@Team
2019-11-23T13:14:01.000000Z
字数 3767
阅读 3802
堪比Focal Loss!解决目标检测中样本不平衡的无采样方法
白将
训练目标检测模型的一个难点是样本不均衡,特别是正负样本比例严重失衡。目前解决这类问题主要是两种方案(见综述Imbalance Problems in Object Detection: A Review):一是hard sampling方法,从所有样本中选择一定量的正样本和负样本,只有被选择的样本才计算loss,一般会倾向选择一些难负例样本,比如OHEM;另外一类方法是soft sampling方法,选择所有样本计算loss,但是不同的样本赋给不同的权重值,比如focal loss。这些基于采样的策略虽然有效,但是需要超参数调节。这里,我们介绍的论文是Is Sampling Heuristics Necessary in Training Deep Object Detectors?,论文提出了一种无采样方案,此方案与前面两种方法的对比如下:
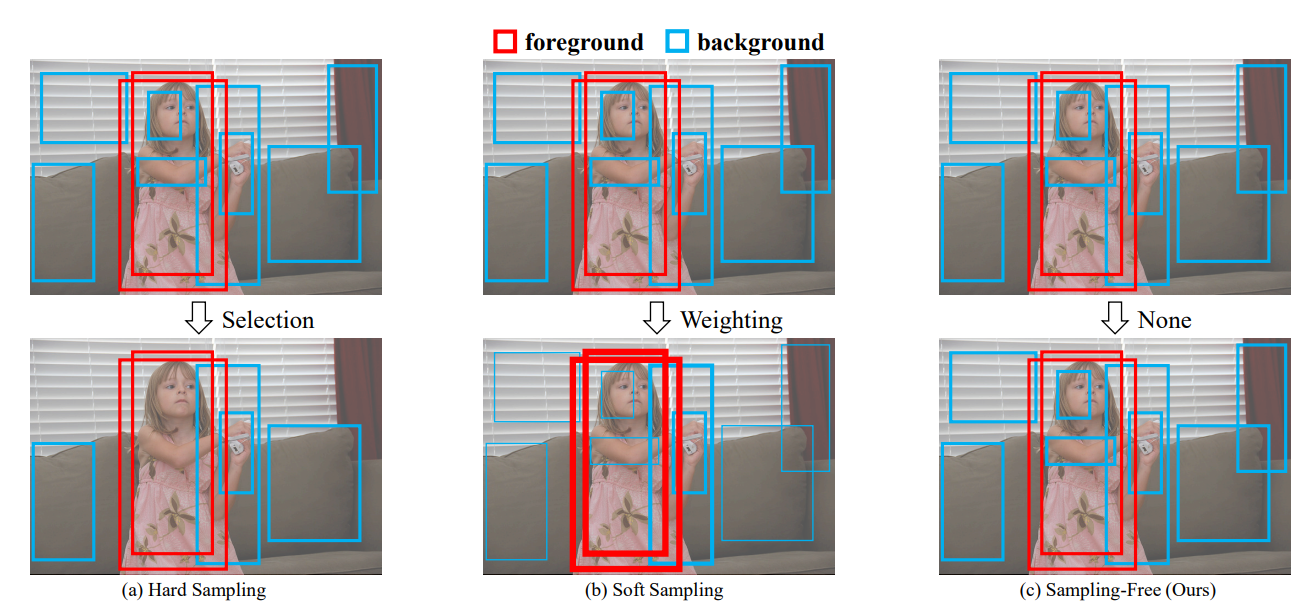
图1 三类方法对比
无采样方法使用所有的样本进行训练,下面我们具体来看它如何训练出比较好的检测效果,它的策略非常简单。
从RetinaNet和Focal loss说起
RetinaNet是目前比较好的one-stage目标检测算法,它采用focal loss来解决正负样本不均衡问题。这里我们探讨focal loss对RetinaNet的影响。我们将采用focal loss的算法称为RetinaNet-FL,而简单采用标准交叉熵的算法称为RetinaNet-None。两种loss的计算如下所示:
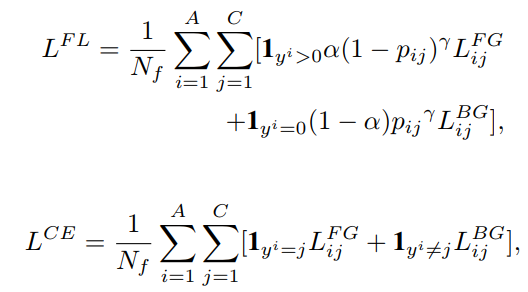
其中表示focal loss,而表示普通交叉熵。表示的是对第个anchor(一个anchor对应一个训练实例)的第的类的预测概率。正负样本的loss就是负对数loss:
