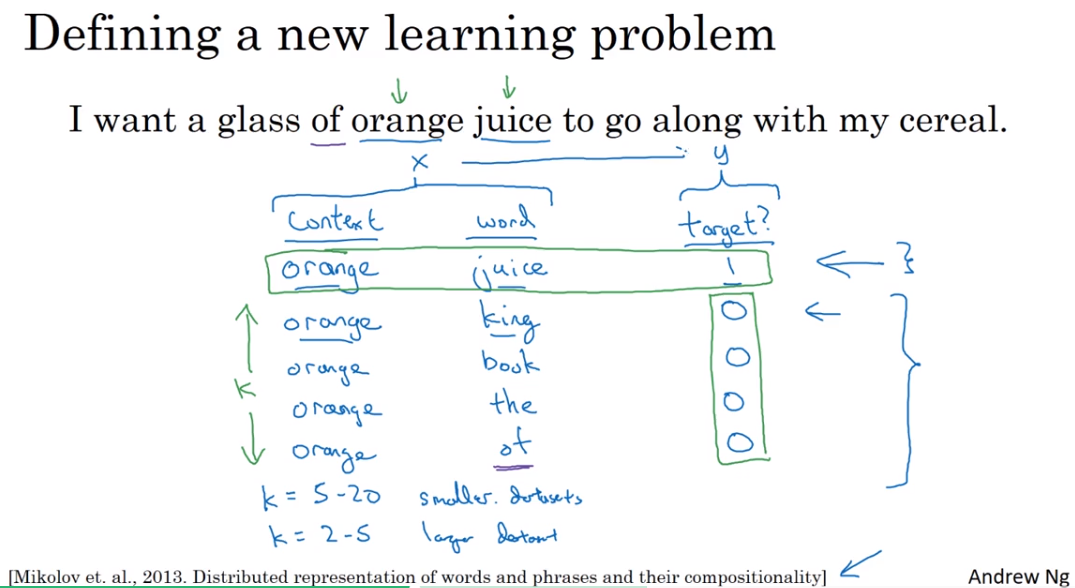
做什么呢?
So to summarize, the way we generated this data set is, we'll pick a context word and then pick a target word and that is the first row of this table. That gives us a positive example. So context, target, and then give that a label of 1. And then what we'll do is for some number of times say, k times, we're going to take the same context word and then pick random words from the dictionary, king, book, the, of, whatever comes out at random from the dictionary and label all those 0, and those will be our negative examples.
关于的取值
How do you choose k, Mikolov et al, recommend that maybe k is 5 to 20 for smaller data sets. And if you have a very large data set, then chose k to be smaller. So k equals 2 to 5 for larger data sets, and large values of k for smaller data sets. Okay, and in this example, I'll just use k = 4.
Model
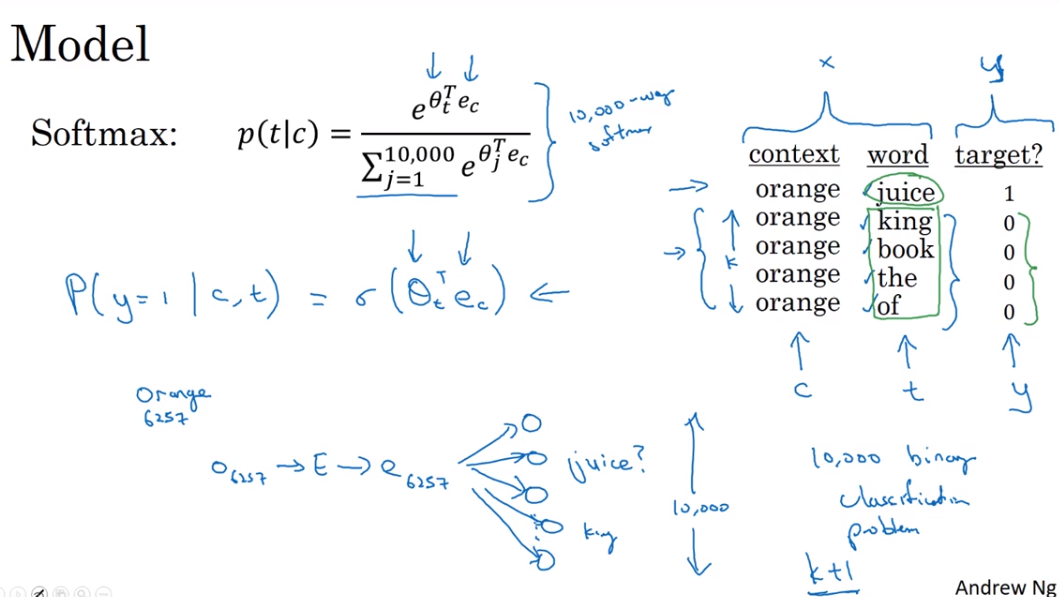
转化为1000个二分类问题 1000 binary classification problem
So think of this as having 10,000 binary logistic regression classifiers, but instead of training all 10,000 of them on every iteration, we're only going to train five of them. We're going to train the one responding to the actual target word we got and then train four randomly chosen negative examples. And this is for the case where k is equal to 4. So instead of having one giant 10,000 way Softmax, which is very expensive to compute, we've instead turned it into 10,000 binary classification problems, each of which is quite cheap to compute. And on every iteration, we're only going to train five of them or more generally, k + 1 of them, of k negative examples and one positive examples. And this is why the computation cost of this algorithm is much lower because you're updating k + 1, let's just say units, k + 1 binary classification problems. Which is relatively cheap to do on every iteration rather than updating a 10,000 way Softmax classifier.
怎么选择negative samples呢

