@Team
2019-09-01T09:39:10.000000Z
字数 3594
阅读 4660
炫酷的图像转换:从pix2pix到CycleGAN
叶虎
使用笔名白将
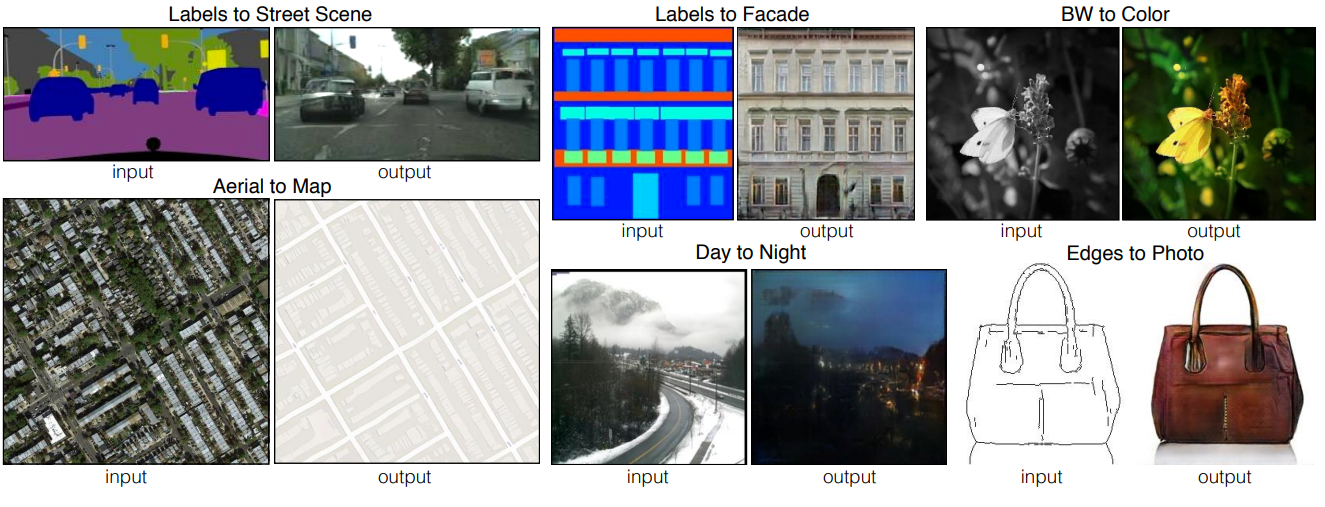
图像转换是将一张输入图片转换为不同的输出图片,如将一张灰度图变成彩色图,素描图换成实物图(见下图),这在现实生活中有很多应用场景。这类问题本质上是要建立输入和输出图像像素点之间的映射关系,而CNN网络正适合担当这个角色。从另外一个角度看,这类问题其实是建立生成模型,GAN架构是一种很好的解决方案。这里介绍的pix2pix模型就是通过GAN来实现图像转换的,不过其训练过程需要成对的输入和输出样本,这个条件在很长情况下会限制其应用。相对应地,CycleGAN模型前进了一步,不需要成对的样本就可以训练出较好的图像转换模型。
GAN和cGAN介绍
生成对抗模型(Generative Adversarial Net, GAN)是非常火的生成模型,被广泛应用在图像生成领域。GAN包括两个对抗的网络:用于拟合数据分布的生成器G,和用于判别数据真实性的判别器D。对于数据,G要学习到其数据分布,并给定噪音可以生成“真实”的数据,而D要能够识别数据的真假性。这是一种零和博弈:
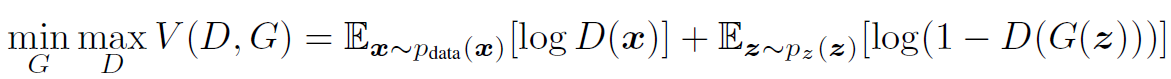
对于G,其训练目标是最大化,而D的训练目标是同时最大化和。
给定噪音,生成器G的自由度很高,可以生成任何符合分布的数据。有时候,我们可以给模型加入一些额外条件,那么这就变成了条件GAN,即cGAN,其优化目标变成:
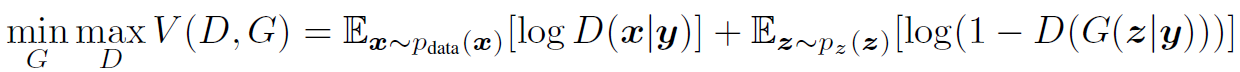
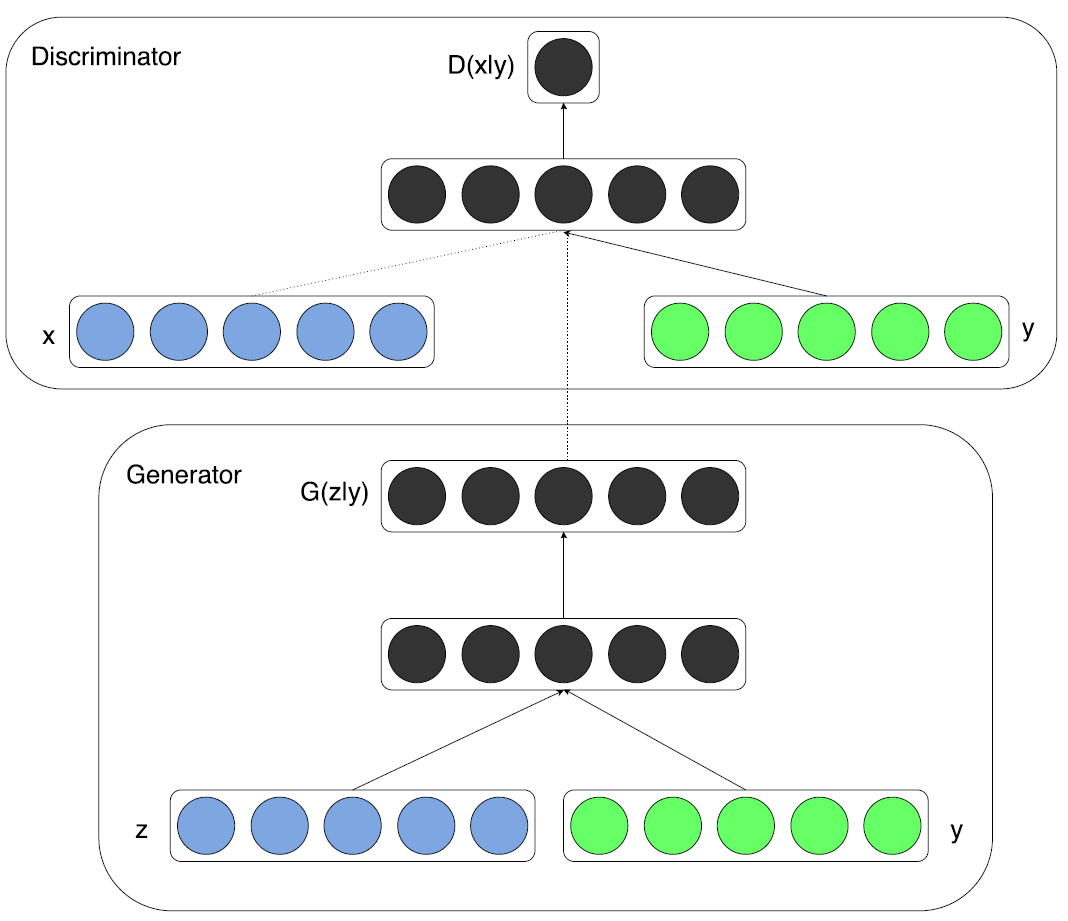
对于cGAN,其实现也是比较容易的,只需要在G和D的输入中加入即可以,如下图所示:
GAN和cGAN是后面要介绍的pix2pix和CycleGAN模型的基础,两者本质都是GAN架构的应用。
pix2pix模型
对于pix2pix模型,其贡献点在于提出了用GAN来解决图像转换问题的通用方法,并且证明了其方法的有效性。
