@Team
2020-09-20T15:26:27.000000Z
字数 5250
阅读 4776
CV中的无监督学习方法:MoCo
我是小将
无论是CV还是NLP领域,学习一个好的特征或者表达至关重要。对于NLP,
通过无监督方法学习特征已经取得好大的成功,但是在CV领域,目前主流的方案还是采用ImageNet上的有监督pretrain模型。这是因为NLP任务的输入如words属于一个离散空间,而CV任务的输入图片属于一个高维连续空间。不过,目前的一些CV领域的无监督学习方法也取得了一些较大的进展,这里介绍的MoCo就是一种比较流行的无监督学习方法。
对比学习
无监督学习方法主要用来学习好的特征以用于特定的下游任务,这类方法往往需要建立一个代理任务(pretext task),所谓代理任务指的是这个任务本身并不是学习目的,真正想要的是通过这个任务学习到好的数据特征或者表达。这些代理任务总体可以分成两大类:生成式(generative)和判别式(discriminative)。对于生成式方法,常见的通用自编码器对图像重建或者GAN,这类方法直接操作在pixel空间,计算费时而且对于学习特征往往也不必要。而判别式方法和我们常用的监督学习类似,通过特定的目标函数来训练,但是输入和标签都是来自于无标注数据中,所以判别式方法也可以称为自监督学习( self-supervised learning)。对比学习(contrastive learning)是判别式方法中最流行且成功的方法,其主要思路通过学习区分样本对的特征来学习到好特征。
这里介绍的Moco方法就属于对比学习的范畴,采用代理任务是instance discrimination task(见这篇paper),其主要点是最小化同一个图片的不同view下的差异,这里的不同view是由同一个图片进行不同的数据增强得到。论文中将对比学习看成一个dictionary look-up task,这个dictionary的keys是一系列图片经过一个encoder得到的特征,这个encoder是一个网络记为,对于输入,其编码后的特征为。另外,这里有另外一个encoder网络,记为,它用来产生query的编码,对于输入,其编码后得到(注意的是和可以是同一个网络,也可以不同)。对比学习就是对比query和字典中的keys。这里假定对于一个特定的,这个字典中只有一个key与匹配,记为,又称为positive key,在这里其实和是同一个图片的不同view,而其他key是来自于不同的图片,所以是negative key。那么对比学习的目标函数就是要最大化和与之对应的之间的相似度,而最小化和其他的之间的相似度。这里直接用两个特征向量的点积来衡量相似度,而对比损失函数采用InfoNCE:
这里的是超参数,样本中只有一个正例和K个负例,这个问题可以看成K+1分类问题,label是那个正例,所以损失函数就是基于softmax的交叉熵。
在实现上,对比学习共有两种常用的实现机制:end-to-end和memory bank,如下图所示。end-to-end方式应该是最直观的,无论是encoder 和encoder 均有梯度传递,虽然字典中keys一致性高(都是同参数的encoder产生),但是这种方式字典的大小一般是mini-batch的大小,因为受限于GPU显存。memory bank是对end-to-end的改进,memory bank包含数据集中所有样本编码后特征,这样每个mini-batch的字典从memory bank中随机采样得到,这个过程不计算梯度,这样字典的大小原则上可以很大,甚至和数据集大小一致。由于每个迭代,memory bank会更新mini-batch中的样本,所以采样得到的字典中keys一致性就差,因为可能来自不同训练step,此时encoder参数是不同的。
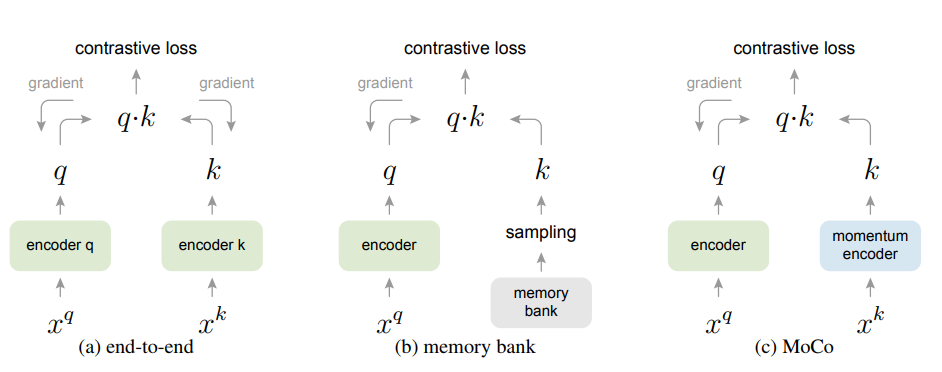
图1 三种对比学习策略比较
Moco
无论是end-to-end还是memory bank都有优缺点,一个最优的方式是:字典的keys一致性更高,而且字典大小足够大,这样才有足够多的负样本以训练出好的encoder。Moco方法就是从这两个方面来进行改进。Moco的核心是将字典看成一个队列queue,队列的大小可以比mini-batchh大,属于超参数。队列是逐步更新的在每次迭代时,当前mini-batch的样本入列,而队列中最老的mini-batch样本出列,这个字典中的keys始终是最新的。
使用队列虽然可以使字典很大,但是与memory bank一样,操作上难以通过BP来更新encoder,一个最简单的方式直接用最新的作为,并且忽略梯度,但是实验中效果较差,这应该和memory bank类似,字典中的keys的一致性较差,因为每次迭代的encoder都更新很快。Moco采用momentum update策略来解决这个问题。假定和的参数分别是和,那么在训练的每次迭代中,通过BP来更新,但是采用momentum update:
这里的是momentum系数,一般取较大的值,论问中取0.999,这意味着更新过程非常平滑,这样字典的keys一致性就更高。
Moco的核心就是维护一个动态的queue作为字典,然后通过momentum update方式更新字典keys编码网络,其PyTorch伪代码如下所示:
# f_q, f_k: encoder networks for query and key# queue: dictionary as a queue of K keys (CxK)# m: momentum# t: temperaturef_k.params = f_q.params # initializefor x in loader: # load a minibatch x with N samplesx_q = aug(x) # a randomly augmented versionx_k = aug(x) # another randomly augmented versionq = f_q.forward(x_q) # queries: NxCk = f_k.forward(x_k) # keys: NxCk = k.detach() # no gradient to keys# positive logits: Nx1l_pos = bmm(q.view(N,1,C), k.view(N,C,1))# negative logits: NxKl_neg = mm(q.view(N,C), queue.view(C,K))# logits: Nx(1+K)logits = cat([l_pos, l_neg], dim=1)# contrastive loss, Eqn.(1)labels = zeros(N) # positives are the 0-th, so GT label is 0loss = CrossEntropyLoss(logits/t, labels)# SGD update: query networkloss.backward()update(f_q.params)# momentum update: key networkf_k.params = m*f_k.params+(1-m)*f_q.params# update dictionaryenqueue(queue, k) # enqueue the current minibatchdequeue(queue) # dequeue the earliest minibatch# bmm: batch matrix multiplication; mm: matrix multiplication; cat: concatenation
对于同一张图片,要通过不同的数据增强来产生和,Moco采用的数据增强方式如下所示:
augmentation = [transforms.RandomResizedCrop(224, scale=(0.2, 1.)),transforms.RandomGrayscale(p=0.2),transforms.ColorJitter(0.4, 0.4, 0.4, 0.4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize]
论文中采用ResNet作为encoder,不过网络的最后一个FC层输出作为特征向量,其维度大小为128,这个向量经过L2-norm进行归一化作为query和key。由于ResNet网络存在BN层,但是直接采用BN层会恶化结果,因为BN层中的mean和variance可能会泄露一些信息导致模型训练过程走捷径,虽然loss很低,但是得到的特征却并不好。Moco的解决方案是shuffling BN和多卡训练,具体操作如下:
# compute query features,query计算过程不做改动q = self.encoder_q(im_q) # queries: NxCq = nn.functional.normalize(q, dim=1)# key的计算要先shuffle 样本,这样同一张上query和key的BN层采用不同的样本计算得到,避免信息泄露with torch.no_grads():# shuffle for making use of BNim_k, idx_unshuffle = self._batch_shuffle_ddp(im_k)k = self.encoder_k(im_k) # keys: NxCk = nn.functional.normalize(k, dim=1)# undo shufflek = self._batch_unshuffle_ddp(k, idx_unshuffle)
对于这个问题,SimCLR采用的global BN策略,就是聚合所有卡上的BN层中的mean和variance,其它策略是将BN替换成layer Norm。
衡量无监督方法得到的特征质量常用的方法是Linear Classification Protocol,简单来说,就是将encoder得到的特征冻结,后面加一个线性分类器来进行监督训练,在ImageNet数据集上,Moco比end-to-end和memory bank方法取得更好的效果。无监督方法一个最重要应用是将训练的特征迁移到其它下游任务,如检测和分割,此时无监督方法得到的encoder就作为初始化网络来代替ImageNet数据集上监督训练网络,实验证明Moco确实可以取得更好的效果。
借鉴SimCLR方法的优秀策略,Moco升级为MocoV2,首先采用更heavy的数据增强,数据增强在对比学习中至关重要,MocoV2采用的数据增强方式如下所示:
augmentation = [transforms.RandomResizedCrop(224, scale=(0.2, 1.)),transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1) # not strengthened], p=0.8),transforms.RandomGrayscale(p=0.2),transforms.RandomApply([moco.loader.GaussianBlur([.1, 2.])], p=0.5),transforms.RandomHorizontalFlip(),transforms.ToTensor(),normalize]
另外是将Moco中的fc head替换成一个2层的MLP head (隐含层为 2048-d,采用ReLU),这个只是为了提升训练过程,linear classification和迁移时不会使用MLP。其它的改进策略是采用cosine learning rate schedule。这些策略使得MocoV2效果进一步提升: