@Team
2020-03-10T15:37:31.000000Z
字数 4149
阅读 3290
anchor free的目标检测方法--FCOS
石文华
前言
全卷积的 one-stage目标检测器(FCOS),对每个像素进行预测的方式来解决目标检测问题,类似于语义分割。FCOS 不需要 anchor box,同时也不需要 proposals,由于消除了对预定义 anchor 的依赖,因此避免了与 anchor box相关的复杂计算,同时还避免了与 anchor相关的所有超参数,例如:尺寸、宽高比、数量等,通常这些参数对最终检测性能非常敏感。 FCOS 优于之前的 anchor-based one-stage detectors。
一、anchor-based detectors 存在的一些缺点: :
目前主流的目标检测算法,如Faster R-CNN,SSD 和YOLOv2,v3等都依赖于一组预定义的 anchor box,尽管 anchor box使检测器取得了巨大成功,但anchor-based detectors 存在的一些缺点:
1、如 Faster R-CNN 和 Focal Loss ,检测性能对anchor box 的尺寸、宽高比、数量非常敏感。 例如,在RetinaNet 中,根据 COCO 构建的 benchmark 上,仅仅改变这些超参数就会影响AP的性能提升4%。
2、由于 anchor box 的尺寸和宽高比保持固定,检测器在处理具有较大形状变化的目标数据集时会遇到困难,特别是对于小物体。 预定义的 anchor box 也妨碍了检测器的泛化能力,因为它们需要在具有不同物体尺寸或宽高比的新检测任务上进行重新设定。
3、为了实现高召回率,anchor-based 检测器需要将 anchor box 密集地放置在输入图像上,造成正负样本不均衡。
4、当在训练期间计算所有 anchor box 和 GT之间的 IOU 时,过多数量的 anchor box 也显著增加了计算量和存储器占用量。
二、FCOS具有以下优点:
1、使得检测与许多其他FCN可解决的任务(如语义分割)统一起来,从而更容易重用这些任务中的思想。
2、检测成为proposal free 和 anchor free,这大大减少了设计参数的数量(超参数)。设计超参数通常需要启发式调整,需要使用许多技巧才能获得良好的性能。因此,新的检测框架使得检测器的训练变得非常简单。
3、通过消除anchor box,新检测器完全避免了anchor box相关的复杂的IOU计算以及训练过程中anchor 与GT之间的匹配,使得训练和测试速度更快,同时训练内存占用更少。
4、FCOS在 One-Stage Detectors 中实现了 SOTA 的结果,实验还表明,FCOS 可以用作 Two-Stage Detectors 中的 RPN,并且可以实现比基于 anchor Box的 RPN 更好的性能。考虑到更简单的anchor free 检测器有更好的性能,鼓励重新考虑anchor Box在目标检测中的必要性,虽然目前anchor Box这被认为是检测任务的事实标准。