对于图像转换问题,我们能想到的一个简单解决方案是直接训练一个CNN模型来建立像素间的映射关系,loss函数可以采用欧式距离。但是训练结果却是事与愿违,欧式距离是最小化平均结果,得到的将是模糊的图像。设计一个好的loss函数是至关重要的,但是也不那么容易。pix2pix模型采用GAN来解决这个困境,对于GAN模型来说,判别器可以用来区分转换图像的真实性,而生成器会尽量学习生成真实的图像,通过这种训练方式,模型能够自动学习到完成图像转换的近似loss函数,整体思路如下图所示:
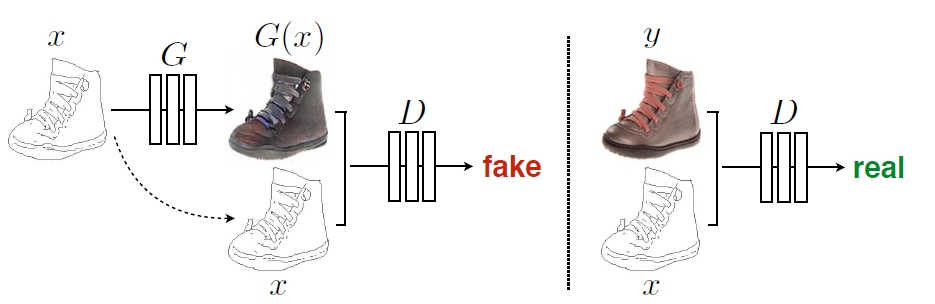
具体地,pix2pix采用的cGAN,因为我们希望生成器在限定输入图像下转换为对应的图像,其优化目标如前所述:
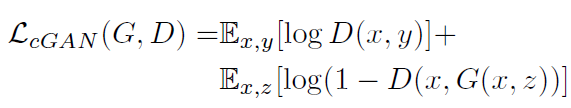
这里与GAN不同,无论是D还是G都额外增加了作为输入,毕竟我们希望G生成的图像与原始输入图像是类似的。另外一点是,在cGAN的优化目标上额外增加传统的loss是非常有用的,如L2距离,以使得G得到的图像更接近ground truth。这里,pix2pix采用的L1以减少图像的模糊:
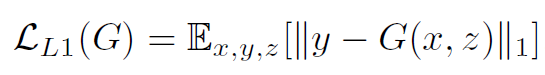
因此,最终的优化目标是:
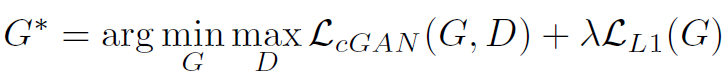
如果G没有噪音的加入,将产生确定性的输入。一般的从cGAN采用高斯噪音作为输入送入G,但是作者发现这种策略往往没效果。在pix2pix,噪音的输入是通过在G网络中加入dropout策略来实现的,并且训练和测试阶段,dropout都是采用的,不过作者依然发现dropout策略也并不会让模型产生非常大的不确定性。
对于生成器G,采用的是Unet结构,即带有短路连接的encoder-decoder架构,如下图所示:
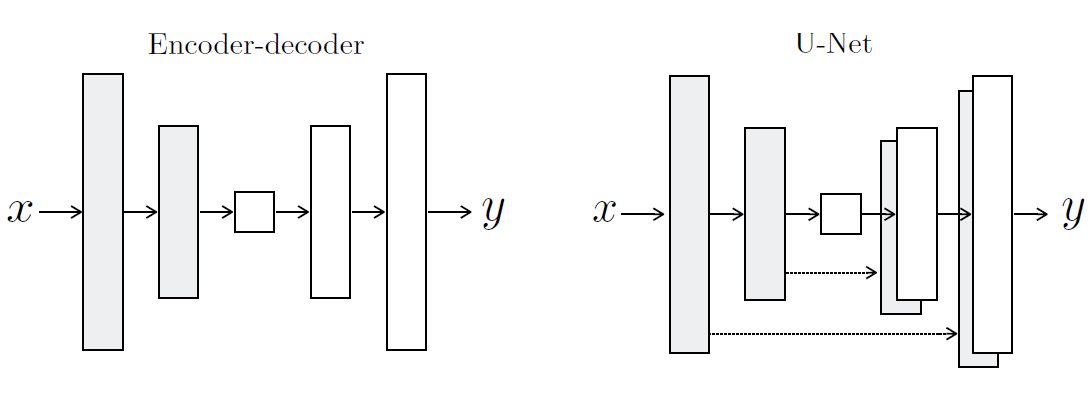
无疑这种Unet结构是非常适合的,用来建立图像转换的像素间的映射关系。另外一点是G网络中的norm层采用的是InstanceNorm,而不是BatchNorm,InstanceNorm就是batch_size=1下的BatchNorm,这主要是为了训练和测试阶段是一致的。
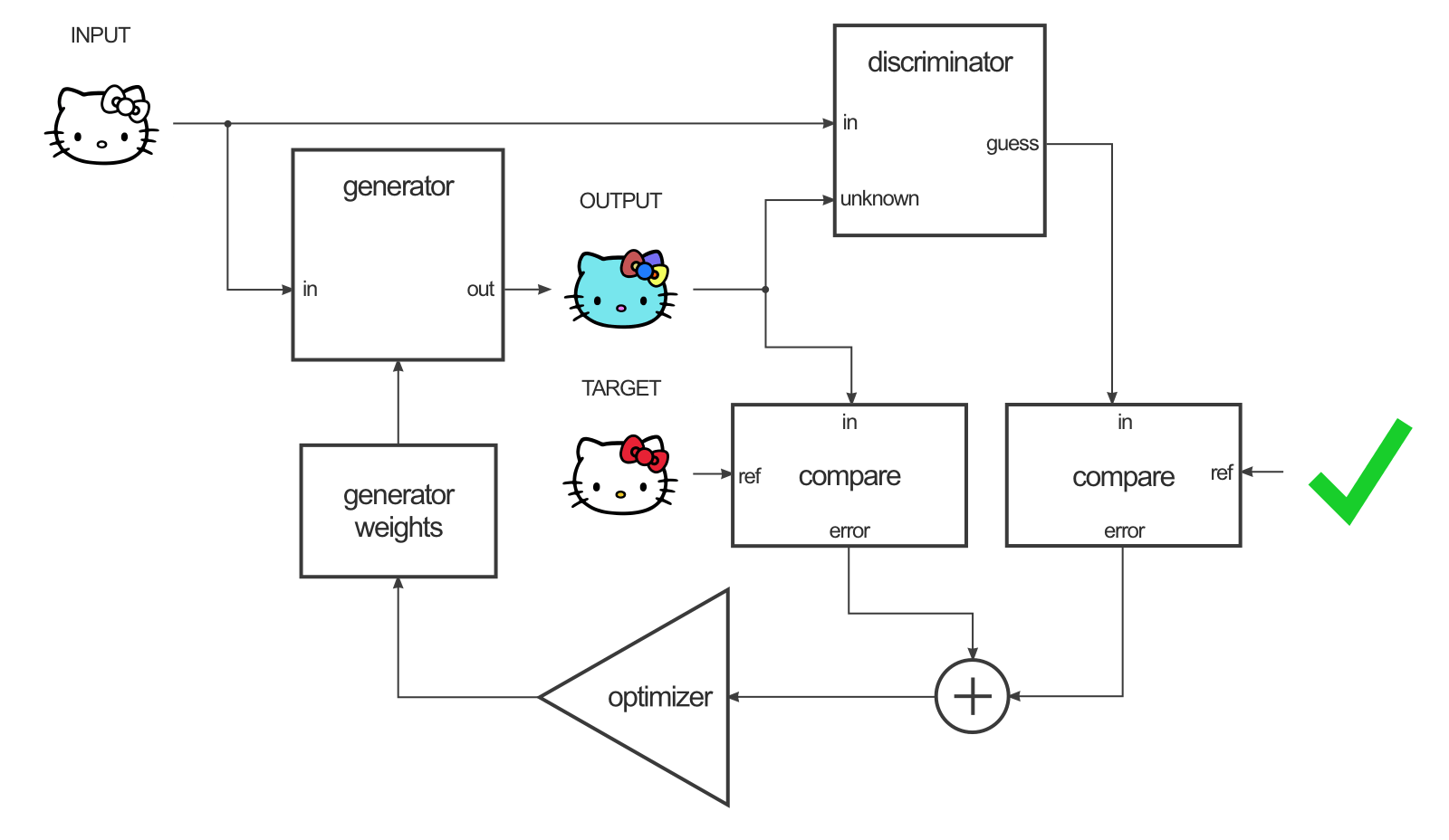
