@huanghaian
2020-02-17T12:28:32.000000Z
字数 4556
阅读 1539
分类
黄海安
仓库集合
1 https://github.com/donnyyou/pytorch-image-models
细粒度分类
The Devil is in the Channels
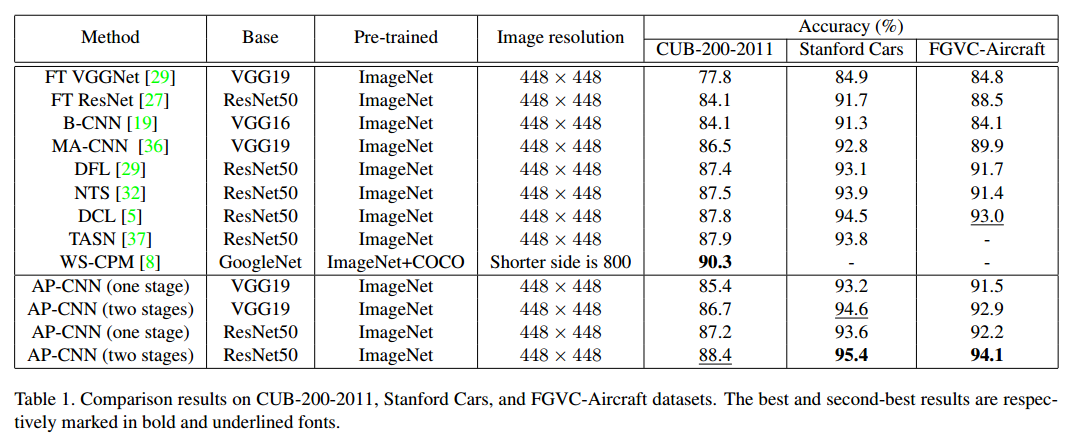
题目:The Devil is in the Channels: Mutual-Channel Loss
for Fine-Grained Image Classification-arxiv 2002.04264 代码开源,可以试下,无缝嵌入。
本文就是提出一个loss,用于自动学习可判别区域和特征。作者指出仅仅需要一个loss就可以实现细粒度分类,而不需要以前那么复杂的网络设计。核心思想如下:
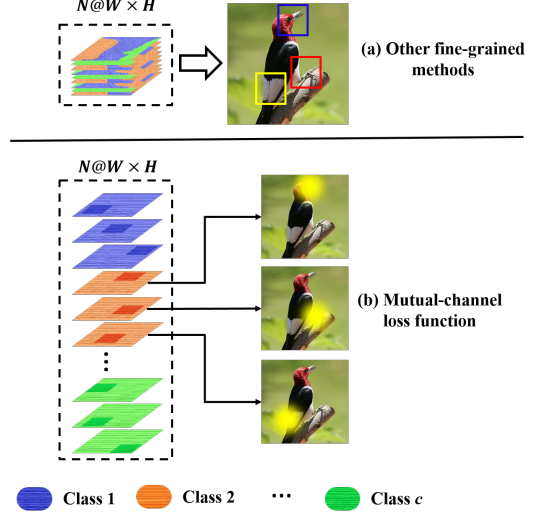
本文Loss的目的是:不同的通道自动学习不同的可判别区域,并且自动按照类别分组。这里面包括两个:(1) 在同一个组内部的特征,每个通道都是学习可判别特征;(2) 在同一个组内,每个通道特征都是互斥的,即学习不同的可判别特征,而不是每个通道都只学习最明显特征。
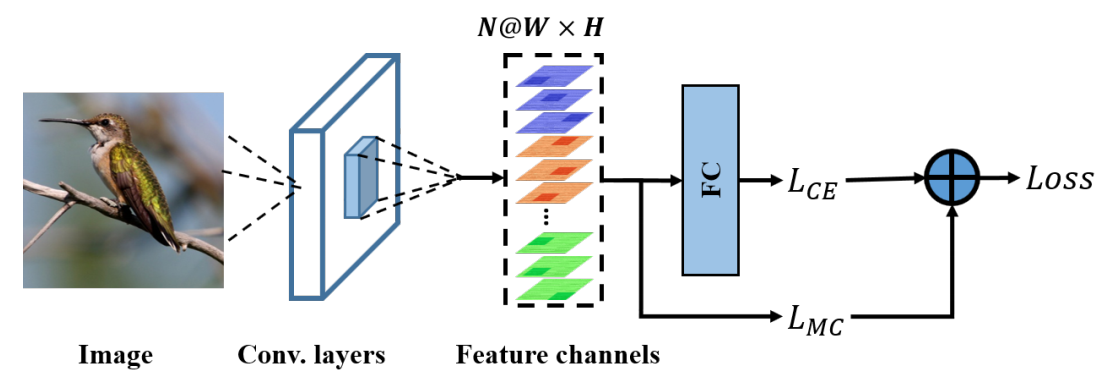
可以看出就是多了一个loss,和pc很像。
其网络如下:
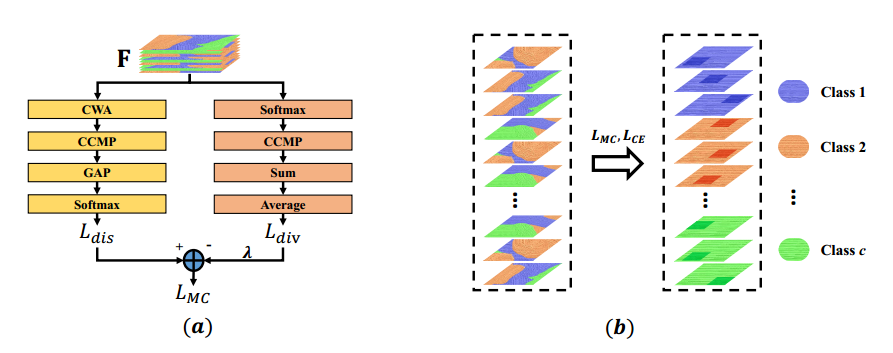
希望学习出右边图示的特征,具体做法是左边图示。整个loss包括两个并行部分,dis是指可判别组件。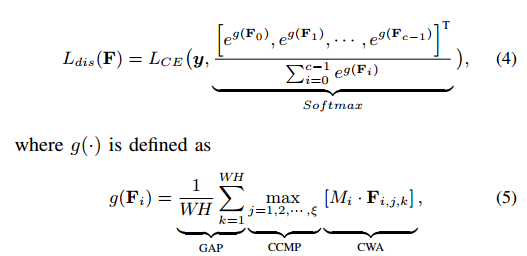
注意所有的操作都是对于组来说的,组的定义是提前设置好的,假设输出特征图通道是N,那么N=c*a,c是类别数,a是预定义的每组采用多少个通道来学习可判别特征。
CWA( Channel-Wise Attention) 是对组内的特征采用随机mask,覆盖掉一些特征,有助于学习可判别区域,这是常规做法。
CCMP(the Cross-Channel Max Pooling),用于计算the maximum response of each element across each feature channel ,其实就是对每个组内特征进行max pool操作,提取组内最有判别力的特征。
可以看出dis模块没有对组内的特征进行约束,故提出了div组件,用于确保组内的每个可判别特征都是不一样的,最大程度去掉冗余信息。
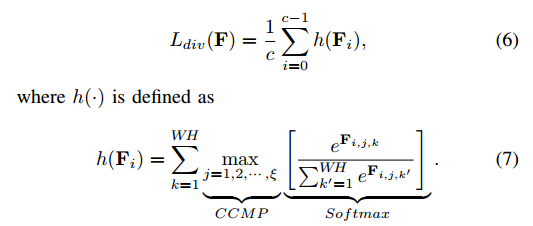
可视化解释如下:
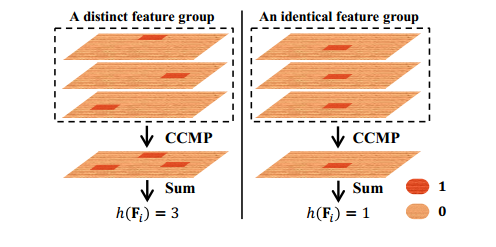
我们的目的就是h越大越好,故loss需要取负号。
总的Loss:
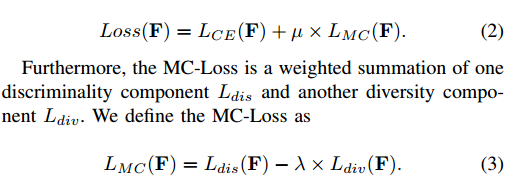
可视化:

Weakly Supervised Attention Pyramid Convolutional Neural Network
arxiv-2002.03353 AP-CNN
http://dwz1.cc/ci8so8a
本文思想和ws-dan差不多,看起来性能应该会好一点。也是包括两次前向,第一个是全图的前向,第二个是特征图上小图的前向,然后结果取平均。但是代码更加复杂,速度应该也会慢很多。
本文出发点:integrating low-level information (e.g., color, edge junctions, texture patterns), performance can be improved with enhanced feature representation and accurately located discriminative regions
核心图示如下:
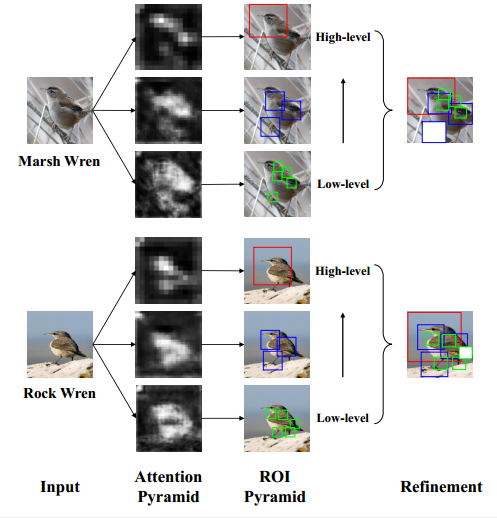
低级和高级特征对细粒度分类都很重要,核心思想就是利用高低级别的预测特征得到bbox,然后对特征图进行处理,例如裁剪和缩放等,然后再进行分类即可。
详细网络结构如下:
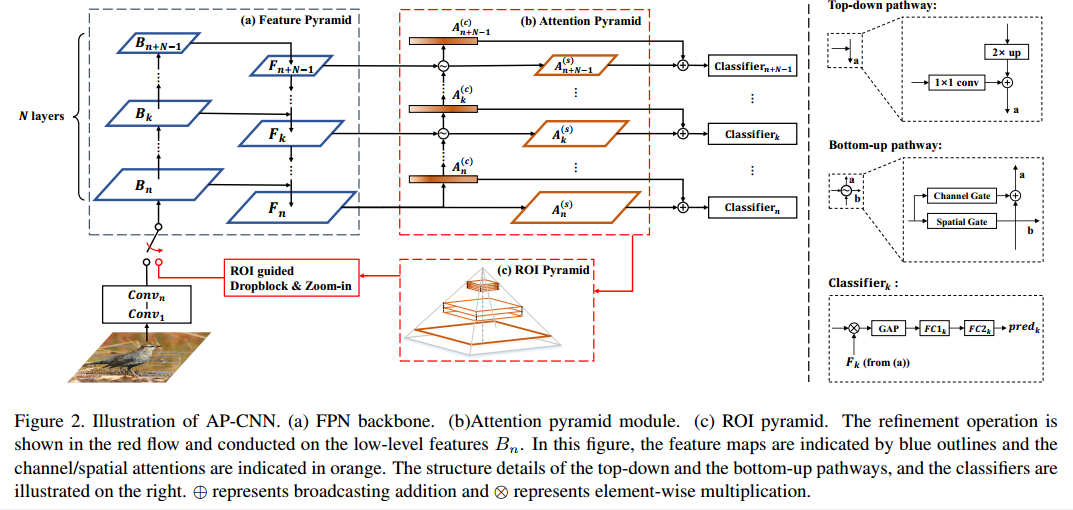
(1) 骨架
骨架网络采用resnet50和vgg19,在resnet的F2 F3 F4三个阶段引出构成FPN结构。
n, c, img_h, img_w = inputs.size()
x = self.conv1(inputs)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x1 = self.layer1(x)
x2 = self.layer2(x1)
x3 = self.layer3(x2)
x4 = self.layer4(x3)
# stage I
f3, f4, f5 = self.fpn([x2, x3, x4])
