@Team
2020-07-26T17:08:01.000000Z
字数 8423
阅读 3259
GAN IN ACTION-第1部分 GAN和生成模型的简介
陈扬
翻译:Marcus·Yang
前言:正如我先前说的那样,我决定翻译这本在 GAN 领域出版的第一本系统性概括其发展的书籍,给大家深入学习生成对抗网络提供帮助,在第一版的翻译中我将统一使用 pytorch 代码代替作者原有的代码(原有代码版本混乱且框架不止一个,而且译者个人喜欢 pytorch).
第1部分介绍了生成对抗网络(GAN),并逐步介绍了最经典的GAN变体的实现:
在第1章中,您将学习GAN的基础知识,并对它们的工作方式有一个直观的了解。
在第2章中,我们将稍作切换,并介绍自动编码器,以便您可以更全面地了解生成模型。自编码机(autoencoders)是GAN最重要的理论和实践先驱,至今仍在广泛使用。
第3章从第1章开始,我们开始更深入地探讨GAN和对抗性学习的基础理论。在本章中,您还将实现和培训您的第一个功能齐全的GAN。
第4章通过探索深度卷积GAN(DCGAN)继续您的学习旅程。在原始GAN之上的这项创新性地使用了卷积神经网络来提高生成图像的质量。
第1章:GAN的简介
本章节包括:
- 生成对抗网络概述
- 是什么让这类机器学习算法如此与众不同?
- 一些有趣的GAN应用程序
"机器是否可以思考这个想法比计算机本身更古老。" 在1950年,著名的数学家,逻辑学家和计算机科学家艾伦·图灵(Alan Turing)以在解码纳粹战时加密机Enigma中的作用而闻名,他写了一篇论文,此书将使他的名字永生不朽:“Computing Machinery and Intelligence.”
在这篇论文中,图灵提出了一个他称为"模仿游戏"的测试,如今更名为图灵测试。在这种假设的情况下,一个不知情的观察者在门后与两个人交谈:其中一个是同伴,另一个是计算机。图灵解释说,如果观察者无法分辨出哪个人是哪个机器,那台计算机就通过了测试并且必须被认为是智能的。
任何尝试与自动聊天机器人或语音驱动的智能助手进行对话的人都知道,计算机要通过这种看似简单的测试还有很长的路要走。但是,在其他任务中,计算机不仅与人类的表现相匹配,而且甚至超过了人类的表现,甚至在直到最近才考虑到的领域,即使是最智能的算法也无法实现,例如超精确的人脸识别或精通游泳的 GO。[1]
机器学习算法非常擅长识别现有数据中的模式,并将这种洞察力用于诸如分类(为示例分配正确的类别)和回归(根据各种输入估算数值)等任务。但是,当要求生成新数据时,计算机还仍需要努力。也行一种算法可以打败国际象棋大师,估算股票价格走势,并对信用卡交易是否可能是欺诈进行分类。相反,任何尝试在与亚马逊的Alexa或苹果的Siri闲聊都注定了。确实,人类最基本和最基本的能力(包括欢乐的交谈或原创作品的手工制作)甚至可以使最复杂的超级计算机陷入数字痉挛。
2014年,当时蒙特利尔大学的博士生Ian Goodfellow发明了Generative Adversarial Networks(GAN),这一切都改变了。这种技术使计算机能够使用一个或两个独立的神经网络来生成现实数据。 GAN并不是用于生成数据的第一个计算机程序,但是GAN的结果和多功能性使其与所有其他计算机区分开。 GAN已取得了卓越的结果,长期以来人们一直认为对于人工系统来说这几乎是不可能的,例如能够生成具有真实世界般质量的伪图像,将涂鸦转换为照片图像或将马的视频片段转换为视频的能力。一匹正在奔跑的斑马线-无需大量苦心经营的带有标签的训练数据。

图1.1说明了人脸的合成,这是通过GAN可以将机器数据生成推进多远的一个示例。直到2014年,当GAN发明时,机器所能产生的最佳效果是模棱两可的,甚至被誉为开创性的成功。短短三年后的2017年,GAN的发展使计算机能够合成伪造高分辨率的面孔,其质量可与高分辨率的人像照片相媲美。在本书中,我们将深入探讨使如何使这些成为可能的算法。
1.1. 生成式对抗网络是什么?
