@Team
2019-10-13T03:30:50.000000Z
字数 1457
阅读 4482
混合精度对模型训练和推理的影响
刘才权
单精度/双精度/半精度/混合精度
计算机使用0/1来标识信息,每个0或每个1代表一个bit。信息一般会以下面的三种形式表示:
1 字符串
字符串的最小单元是char,每个char占8个bit,也就是1个byte。比如字符串“abc”这三个字符组成的串占用的存储空间:
存储空间=1x3=3(bytes)=24(bits)
2 整数
整数包括INT4、INT8、INT16、INT32、INT64,INT后面的数值表示该整数类型占用的byte个数。
3 浮点数
浮点数包括Float16、Float32、Float64,同样,Float后面的数字表示该浮点型占用byte的个数。而这三种浮点数又有个不同的名字:
- 半精度浮点数:Float16
- 单精度浮点数:Float32
- 双精度浮点数:Float64
有了上面单精度、双精度、混合精度三种形式的解释,混合精度就很好理解了。就是计算中存在不同精度的浮点数,比如:
Float16+Float32
混合精度的优点
先说结论:
压缩模型大小
我们一般模型训练使用的是Float32,那换成混合精度有什么好处呢?为了更好理解,我们将Float32的模型参数都换成Float16. 在参数数目不变的情况下,将Float32的参数都更换成Float16后,模型占用的内存就变成了之前的一半。所以,混合精度最直观的优点就是能够压缩模型的大小。
前面为了好理解,将Float32全都转成了Float16,但在实际的模型训练中,Float16因为能表示的精度有限,会导致数据溢出(超出能表示的范围),所以,只能部分操作用Float16,部分操作用Float32.最终导致混合精度的提出。
混合精度比较经典的论文是这篇:
论文介绍了混合精度在模型训练中的方法,并在多个训练场景中证实,混合精度相对于完全Float32的模型的参数训练,最终的算法效果影响不大。
混合精度对模型训练和推理速度的影响
先说结论:
理论上没有提升,反而会下降。但在结合计算平台特性,训练和推理速度会有提升
理论上混合精度只能压缩模型的大小,在训练阶段和推理阶段,都能能大大缓解CPU内存或GPU显存限制对模型训练压力。
因为模型结构和参数数量没有发生显著的变化(忽略混合精度对模型训练,参数更新的影响),理论上训练和推理速度应该不会有大的改变。而且,因为不同的精度需要进行对齐再运算(计算时,先将不同的精度转变成统一的精度后,再进行计算),返回导致计算效率降低,从而会导致训练和推理的速度降低。
但实际上计算平台对这种特殊的计算场景一般都有专门的硬件计算加速,比如:
1 具备专用的半精度计算单元
GPU针对Float16、Float32运算,都有专门的计算单元。
2 单精度支持两个半精度计算同时进行
比如,英伟达的GPU Tesla P100支持在一个Float32里同时进行2次Float16的半精度浮点计算,所以对于半精度的理论峰值可以达到单精度浮点数计算能力的两倍。
3 TensorCore
英伟达的瓦特(如Tesla V100)和图灵架构(如Tesla T4)都具备TensorCore单元,能完成单指令的混合精度矩阵乘加运算。
混合精度的实际表现
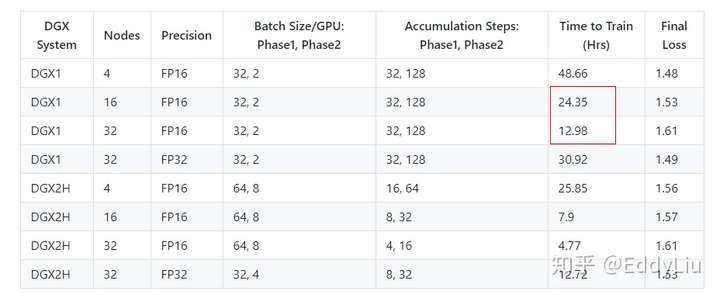
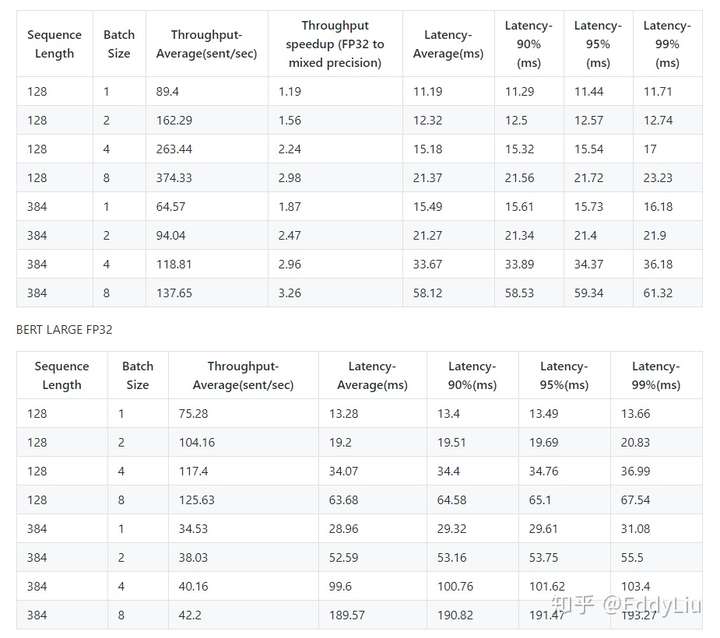
我们以英伟达开源的BERT评测对比下:
模型训练:
模型推理:
总结
混合精度可以明显的对模型的大小进行压缩(内存占用),同时,针对优化的计算平台,在模型训练和推理的速度方面也都有提升。
参考文档:
