@Team
2018-04-25T01:07:30.000000Z
字数 6883
阅读 3868
强化学习通俗理解系列一:马尔科夫奖赏过程MRP
黄海安
0 前言
本文写作目的:尽量通俗讲解强化学习知识,使读者不会被各种概念吓倒!本文是第一篇,但是最关键的一篇是第二篇马尔科夫决策过程(Markov Decision Process,MDP),只有充分理解了马尔科夫决策过程,才能游刃有余的学习后续知识,所以希望读者能够将MDP深入理解后再去学习后续内容。
由于本人水平有限,文章写作顺序几乎是完全按照David Silver强化学习课程讲解,但是会补充自己学习心得,所以文章会比较通俗易懂。由于本人接触时间也不长,如有错误,欢迎指出,我及时修改!谢谢。
本文思路:
1. 强化学习基本概念
2. 强化学习与其他机器学习算法区别和联系
3. 马尔科夫性质
4. 马尔科夫过程
5. 马尔科夫奖赏过程
6. 总结
1 强化学习简要说明
强化学习(Reinforcement Learning, RL)是一类算法,发展历史也很久了,只不过由于深度学习的快速发展,也快速推动了RL的发展,使得深度强化学习成为研究热点,特别是Alpha go、游戏AI等的广泛传播使得人尽皆知。由于这类文章特别多,这里就不再赘述。这里只介绍RL常见的概念和其他机器学习算法区别。
1.1 强化学习基本概念
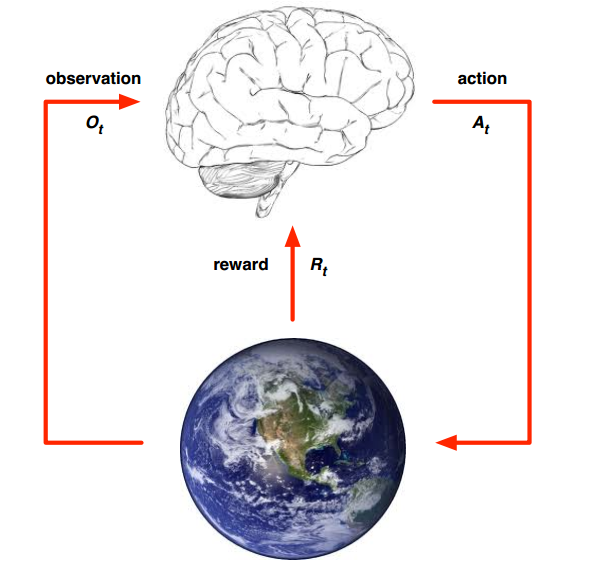
强化学习,从字面理解包括强化和学习过程,强化代表着提升即不断提升自己,而学习代表着不断感知周围环境,并接收环境给予的反馈,强化和学习是一个不断循环迭代的过程,直到达到最优决策。以上图结合动物园猴子学骑车为例:图中的大脑即为agent,对应的就是猴子;action表示动作,对应的就是猴子往哪个方向走,设action是{左,右,上,下};地球代表环境,环境是可以感知的,并且执行某个或者某些action后会给出reward奖励,对应的就是猴子骑车到达了指定位置,就可以获得香蕉reward;observation表示可观测序列,对应的就是训猴子的人看到的一系列猴子做出的动作。
在训练猴子的过程中,一个完整的强化学习过程是:人督促猴子做出某个动作action,然后训猴子的人观察observation是否正确,在猴子执行了一系列动作到达目的地后给予香蕉reward,如果没有到达就啥也不给。每次完成一次或者失败一次后,重新恢复到原始位置,不断循环重复,直到猴子学会了如何快速骑车到达目的地。
上述例子其实涉及到很大部分强化学习概念即:
- agent 代理
1.1 Executes action 可执行动作
1.2 Receives observation 可观测序列
1.3 Receives scalar reward 可接收回报 是一个标量,简单来说就是数值,后面会详细说明其意义- environment环境
2.1 Receives action 可接收动作
2.2 Emits observation 发射观测序列
2.3 Emits scalar reward 发射标量回报
其中表示第个步骤或者阶段,对应的就是猴子骑车的每一个时刻。 写了一大堆,其实上面内容都不重要,因为太过概念化、官方化了。大家只需要了解大意即可,实际上我觉得对于RL的上述概念其实很好理解,一看就懂,无需多言!
1.2 强化学习与其他机器学习算法区别与联系
需要了解一些强化学习和其他机器学习算法的区别和联系。简单来说强化学习特点是:
- RL没有supervisor,只有一个reward signal。它不需要提供标注的数据
- RL问题中的feedback是延时的。对于上面的猴子骑车问题,猴子并不是每骑一个方向就有奖励,只有当它骑了好多步并且到达目的地才有奖励,是有延迟的
- 时序数据,不满足iid独立同分布性质
- 当前动作执行会影响后续接收数据
通过下面两幅图可以很容易看出区别:

1.3 强化学习目的
reward回报是强化学习中最重要的东西,它是一个标量反馈信号,表示agent在当前t时刻做的有多好。给一支香蕉和不给香蕉就可以认为是reward,假设定义为{1,0},而强化学习算法的目标或者说优化函数就是最大化累计回报(maximise cumulative reward),对于序列化决策问题,强化学习就是选择一些action使得将来回报最大;对于训练猴子问题,强化学习目的就是通过让猴子知道只有骑车到达目的地才能得到最多香蕉;对于走迷宫问题,就是让机器人学习出一条路径,按照这条路径走才能最快出迷宫。
总之,不管啥强化学习算法,本质目的就是maximisation of expected cumulative reward,好比机器学习或者深度学习算法,本质目的就是优化某个损失函数而已,而最大化累计回报也可以认为是函数,但是不能认为是损失函数(损失函数是要值下降的)。
2 马尔科夫性质
看到这里,您才算真正进入了强化学习了,恭喜你!
既然RL是一个时序决策问题,那么就涉及到历史决策信息,如果每一步决策都要考虑历史前n多步的决策,可想而知,解决这类问题非常复杂,故而为了简化问题或者说实际上很多情况都是可以这样近似的而引入马尔科夫链(Markov chain,MC)性质。实际上对于熟悉机器学习算法的人应该很清楚这部分,在贝叶斯网络、隐马尔科夫模型、文档主题生成模型LDA、贝叶斯决策等算法中都有用到该性质。其定义为:

如果说状态是马尔科夫的,当前仅当满足上述式子。意思是处于状态下,出现的概率只与状态有关,而和之前的状态无关,或者说给定当前状态,将来的状态与时刻之前的状态没有关系。这样的性质使得时序决策问题瞬间简单很多。但是需要说明的是这种性质是有依据的,并不是说故意简化,例如走迷宫问题,每一步做出的决策,都是基于站在当前位置看到的信息而言的,是非常符合实际的。
3 状态转移矩阵
在上一节中,概率P实际上是状态转移矩阵(State Transition Matrix),表示从状态转移到状态存在的概率,完整的状态转移矩阵表征的是所有状态的转移概率,是非常重要的矩阵,可以看出它是满足马尔科夫性质的。
对于一个马尔科夫状态和下一个状态,状态转移可以定义为:
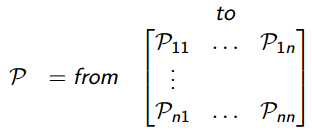
注意:每一行概率和肯定是1,因为从当前状态转移到其他所有状态的概率和必然是1。
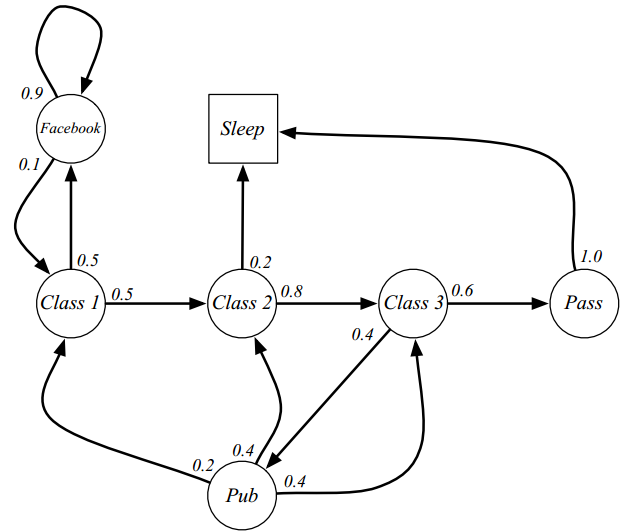
上图是本文分析的核心状态转移图,也是从David Silver强化学习课程的PPT中而来,后面的每一个过程都会用这副图来讲解。对应上图的状态转移矩阵是:

空白的地方可以填入-1或者0,表示不可转移。
4 马尔科夫过程
马尔科夫过程Markov Process或者马尔科夫链是一个无记忆随机过程,是一些具有马尔科夫性质的随机状态序列构成,可以用一个元组表示,其中S是有限数量的状态集,P是状态转移概率矩阵。如下:

上面的状态转移图就是一个关于学生的马尔科夫随机过程(马尔科夫链)。每一个圆圈代表一个state,图中一共7个state,分别是{facebook,calss1,class2,class3,pass,pub,sleep},sleep是吸收状态,可以保证马尔科夫序列是一个有限序列,箭头表示状态转移,箭头上方的数据表示转移概率值。例如当学生处于class2状态,他有0.2的概率进入sleep状态,有0.8的概率进入class3状态,其他分析同理。
5 马尔科夫奖赏过程
5.1 马尔科夫奖赏过程定义
马尔科夫奖励过程Markov Reward Process是在马尔科夫过程的基础上增加了奖励R和衰减系数γ,其定义如下:

是奖励函数,状态下的奖励是在时刻处,在当前状态下,下一个时刻能获得的奖励期望。这个不好理解,David指出这仅是一个约定,一般我们都是说是离开该状态能够获得的立即奖励。

上图中的就是奖励,是自己定义的。例如当学生处在第一节课(Class1)时,他参加第2节课(Class2)后获得的Reward是-1;同时进入到浏览facebook这个状态中获得的Reward也是-1,一般我们是说:他从class1状态离开,进入到class2状态所得到的离开立即奖励是-2,如果大家统一说法,其实就非常好理解了。由于作者认为最终目的是通过考试,所以在pass状态下离开获得的立即奖励是非常大的=10。
5.2 Return
下面引出一个非常重要的公式,这个公式是后续推导的最原始形式。Return 定义:收获 为在一个马尔科夫奖励过程中上从t时刻开始往后所有的奖励的有衰减的收益总和。其定义为:

指的是衰减因子,体现的是未来的奖励在当前时刻的价值比例,接近0,则表明趋向于“近视”性评估; 接近1则表明偏重考虑远期的利益,很好理解,当=0时收获的回报就是只考虑当前一步,有可能陷入误区,当=1时收获的回报考虑了未来,当前一步的回报并不是占主要地位。和机器学习中常用的滑动平均模型其实原理是一样,你对未来更信任一点,那么就设置大一些,你对未来没有信心,只关心目前状况,那么小一点即可。在David PPT里面也有解释为何要引入:
1.数学表达的方便,这也是最重要的
2.避免陷入无限循环
3.远期利益具有一定的不确定性
4.在金融学上,立即的回报相对于延迟的汇报能够获得更多的利益
5.符合人类更看重眼前利益的性格
需要注意的是并不只是一条路径,从t时刻到终止状态或者吸收时刻,可能会有多条路。
依然以上面的学生状态转移图为例:一个学生的样本片段序列episodes是从class1开始,终止于sleep状态,其观测得到的出现的状态转移序列是(还有其他很多可能序列,但是可能没有观测到):

所以实际上你想计算出精确的是不可能的,因为你无法穷尽所有序列,但是可以通过采样来近似计算。具体计算看后面。
5.3 状态值函数 State Value function
上面说过是不好算的,因为路径是非常多条的,而值函数的引入就是为了解决上述问题。值函数给出了某一状态或某一行为的长期价值,其定义是:一个马尔科夫奖励过程中某一状态的价值函数为从该状态开始的马尔可夫链收获的期望。
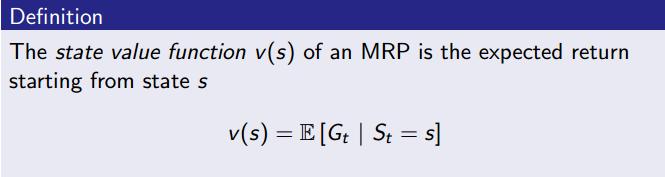
值函数是一个数值,而且包括了多条路径,这样就可以解决上述难题了。期望的作用就是把从t时刻到终止状态的马尔科夫链的每一条对应的概率和Return收益进行求平均得到一个定值,方便后续优化。以学生状态转移图为例:

以第二条路径进行分析:图中的v1其实写成更好一些
v1=C1状态离开的即时奖励+ × FB状态离开的即时奖励+ ×
FB状态离开的即时奖励+ × C1状态离开的即时奖励+ × C2状态离开的即时奖励
如果仅仅观测到以上4条序列,那么在状态Class1处学生的值函数v(s)就是上述4个值除以4即可,。
再次以下图为例,阐述一下状态值函数的计算方法:
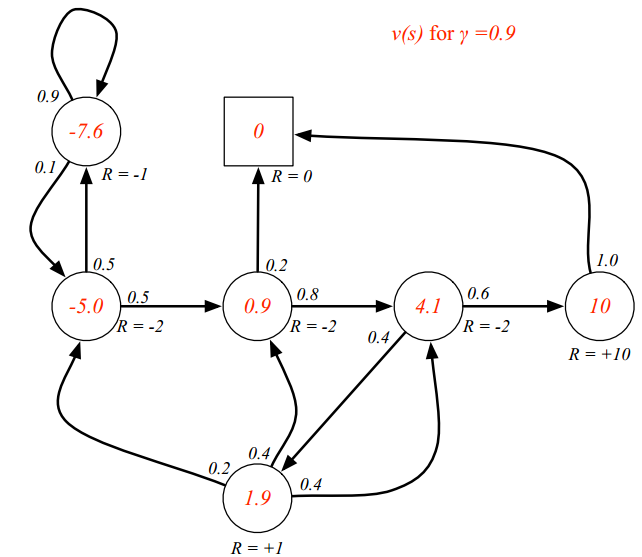
v(pass)=10
v(class3)=0.6(-2+0.9*10)+0.4*(-2+0.9*1.9)=4.1
可能你存在疑问:计算v(class3)直接使用了v(pub)的值,但是目前来说v(pub)是还没有计算出来的。确实如果采用上面的计算方法确实是没法计算的,但是就上面问题而言,实际上是可以通过线性代数直接求出来或者通过迭代化求解,在下一小结会讲解。这里先提前说明一个知识点:假设你已经算出来上面的各个状态下的值函数,那么对于强化学习而言,假设是找到一条最优路径,起点状态是class1,那么很明显最优状态链是class1->class2->class3->pass->sleep,也就是说这条路径的累计回报最大,也就是说值函数求出来了,其实强化学习问题就解决了,对应的就是后续的值迭代法、Q-learning等思路了。这些算法后面会细说,大家不用着急。
5.4 贝尔曼期望方程Bellman Equation
状态值函数的引入解决了Return 路径有很多条,不容易优化的问题,将其转化为期望就变成固定标量了,很明显的转化。但是现在又出现另一个问题了,状态值函数也不好算,因为在计算某个状态时候需要使用到将来所有状态的,这明显是不科学的。那么凭借大家学习算法思想,既然是状态更新,既然是马尔科夫的,很容易想到应用迭代思想求解,而贝尔曼期望方程就是一个迭代方程,目的是使得状态值函数容易求解。
设离开某状态的立即回报是,后继状态的折扣价值函数是,那么有:
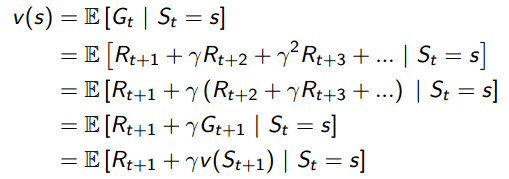
对于倒数第二步推导到最后一步的推导,可能很多人有疑问,我推导一下:
好的,现在得出结论:针对马尔科夫奖赏过程MRP的Bellman Equation方程是:
下面把期望E去掉,假设下一时刻状态是,那么有:
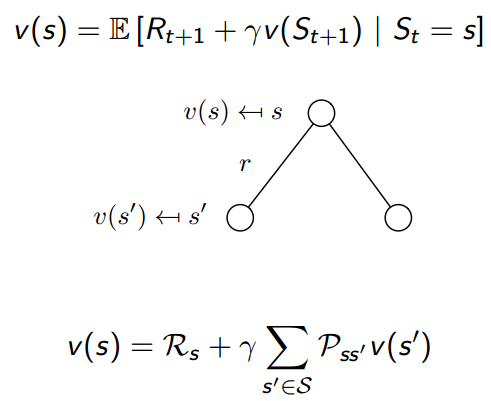
上图的空心圆圈表示状态,说个题外话:我希望大家立即公式能够把对应的状态连接图记住,类似上面那个图,因为从这个图很容易推导出公式,很容易理解记忆。去掉期望后,v(s)就等于离开该状态的立即回报加上各条后继状态的转移概率乘以对于的,再乘以衰减因子。上述公式非常重要。依然以学生为例:
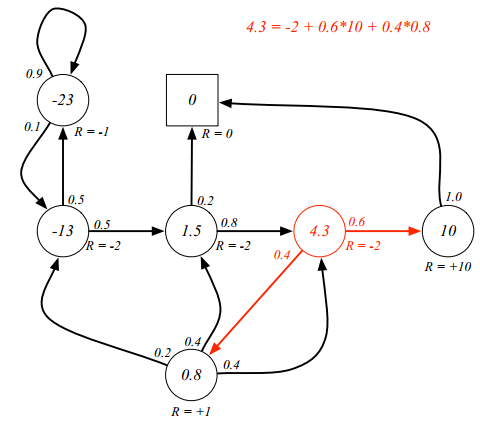
在状态class3处的状态值函数计算就非常简单了。这里还是需要说明:其实一开始计算时候0.8肯定是不存在的,实际计算可以采用迭代法,一开始任意初始化,后面学习更新即可,这就是所谓的值迭代法。当然对于这个问题,可以采用下面的方法直接求解。
5.5 贝尔曼期望方程的矩阵形式Bellman Equation in Matrix Form

将上述的不含期望的贝尔曼期望方程写成矩阵形式,可以看出它是一个线性方程,那么可以直接采用线性代数的方法求解,无需迭代。可能有同学有疑问:明明是才对啊?其实是这样的,是后继状态的值函数,但是它肯定也是由v(1)~v(n)构成的呀,所以可以直接写成上述矩阵形式。那么求解后得到的解是:
下一篇文章是马尔科夫决策过程,是强化学习的最核心内容,请注意查收!
6 总结
本文讲的内容其实可以简单归纳为:
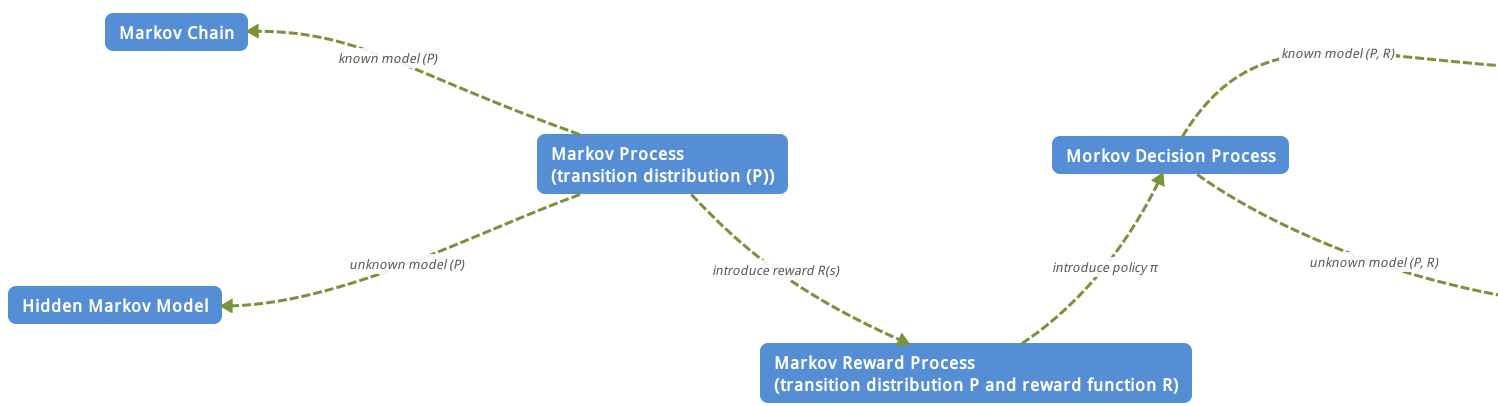
对于某个马尔科夫过程,如果已知模型,那么就是马尔科夫链;如果不知道模型,那么就是隐马尔科夫模型;如果引入了回报,那么就转化为马尔科夫奖赏过程;如果再引入Action,就转化为了马尔科夫决策过程,对于MDP问题,如果已知model(P,R),那么就是planning问题,如果不知道model(P,R),那么就是强化学习问题了。强化学习的方向主要也就是该分支部分。如有疑问,欢迎加群交流678455658。
参考文献
1 David Silvr强化学习课程,b站有视频