5、该检测器只需做很小的修改就可以扩展并解决其他视觉任务,包括实例分割和关键点检测。作者相信这种新方法可以作为许多实例级预测问题的新基准。
三、细节:
设是 backbone CNN的第层的特征图, 是该到该层累积的总的 stride,输入图像真实框GT Box定义为,
其中,,这里和表示GT box左上角和右下角的坐标,是GT Box对象所属的类别,在coco数据集中是C等于80,即80个类别。对于特征图上的每个位置,将其映射回原始图片上的坐标,差不多刚好位于位置的感受野中心附近,与基于anchor的检测器将输入图片上的位置视为anchor box中心点并对这些 anchor box 的目标边界框进行回归不同,FCOS直接回归每个位置的目标边界框,也就是Detector 直接将 location 视为训练样本而不是将 anchor box 视为训练样本,相当于语义分割的FCN。
具体的说,如果位于任何一个GT box的内部,就将它当做正样本,并且该位置的类标签 就是 的类标签,否则就是负样本并且 c∗=0(即背景类),除了用于分类的标签以外,还定义了一个4D的实数向量来表示每个样本的回归目标。表示的是该位置到GT box的4条边的距离,如下图左图所示:

如果某个位置位于多个GT box内,则会将其视为模糊样本,处理策略是只选择具有最小面积的边界框作为其回归目标,通过多级预测的方式,可以显著减少模糊样本的数量。如果与某个关联,则该位置的训练回归目标表示如下:
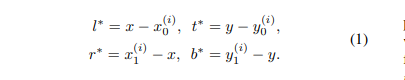
需要注意的是,FCOS 可以利用尽可能多的前景样本来训练回归量,而anchor-based detectors 仅仅将与 GT box 具有足够 IOU 的anchor box 作为正样本。
1、网络的输出
网络的最后一层会预测用于分类的 80D 向量和 bounding box 坐标 4D 向量,训练分类的时候不是训练多类分类器,而是训练 个二元分类器,与 R-CNN 类似,在 backbone网络的特征图之后分别为分类和回归分支添加了四个卷积层,此外,由于回归目标总是正的,使用将任意的实数都映射到回归分支顶部的,需要注意的是,FCOS 的网络输出变量比常用的 anchor based detectors 少 9 倍,因为anchor based detectors每个位置有 9 个 anchor boxes。
2、损失函数
定义的损失函数如下:
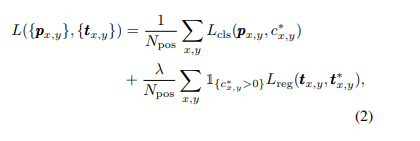
其中,是 Focal Loss作为损失函数,是 IOU 的loss, 代表 positive samples 的数量, 在本文中均为 1,如果,则为1,否则为0。
3、推理预测
给定输入图像,将其放入网络进行一次 forward 计算, 并获得特征图上的每个位置的分类分数以及回归预测值,将>0.05的位置作为正样本并通过反转公式(1)来获得预测的边界框。
四、基于FPN的FCOS多级预测
FCOS 存在的两个可能的问题:
1、网络最后的 feature maps 的大步幅(例如16)可能导致相对较低的 best possible recall(BPR),对于基于anchor的检测器,由于大步幅导致的低召回率可以通过降低 positive anchor boxes 所需的IOU分数来缓解,对于FCOS,实验结果表明即使步幅很大,基于 FCN 的 FCOS 仍能产生良好的BPR,它甚至可以比官方实现的 Detectron 中基于 anchor 的检测器 RetinaNet 的 BPR更好,利用多级 FPN 预测,可以进一步改进 BPR 。
2、与真实框的重叠会导致在训练期间产生模糊性(即哪个边界框应该在重叠位置进行回归),采用多级预测方法可以有效地解决模糊问题。
多级预测的具体方式与FPN类似,在不同级别的特征图上检测到不同大小的对象,五种级别的特征图,其中在骨干网络的特征图上接1x1的卷积得到,分别在上使用一个步长为 2 的卷积层得到,这五种级别的特征图的步长分别为8,16,32,64和128。如下图所示:
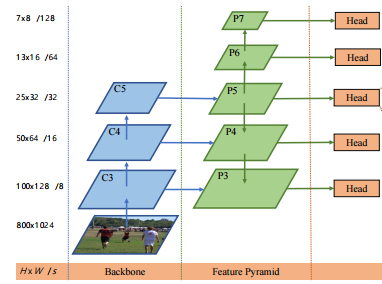
大多数重叠发生在具有显著不同大小的对象之间,为了将具有不同大小的对象分配到不同的特征级别上,作者直接限制边界框回归的范围,具体做法是首先计算所有特征级别上每个位置的回归目标l、t、r、b,如果位置满足max(l, t, r, b) > mi 或者 max(l, t, r, b) < mi -1,则将其设置为负样本并且再也不会对该位置进行回归操作,mi是特征层级 i 需要回归的最大距离,m2,m3,m4,m5,m6 和 m7 分别设置为 0,64,128,256,512 和 ∞,如果一个位置,即使使用多级预测方式,仍然被分配给多个真实框,我们只需选择最小面积的真实框作为目标。这种多级预测可以很大程度减轻重叠导致的模糊性并且将基于 FCN 的检测器提升到与基于 anchor 的检测器相同的检测性能。
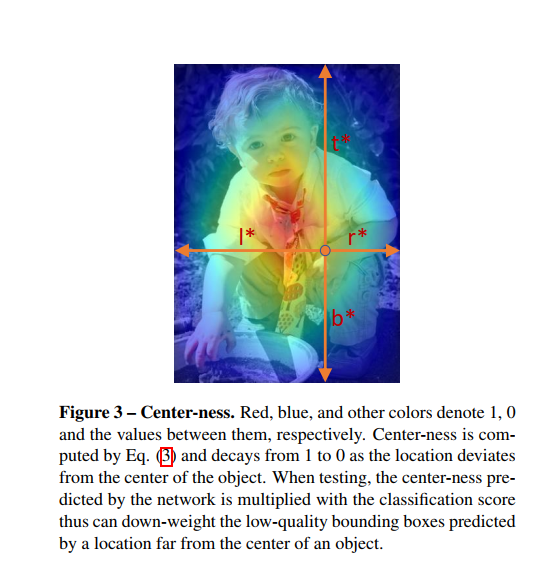
五、center-ness
由于远离物体中心的位置产生的许多低质量预测边界框,造成了FCOS 和 anchor based的检测器之间仍存在性能差距。对于这个问题,作者引入一个单层分支,与分类分支并行,以预测一个位置的“中心概率(center-ness)”(即,从该位置到该位置所负责的对象的中心的距离)。center-ness target 定义为:
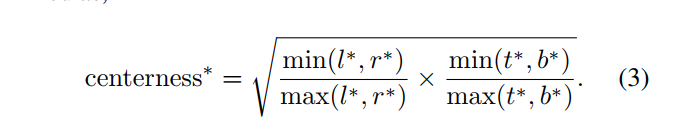
center-ness 取值0到1之间,用交叉熵(BCE)损失训练。 损失被添加到上面的损失函数公式中。在测试阶段,通过将预测的 center-ness 与相应的分类得分相乘来计算最终得分(用于对检测到的边界框进行排序)。 因此, center-ness 可以使远离物体中心的边界框的 scores 减小。 因此,这些低质量的边界框很可能被最终的非极大抑制(NMS)过程滤除,从而显著提高检测性能。如下图所示:
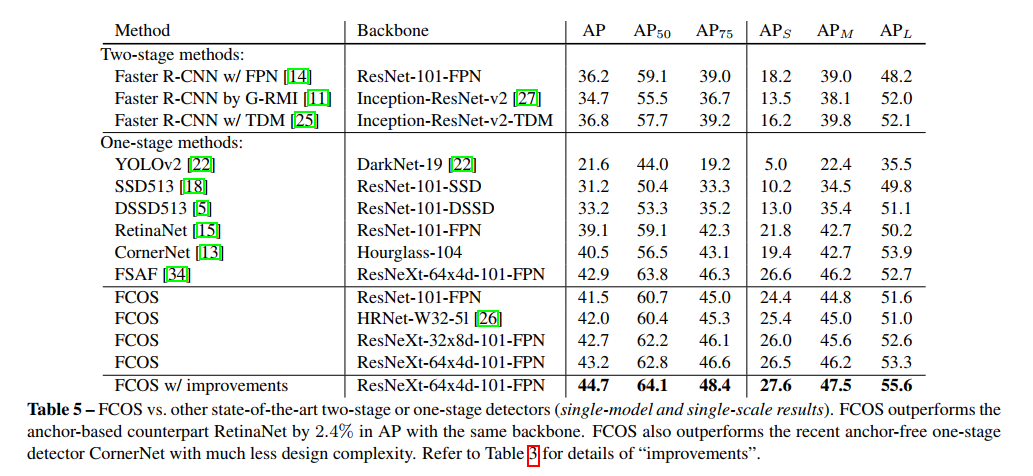
六、实验效果
FCOS vs. other SOTA一阶、二阶检测器
FCOS开源代码地址如下:
https://github.com/tianzhi0549/FCOS