对于focal loss其实就是在交叉熵基础上为不同样本分配权重。对于RetinaNet-FL,比较容易训练并取得很好的效果。那么,对于RetinaNet-None,如果只是按同样的设置训练,会发现分类的梯度很快爆炸,如图2a所示,当我们尝试减少分类loss的权重直到除以5000才可以解决梯度爆炸,但是最终的效果很差,AP值仅为6.9。我们来分析这个问题,首先由于负样本太多,模型训练刚开始负样本的loss会很大,而且不稳定,所以很容易出现梯度爆炸。然后我们可以通过降低分类权重避免梯度爆炸,但是从loss曲线上看,分类loss会从一个较大的值迅速降为一个极小值,后面就在此附近来回震荡,这说明模型的分类loss很快被负样本所主导,模型倾向于预测负样本,所以最终模型效果依然很差。这是一个进退难题。
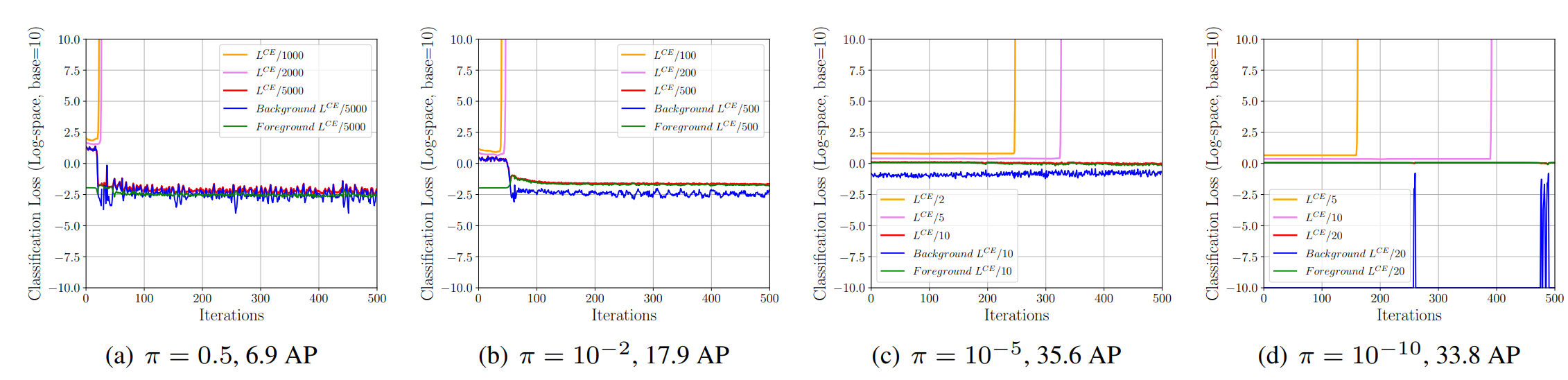
图2 分类损失的迭代曲线
其实梯度容易爆炸的一个原因在于模型初始化策略,一般情况下我们会倾向让初始化的模型对于各类的预测是相同概率的,但是对于我们这个正负样本极度不平衡问题,这其实是非常不利的,因为负样本的loss会很大。所以RetinaNet论文中建议在对分类分支初始化时,对负样本设置一个先验概率值,具体实施是改变分类分支的bias初始化值,对bias设置如下:
RetinaNet中采用的为0.01,那么初始化后的分类分支sigmod处理后的预测概率倾向于0.01,而不是0.5,这会大大减少负样本的初始loss。如图2b所示,但是依然还是出现了梯度爆炸,将分类loss除以500后可以避免,最终的AP值为17.9,从曲线上loss还是有一个突变,说明模型还是陷入负样本中。进一步地调整,当设置为1e-5时,并且分类loss除以10,发现模型可以较好地收敛,最终的AP为35.6,基本达到RetinaNet-FL的效果(AP为36.4)。再进一步地降低为1e-10,发现模型效果反而有稍微下降,AP值为33.8。另外,作者发现RetinaNet-None预测的概率平均值是远远低于RetinaNet-FL,为了提升召回,可以设置较低的阈值,若将阈值从0.05降低至0.005,AP值从35.6提升到36.2,而这对RetinaNet-FL无影响。