生成器G的训练loss包括两个部分,一是将input以及G生成的output送入D,要最大化,另外要最小化output以及target之间的L1损失,如下图所示(图片来源affinelayer.com):
对于判别器D,采用的PatchGAN,具体来说就是判别器D是对图像中每一大小的patch进行分类。D最后的loss是聚合所有patch的分类loss。是一个超参数,如果为1那就变成PixelGAN,即对每个像素点进行分类;若为图像大小,那就变为ImageGAN,对整个图片分类。论文中采用的70x70大小,此时效果较好。采用PatchGAN主要是希望D可以对图像的高频信息进行建模,而L1损失是用来学习图像的低频信息。
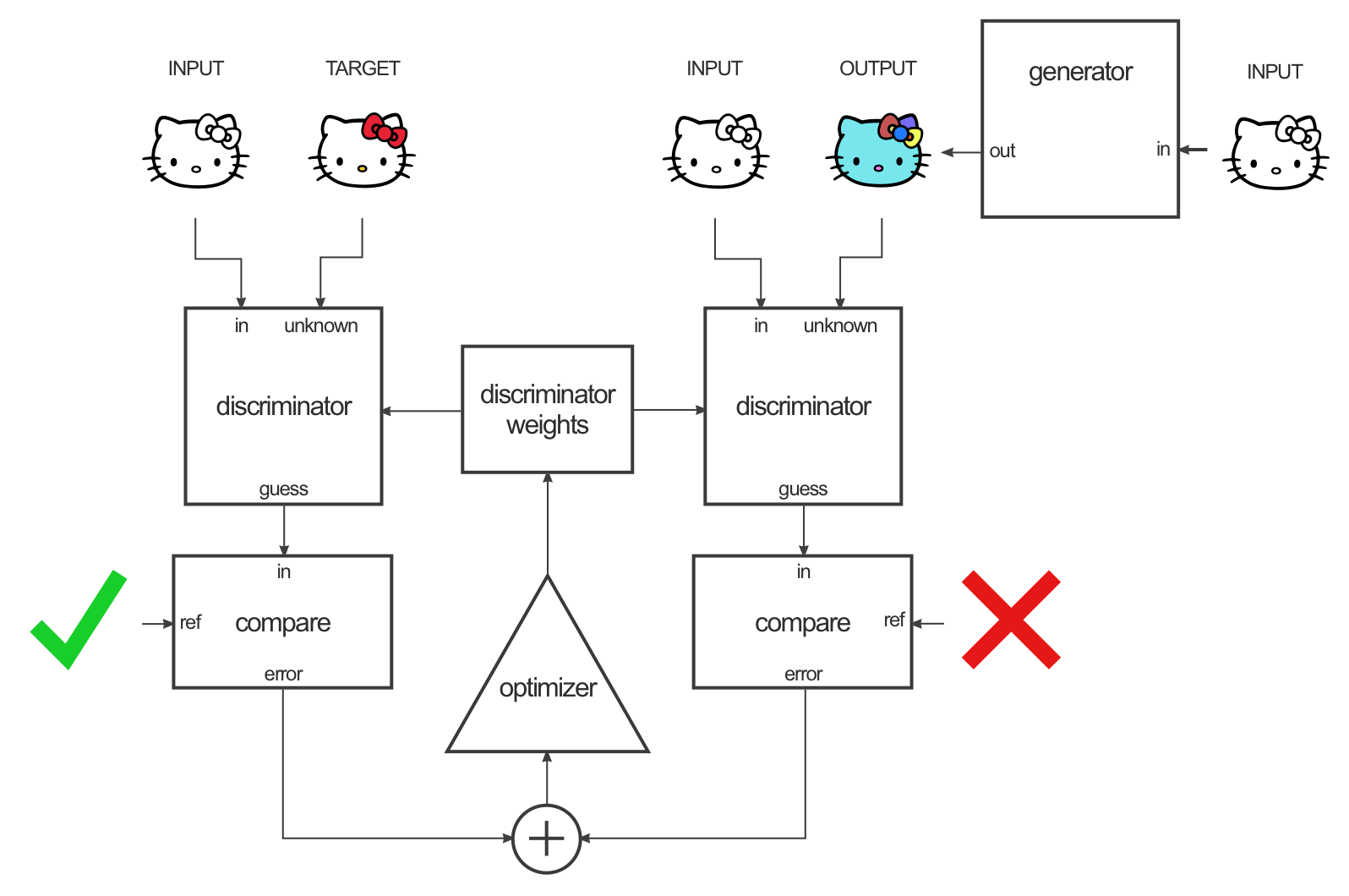
判别器D的训练loss主要包含两部分,一是送入真实的input和target,D要最大化,另外一部分是送入input以及G生成的output,D要最大化,如下图所示(图片来源affinelayer.com):
最终,pix2pix模型的可视化效果如下所示,可以看到单纯采用L1损失得到的是模糊的图像,而cGAN模型效果就好很多,L1+cGAN取得最好效果。

CycleGAN模型
