@Team
2019-11-01T13:00:15.000000Z
字数 6809
阅读 4766
《从零开始学习自然语言处理(NLP)》-BERT模型推理加速总结(5)
刘才权
1 BERT模型介绍
BERT是NLP任务的集大成者。 发布时,在GLUE 上的效果排名第一。
在语义表征方面
将基于浅层语义表征的词向量,加强为深层语义特征向量。同时,引入上下文特征,解决了词向量一词多义的问题。
在知识迁移方面
能够在海量的无监督文本训练语料中,有效的抽取语义特征。Pre-Train+Fine-Turning的模式下,非常实用。
在计算效率方面
BERT基于Transformer实现,采用self-attention机制,采用并行的矩阵运算,替代RNN的串行执行,有效提升模型计算效率。
在任务设计方面
BERT提供了分类、相似度计算(也是一种分类)、序列标注等NLP任务模板,基本覆盖了NLP任务的大多数模型应用场景。
具体的BERT介绍可以参考Google的论文:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
在学习BERT之前,建议先熟悉Transformer,具体可以参考Google论文:《Attention Is All You Need》
直接看论文可能不好理解,建议先参考网上的Blog:
图解Transformer:《The Illustrated Transformer》
图解BERT:《The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)》
很多国内的博客都是上面两篇博客的翻译或者引用。
BERT在NLP预训练领域确实有里程碑的意义,这篇博客做了不错的总结:《从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史》
2 BERT模型的困境
虽然BERT有各种优点,在项目落地上却存在缺陷:计算复杂度过高。通过BERT模型的参数量,感受下:
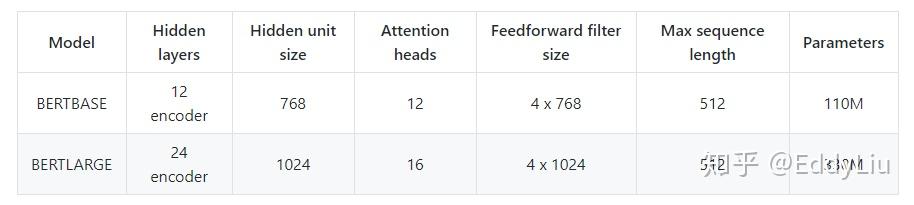
数据来源:https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT
针对BERT模型,我们从预训练(Pre-train)、Fine-tuning、推理三个维度来看模型的计算耗时。
模型训练(Pre-train)时间:
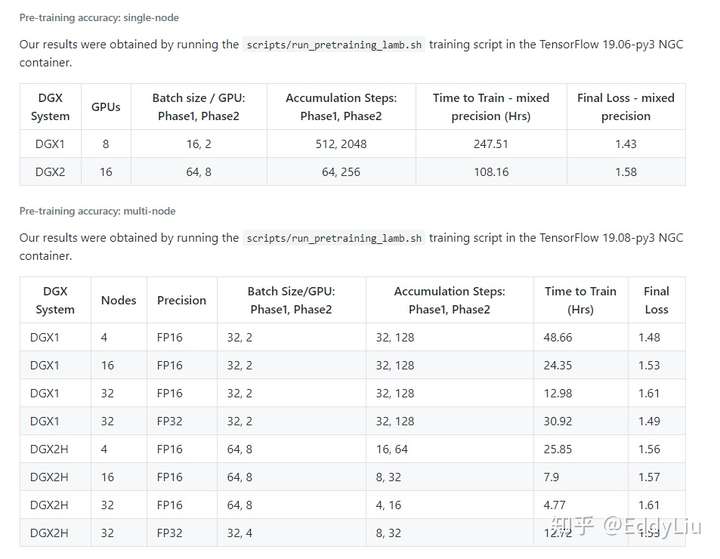
数据来源:https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT
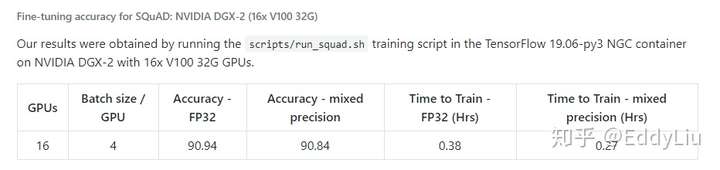
Fine-tuning时间:
模型推理时间:
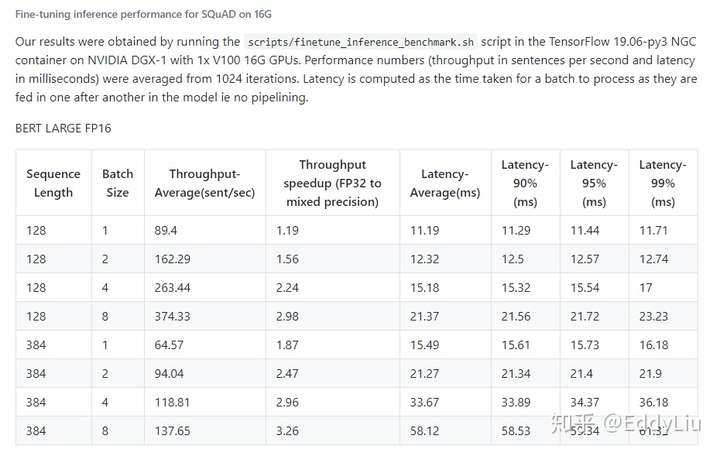
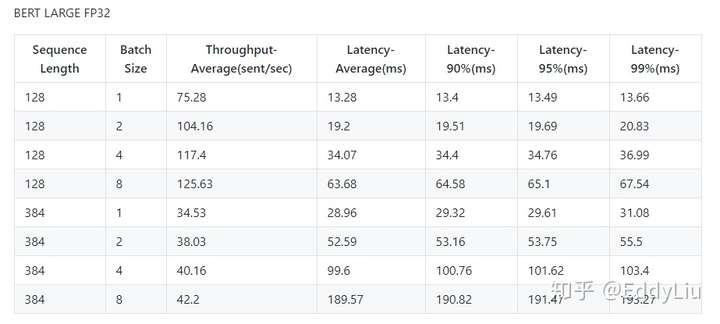
数据来源:https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT
从上面的数据来看,预训练(Pre-train)要求的计算资源最大,耗时最长。自己做预训练相对较难。还好Google提供预训练模型(包括中文的预训练模型),git地址:https://github.com/google-research/bert
