@Team
2019-04-08T06:57:39.000000Z
字数 7027
阅读 2825
大业14年
石文华
将图像中每个像素分配到某个对象类别,相关模型要具有像素级的密集预测能力
1、FCN
改编当前的分类网络:AlexNet、VGG、GoogLeNet到全卷积网络和通过微调传递它们学习的特征表达能力到分割任务中。然后定义了一个跳跃式的架构,结合来自深、粗层的语义信息和来自浅、细层的表征信息来产生准确和精细的分割。
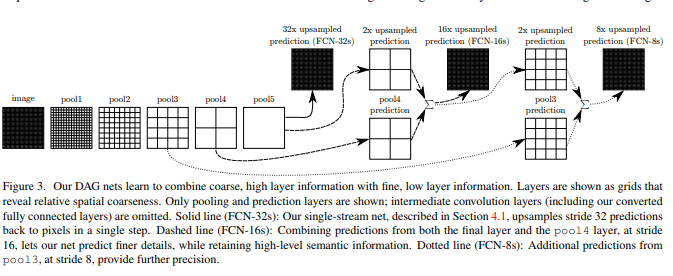
上图可以看出该算法采用了“融合层”策略,将高层特征和低层特征进行融合来提高分割性能,分别采用了3种不同的结构,第一种是32x upsampled prediction,第二种是16x upsampled prediction,第三种是8x upsampled prediction。
过程是这样的:
1、32x upsampled prediction
原图经过不断的卷积和池化,得到pool5层的特征(比原图缩小了32倍),将pool5通过32倍的上采样(反向卷积)得到最后结果。但是pool5层的特征属于高层抽象特征,采样后得到的结果不够精细。
2、16x upsampled prediction
将pool5的结果进行2倍上采样,与pool4相加,作为“融合”,然后将“融合”结果进行16倍的上采样(反向卷积)得到最后结果(注:融合是指对应位置像素值相加,后来的u-net则直接是通道上拼接)。
3、8x upsampled prediction
将pool5的结果进行2倍上采样,与pool4相加,作为“融合”,然后将“融合”结果进行2倍的上采样,再与pool3的结果进行“融合”,之后进行八倍的上采样。
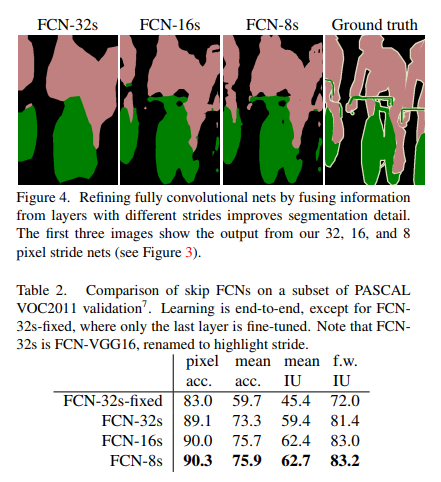
三种结构实验结果表明,将高层特征与低层特征的融合能够明显提高像素点的分类效果,如下图所示:
2、SegNet
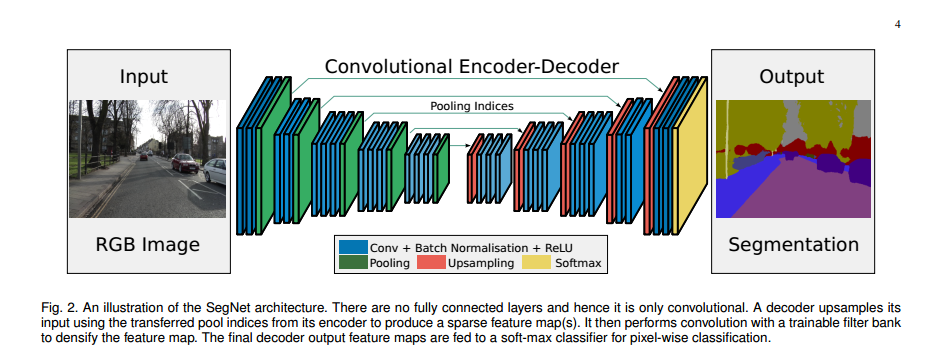
上图可以看到segNet没有全连接的层。SegNet和FCN思路十分相似,不同之处在于解码器使用从编码器传输的最大池化索引(位置)对其输入进行非线性上采样,从而使得上采样不需要学习,生成稀疏特征映射。然后,使用可训练的卷积核进行卷积操作,生成密集的特征图。最后的解码器输出特征映射被送入soft-max分类器进行像素级分类。
编码和解码过程
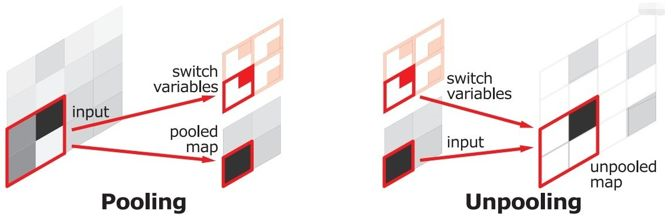
SegNet在编码阶段进行pooling的时候会保留保存通过max选出的权值在2x2 filter中的相对位置,用于之后在解码器中使用那些存储的索引来对相应特征图进行去池化操作,如下图所示:
3、U-net
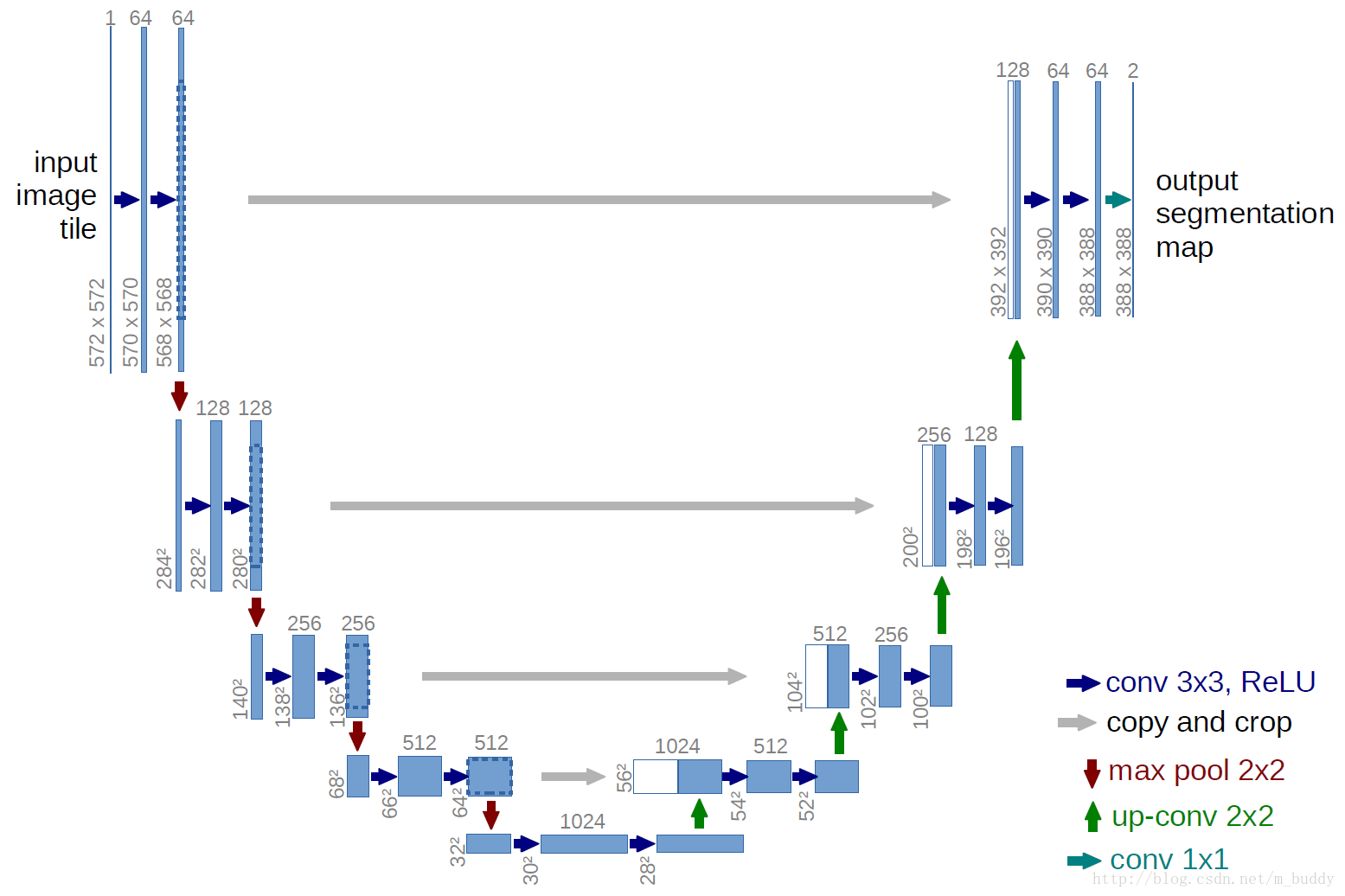
1、下采样(Conv+maxpooling),即收缩路径,分辨率减小,通道数增加,位置信息变少,语义信息增强。因此,较浅的高分辨率层(位置信息强的层)的特征可以用来解决像素定位的问题,较深的层(语义信息强的层)的特征可用来解决像素分类的问题。
2、上采样(反卷积),即扩张路径,增加输出的分辨率。上采样之后需要增加下采样中的高分辨率特征(high resolution features),采用的是叠加(concatenate操作)的做法,而不是FCN中的横向连接(加)操作。这样综合的特征将使得结果更加精确。
3、扩张路径基本对称于收缩路径,只是网络在上采样部分依然有大量的特征通道(feature channels),只需要每次使用反卷积的时候都将特征通道数量减半,特征图大小加倍。这样能将特征信息向更高的分辨率层(higher resolution layers)传播。
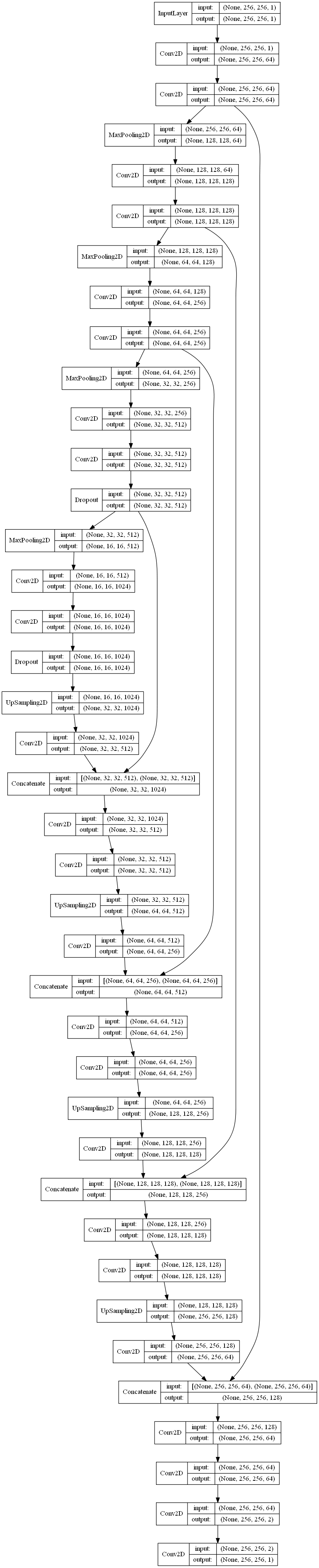
"""Spyder EditorThis is a temporary script file."""import numpy as npimport osimport skimage.io as iofrom keras.models import Modelfrom keras.layers import Conv2D,Input,MaxPooling2D,Dropout,concatenate,UpSampling2Dfrom keras.optimizers import *from keras.callbacks import ModelCheckpoint,LearningRateSchedulerfrom keras import backend as kerasinput_shape=(256,256,1)#定义输入inputs=Input(input_shape)conv1=Conv2D(64,3,activation='relu',padding='same',kernel_initializer='he_normal')(inputs)conv1=Conv2D(64,3,activation='relu',padding='same',kernel_initializer='he_normal')(conv1)pool1=MaxPooling2D(pool_size=(2,2))(conv1)conv2=Conv2D(128,3,activation='relu',padding='same',kernel_initializer = 'he_normal')(pool1)conv2=Conv2D(128,3,activation='relu',padding='same',kernel_initializer='he_normal')(conv2)pool2=MaxPooling2D(pool_size=(2,2))(conv2)conv3=Conv2D(256,3,activation='relu',padding='same',kernel_initializer='he_normal')(pool2)conv3=Conv2D(256,3,activation='relu',padding='same',kernel_initializer='he_normal')(conv3)pool3=MaxPooling2D(pool_size=(2,2))(conv3)conv4=Conv2D(512,3,activation='relu',padding='same',kernel_initializer='he_normal')(pool3)conv4=Conv2D(512,3,activation='relu',padding='same',kernel_initializer='he_normal')(conv4)drop4=Dropout(0.5)(conv4)pool4=MaxPooling2D(pool_size=(2,2))(drop4)conv5=Conv2D(1024,3,activation='relu',padding='same',kernel_initializer='he_normal')(pool4)conv5=Conv2D(1024,3,activation='relu',padding='same',kernel_initializer='he_normal')(conv5)drop5=Dropout(0.5)(conv5)up6=Conv2D(512,2,activation='relu',padding='same',kernel_initializer = 'he_normal')(UpSampling2D(size=(2,2))(drop5))merge6=concatenate([drop4,up6],axis=3)conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6)conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6)up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))merge7 = concatenate([conv3,up7], axis = 3)conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7)conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7)up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))merge8 = concatenate([conv2,up8], axis = 3)conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8)conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8)up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))merge9 = concatenate([conv1,up9], axis = 3)conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9)conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)conv10 = Conv2D(1, 1, activation = 'sigmoid')(conv9)model = Model(input = inputs, output = conv10)model.summary()
网络结构图:
4、Fully Convolutional DenseNet
1、前言:
DenseNet 是一种具有密集连接的卷积神经网络,即任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。这种密集连接通过将特征在channel上的连接来实现特征重用(feature reuse),这让DenseNet在参数和计算成本更少的情形下实现比ResNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖。
2、密集连接机制:
即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入,在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起,并作为下一层的输入。对于一个L层的网络,DenseNet共包含个L(L+1)/2个连接。DenseNet是直接concat来自不同层的特征图来实现特征重用的。
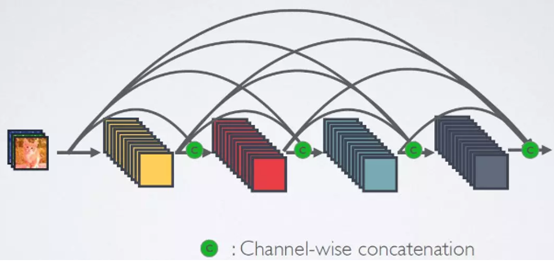
3、网络组成架构
由于密集连接的时候要求特征图大小是一致的,为了使随着网络深度的加深特征图大小降低,也就是使用pooling,使用DenseBlock和Transition两种模块来组合。DenseBlock模块里面层与层之间采用密集连接方式,Transition连接两个相邻的DenseBlock,使用Pooling降低分辨率。看图:
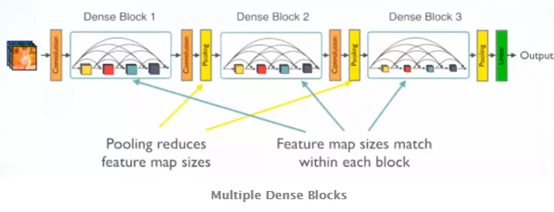
4、DenseBlock和Transition的细节
(1)非线性组合:
DenseBlock中是非线性组合函数,比如BN+ReLU+3x3 Conv结构,而且各个层的特征图大小是一致的,这样才能保证在channel维度上连接。
(2)增长率(Growth rate):
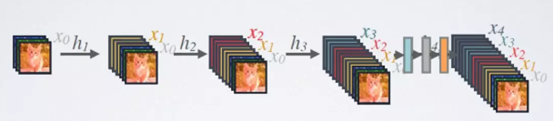
由于网络中的每一层都直接与其前面层相连,实现特征的重复利用,因此为了降低冗余性,使用了一个超参数K,用于控制每一层输出的feature maps的厚度,一般情况下使用较小的k(比如12),目的是为了把网络的每一层设计得特别「窄」,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图)。假定输入层的特征图的channel数为3,那么L层输入的channel数为3+k(L-1),因此随着层数增加,尽管k设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有k个特征是自己独有的。如下图所示,使用K个卷积核对(x0,x0,x2,x3)组成的特征图进行非线性变换得到通道数为K的x4,再通过x4和前面每个阶段的特征图拼接起来得到(x0,x1,x2,x3,x4)
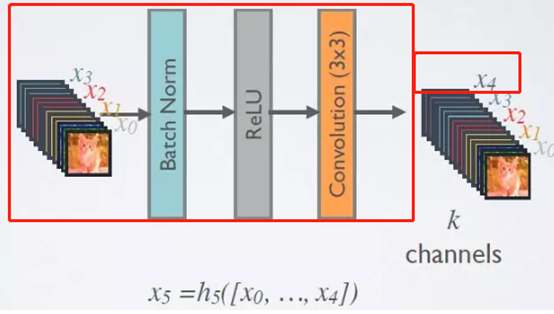
(3)bottleneck层:
虽然k使用较小的值,但是通过多个层不断的密集连接,最终特征图的通道数还是会比较大而造成网络计算量增大。因此在非线性变换中引入1*1的卷积来进行降维。引入1*1之后的非线性模块变为:BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构,看图:
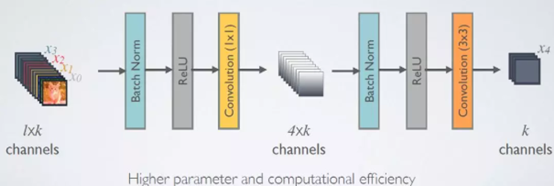
(4)Transition层:
Transition层也是非线性变换函数组成的模块,组合方式为:BN+ReLU+1x1 Conv+2x2 AvgPooling,既然是非线性变换组合,在这个组合中加入pooling就可以起到降低特征图大小的作用,那么它也可以通过控制输入的卷积核个数,起到进一步压缩特征图的作用,从而进一步优化模型。假设一个Denseblock中包含m个特征图,那么我们使其输出连接的transition layer层生成⌊θm⌋个输出特征图.当这里的θ取值为(0,1]时,起到压缩的作用,因此可以叫做压缩系数, 当θ=1时,transition layer将保留原feature维度不变。
5、DenseNet 的优点
(1)省参数, 在 ImageNet 分类数据集上达到同样的准确率,DenseNet 所需的参数量不到 ResNet 的一半
(2)省计算。达到与 ResNet 相当的精度,DenseNet 所需的计算量也只有 ResNet 的一半左右.
(3)抗过拟合, 对于 DenseNet 抗过拟合的原因有一个比较直观的解释:神经网络每一层提取的特征都相当于对输入数据的一个非线性变换,而随着深度的增加,变换的复杂度也逐渐增加(更多非线性函数的复合)。相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高)的特征,DenseNet 可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的具有更好泛化性能的决策函数。
(4)支持特征重用,强化特征传播,有效解决梯度消失问题。
6、FC-DenseNet语意分割
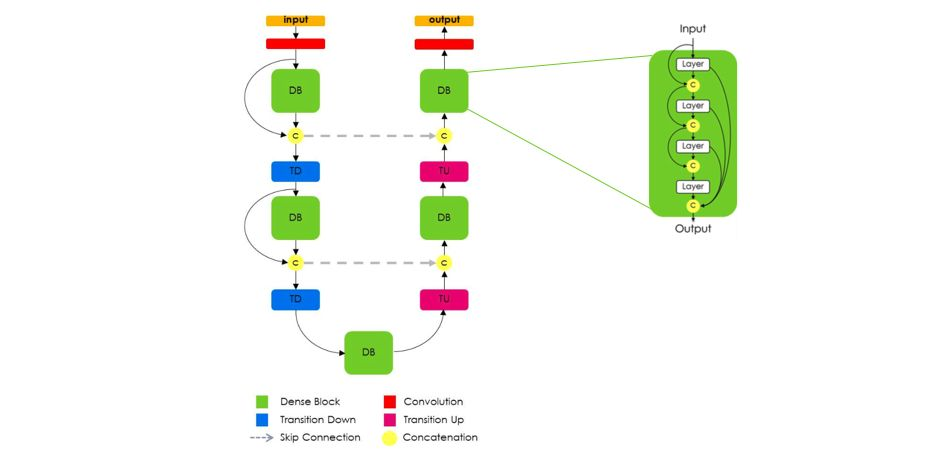
由上图可以看出,全卷积 DenseNet 使用 DenseNet作为它的基础编码器,并且也以类似于 U-Net的方式,在每一层级上将编码器和解码器进行拼接。在解码阶段,将卷积操作替换为dense模块,并由transition up模块完成升采样,transition up模块使用转置卷积升采样以前的特征图,然后将升采样后的特征图连接到来自下采样过程中的dense模块的跨层连接。需要注意的是,为了解决特征图数目的线性增长问题,dense模块的输入并不连接到它的输出,转置卷积仅对最后一个dense block的特征图使用,因为最后一个dense模块包含了前面所有相同分辨率dense模块信息之和。同时引入跳层解决之前dense block特征损失的问题。网络结构如下图所示:

7、参考:
https://www.jianshu.com/p/8a117f639eef
https://www.sohu.com/a/161639222_114877
https://mp.weixin.qq.com/s/xhvyK26zxWNhB8XcKYZSAA
https://mp.weixin.qq.com/s/6ZDkwxm3WZDZ_jN5WEdvrQ
https://blog.csdn.net/cv_family_z/article/details/77506526
5、 DeepLab系列
参考:
https://arxiv.org/pdf/1411.4038.pdf
https://www.jianshu.com/p/24860a36cc05