这说明只要适当调整模型的初始化以及loss,采用普通交叉熵是可以达到与focal loss类似的效果的。这是此论文最重要的发现,据此给出了无采样的训练机制,主要包括三点,让我们一一道来。
最优bias初始化
前面已经说到,分类分支的初始化对模型训练很关键,这里我们理论分析最优的如何确定。假定数据集中共有个类别,样本量为,其中正例为。模型刚开始对所有样本的预测概率值是接近的,那么分类loss就可以大致估算出来:
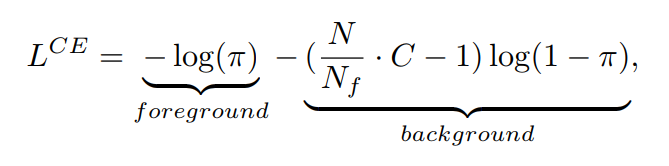
在论文的实验中,为80,而大约为1000。给定一系列值,我们可以计算出正负例的分类loss,如下表所示:
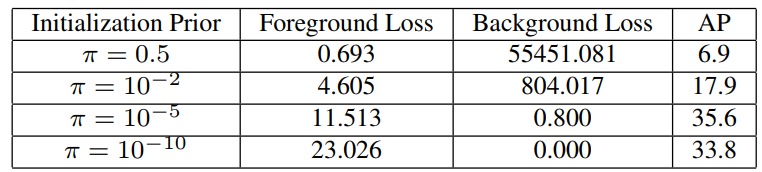
在前面的分析中,我们发现取1e-5时,模型效果最好。从表中我们可以看到,此时的整体loss是最小,这大大降低了训练初期的梯度爆炸的风险,而且负样本的loss也较小,模型训练过程中更容易学习到正样本。而当为0.5或者0.01时,负样本的loss很大,模型很容易陷入负样本的陷阱中。若取1e-10,虽然负样本loss更低,但是正样本loss增加了,这反而不利于模型的稳定训练。
基于上面的分析,最优的设置应该是要使整体loss最低,我们可以求导数来确定:

很容易计算出最优为,此时最低。这里我们认为模型训练之初,。那么可以计算出bias的最优初始化值为:
按照上面参数计算,最优的为1.113e-5,和我们的实验值是吻合的。
Guided Loss
前面实验的另外一个结论是要降低分类loss,但是降低比例很难确定。但是对于回归loss,其只计算正样本,不会受到正负样本不平衡的影响,所以我们可以通过回归loss来确定分类loss的调整比例:
那么最终的loss计算为:
这里和是回归和分类loss的权重系数,是检测模型所固有的参数。简单来说,我们用来引导,以希望分类loss可以和回归loss维持相同的水平,这在论文中称为guided loss。值得注意的是,我们虽然在训练过程中实时确定r,但是这一过程是不经过BP的,所以这一机制没有带来任何负担,也不引入新的超参数。
类别自适应阈值
