@Team
2019-05-15T09:27:08.000000Z
字数 1360
阅读 3062
语义分割网络经典:FCN与SegNet
石文华
将图像中每个像素分配到某个对象类别,相关模型要具有像素级的密集预测能力
1、FCN
(1)概述:
改编当前的分类网络:AlexNet、VGG、GoogLeNet到全卷积网络和通过微调传递它们学习的特征表达能力到分割任务中。然后定义了一个跳跃式的架构,结合来自深、粗层的语义信息和来自浅、细层的表征信息来产生准确和精细的分割。

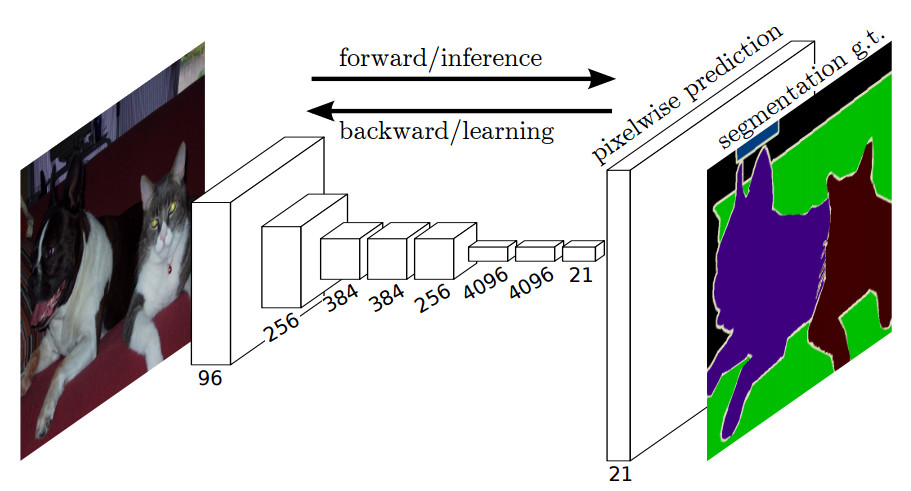
由上图可以看出,将分类网络改成全卷积网络,生成了一个低分辨率的类的热图(图中的:tabby cat heatmap),上采样用双线性初始化的反卷积,并在上采样的每一个阶段通过融合(简单地相加)下采样阶段网络中的低层的更加粗糙但是分辨率更高的特征图进一步细化特征。
(2)特征上采样与融合细节
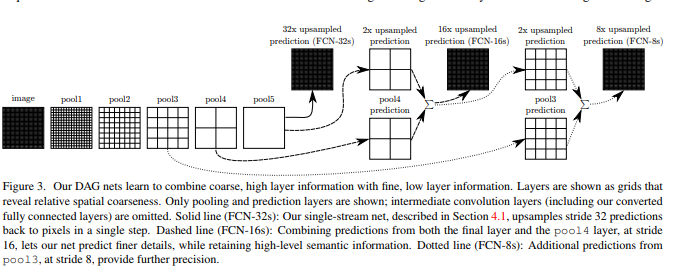
上图可以看出该算法采用了“融合层”策略(简单地相加),将高层特征和低层特征进行融合来提高分割性能,分别采用了3种不同的结构,第一种是32x upsampled ,第二种是16x upsampled,第三种是8x upsampled。
过程是这样的:
1、32x upsampled
原图经过不断的卷积和池化,得到pool5层的特征(比原图缩小了32倍),将pool5通过32倍的上采样(反向卷积)得到最后结果。但是pool5层的特征属于高层抽象特征,采样后得到的结果不够精细。
2、16x upsampled
将pool5的结果进行2倍上采样,与pool4相加,作为“融合”,然后将“融合”结果进行16倍的上采样(反向卷积)得到最后结果(注:融合是指对应位置像素值相加,后来的u-net则直接是通道上拼接)。
3、8x upsampled
将pool5的结果进行2倍上采样,与pool4相加,作为“融合”,然后将“融合”结果进行2倍的上采样,再与pool3的结果进行“融合”,之后进行八倍的上采样。
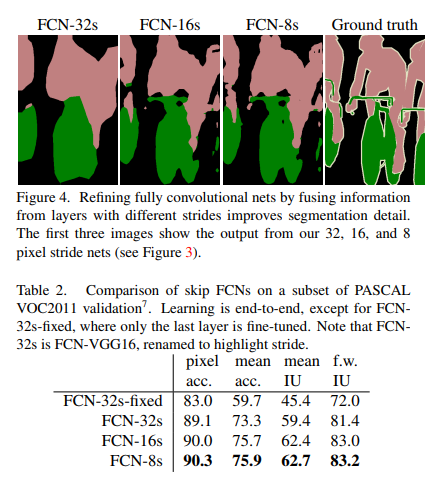
三种结构实验结果表明,将高层特征与低层特征的融合能够明显提高像素点的分类效果,如下图所示:
2、SegNet
(1)概述

上图可以看到segNet没有全连接的层。SegNet和FCN思路十分相似,不同之处在于解码器使用从编码器传输的最大池化索引(位置)对其输入进行非线性上采样,从而使得上采样不需要学习,生成稀疏特征映射。然后,使用可训练的卷积核进行卷积操作,生成密集的特征图。最后的解码器输出特征映射被送入soft-max分类器进行像素级分类。
上采样使用池化层索引的优势:
1)提升边缘刻画度;
2)减少训练的参数;
3)这种模式可包含到任何编码-解码网络中。
(2)编码和解码过程
SegNet在编码阶段进行pooling的时候会保留保存通过max选出的权值在2x2 filter中的相对位置,用于之后在解码器中使用那些存储的索引来对相应特征图进行去池化操作,如下图所示:

代码地址
网络结构部分的代码详见:
https://github.com/cswhshi/segmentation/blob/master/FCN.ipynb
https://github.com/cswhshi/segmentation/blob/master/SegNet.ipynb
欢迎大家指正和star~
