@Team
2018-03-23T15:43:26.000000Z
字数 3213
阅读 3556
【(Keras/监督学习)15分钟搞定最新深度学习车牌OCR】
石文华
文章来源:https://hackernoon.com/latest-deep-learning-ocr-with-keras-and-supervisely-in-15-minutes-34aecd630ed8

大家好,本教程在15分钟之内为大家介绍如果使用深度学习来构建现代文本识别系统,你将学会如何使用keras和监督学习解决这个问题,本指南适合对深度学习进行图像文本识别技术感兴趣的人们。
思考现实世界中一个简单的例子:车牌识别,这是一个很好的起点,你可以轻松的使用它来定制你的任务,关于车牌识别简单的教程,你可以在这里找到它:https://towardsdatascience.com/number-plate-detection-with-supervisely-and-tensorflow-part-1-e84c74d4382c

当我们进入这个领域时,面临着网上资源缺乏的问题,通过长期的研究和阅读很多论文,对构建有效的识别系统的原理我们有了自己的理解,我们在社区中用了2个小时的视频讲座分享了我们的想法,并用简单的语言解释了它是如何工作的,我们觉得这个内容是非常有价值的,因为你很难找到关于如何构建现代识别系统方面好的资源和浅析,我们强烈建议你在开始这篇文章之前观看它,因为它会给你很多直观的认识。
要顺利完成本教程,你需要Ubuntu, GPU 和 Docker.
所有的资源都可以在github(https://github.com/DeepSystems/supervisely-tutorials)上找到。源代码位于一个单独的jupyther笔记本上(https://github.com/DeepSystems/supervisely-tutorials/blob/master/anpr_ocr/src/image_ocr.ipynb),并带有解释和必要的可视化。
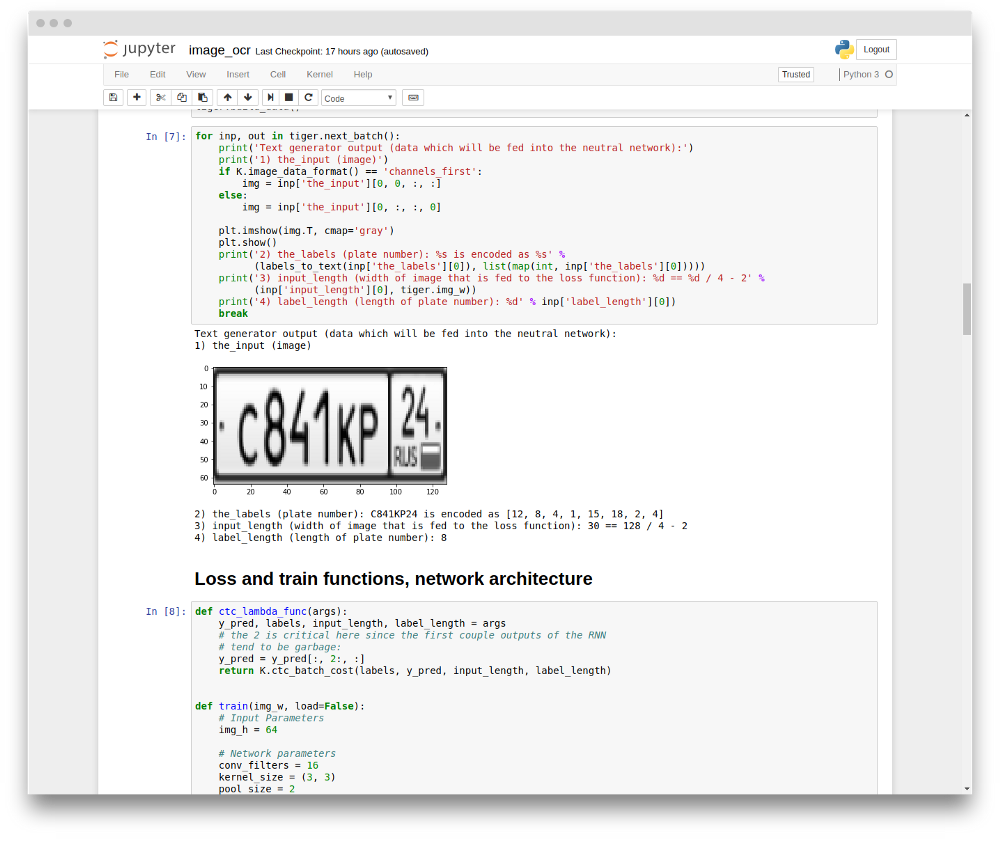
在哪里获得训练数据
对于本教程,我们人工生成了超过10k的图像数据集,它们跟真实的车牌非常相似,这些图片如下:

你可以很容易的从Supervisely(https://supervise.ly/)获取数据集,我们也在DeepSyetems(https://deepsystems.ai/)上做了很多像自动驾驶汽车,收据识别系统,道路缺陷检测等计算机视觉开发的案例。作为数据科学家,我们花费了很多时间处理训练数据集:创建自定义图像注释,将数据与公共数据集合并在一起,进行数据增强等,Supervisely这个网站简化了你使用训练数据,并自动执行许多日常任务。我们相信你会发现它真的很有用。
第一步是在Supervisely中注册。下一步是进入“导入” - >“数据集库”选项卡并单击“anpr_ocr”项目。
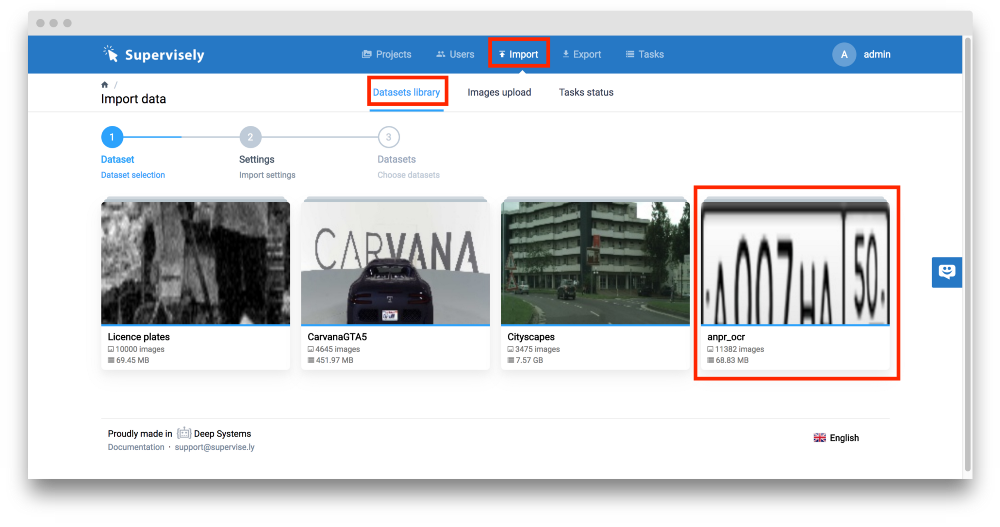
接着键入名称“anpr_ocr”并单击“下一步”按钮。