前面已经提到,RetinaNet-None会出现置信度偏移现象,我们可以采用较低的阈值来进一步提升模型效果,但是其实对每个类别,我们可以采用不同的过滤阈值。这里提出一种基于训练样本的类别自适应阈值(class-adaptive threshold):
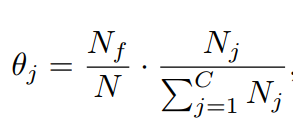
其中第一项是正样本在负样本所占的比例,而第二项是各个类别在所有类中的所占比例。
实验效果
首先,要说明的是上面所提出的3种机制对大部分目标检测算法都是适用的,包括基于anchor的one-satge和two-stage方法,以及无anchor的目标检测方法。论文中选取了YOLOv3,RetinaNet,FoveaBox(无anchor),Faster R-CNN以及Cascade R-CNN进行实验,来测试所提出的无采样方法的效果,如下表所示:
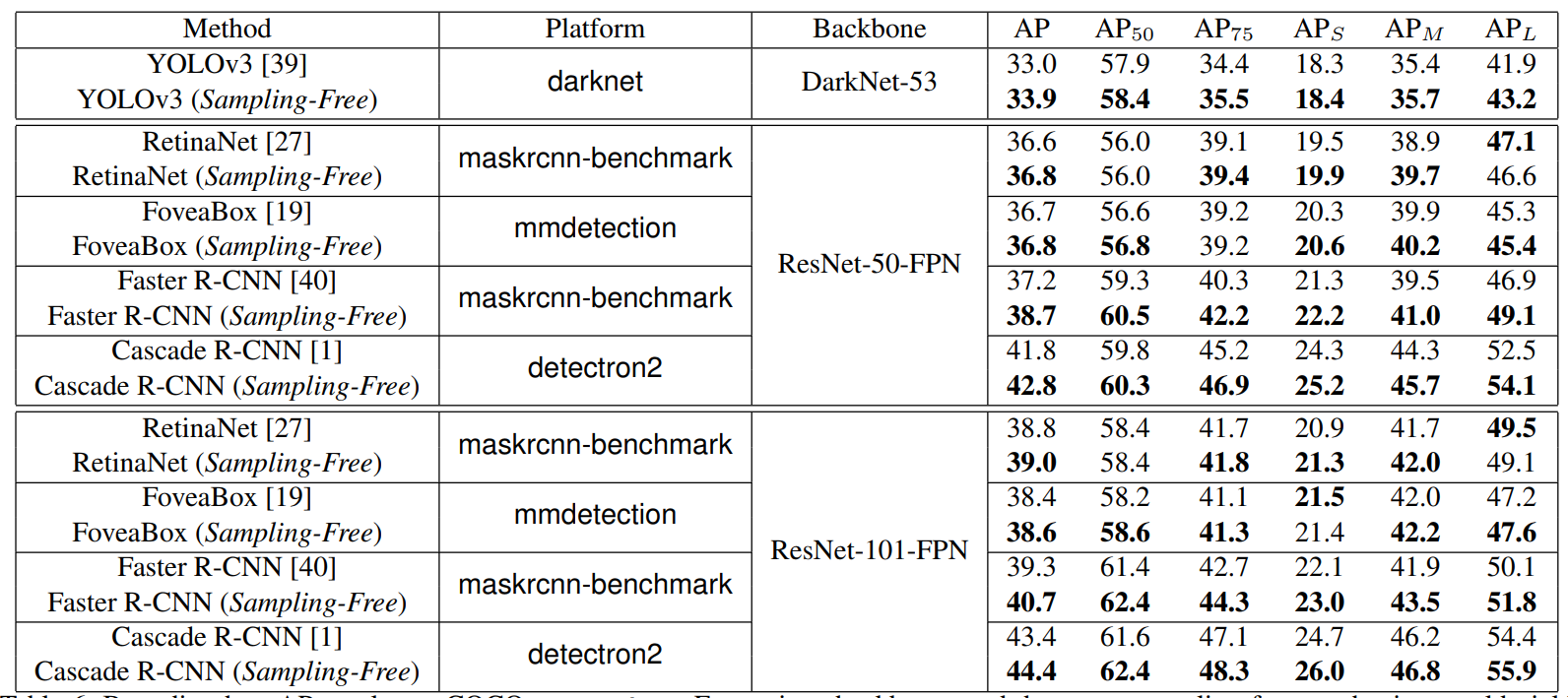
从表中可以看到,采用无采样方法的模型相比baseline均有一定的提升,这说明这一机制不仅限于理论分析,在实际中确实可以取得较好的效果。
另外,作者也分别实验分析了三种策略,如下表所示:

可以看到三种策略都是有一定的效果的,但是我觉得第3个策略是最无关紧要的,提升不大,只能算上一种辅助策略。
另外一点是,前两种策略应该是有一定的互补性质的,比如都是适当降低分类loss来避免梯度爆炸的问题。这里作者比较了第一策略的采用与否对第二策略guided loss的影响,结果如下图所示:
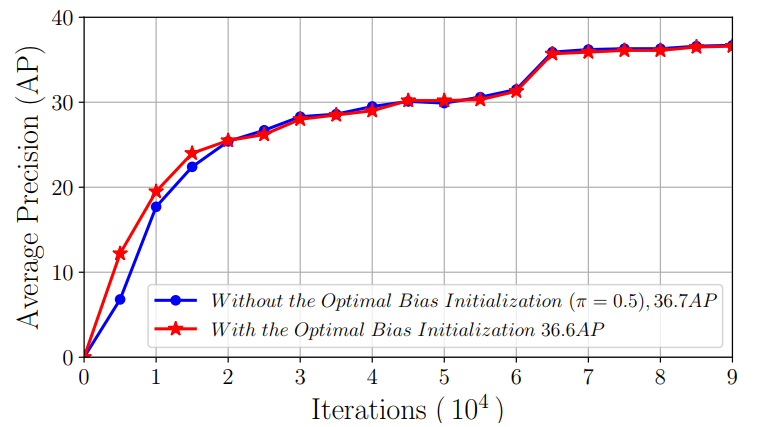
这里可以看到只要有了guided loss,第一策略对最终模型效果的影响是微乎其微的。这也很容易理解,最早的实验我们发现最重要的是要降低分类loss,两个策略可以起到同样的效果。不过从收敛曲线上可以看到,加入第一策略,收敛速度稍微更快一些,所以还是推荐加入第一策略。
小结
正负样本不平衡一直以来是目标检测中比较头疼的问题,这篇论文的主要贡献是分析了这个问题对训练的影响,并给出了可以解决该问题的无采样方法,思路还是非常清晰的,看起来也是行之有效。