生成对抗网络(GANs)是一类机器学习技术,由两个同时训练的模型组成:一个训练模型(生成器)以生成假数据,另一个训练模型(判别器)以判别数据的真假。
一言概括模型的目的:创建新数据。 由GAN生成的数据取决于训练集的选择。例如,如果我们要让GAN合成达芬奇的图像,可以使用达芬奇艺术品(da Vinci’s artwork)的数据集训练.
"对抗"一词指的是构成GAN框架的两种模型(生成器和判别器)之间的博弈式动态竞争。生成器的目标是创建与训练集中的真实数据一样的示例(example)。在我们刚刚举出的例子中,这意味着制作出看起来像达芬奇的画。判别器的目的是将生成器生成的虚假示例(fake example)与训练数据集中的真实示例(ground truth)区分开。在我们的例子中,判别器扮演着一个"艺术专家"的角色,负责评估输入图片被认为是达芬奇作品的真实性。这两个网络一直在相互竞争:生成器在创建令人信服的数据方面越出色,判别器在区分真实实例与虚假实例方面就需要越出色。
最后,“网络”一词表示最常用于表示生成器和判别器的机器学习模型的类别:神经网络。根据GAN实现的复杂性,这些范围可以从简单的前馈神经网络(如您将在第3章中看到)到卷积神经网络(如您将在第4章中看到),甚至可以是更复杂的变体,例如作为U-Net(您将在第9章中看到)。
1.2. GANS如何运作?
GAN的数学基础很复杂(您将在后面的章节中,特别是第3和5章中进行探讨);幸运的是,许多现实世界的类比都可以使GAN更易于理解。之前,我们讨论了一个艺术伪造者(生成器)试图欺骗艺术专家(判别器)的例子。伪造者制作的假画越以假乱真,艺术专家必须越能确定其真实性。在相反的情况下也是如此:艺术专家越能分辨一幅特定的绘画是否真实,伪造者就必须改善得越多,以免被人抓到。
经常用来形容GAN的另一个比喻是Ian Goodfellow自己喜欢使用的一个隐喻,是犯罪分子(Generator)伪造金钱,而侦探(Discriminator)试图抓住他。假钞的外观越真实,侦探就必须更好地识别它们,反之亦然。
用更多的技术术语来说,生成器的目标是制作一些示例来捕获训练数据集的特征,以至于它生成的样本看起来与训练数据没有区别。相反,可以将生成器视为对象识别模型。对象识别算法学习图像中的图案以识别图像的内容。生成器不是识别模式,而是学习从头开始创建它们。实际上,生成器的输入通常只不过是一个随机数向量(noise)。
生成器通过从判别器分类中获得的反馈来学习。判别器的目标是确定特定示例是真实的(来自训练数据集)还是伪造的(由生成器创建)。因此,每当判别器被欺骗以将假图像分类为真实图像时,生成器就知道它做得很好。相反,每次判别器正确拒绝生成器生成的图像为伪造图像时,生成器都会收到需要改进的反馈。
判别器也在继续改进。像任何分类器一样,它可以从预测值到真实标签(真实标签或假标签)的距离中学习。因此,随着生成器在生成逼真的数据方面变得更加出色,判别器在从真实数据中辨别出虚假数据方面也变得更加出色,并且两个网络都在同时不断改进。
表1.1总结了有关这两个GAN子网的主要内容。
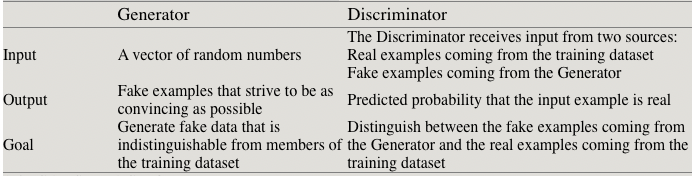
表1.1.生成器和判别器子网
1.3. GANS IN ACTION
现在,您已经对GAN及其组成网络有较高的了解,下面让我们详细了解一下正在运行的系统。想象一下,我们的目标是教GAN生成看起来逼真的手写数字(MNIST)。 (您将在第3章中学习实现这种模型,并在第4章中对其进行扩展。)
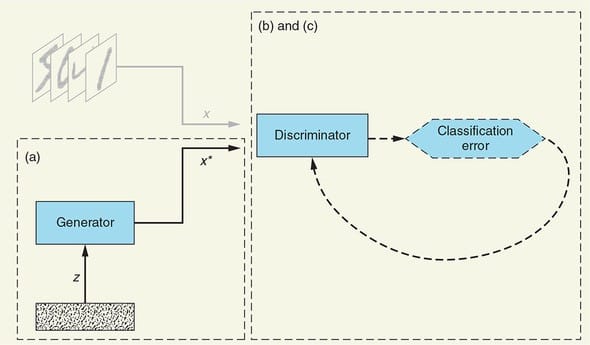
图1.2说明了GAN的核心架构。
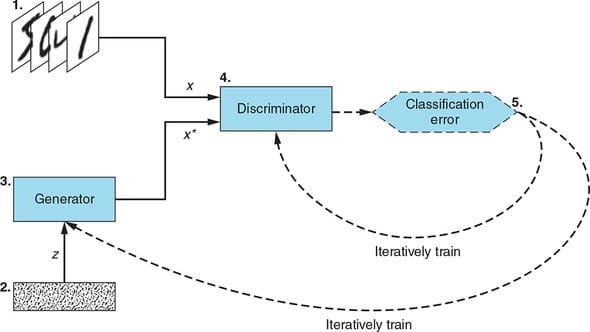
图1.2.这两个GAN子网,它们的输入和输出以及它们之间的相互作用
让我们来看一下图表的详细信息:
训练数据集(Training dataset)--我们希望生成器学习以接近完美的质量进行模拟的真实示例的数据集。在这种情况下,数据集由手写数字图像(MNIST)组成。该数据集用作判别器网络的输入。
随机噪声向量(Random noise vector)--生成网络的原始输入。此输入是随机数向量,发生器将其用作合成假示例的起点。
生成器网络(Generator network)--生成器接收随机噪声向量作为输入,并输出伪造的示例。它的目标是使生成的虚假示例与训练数据集中的真实示例无法区分。
判别器网络(Discriminator network)--判别器将来自训练集的真实示例或生成器生成的虚假示例作为输入。对于每个示例,判别器确定并输出该示例是否真实的概率。
迭代训练/调整(Iterative training/tuning)--对于判别器的每个预测,我们确定其效果(与常规分类器一样),并使用结果通过反向传播迭代地调整判别器和生成器网络:
判别器的权重和偏差会更新,以最大程度地提高分类准确度(最大程度地提高正确预测的概率:为真值,为假值)。
生成器的权重和偏差会更新,以使判别器将错误分类为实数的可能性最大化。
1.3.1. GAN训练
为了了解GAN的各个组成部分。这就是本节的全部内容。首先,我们提出GAN训练算法;然后,我们说明了训练过程,以便您可以看到实际的架构图。
GAN training algorithm
For each training iteration do
- Train the Discriminator:
- Take a random real example x from the training dataset.
- Get a new random noise vector z and, using the Generator network, synthesize a fake example
- Use the Discriminator network to classify and
- Compute the classification errors and backpropagate the total error to update the Discriminator’s trainable parameters, seeking to minimize the classification errors.
- Train the Generator:
- Get a new random noise vector z and, using the Generator network, synthesize a fake example .