然后点击“上传”按钮,项目“anpr_ocr”就被添加到您的帐户。

它由两个数据集组成:“训练集”和“测试集”。
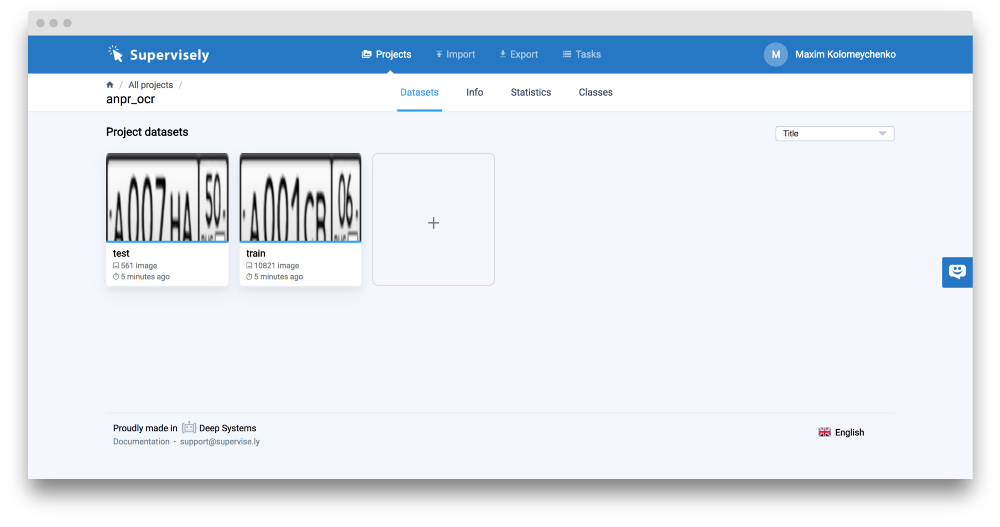
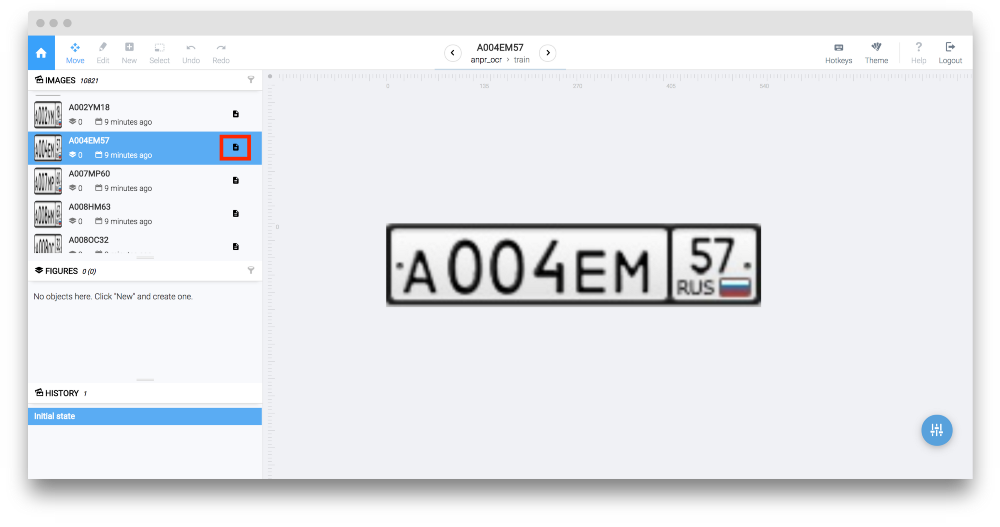
如果你想预览图像,只需点击数据集,你会立即进入注释工具。对每张图片,我们都会有一段文字说明,将用作地面实况来训练我们的系统。要查看它,只需点击所选图像对应的小图标(红色框所示)。
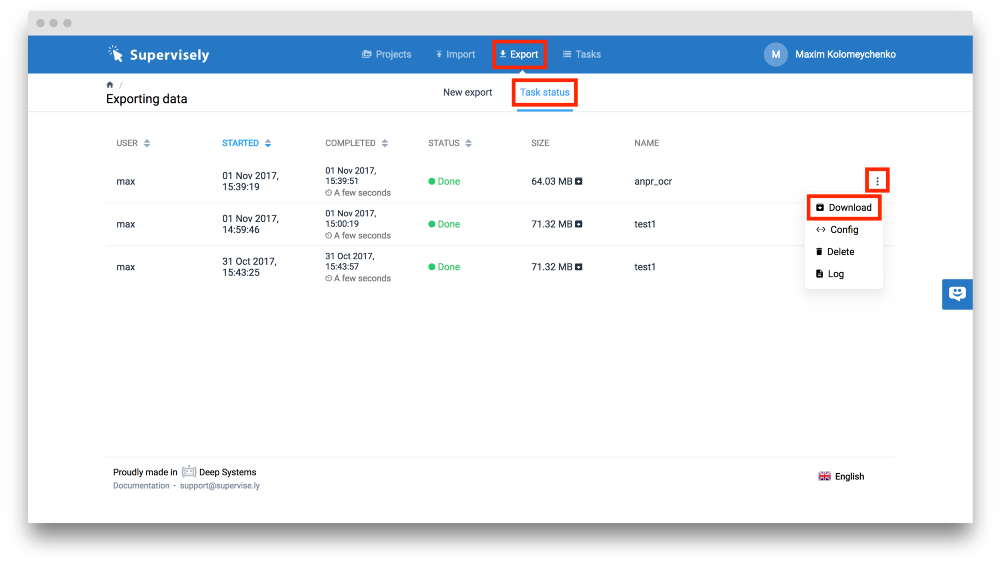
现在我们必须以特定格式下载它。要做到这一点,只需点击“导出”页面,并将此配置插入文本区域。如下图所示:

在上面的截图中,你可以看到说明导出步骤的方案,我们不会深入研究技术细节(如果需要,你可以阅读官方文档https://docs.supervise.ly/)但是你要认真理解下面的过程:在“anpr_ocr”项目中,有两个数据集,“测试”数据集按照原样导出,“Train”数据集被分为两组,“训练集”和“验证集”,“Train”中95%的作为训练集,5%作为验证集。
现在你可以点击“开始导出”按钮,等待两分钟,系统准备存档下载。点击下图红色框的按钮获取训练数据(以红色标记)。
开始我们的实验
我们在git仓库中准备了所有需要用到的东西。用下面的命令克隆它。
git clone https://github.com/DeepSystems/supervisely-tutorials.git
cd supervisely-tutorials/anpr_ocr
目录结构如下:
.
├── data
├── docker
│ ├── build.sh
│ ├── Dockerfile
│ └── run.sh
└── src
├── architecture.png
├── export_config.json
└── image_ocr.ipynb
将下载的压缩文件放入“data”这个目录并运行下面的命令。
unzip .zip -d .
我的例子中使用:
unzip test1–1703.zip -d .
现在让我们构建并运行准备好的工作环境(tensorflow和keras)。只需转到“docker”目录并运行以下命令:
./build.sh
./run.sh
之后,你将在容器内。运行下一个命令启动Jupyther笔记本
jupyter notebook
在终端,你将看到:

你必须复制选定的链接并将其粘贴到Web浏览器中。请注意,你的链接与我的略有不同。
最后一步是运行整个“image_ocr.ipynb”笔记本。点击“单元格” - >“全部运行”。
image_ocr.ipyn笔记本由几个主要部分组成:数据加载和可视化,模型训练,模型评估以及测试。此数据集训练过程大约需要30分钟。
如果运行正常,你会看到下面的输出:

正如你所看到的,预测的字符串将与地面实况相同。因此,我们在一个非常清晰的jupyther笔记本(https://github.com/DeepSystems/supervisely-tutorials/blob/master/anpr_ocr/src/image_ocr.ipynb)中构建了现代OCR系统。接下来,我们将介绍并解释它的工作原理。
它是怎样工作的
对我们来说,理解神经网络架构是关键。
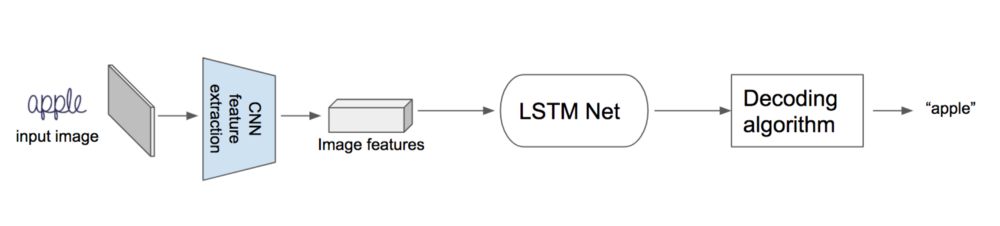
首先,将图像输入到CNN以提取图像特征。 接着将这些特征输入到循环神经网络中,然后经过特殊的解码算法。 这种解码算法从每个时间步获得lstm输出并产生最终标签。
详细的架构如下。 FC - 完全连接层,SM - softmax层。