pix2pix模型虽然可以取得较好的效果,但是它的训练需要成对的数据,而对于很多图像转换问题,成对数据是很难获取的甚至不可能。假定现在我们只用两个不同域(domain)的图像集合和,两个集合中的图像不是一一对应的,这时候我们只能采用普通的GAN来进行训练,而cGAN是无法完成训练的。就算我们采用GAN训练出了最优的生成器G,但是依然无法保证输入x的输出y是配对的,即仅有域上的差异,因为G的自由度很高,它只是学习到如何生成属于域的图像,并没有其它约束。另外一个难题是这种GAN其实是非常难训练的,很容易出现mode collapse,即所有的输入图像生成相同的输出。
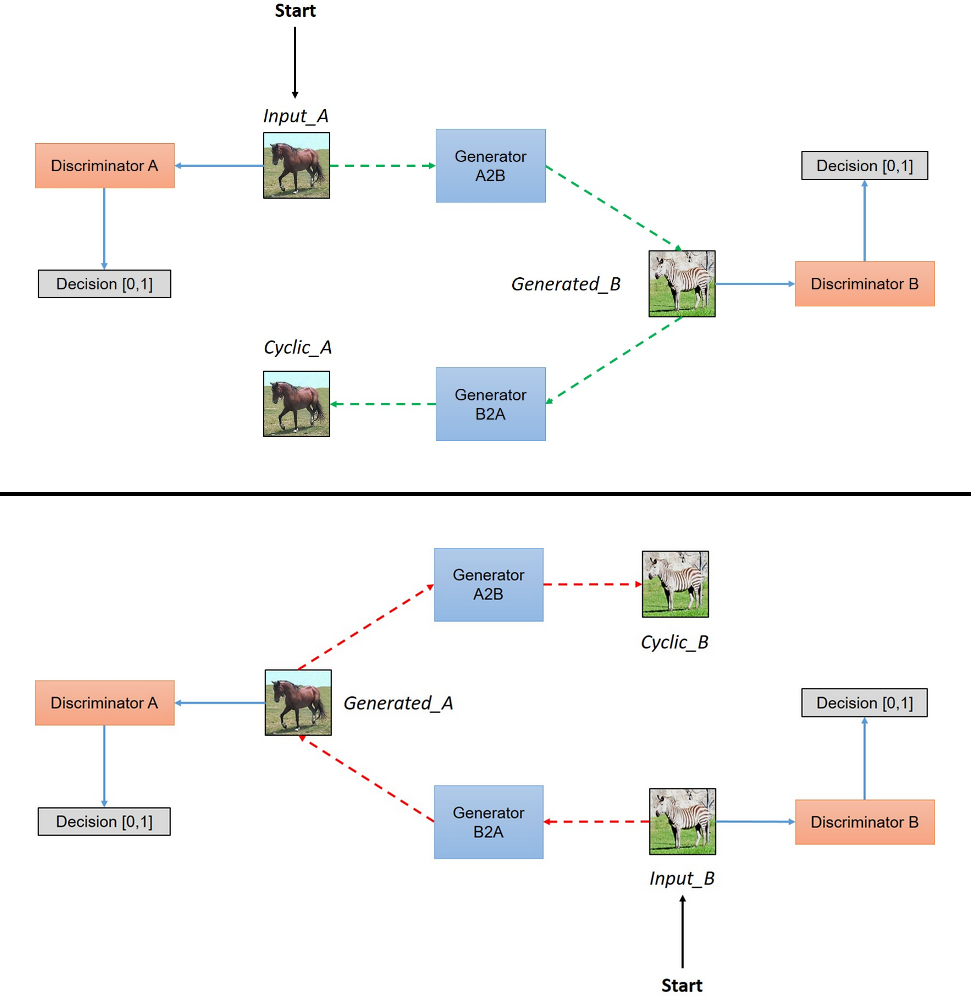
单纯的利用GAN处理这类问题是比较难的,所以需要在优化目标上引入额外的信号,这就是CycleGAN模型的创新之处。具体来说,CycleGAN引入了循环一致loss(cycle consistency loss),这就类比于一个句子能够从英语翻译到法语,也应该从法语再翻译回来英语。在实现上,要定义两个生成器,分别是和,另个生成器应该是互逆的,或者说是循环一致的:且。下图展示了CycleGAN模型整个架构:
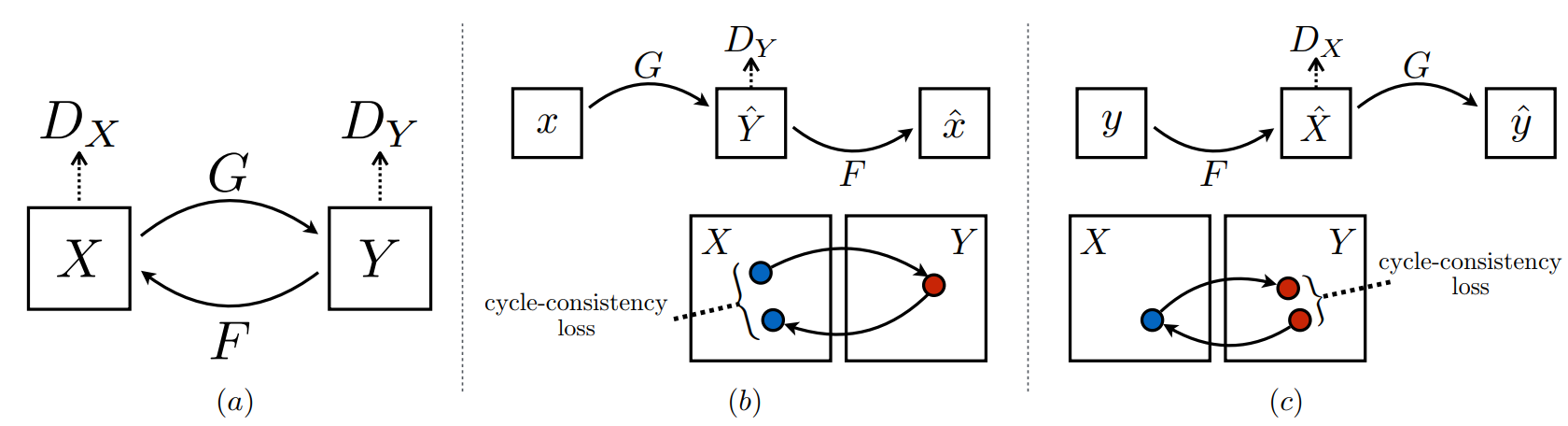
其中(a)表示出了两个生成器G和F外,同时要有两个判别器和,分别用于识别真实图像和合成图像,训练loss采用普通的对抗loss,比如对于判别器,优化目标为:
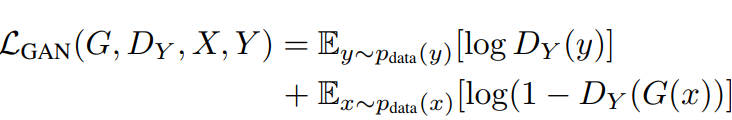
注意这里是普通的GAN结构,而不是像pix2pix中采用cGAN,实际上没有成对的数据也无法用cGAN。另外对于判别器优化目标是类似的。
(b)和(c)表示的生成器G和F的循环一致,前者是前向循环一致:,后者是反向循环一致:,循环一致loss可以采用L1损失,如下所示:
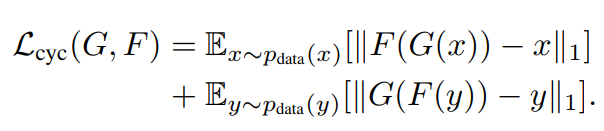
最后,CycleGAN模型的优化目标为:
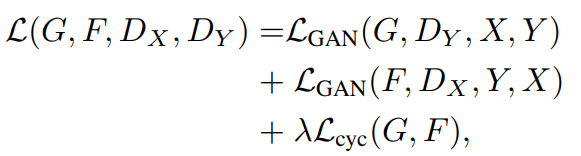
其中用于调整GAN对抗loss和循环一致loss之间的比重,论文中取10。CycleGAN的训练目标也是一个零和博弈:
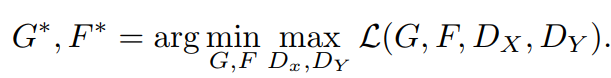