根据word的出现频率来选择,不过是它的3/4次方。
And what they did was they sampled proportional to their frequency of a word to the power of three-fourths.
4. GloVe word vectors
GloVe(global vectors for word representation)

Although, if your choice of context was that, the context is always the word immediately before the target word, then X_ij and X_ji may not be symmetric like this. But for the purposes of the GloVe algorithm, we can define context and target as whether or not the two words appear in close proximity, say within plus or minus 10 words of each other. So, X_ij is a count that captures how often do words i and j appear with each other, or close to each other.
Model
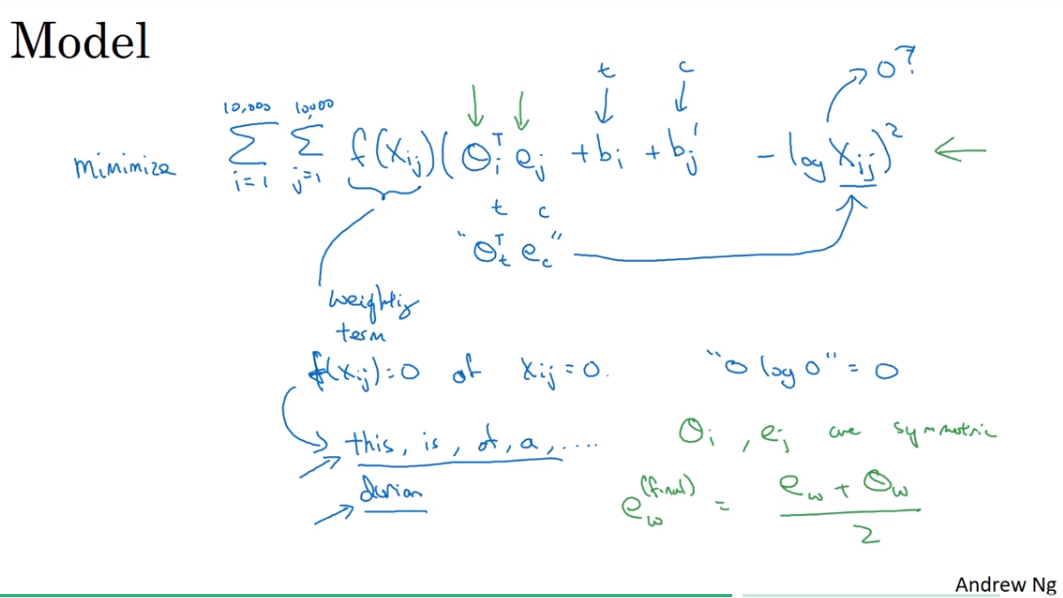
it works...
A note on the featurization view of word embeddings