图片的维度是高度为64,长度为128,通道数为3
上图可以看出我们的原始图片经过CNN特征提取之后,维度变成了4*8*4,在实际应用中,我们的输出特征图可能有很多,也就是图片长宽在缩小,但是我们的特征图的深度在增加。
接着进行维度转换操作。得到16*8的向量序列,上图所示,有8个列向量,每个列有16个元素。 我们将这8个列向量输入LSTM网络并获得输出。 然后,我们使用全连接层+softmax层,并获得6个元素的向量。 该向量里面元素的含义是每个LSTM步骤预测的字母符号的概率。
在实际问题中,CNN输出向量的数量可以达到32,64甚至更多。所以最好使用多层双向LSTM。
如何解析得到的预测结果呢?如下图所示,我们输出了8个概率值,我们将连续的重复字符去掉,以及删除空格等特殊的字符,最后合并成一个字符串输出,也就是我们的预测结果。
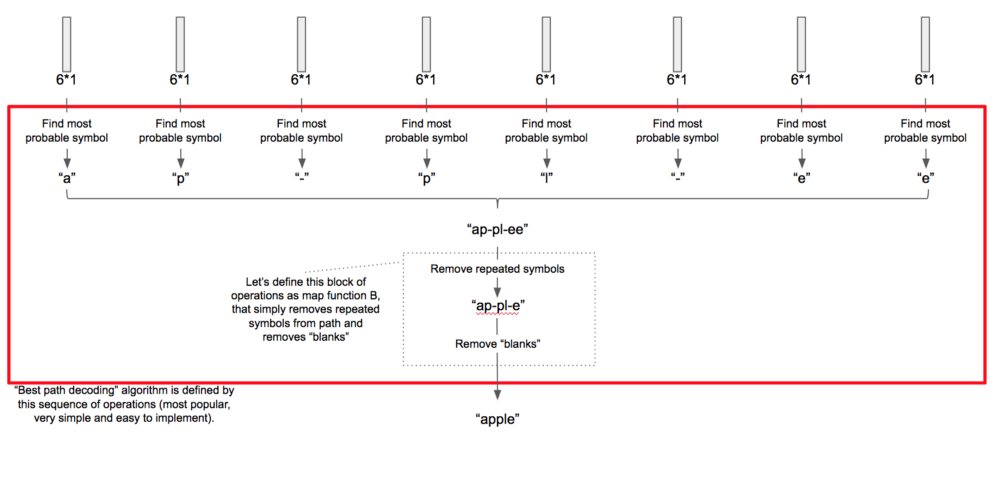
我们在训练网络的时候,使用了CTC损失层代替了解码算法,我们在第二个幻灯片上提到过,虽然现在只有俄语版本,但是我们有英文幻灯片,并且很快发布英文版。
在实际中我们使用了更加复杂的NN价架构,如下图所示,但是原理的基本思想是相同的。
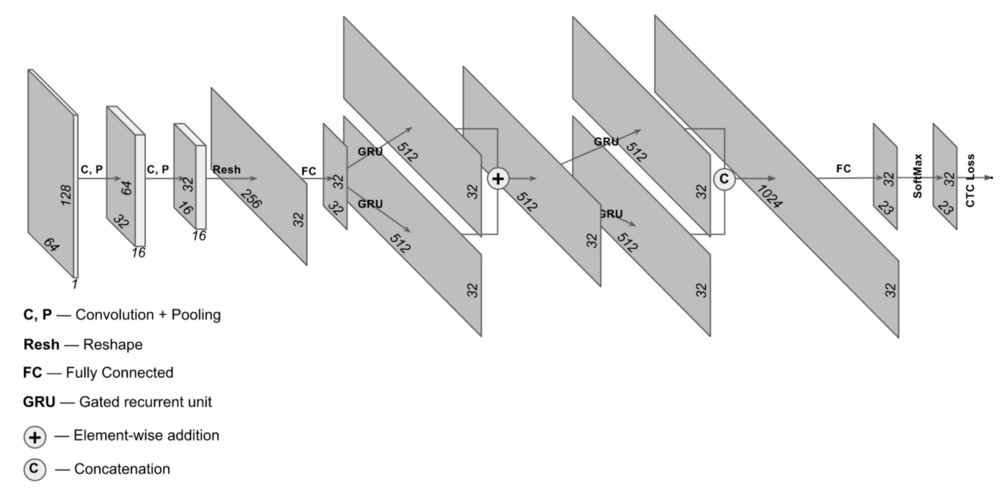
训练好模型之后,模型在测试集上也得到了很高的准确率, 我们将每个RNN步骤的概率分布可视化为一个矩阵。如下图所示:

上图的纵坐标是预测的符号和空白,横坐标表示时序。也就是输出结果的顺序。
总结:
我们很高兴在社区分享我们的经验。我们希望视频讲座和本教程,以及我们的数据和源代码将带你入门图像文字识别,并且希望每个人都可以从头开始构建现代OCR系统。
