@Team
2018-09-11T07:08:22.000000Z
字数 4409
阅读 1909
在此处输入标题
石文华
We present YOLO, a new approach(途径、方法) to object detection. Prior work(以前的工作) on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially(空间地) separated(分离) bounding boxes and associated(相关的) class probabilities(概率). A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation(评估).Since the whole detection pipeline(流水线) is a single network, it can be optimized end-to-end directly on detection performance(优化)
我们提出了一种新的物体检测方法YOLO。先前关于对象检测的工作是重新调整分类器以执行检测。相反,我们将对象检测作为回归问题构建到空间上分离的边界框和相关的类概率。 单个神经网络直接从中预测边界框和类概率 一次评估中的完整图像。由于整个检测流水线是单个网络,因此可以直接在检测性能上进行端到端优化。
Our unified(统一) architecture(框架) is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO,processes an astounding(惊人) 155 frames per second while still achieving double the mAP of other real-time detectors. Compared(比较) to state-of-the-art(最先进的) detection systems, YOLO makes more localization(定位) errors but is less likely to predict false positives(假阳性) on background(背景). Finally, YOLO learns very general(全体的) representations(特征表达) of objects. It outperforms(性能优于) other detection methods, including DPM and R-CNN, when generalizing(泛化) from natural images to other domains like artwork(艺术品).
我们的统一架构非常快。我们的基础YOLO模型以每秒45帧的速度实时处理图像。 较小版本的网络FastYOLO每秒处理速度达到惊人的155帧,同时它仍然实现了其他实时检测器的mAP的两倍。 与最先进的检测系统相比,YOLO产生更多的定位误差,不太可能在预测背景时出现假阳性。最后,YOLO学习了对象的全局的特征表达。当从自然图像推广到其他领域(如艺术品)时,它优于其他检测方法,包括DPM和R-CNN。
Humans glance(瞥一眼) at an image and instantly know what objects are in the image, where they are, and how they interact(相互作用). The human visual system is fast and accurate(精准), allowing us to perform(执行) complex tasks like driving with little conscious thought. Fast, accurate algorithms for object detection would allow computers to drive cars without specialized(专用) sensors(传感器), enable assistive(辅助) devices to convey real-time scene information to human users, and unlock the potential for general purpose, responsive robotic systems.
人类瞥了一眼图像,立即知道图像中的物体,它们在哪里以及它们如何相互作用。 人类视觉系统快速而准确,使我们能够执行复杂的任务,例如驾驶很多时候是不需要很多想法以及意识的情况下进行的。快速且准确的物体检测算法将允许计算机在没有专用传感器的情况下驾驶汽车,使辅助设备能够向人类用户传达实时场景信息,并开放功能给交互式的机器人系统作为一般用途。
Current detection systems repurpose(复用) classifiers to perform(执行) detection. To detect an object, these systems take a classifier for that object and evaluate(评估) it at various locations and scales(尺寸、比例) in a test image. Systems like deformable parts models (DPM) use a sliding window approach where the classifier is run at evenly spaced(间隔) locations over the entire image [10].
当前的目标检测系统利用分类器来执行检测。为了检测对象,这些系统对测试图片上不同位置、不同尺寸的图像进行分类并以及评估。DPM算法使用滑动窗口方法,其分类器在整个图像上以均匀间隔的位置滑动。
More recent approaches like R-CNN use region proposal methods to first generate potential(潜在的) bounding boxes in an image and then run a classifier on these proposed boxes. After classification, post-processing(后处理) is used to refine(提炼) the bounding boxes, eliminate(消除) duplicate(重复) detections, and rescore the boxes based on other objects in the scene [13]. These complex pipelines are slow and hard to optimize because each individual component must be trained separately
最近的方法如R-CNN使用区域提议方法是在图像中生成潜在的边界框,然后在这些提议的框上运行分类器。分类后,后处理用于细化边界框,消除重复检测,并根据场景中的其他对象重新排列框[13]。这种需要多个复杂步骤的方法很慢且难以优化,因为不同的步骤必须单独进行训练。
We reframe object detection as a single regression problem, straight from image pixels to bounding box coordinates(坐标) and class probabilities. Using our system, you only look once (YOLO) at an image to predict what objects are present and where they are.
我们将对象检测重新定义为一个回归问题,直接从图像像素到边界框坐标和类概率。 使用我们的系统,你只需在图像上查看一次(YOLO)即可预测出现的对象以及它们的位置。
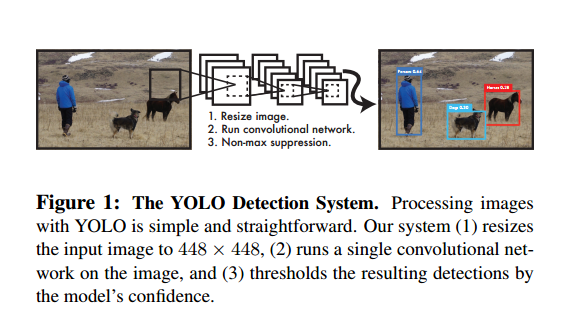
YOLO is refreshingly simple: see Figure 1. A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes.YOLO trains on full images and directly optimizes detection performance. This unified model has several benefits over traditional methods of object detection