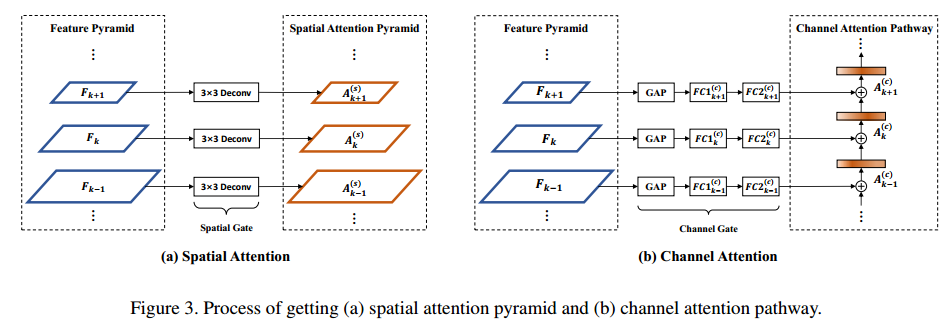
(2) Attention Pyramid
对fpn输出的每个level进行attention操作,构造Attention Pyramid。其实涉及到的Bottom-up pathway,引入了Channel Gate和Spatial Gate,对于每个层级,输出spatial map(用于后续roi操作)和加乘后图(用于分类)
F3, F4, F5 = inputs
A3_spatial = self.A3_1(F3)
A3_channel = self.A3_2(F3)
A3 = A3_spatial*F3 + A3_channel*F3
A4_spatial = self.A4_1(F4)
A4_channel = self.A4_2(F4)
A4_channel = (A4_channel + A3_channel) / 2
A4 = A4_spatial*F4 + A4_channel*F4
A5_spatial = self.A5_1(F5)
A5_channel = self.A5_2(F5)
A5_channel = (A5_channel + A4_channel) / 2
A5 = A5_spatial*F5 + A5_channel*F5
return [A3, A4, A5, A3_spatial, A4_spatial, A5_spatial]
细节如下:
对上述特征连接分类器就构成了第一阶段
f3_att, f4_att, f5_att, a3, a4, a5 = self.apn([f3, f4, f5])
# feature concat
f_concate = self.Concate(f3, f4, f5)
out_concate = self.cls_concate(f_concate)
loss_concate = self.criterion(out_concate, targets)
out3 = self.cls3(f3_att)
out4 = self.cls4(f4_att)
out5 = self.cls5(f5_att)
loss3 = self.criterion(out3, targets)
loss4 = self.criterion(out4, targets)
loss5 = self.criterion(out5, targets)
loss = loss3 + loss4 + loss5 + loss_concate