如果,计算资源充裕,可以使用自己的语料进行预训练,从实际的项目经验反馈来看,用自己的业务相关语料进行预训练,对模型的最终效果,相对于使用Google通用的预训练模型,有小幅提升。
Fine-tuning的计算在实际项目应用中基本可以接受,这里不做特别的深入。
最后需要关注的就是模型推理,而这也是服务上线最需要关注的。后面我们的分析重点,也集中在如何提升BERT模型的推理效率。
3 BERT模型推理加速方案汇总
BERT的模型优化方案,大概有下面几个方面:
3.1 编译优化
这里的编译优化主要指计算框架自身的编译优化,以TensorFlow的XLA为例,
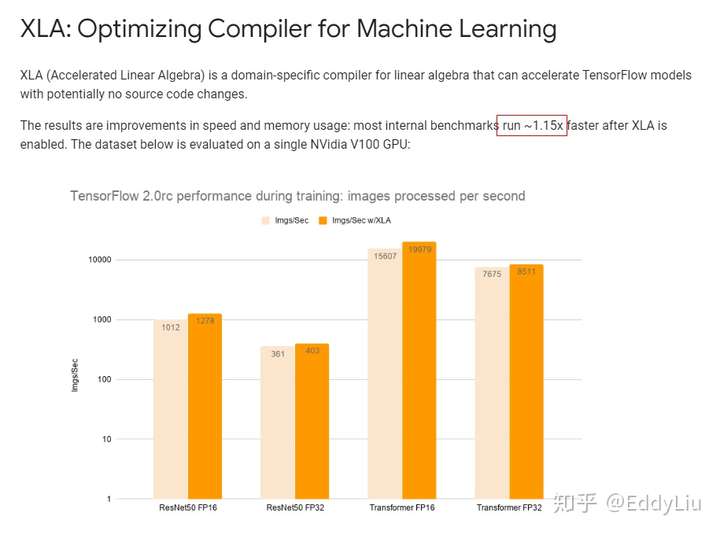
数据来源:https://www.tensorflow.org/xla
从实际的数据来看,TensorFlow的XLA优化能力有限,>1.15倍。
3.2 知识蒸馏
知识蒸馏是一个不错的模型压缩方案,通过小模型(student)来学习大模型(teacher)的能力。但一般来说,通过蒸馏获得小模型,相对于原来的小模型有算法效果提升,但不能保证能完全达到大模型(teacher)的效果。
TinyBERT就是使用了这种思路,具体可以参考paper《TinyBERT: Distilling BERT for Natural Language Understanding》
3.3 混合精度(Nvidia-TensorCore)
一般模型的参数使用FP32(单精度)进行保存和计算。特定的计算平台,比如英伟达的P100,可以使用单个的FP32寄存器,缓存两个FP16(半精度)变量,并进行并行计算,参考《Nvidia GPU的浮点计算能力》。
同时,英伟达的瓦特架构(Tesla V100)和图灵架构(Tesla T4)有TensorCore计算单元,可以同时完成混合精度矩阵的乘加运算。具体可以参考《Video Series: Mixed-Precision Training Techniques Using Tensor Cores for Deep Learning》。
将模型中的FP32变量替换成FP16,可以有效的压缩模型大小,同时,可以提升模型的训练及推理速度。但对模型效果会不会有影响呢?答案,肯定是不会的。具体原因可以参考这篇paper《Mixed Precision Training》。
文章主要提了三个方法:
1 FP32 MASTER COPY OF WEIGHTS
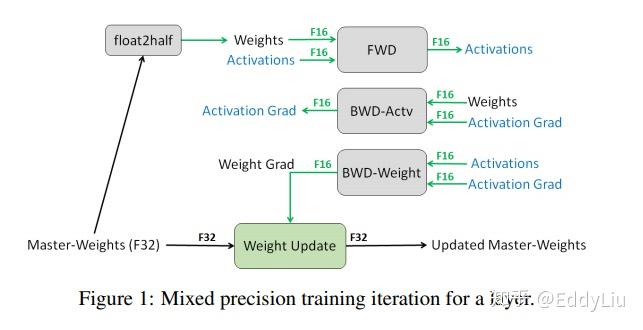
简单的说就是把FP32的变量先拷贝一份,然后把所有的变量都量化成FP16。在前向和反向计算时都使用FP16,只是在最后更新参数时转化为FP32。
这样做也很好理解,更新参数时,一方面,会进行整个batch参数相加(然后取均值),转化成FP32避免向上溢出;另一方面,非常小的梯度会乘以学习率(一般<1),转化成FP32避免向下溢出。
2 LOSS SCALING
就是计算梯度时,梯度一般都会非常小,这里将梯度先乘以一个较大的系数进行放大,避免反向传播发生下溢出,最终再除以一个相同系数进行缩小,恢复正常值,从而在FP16精度的情况下,完成计算。
3 ARITHMETIC PRECISION
这里其实就是介绍了下英伟达的专用硬件模块TensorCore,可以同时完成混合精度的矩阵乘加运算。
ps:这篇paper的作者来自百度和英伟达。
在Nvidia平台上,使用混合精度也非常方便,TensorFlow直接集成了Nvidia的混合精度特性,具体操作如下:

参考《Automatic Mixed Precision for Deep Learning》
3.4 Nvidia-编译优化(TensorRT)
除了TensorFlow自己的XLA优化编译之外,Nvidia推出了自己的模型编译优化方案TensorRT。XLA完成的是通用平台的模型压缩和剪枝优化编译,TensorRT更侧重跟自家平台的结合。
在Nvidia的GPU平台上TensorRT应该比XLA有更好的优化效果。TensorRT其实是一个较大的工具体系,混合精度、模型优化编译、自定义Plugin、TensorRT Serving都是它的组成部分。所以,不要单纯的理解TensorRT只是用来做编译优化的。
3.5 Nvidia-Batch合并(TensorRT Inference Serving)
Batch合并操作充分利用了计算平台并行计算的能力。假设有8个请求,一种方式是每个请求顺序发给模型,然后,串行获取结果;另一种是8个请求合并成一个batch请求模型,然后,并行获取结果。在GPU这样的并行计算平台,后者的计算效率更高。
TensorRT Inference Serving就是利用这个特点,在可容忍的时间相应时间内,尽量合并请求,进行batch处理,从而,提升服务的吞吐量。这是BERT模型在TensorRT Inference Serving的表现:
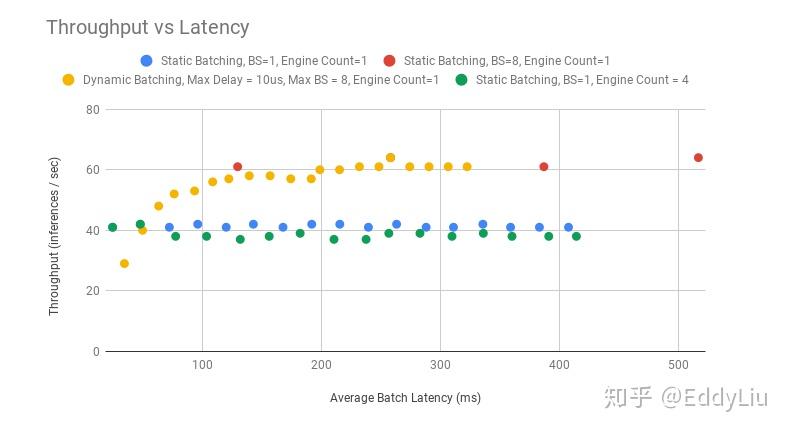
数据来源:https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT
使用TensorRT Inference Serving后,服务的吞吐量有明显的提升。
3.6 Nvidia-自定义Plugin(TensorRT)
Plugin的意思是指模型中的特定计算操作。可以是重写TensorFlow中的算子(如softmax操作),也可以是自定义的矩阵乘加运算。TensorRT提供了C++和Python层的接口,可以进行自定义Plugin的编写。
这些自定义的操作,一方面,可以充分利用Nvidia GPU的计算特性;另一方面,在网络编译优化阶段也会有更好的效果。TensorRT的具体使用可以参考《TensorRT Developer Guide》。
这部分会是BERT性能优化最大的地方,后面的内容会围绕这一点重点展开。
4 BERT模型推理加速优化实践
Nvidia对BERT加速做了专门的工作,也获得不不错的效果,先看结果感受下:
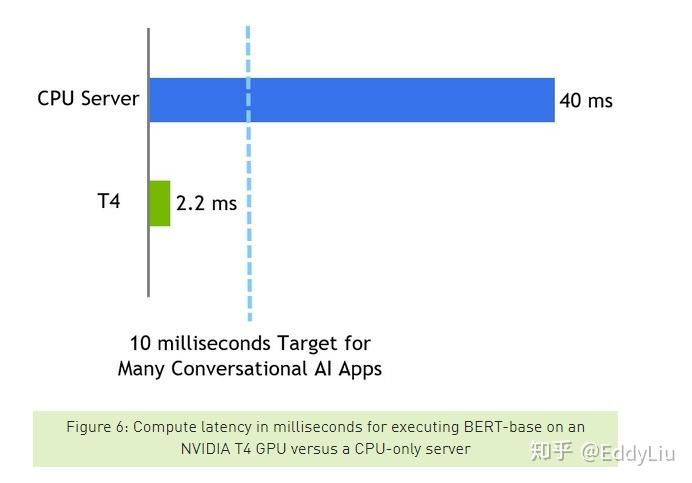
数据来源:https://devblogs.nvidia.com/nlu-with-tensorrt-bert/
4.1 基于TensorRT API实现
在阅读理解任务上的响应时间压缩到了2.2ms,可见优化效果是非常明显的。英伟达开源了整个实验的数据和代码,具体可以参考《Real-Time Natural Language Understanding with BERT Using TensorRT》
基本思路是:
1 Fine-tuning获得的TensorFlow的ckpt模型(如果需要开启混合精度能力,需要在Fine-tuning步骤完成,建议直接使用英伟达修改过的BERT模型,参考《DeepLearningExamples/TensorFlow/LanguageModeling/BERT》)
2 使用TensorRT重新实现BERT,主要是Transformer部分(可以理解自定义了很多Plugin),同时,也包含任务相关的部分代码(如分类任务和阅读理解任务的实现是不同的)
3 使用TensorRT接口加载ckpt模型文件并获取参数
4 将参数输入给重新实现的BERT网络
5 优化编译并输出优化后的模型文件(TensorRT-engine文件)
6 加载TensorRT-engine文件,并进行推理
文中的示例只提供了阅读理解的实现,如果是分类问题,需要自己使用TensorRT API编写Transformer输出后,任务相关的代码,并对其参数。这里需要熟悉TensorRT的API,操作起来比较麻烦。
4.2 基于Fast Transformer实现
如果先看了《Real-Time Natural Language Understanding with BERT Using TensorRT》这篇文章,并尝试文中的方法进行分类分类任务。再看到基于Fast Transformer的方案,肯定觉得自己走了弯路(PS,我就是这样,汗~)。
BERT的核心是Transformer,Nvidia很贴心的把Transformer(主要是Encoder)以组件的形式进行了加速优化,并作为单独的开源项目发布(实现原理和上面一致)。项目参考《Faster Transformer》
简单来说,就是编写推理服务时,还是继续使用TensorFlow,只是其中的Google默认实现的Transformer被Nvidia换成了自己的定制实现模块。Transformer之外的部分原封不动。这样就既实现了BERT的计算加速,又保证了使用的灵活性。效果还是蛮不错的:

数据来源:https://github.com/NVIDIA/DeepLearningExamples/blob/master/FasterTransformer/sample/tensorflow_bert/sample.md
这里多说一句,后面Nvidia会开源Fast Transformer 2.0,核心就是实现了Transformer的Decoder。
另外,TensorRT和Fast Transformer Nvidia有专门的在线研讨会(虽然过期了,但可以回看),这里推荐两个,《利用 TensorRT 自由搭建高性能推理模型》,《Faster Transformer 介绍》
总结
本文介绍了BERT的基本情况,面临的上线问题,以及加速优化的各种方案及原理。最后提出了基于Fast Transformer的通用加速方案。
资料参考
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》:https://arxiv.org/abs/1810.04805
《Attention Is All You Need》:https://arxiv.org/abs/1706.03762
《The Illustrated Transformer》:https://jalammar.github.io/illustrated-transformer/
