@Team
2019-11-09T12:16:44.000000Z
字数 4388
阅读 3848
《从零开始学习自然语言处理(NLP)》-BERT推理加速实践(6)
刘才权
BERT推理加速的理论可以参考之前的博客《从零开始学习自然语言处理(NLP)》-BERT模型推理加速总结(5)。这里主要介绍基于Nvidia开源的Fast Transformer,并结合半精度模型量化加速,进行实践,并解决了TensorFlow Estimator预测阶段重复加载模型的问题。主要包括:
环境搭建
Pre-train模型获取
结合自身业务Fine-tuning
模型单精度(FP32)转半精度(FP16)
Fast-transformer编译
Fast-transformer集成
TensorFlow estimator线上推理
下面逐个进行介绍。
环境搭建
BERT的Fine-tuning需要GPU环境(CPU训练估计要慢到天长地久),而GPU的环境配置又相对麻烦。除了显卡驱动外,还需要对应版本的安装CUDA、CUDNN、Python、TensorFlow-GPU。版本不匹配很容易出问题。简单的环境搭建,推荐直接使用Nvidia的NGC镜像。针对BERTFine-tuning(Pre-train同样适用),本文中使用Docker镜像:nvcr.io/nvidia/tensorflow:19.10-py3(镜像说明:https://ngc.nvidia.com/catalog/containers/nvidia:tensorflow)。
镜像主要包括:
- Python 3.6.8
- Tensorflow-estimator 1.14.0
- Tensorflow-gpu 1.14.0+nv
- TensorRT 6.0.1(Fast transformer基于TensorRT实现,需要依赖TensorRT)
Pre-train模型获取
中文的BERT预训练模型直接从google-research/bert获得即可,具体地址:https://github.com/google-research/bert
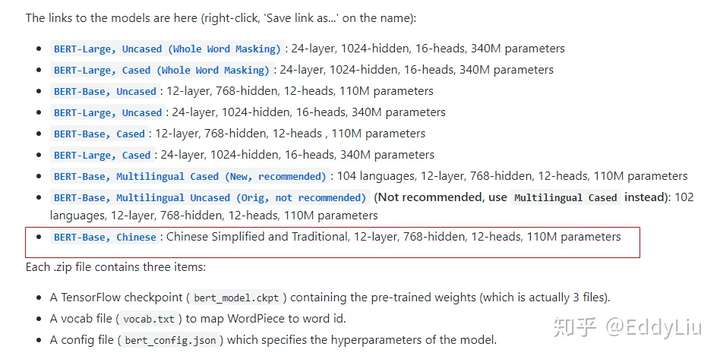
结合自身业务Fine-tuning
Fine-tuning主要是根据自己的使用场景,修改训练的数据读取逻辑,这里以文本分类(多分类、单标签)为例进行展开。文本分类的入口是run_classifier.py文件,主要增加一个自定义的数据获取类,比如,
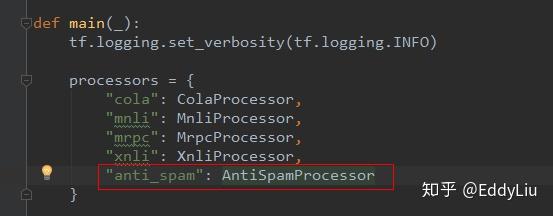
其中,
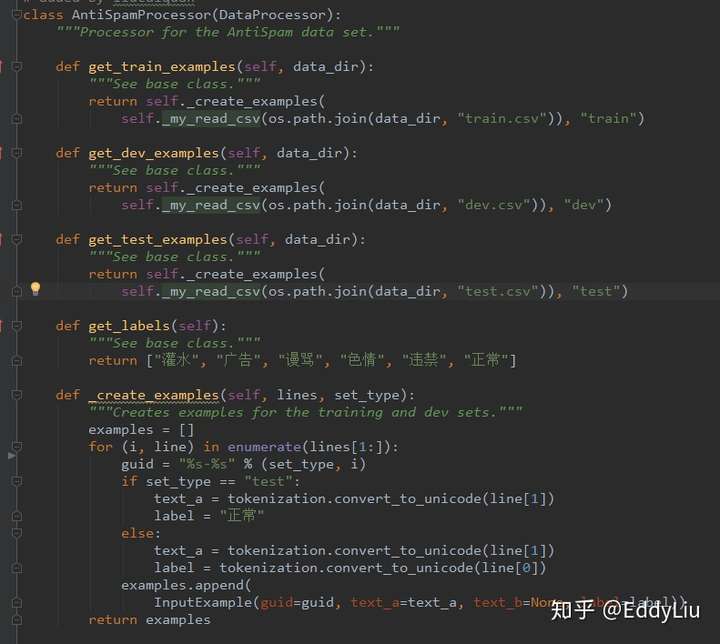
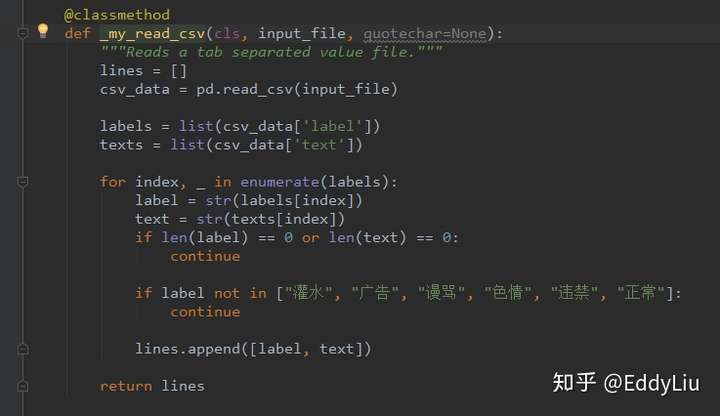
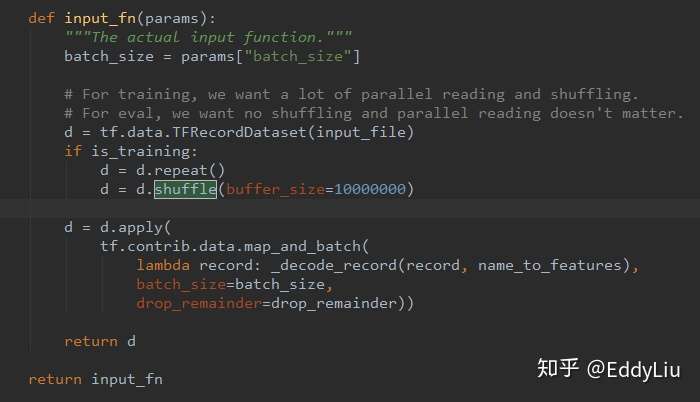
需要注意的是,如果训练样本提前没有进行shuffle操作,可以将代码中的shuffle值修改的大一些,否则,训练结果会很差,比如,
Fine-tuning的代码可以使用Google官方的代码(代码地址:https://github.com/google-research/bert),也可以使用Nvidia提供的BERT代码(代码地址:https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT)。
Nvidia代码的优点是方便配置,比如:
混合精度:加快训练速度
XLA优化:后面使用Fast Transformer加速,不建议打开这个选项,担心XLA的网络优化,会导致Fast Transformer参数初始化失败。(没有通过实验验证,不确定真实的结果)。
Fine-tuning后的模型会发现变大很多,比如BERT的中文预训练模型大小为393M,Fine-tuning后居然变成了1.2G。这么大的变化,主要由于训练过程中的checkpoints由于包含了每个权重变量对应的Adam momentum和variance变量。具体可以参考《BERT-TensorFlow版微调后模型过大解决方案》。
模型单精度(FP32)转半精度(FP16)
Fine-tuning后的模型默认是FP32保存的,在服务上线进行推理阶段,要先转换成半精度(FP16),从而加快推理速度。
TensorFlow提供了半精度转换的API,具体参考《TensorFlow 模型优化工具 — float16 量化将模型体积减半》。
这里没有使用TensorFlow的API,而是,使用了Nvidia Fast transformer提供的方法(ckpt_type_convert.py):

解释地址:https://github.com/NVIDIA/DeepLearningExamples/blob/master/FasterTransformer/sample/tensorflow_bert/sample.md
ckpt_type_convert.py地址:https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer/sample/tensorflow_bert
Fast-transformer编译
Fast-transformer由C++编写实现,使用前需要先进行编译。
编译环境之间使用当前的Docker环境即可,需要注意的是要先下载TensorRT的压缩包。虽然环境中已经有了TensorRT,但为了方便起见,还是直接下载一个(直接编译会出错)。注意对齐环境中的TensorRT版本(环境中使用的是TenorRT6.0版本)。
TensorRT下载地址:https://developer.nvidia.com/tensorrt
编译命令:
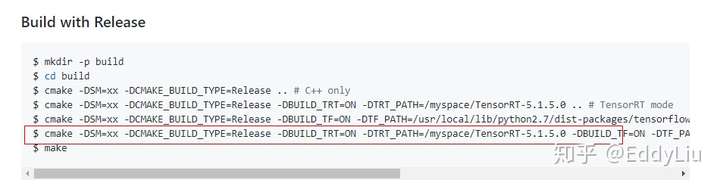
命令地址:https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer
要正常使用Fast transformer还需要gemm_config.in文件,这个文件通过命令生成:
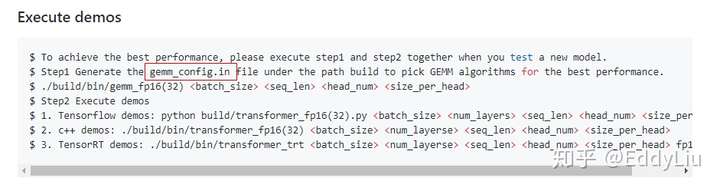
命令地址:https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer
Fast-transformer集成
Fast transformer的集成相对简单,直接将DeepLearningExamples/FasterTransformer/sample/tensorflow_bert/目录中的内容,拷贝到BERT源码目录即可。这里需要注意的是拷贝到google-research/bert的官方源码目录,而不是NVIDIA/DeepLearningExamples的BERT源码目录。
拷贝到后者中,会运行出错(Fast transformer Demo应该是基于Google官方BERT源码实践的)。
同时,需要注意的是上一个步骤中生成的C++层Fast transformer动态链接库,以及gemm_config.in文件的位置。
C++层Fast transformer动态链接库引用:
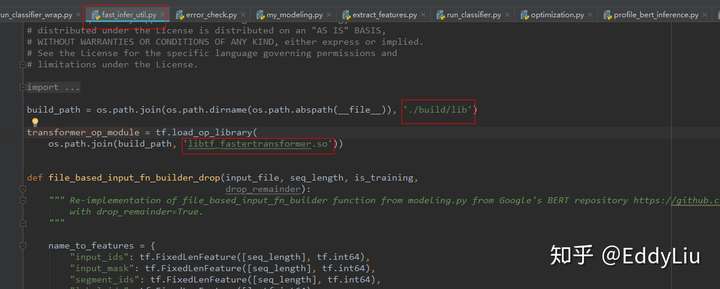
gemm_config.in文件放在源码目录下即可(执行命令的根目录)。
最后,设置
FLAGS.floatx = 'float16'
从而开启半精能力。
总结下Fast transformer集成需要的注意点:
- 1 Fast transformer example代码拷贝到Google的BERT官方源码中;
- 2 包含libtf_fastertransformer.so的build文件放置在正确位置;
- 3 http://gemm_config.in文件放置在执行命令的目录;
- 4 设置FLAGS.floatx = 'float16',开启半精推理能力;
TensorFlow estimator线上推理
Google官方的BERT是基于Estimator实现的,但Estimator的模型训练、评估、预测,每次都要重新加载模型。这对于实时的线上预测任务是不能接受的。需要将Estimator的预测部分进行修改,每次推理预测时不重新加载模型。具体的实现可以参考《TensorFlow关于怎样解决Estimater.predict总是重新加载模型的问题》。实际上,这篇博客的实现主要是参考了一个很棒的gitlab开源项目hanxiao/bert-as-service。
基于Fast transformer推理速度:
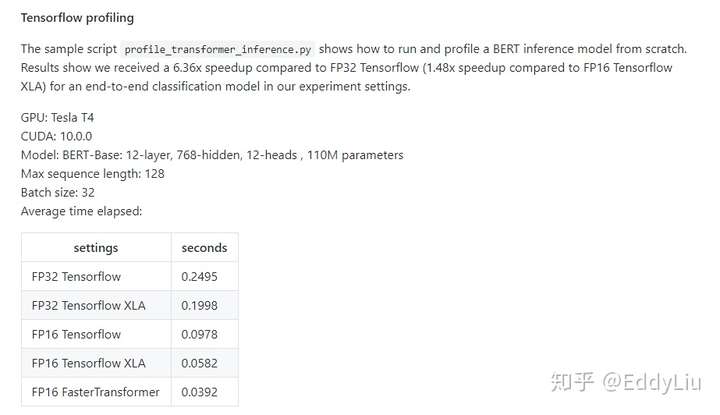
数据来源:https://github.com/NVIDIA/DeepLearningExamples/blob/master/FasterTransformer/sample/tensorflow_bert/sample.md
小结
本文基于Nvidia的Fast transformer,详细介绍了BERT推理加速优化的完整步骤,包括环境搭建、Pre-train模型获取、结合自身业务Fine-tuning、模型单精度(FP32)转半精度(FP16)、Fast-transformer编译、Fast-transformer集成、TensorFlow estimator线上推理等步骤,以及其中需要注意的问题,为BERT推理服务上线提供参考。
参考资料
《BERT-TensorFlow版微调后模型过大解决方案》:https://blog.csdn.net/ljp1919/article/details/100652794
《TensorFlow 模型优化工具 — float16 量化将模型体积减半》:https://mp.weixin.qq.com/s?__biz=MzU1OTMyNDcxMQ==&mid=2247486633&idx=1&sn=18d8541781f48d4d845c93473cd27bcb&chksm=fc1847e1cb6fcef7617832b538751ed7731755d2bcb052f0005c8736c866b2153c87484a680d&scene=0&xtrack=1&key=6ccb298b02eeb1eb594dec195455c03b8590cecdfa74d520f2ac3ffa3045a6a68fecf770f1ffe514191634410c0b511057cf428acc0d07c8686e77b626052a5a076801f3e0dbed26e3c7f9ed9fc270f1&ascene=1&uin=MTU2Nzk1MDIyMA%3D%3D&devicetype=Windows+10&version=62070152&lang=zh_CN&pass_ticket=%2BEHBIFHwjhPmTTiowh%2FkWmCf9eVl%2BAYiX2jsbCe13wDg%2FyRzwrFbvFs7zf4i3icO
《TensorFlow关于怎样解决Estimater.predict总是重新加载模型的问题》:https://blog.csdn.net/hezhefly/article/details/98877796