But when you learn a word embedding using one of the algorithms that we've seen, such as the GloVe algorithm that we just saw on the previous slide, what happens is, you cannot guarantee that the individual components of the embeddings are interpretable. Why is that? Well, let's say that there is some space where the first axis is gender and the second axis is royal. What you can do is guarantee that the first axis of the embedding vector is aligned with this axis of meaning, of gender, royal, age and food. And in particular, the learning algorithm might choose this to be axis of the first dimension. So, given maybe a context of words, so the first dimension might be this axis and the second dimension might be this. Or it might not even be orthogonal, maybe it'll be a second non-orthogonal axis, could be the second component of the word embeddings you actually learn. And when we see this, if you have a subsequent understanding of linear algebra is that, if there was some invertible matrix A, then this could just as easily be replaced with A times theta i transpose A inverse transpose e_j. Because we expand this out, this is equal to theta i transpose A transpose A inverse transpose times e_j. And so, the middle term cancels out and we're left with theta i transpose e_j, same as before. Don't worry if you didn't follow the linear algebra, but that's a brief proof that shows that with an algorithm like this, you can't guarantee that the axis used to represent the features will be well-aligned with what might be easily humanly interpretable axis. In particular, the first feature might be a combination of gender, and royal, and age, and food, and cost, and size, is it a noun or an action verb, and all the other features. It's very difficult to look at individual components, individual rows of the embedding matrix and assign the human interpretation to that. But despite this type of linear transformation, the parallelogram map that we worked out when we were describing analogies, that still works. And so, despite this potentially arbitrary linear transformation of the features, you end up learning the parallelogram map for figure analogies still works. So, that's it for learning word embeddings. You've now seen a variety of algorithms for learning these word embeddings and you get to play them more in this week's programming exercise as well. Next, I'd like to show you how you can use these algorithms to carry out sentiment classification. Let's go onto the next video.
Applications using Word Embeddings
1. Sentiment classification
So one of the challenges of sentiment classification is you might not have a huge label data set. So for sentimental classification task, training sets with maybe anywhere from 10,000 to maybe 100,000 words would not be uncommon. Sometimes even smaller than 10,000 words and word embeddings that you can take can help you to much better understand especially when you have a small training set. So here's what you can do.
Simple sentiment classification model
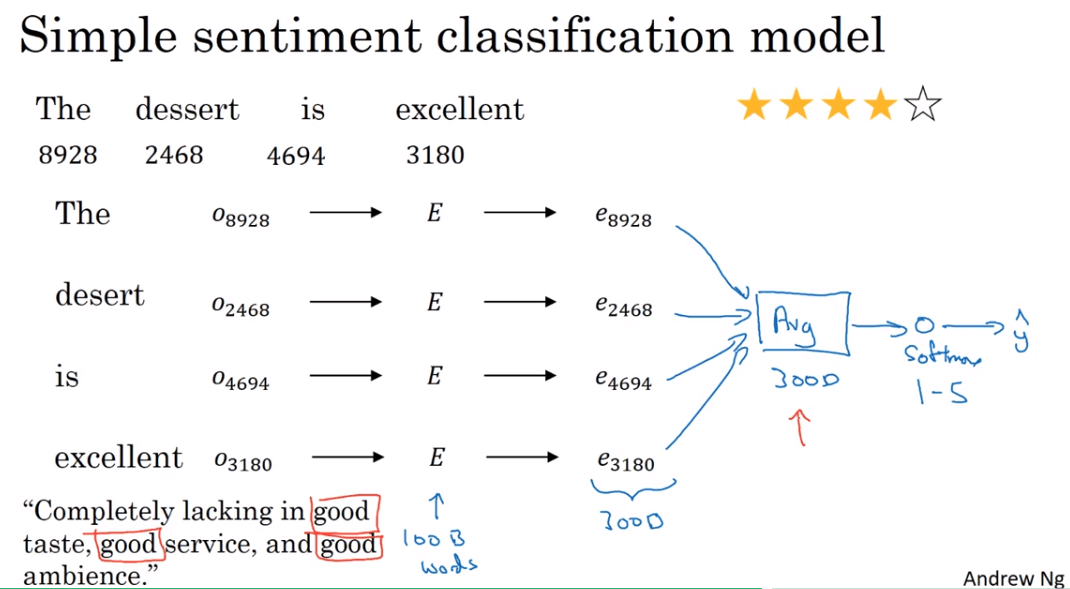
一个简单的sentiment classification模型,将featurized embedding求和或者求平均然后送入一个softmax单元
缺点是忽略了word的order,例如举的那个例子就很有可能出错(出现了多个word)。
RNN for sentiment classfication

- 这是一个典型的many-to-one的RNN结构。
2. Debiasing word embedding
Machine learning and AI algorithms are increasingly trusted to help with, or to make, extremely important decisions. And so we like to make sure that as much as possible that they're free of undesirable forms of bias, such as gender bias, ethnicity bias and so on. What I want to do in this video is show you some of the ideas for diminishing or eliminating these forms of bias in word embeddings. When I use the term bias in this video, I don't mean the bias variants. Sense the bias, instead I mean gender, ethnicity, sexual orientation bias. That's a different sense of bias then is typically used in the technical discussion on machine learning.
The problems of bias in word embeddings

- 一些有关性别歧视、种族歧视的bias。
p.s. 话说word embeddings是算法学出来的呀,这么说我们的语料库本身就体现了这些bias。
- 一些有关性别歧视、种族歧视的bias。
Addressing bias in word embedding

先是确定bias的方向,例如gender,可以
然后中立化,将不和gender相关的词投影到non-bias的方向上,例如beard,和性别有关,不用投影。
最后确保word pairs和某些word之间的距离相同。如grandfather,grandmother与babysitter之间的距离相同。