- Use the Discriminator network to classify
- Compute the classification error and backpropagate the error to update the Generator’s trainable parameters, seeking to maximize the Discriminator’s error.
End for
GAN训练的可视化
图1.3 说明了GAN训练算法。图中的字母表示GAN训练算法中的步骤列表。
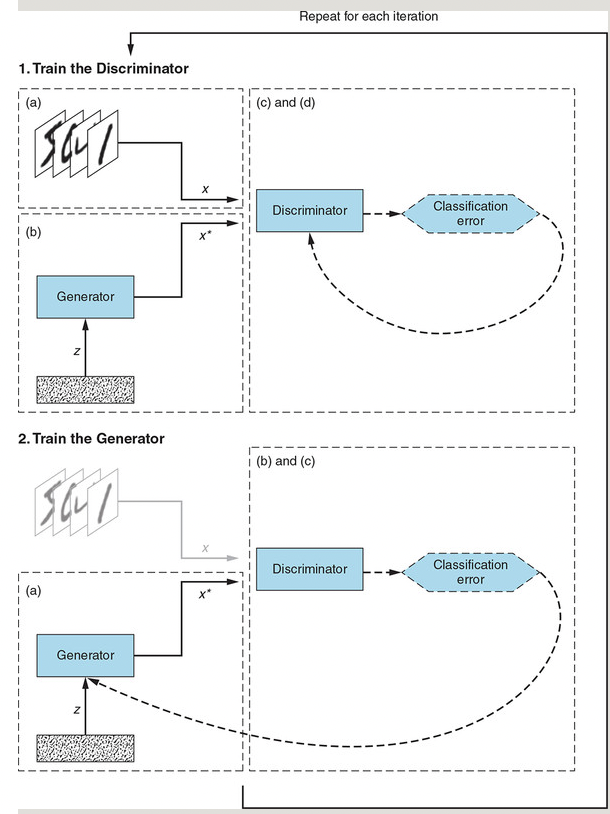
图1.3. GAN训练算法有两个主要部分。判别器训练和生成器训练这两个部分在训练过程的相应阶段中的不同时间快照处描绘了相同的GAN网络。
训练判别器
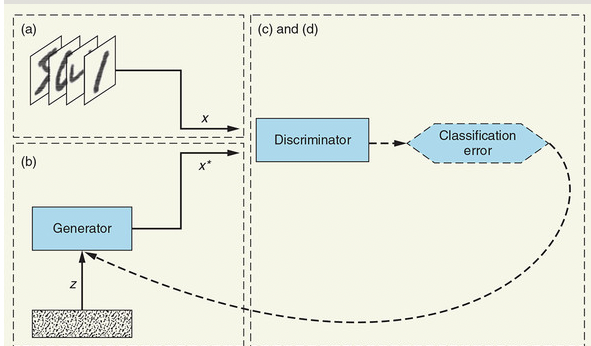
- 从训练数据集中获得一个随机的真实示例。
- 获得一个新的随机噪声向量,并使用生成器网络合成一个虚假示例。
- 使用判别器网络对和进行分类。
- 计算分类误差并反向传播总误差,以更新判别器的权重和偏差,力求最大程度地减少分类误差。
训练生成器
- 获得一个新的随机噪声矢量,并使用Generator网络合成一个伪示例。
- 使用判别器网络对进行分类。
- 计算分类误差,然后反向传播该误差,以更新生成器权重和偏差,以求使判别器误差最大化。
(译者也不知道作者这两段在扯啥,我简要的说一下就是,训练判别器的时候,把虚假标签当成 0,真实标签当成1,在训练生成器的时候把虚假标签当成 1)
1.3.2. 达到平衡
您可能想知道GAN训练循环何时停止。更准确地说,如何知道GAN何时经过全面训练,以便我们可以确定适当的训练迭代次数?使用常规的神经网络,我们通常有一个明确的目标可以实现和衡量。例如,在训练分类器时,我们在训练和验证集上测量分类误差,并在验证误差开始恶化时停止处理(以避免过度拟合)。在GAN中,两个网络具有相互竞争的目标:当一个网络变得更好时,另一个网络变得更糟。我们如何确定何时停止?
那些熟悉博弈论的人可能会将此设置视为零和博弈的一种情况,其中一个玩家的收益等于另一个玩家的损失。当一个玩家提高一定程度时,另一位玩家恶化同样程度。所有零和游戏都具有纳什均衡,在这一点上,任何玩家都无法通过改变其行为来改善其处境或收益。
满足以下条件时,GAN达到Nash平衡:
"生成器生成的虚假示例与训练数据集中的真实数据无法区分。"
判别器最多可以随机猜测一个特定示例是真实的还是假的(即,以50/50的比例猜测一个示例是真实的)。
Note
纳什均衡是以美国经济学家和数学家约翰·福布斯·纳什(John Forbes Nash Jr.)的名字命名的,他的生平和职业生涯被传记《美丽的心灵》所记录,并启发了同名电影。
让我们说服您为什么会这样。当每个虚假示例()与来自训练数据集的真实示例()确实没有区别时,判别器无法使用它们来区分它们。由于接收到的示例中有一半是真实的,而一半是伪造的,因此判别器可以做的最好的事情是掷硬币并将每个示例分类为真实或伪造的概率为50%。
同样,生成器处于无法从进一步调整中获益的地步。因为它产生的示例已经与真实示例无法区分,所以即使将其用于将随机噪声矢量()转换为伪示例()的过程进行微小的更改,也可能为判别器提供一个辨别方法的线索。真实数据中的虚假示例,可能使生成器变得更糟。
达到平衡后,很难说明GAN已经收敛。在实践中,几乎不可能找到GAN的Nash平衡,因为达到目标需要极大的复杂性非凸类游戏中的趋同性(在后面的章节中,尤其是在第5章中,会更多地讨论趋同性)确实,GAN收敛仍然是GAN研究中最重要的开放性问题之一。
幸运的是,这并不妨碍GAN研究或生成对抗性学习的许多创新应用。即使在没有严格的数学保证的情况下,GAN也取得了卓越的经验结果。本书涵盖了一些最具影响力的内容,以下部分将对其中一些内容进行预览。
1.4. 为什么要研究GANS?
自从GAN发明以来,GAN一直被学者和行业专家誉为深度学习中最重要的创新之一。 Facebook的AI研究总监Yann LeCun甚至说GAN及其变化是“过去20年来深度学习中最酷的想法[2]。”
兴奋是有道理的。与机器学习的其他进步不同,GAN吸引了研究人员和广大公众的想像力,而机器学习的其他进步可能是研究人员中的家喻户晓,但只会引起其他人的质疑。 《纽约时报》,BBC,《科学美国人》和许多其他知名媒体都对它们进行了报道。确实,这是GAN令人振奋的结果之一,很可能使您首先买了这本书。 (译者:作者的软广?)
也许最值得注意的是GAN创建超真实感图像的能力。图1.4中的面孔都不是真实的人。它们都是伪造的,展示了GAN具有以逼真的质量合成图像的能力。这些面孔是使用渐进式GAN(progressive growing GAN)(第6章介绍的技术)制作的。

图1.4. 这些照片般逼真的伪造人脸是由经过训练的 pg GAN 合成的,这些人接受了名人的高分辨率肖像照片的训练。
GAN的另一个杰出成就是图像到图像的翻译。类似于将句子从中文翻译为西班牙语的方式,GAN可以将图像从一个域转换为另一个域。如图1.5 所示,GAN可以将马的图像转换为斑马的图像(也可以反过来!),并将照片转换为类似莫奈的画作-几乎没有监督,也没有标签。使之成为可能的GAN变体称为CycleGAN;您将在第9章中了解所有内容。

图1.5。通过使用被称为CycleGAN的GAN变体,我们可以将莫奈的绘画变成照片,或者将斑马的图像变成对马的描绘,反之亦然。
更加实用的GAN用例同样引人入胜。亚马逊正在尝试利用GAN提出时尚方面的建议:通过分析大量的服装,系统学会生产与任何给定样式匹配的新商品[3]。在医学研究中,GAN用于通过合成示例用于扩展数据集以提高诊断准确性[4]。在第11章中,您掌握了GAN及其变体的训练的精髓之后,将详细探讨这两个应用程序。
GAN也被视为实现人工智能的重要踏脚石[5],能够匹配人类认知能力的人工智能系统,可以在几乎任何领域获得专业知识,从涉及步行的运动技能,语言到创造力所需的创造力组成十四行诗(这个参考链接是译者加的)[6]。
但是,由于具有生成新数据和图像的能力,GAN也具有危险的能力。关于虚假新闻的传播和危害已经进行了很多讨论,但是GAN创造可信的虚假录像的潜力令人不安。在标题为GAN的2018年标题恰当的结尾处,“人工智能如何“猫鼠游戏”生成可信的伪造照片”,《纽约时报》记者凯德·梅斯(Cade Metz)和基思·柯林斯(Keith Collins)讨论了人们担心利用GAN来制造和传播令人信服的错误信息的前景,其中包括世界领导人发表的虚假陈述录像。麻省理工学院技术评论旧金山分社社长马丁·吉尔斯(Martin Giles)回应了他们的担忧,并在他2018年的文章“ GAN father:被赋予机器想象力的人”中提到了另一个潜在风险:在熟练的黑客手中,GAN可以成为用于以前所未有的规模感知和利用系统漏洞。这些担忧促使我们在第12章中讨论GAN的道德考虑。
GAN可以为世界带来很多好处,但是所有技术创新都可能有滥用。这里的哲学必须是一种意识:因为不可能“取消发明”一种技术,因此确保像您这样的人意识到这种技术的迅速兴起及其巨大潜力至关重要。
在这本书中,我们只能从头开始了解GAN所能提供的一切。但是,我们希望本书能够为您提供必要的理论知识和实践技能,以继续探索您认为最有趣的领域。
因此,事不宜迟,让我们开始吧!
小结
GAN是一种深度学习技术,它利用两个神经网络之间的竞争动态来合成真实的数据样本,例如伪造的真实图像。组成GAN的两个网络如下:
生成器,其目的是通过产生与训练数据集无法区分的数据来欺骗判别器,
判别器,其目标是正确地区分来自训练数据集的真实数据和生成器生成的假数据
GAN在时尚,医学和网络安全等许多不同领域都有广泛的应用。
[1] See “Surpassing Human-Level Face Verification Performance on LFW with GaussianFace,” by Chaochao Lu and Xiaoou Tang, 2014,https://arXiv.org/abs/1404.3840. See also the New York Times article “Google’s AlphaGo Defeats Chinese Go Master in Win for A.I.,” by Paul Mozur, 2017, http://mng.bz/07WJ. ↩
[2] See “Google’s Dueling Neural Networks Spar to Get Smarter,” by Cade Metz, Wired, 2017, http://mng.bz/KE1X. ↩
[3] See “Amazon Has Developed an AI Fashion Designer,” by Will Knight, MIT Technology Review, 2017, http://mng.bz/9wOj. ↩
[4] See “Synthetic Data Augmentation Using GAN for Improved Liver Lesion Classification,” by Maayan Frid-Adar et al., 2018, https://arxiv.org/abs/1801.02385. ↩
[5] See “OpenAI Founder: Short-Term AGI Is a Serious Possibility,” by Tony Peng, Synced, 2018, http://mng.bz/j5Oa. See also “A Path to Unsupervised Learning Through Adversarial Networks,” by Soumith Chintala, f Code, 2016, http://mng.bz/WOag. ↩
[6] Yi, Xiaoyuan, et al. "MixPoet: Diverse Poetry Generation via Learning Controllable Mixed Latent Space." AAAI. 2020. ↩