另外,论文中还提到了可以在训练中加入一种额外的loss,称之为identity loss,其含义是当一个真实的样本送入生成器时,应该得到的还是自己。用数学表达就是:
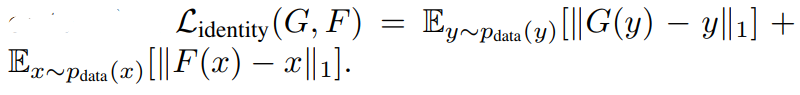
CycleGAN整个架构可以用下图展示(图片来源CycleGANBlog):
至于网络结构,生成器和判别器可以采用与pix2pix一样的网路,CycleGAN的创新点在于训练loss,而基本上与无网络结构关系不大。但是相比pix2pix模型,CycleGAN训练难度依然很大。具体到训练细节上,CycleGAN的对抗loss采用最小方差损失,而且训练判别器时采用一些历史生成数据。
缺少成对的数据,CycleGAN模型效果是比pix2pix差一些的,但是总体上如果训练得较好,视觉效果还是可以接受的,下图是一些生成结果:

小结
这篇文章简答介绍了pix2pix和CycleGAN模型,其实两个模型整体上都是比较简单的,都是在GAN的基础上增加一些额外的loss设计,至于具体的代码实现网上已经开源,感兴趣的可以coding。
