@Team
2020-01-06T03:57:00.000000Z
字数 2559
阅读 2491
轻量级语义分割网络:ENet
石文华
一、介绍
为了减少浮点运算的次数和内存占用以及推理时间,提出了Enet,采用编码器-解码器架构,相比SegNet,速度提升18倍,计算量减少75倍,参数量减少79倍。并且具有相当的精度,它是一个实时的语义分割网络结构。ENet分割图像的示例如下图所示:

二、网络结构
网络结构如下表所示:
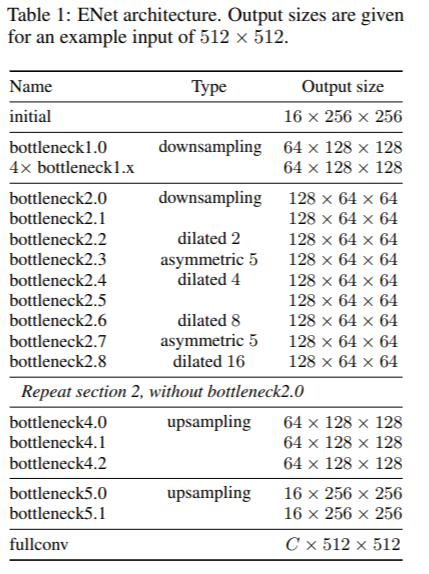
网络的输入大小是512x512,有两种网络模块,分别是initial和bottleneck,如下图所示:
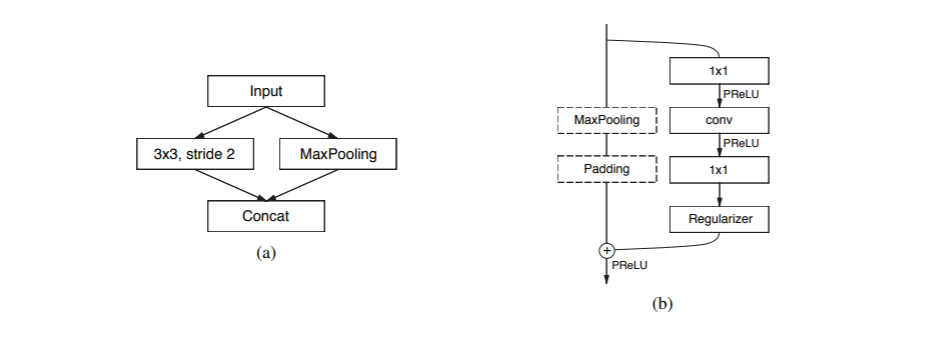
图(a)是initial模块,MaxPooling为步长2的2x2的filter,卷积有13个filter,Concat后的特征映射总计为16个,起到特征提取、压缩输入图像”体积”、除去图像中的视觉冗余信息的作用。图(b)是bottleneck 模块,采用残差连接的思想,包含三个卷积层:一个1 x 1的降维卷积,一个主卷积层,一个1 x 1扩张卷积,bn和PReLU放在中间。对于下采样的bottleneck模块,主分支添加最大池层,第一个1×1卷积被替换为步长为2的2×2卷积,中间的主卷积有三种可能的选择:Conv普通卷积,asymmetric分解卷积(如分解成 5 × 1 和 1 × 5 ),Dilated空洞卷积。对于正则化方式,使用了Spatial Dropout,在bottleneck 2.0之前p=0.01,之后p=0.1。由网络结构表格可以看到,初始阶段包含一个块,接着是阶段1由5个bottleneck 组成,而阶段2和阶段3具有相同的结构,阶段3在开始时没有对输入进行降采样。阶段1到3是编码器。阶段4和5属于解码器。
细节:
(1)为了减少内核调用和内存操作,没有在任何投影中使用bias,因为cuDNN会使用单独的内核进行卷积和bias相加。这种方式对准确性没有任何影响。
(2)在每个卷积层和随后的非线性之间,都使用了bn进行处理。
(3)在解码器中,用max unpooling代替max pooling,用无bias的spatial convolution代替padding。
(4)在最后一个上采样模块中,没有使用池化索引,因为初始块在输入帧的3个通道上操作,而最终输出具有C特征映射(对象类的数量)。
(5)出于性能原因,只在网络的最后一个模块设置一个完全卷积,仅这一项就占用了解码器处理时间的很大一部分。
三、设计选择
1、Feature map resolution
语义分割中的图像降采样有两个主要缺点:一是降低特征图的分辨率意味着丢失精确边缘形状等空间信息;二是全像素分割要求输出与输入具有相同的分辨率。这意味着进行了多少次下采样将需要同样次数的上采样,这将增加模型尺寸和计算成本。第一个问题在FCN中通过编码器生成的特征映射之间的add得到了解决,在SegNet中通过保存在max pooling层中选择的元素的索引,并使用它们在解码器中生成稀疏的上采样映射得到了解决。作者遵循SegNet方法,因为它减少了对内存需求。尽管如此,还是发现下采样会损害准确性,需要尽可能的限制下采样。当然,下采样能够扩大感受野,学习到更多的上下文特征用于逐像素的分类。
2、Early downsampling
高分辨率的输入会耗费大量计算资源,ENet的初始化模块会大大减少输入图像的大小,并且只使用了少量的feature maps,初始化模块充当良好的特性提取器,并且只对网络稍后部分的输入进行预处理。
3、Decoder size
ENet的Encoder和Decoder不对称,由一个较大的Encoder和一个较小的Decoder组成,作者认为Encoder和分类模型相似,主要进行特征信息的处理和过滤,而decoder主要是对encoder的输出做上采样,对细节做细微调。
4、Nonlinear operations
作者发现ENet上使用ReLU却降低了精度。相反,删除网络初始层中的大多数ReLU可以改善结果。用PReLU替换了网络中的所有ReLU,对每个特征映射PReLU有一个附加参数,目的是学习非线性的负斜率。
5、Information-preserving dimensionality changes
选择在使用步长2的卷积的同时并行执行池化操作,并将得到的特征图拼接(concatenate)起来。这种技术可以将初始块的推理时间提高10倍。此外,在原始ResNet架构中发现了一个问题。下采样时,卷积分支中的第一个1×1卷积在两个维度上以2的步长滑动,直接丢弃了75%的输入。而ENet将卷积核的大小增加到了2×2,这样可以让整个输入都参与下采样,从而提高信息流和精度。虽然这使得这些层的计算成本增加了4倍,但是在ENET中这些层的数量很少,开销并不明显。
6、Factorizing filters
卷积权重存在大量冗余,并且每个n x n卷积可以分解成一个n x 1滤波和一个1 x n滤波,称为非对称卷积。本文采用n = 5的非对称卷积,它的操作相当于一个3 x 3的卷积,增加了模块的学习能力并增加了感受野,更重要的是,在瓶颈模块中使用的一系列操作(投影、卷积、投影)可以被视为将一个大卷积层分解为一系列更小和更简单的操作,即其低阶近似。这样的因子分解可以极大地减少参数的数量,从而减少冗余。此外,由于在层之间插入的非线性操作,特征也变的更丰富了。
7、Dilated convolutions
大的感受野对分割任务也是非常重要的,可以参考更多的上下文特征对像素进行分类,为了避免对特征图进行过度的下采样,使用空洞卷积,在最小分辨率下运行的阶段中,几个瓶颈模块内的主要卷积层都使用了空洞卷积。在没有增加额外计算开销的情况下,便提高了准确度。当作者将空洞卷积与其他bottleneck(常规和非对称卷积)交织时,即不是按顺序排列它们,获得了最佳效果。
8、Regularization
为了防止过拟合,把Spatial Dropout放在卷积分支的末端,就在加法之前。
四、实验
1、性能比较
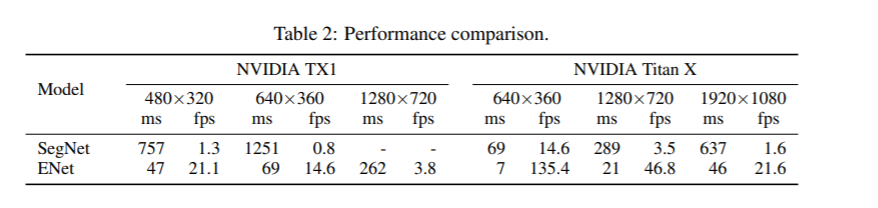
2、硬件要求比较
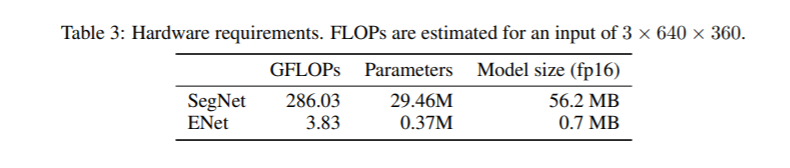
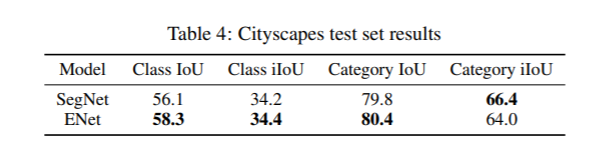
3、Cityscapes测试集上的结果比较
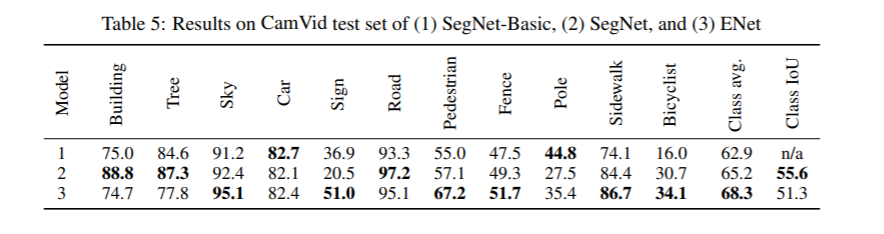
4、CamVid数据集上不同模型的比较
代码地址
网络结构部分的代码详见:
https://github.com/cswhshi/segmentation/blob/master/ENet.py
欢迎大家指正和star~