《The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)》:https://jalammar.github.io/illustrated-bert/
《从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史》:https://zhuanlan.zhihu.com/p/49271699
《TinyBERT: Distilling BERT for Natural Language Understanding》:https://arxiv.org/abs/1909.10351
《Nvidia GPU的浮点计算能力》:https://weibo.com/ttarticle/p/show?id=2309403987017473113077
《Video Series: Mixed-Precision Training Techniques Using Tensor Cores for Deep Learning》:https://devblogs.nvidia.com/video-mixed-precision-techniques-tensor-cores-deep-learning/?ncid=so-twi-dplgdrd3-73821
《Mixed Precision Training》:https://arxiv.org/abs/1710.03740
《Automatic Mixed Precision for Deep Learning》:https://developer.nvidia.com/automatic-mixed-precision
《TensorRT Developer Guide》:https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#extending
《NVIDIA/tensorrt-inference-server》:https://github.com/NVIDIA/tensorrt-inference-server
《Real-Time Natural Language Understanding with BERT Using TensorRT》:https://devblogs.nvidia.com/nlu-with-tensorrt-bert/
《Faster Transformer》:https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer
《利用 TensorRT 自由搭建高性能推理模型》:https://info.nvidia.com/223020-ondemand.html
《Faster Transformer 介绍》:https://mudu.tv/watch/3737641?key=502dfd75f66e66a8d5e4621c0887f617&expire=600
《DeepLearningExamples/TensorFlow/LanguageModeling/BERT》:https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT
