@Team
2018-10-22T09:26:41.000000Z
字数 6622
阅读 2734
《Computer vision》笔记-VGGNet(2)
石文华
VGGNet由牛津大学的视觉几何组提出,并在2014年举办的ILSVRC中获得了定位任务第一名和分类任务第二名的好成绩,相比AlexNet而言,VGGNet模型中统一了卷积中的使用参数,卷积核的长度宽度为3*3,卷积核步长统一为1,padding统一为1,并且增加了卷积神经网络的深度。VGG主要的工作贡献就是基于小卷积核的基础上,去探寻网络深度对结果的影响。下图是VGG网络的架构图:
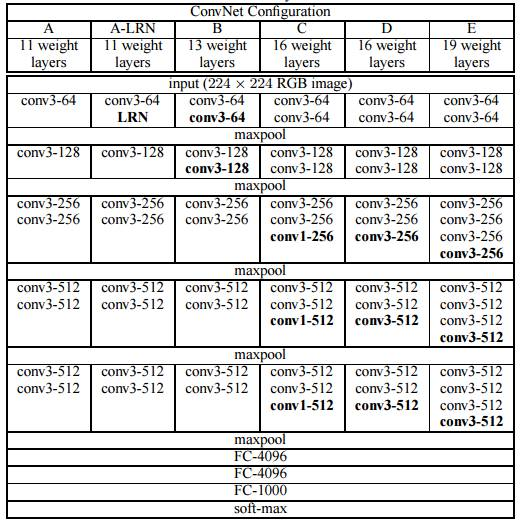
好吧,上面那张图看起来眼花缭乱,实际上上图展示了不同层数的VGG,分别是11层,13层,16层,19层,不同层数的网络训练出来的网络模型大小如下:

可以看到卷积层数增加了很多,但是网络大小并没有增加很多,侧面也反应出卷积层所占的参数并不是很多,而全连接层占据了大多数的参数数量。
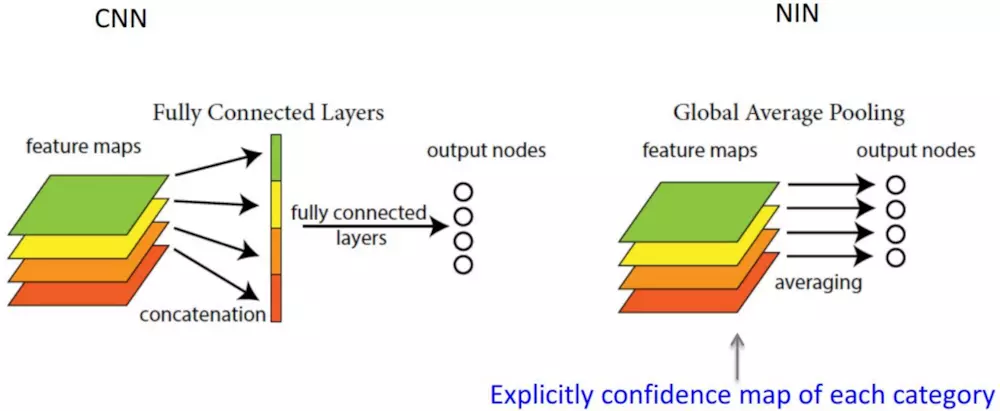
说句题外话,可以使用全局平均池化层(GAP,Global Average Pooling)的方法代替全连接层。它的思想是:用 feature map 直接表示属于某个类的 confidence map,比如有4个类,就在最后输出4个 feature map,每个feature map中的值加起来求平均值,这四个数字就是对应的概率或者叫置信度。然后把得到的这些平均值直接作为属于某个类别的 confidence value,再输入softmax中分类, 实验效果并不比用 FC 差,并且参数会少很多,从而又可以避免过拟合。如下图所示:
言归正传,回到VGG,特意找了一张VGG16网络结构图,此图对应上图中的D,这样看起来就舒服多了,如下:
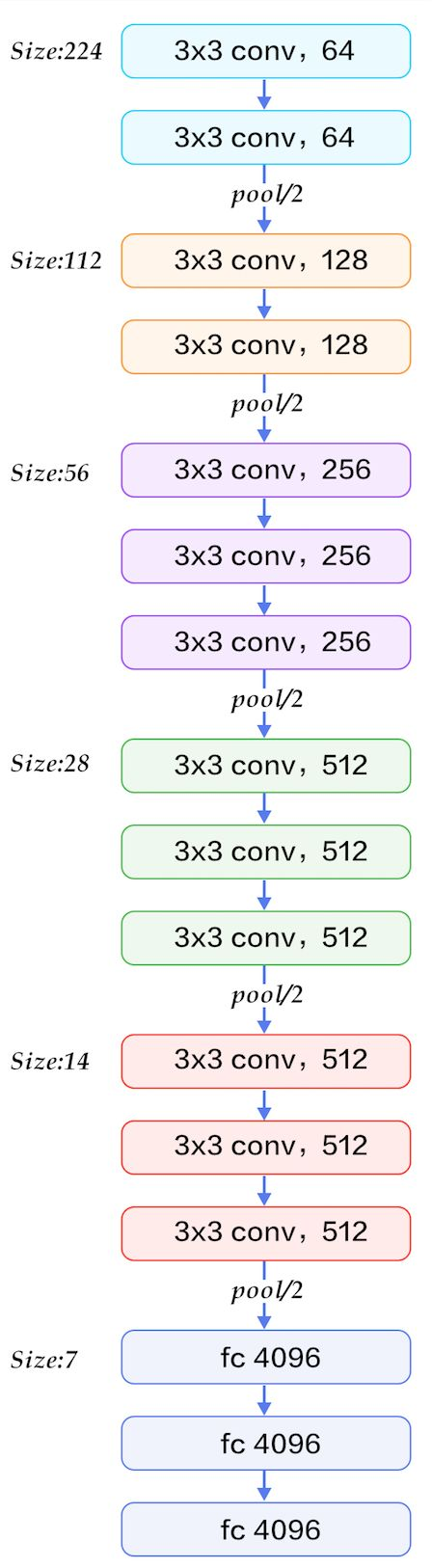
VGG-16维度的变换情况可以参考《Computer vision》笔记-AlexNet(1)文中的方式进行推导。由图可以看到,VGG-16 是一种只需要专注于构建卷积层的简单网络。首
先用 3×3,步幅为 1 的过滤器构建卷积层, padding 参数为 same 。然后用一个
2×2,步幅为 2 的过滤器构建最大池化层。因此 VGG 网络的一大优点是它确实简化了神经网
络结构。VGG-16 的这个数字 16,就是指在这个网络中包含 16 个卷积层和全连接
层。确实是个很大的网络,总共包含约 1.38 亿个参数,即便以现在的标准来看都算是非常
大的网络。但 VGG-16 的结构并不复杂,这点非常吸引人,而且这种网络结构很规整,都是
几个卷积层后面跟着可以压缩图像大小的池化层,池化层缩小图像的高度和宽度。同时,卷
积层的过滤器数量变化存在一定的规律,由 64 翻倍变成 128,再到 256 和 512。作者可能认
为 512 已经足够大了,所以后面的层就不再翻倍了。无论如何,每一步都进行翻倍,或者说
在每一组卷积层进行过滤器翻倍操作,正是设计此种网络结构的另一个简单原则。这种相对
一致的网络结构对研究者很有吸引力,而它的主要缺点是需要训练的特征数量非常巨大。代码如下所示:
import torchimport torch.nn as nnclass VGGNet16(nn.Module):def __init__(self,num_classes=10):super(VGGNet16,self).__init__()self.Conv=nn.Sequential(nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2,stride=2),nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.Conv2d(128,128,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2,stride=2),nn.Conv2d(128,256,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.Conv2d(256,256,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2,stride=2),nn.Conv2d(256,512,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.Conv2d(512,512,kernel_size=3,stride=1,padding=1),nn.ReLU(),nn.MaxPool2d(kernel_size=2,stride=2))self.classifier = nn.Sequential(nn.Linear( 6 * 6*512, 1024),nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(1024,1024),nn.ReLU(),nn.Dropout(p=0.5),nn.Linear(1024, num_classes),)def forward(self,inputs):x=self.Conv(inputs)x=x.view(-1,4*4*512)x=self.classifier(x)return xvgg=VGGNet16()print(vgg)
输出结果:
VGGNet16((Conv): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU()(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU()(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU()(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU()(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU()(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU()(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU()(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU()(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU()(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(classifier): Sequential((0): Linear(in_features=18432, out_features=1024, bias=True)(1): ReLU()(2): Dropout(p=0.5)(3): Linear(in_features=1024, out_features=1024, bias=True)(4): ReLU()(5): Dropout(p=0.5)(6): Linear(in_features=1024, out_features=1000, bias=True)))
加载数据:
import torchfrom torchvision import datasets,transformsimport osimport matplotlib.pyplot as pltimport time#transform = transforms.Compose是把一系列图片操作组合起来,比如减去像素均值等。#DataLoader读入的数据类型是PIL.Image#这里对图片不做任何处理,仅仅是把PIL.Image转换为torch.FloatTensor,从而可以被pytorch计算transform = transforms.Compose([transforms.Scale([224,224]),transforms.ToTensor(),#transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])#训练集train_set = datasets.CIFAR10(root='drive/pytorch/Alexnet/', train=True, transform=transform, target_transform=None, download=True)#测试集test_set=datasets.CIFAR10(root='drive/pytorch/Alexnet/',train=False,download=True,transform=transform)trainloader=torch.utils.data.DataLoader(train_set,batch_size=32,shuffle=True,num_workers=0)testloader=torch.utils.data.DataLoader(test_set,batch_size=32,shuffle=True,num_workers=0)classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')(data,label)=train_set[64]print(classes[label])
查看数据:
X_example,y_example=next(iter(trainloader))print(X_example.shape)img=X_example.permute(0, 2, 3, 1)print(img.shape)import torchvisionimg=torchvision.utils.make_grid(X_example)img=img.numpy().transpose([1,2,0])import matplotlib.pyplot as pltplt.imshow(img)plt.show()

本次训练并不直接使用上面的VGGNet16,直接使用Pytorch的models里面预训练好的模型,进行迁移学习,首先先下载模型,然后冻结前面的卷积层,仅对后面全连接层参数进行调整,调整之后再进行迁移学习,代码如下:
from torchvision import modelsvgg=models.vgg16(pretrained=True)for parma in vgg.parameters():parma.requires_grad = Falsevgg.classifier=torch.nn.Sequential(torch.nn.Linear(25088,4096),torch.nn.ReLU(),torch.nn.Dropout(p=0.5),torch.nn.Linear(4096,4096),torch.nn.ReLU(),torch.nn.Dropout(p=0.5),torch.nn.Linear(4096,10))cost=torch.nn.CrossEntropyLoss()optimizer=torch.optim.Adam(vgg.classifier.parameters(),lr=0.0001)import torch.optim as optim #导入torch.potim模块import timefrom torch.autograd import Variable # 这一步还没有显式用到variable,但是现在写在这里也没问题,后面会用到import torch.nn as nnimport torch.nn.functional as Fepoch_n=5for epoch in range(epoch_n):print("Epoch{}/{}".format(epoch,epoch_n-1))print("-"*10)running_loss = 0.0 #定义一个变量方便我们对loss进行输出running_corrects=0for i, data in enumerate(trainloader, 1): # 这里我们遇到了第一步中出现的trailoader,代码传入inputs, labels = data # data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labels#inputs=inputs.permute(0, 2, 3, 1)#print("hahah",len(labels))y_pred = vgg(inputs) # 把数据输进网络net,这个net()在第二步的代码最后一行我们已经定义了_,pred=torch.max(y_pred.data,1)optimizer.zero_grad() # 要把梯度重新归零,因为反向传播过程中梯度会累加上一次循环的梯度loss = cost(y_pred, labels) # 计算损失值,criterion我们在第三步里面定义了loss.backward() # loss进行反向传播,下文详解optimizer.step() # 当执行反向传播之后,把优化器的参数进行更新,以便进行下一轮# print statistics # 这几行代码不是必须的,为了打印出loss方便我们看而已,不影响训练过程running_loss += loss.item() # 从下面一行代码可以看出它是每循环0-1999共两千次才打印一次running_corrects+=torch.sum(pred==labels.data)if(i % 2 == 0): # print every 2000 mini-batches 所以每个2000次之类先用running_loss进行累加print("Batch{},Train Loss:{:.4f},Train ACC:{:.4f}".format(i,running_loss/i,100*running_corrects/(32*i)))
如下图可以看到,程序可以进行训练,由于时间和资源有限,仅仅是给出前面一部分训练输出的日志。

参考文献:
Andrew Ng 《Deep Learning》
https://arxiv.org/abs/1409.1556
http://www.mamicode.com/info-detail-2299459.html