out = (out3 + out4 + out5 + out_concate) / 4
_, predicted = torch.max(out.data, 1)
correct = predicted.eq(targets.data).cpu().sum().item()
(3)ROI Pyramid
对于第二阶段操作,首先是基于语义特征得到bbox,采用了RPN的做法,对于每个level,基于感受野设计了一个scale和比例,也就是说只有一个anchor,大小分别是64 128 256.其实就是anchor-free操作,对每一个点基于score,大于阈值的就是需要的bbox,然后采用nms操作的bbox,最后tok,得到需要的指定个数bbox,本文设定为低层5个,中间3个,高层1个。
# roi pyramid
roi_3, roi_score_3 = self.get_att_roi(a3, 2 ** 3, 64, img_h, img_w, iou_thred=0.05, topk=5)
roi_4, roi_score_4 = self.get_att_roi(a4, 2 ** 4, 128, img_h, img_w, iou_thred=0.05, topk=3)
roi_5, roi_score_5 = self.get_att_roi(a5, 2 ** 5, 256, img_h, img_w, iou_thred=0.05, topk=1)
roi_list = [roi_3, roi_4, roi_5]
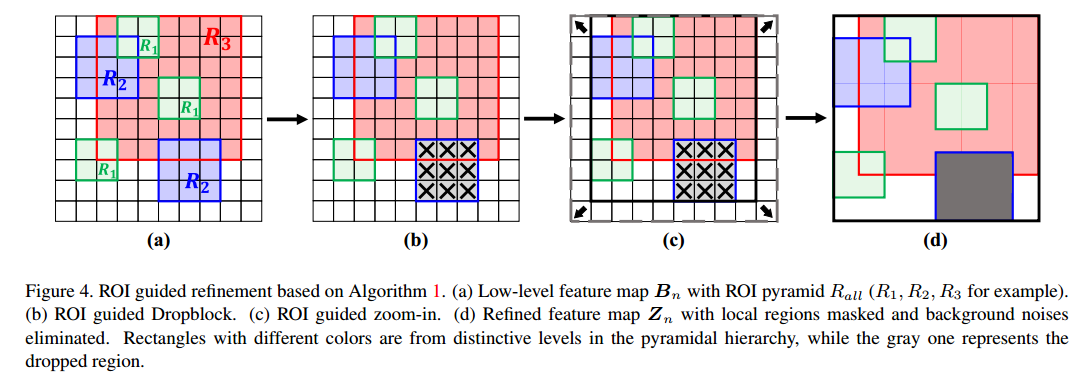
(4) ROI Guided Dropblock 和ROI Guided Zoom-in
得到9个bbox后作用于f2的特征图上,相当于裁剪原图特征。在裁剪特征的同时进行了一定概率的dropblock和zoom-in操作,目的是覆盖掉一些可判别区域以及出除去背景干扰。
x2_crop_resize, _ = self.get_roi_crop_feat(x2, roi_list, 2 ** 3)
(5) 第二阶段
# 其实就是再执行一遍以前代码就可以了
x3_c rop_resize = self.layer3(x2_crop_resize)
x4_crop_resize = self.layer4(x3_crop_resize)
f3_crop_resize, f4_crop_resize, f5_crop_resize = self.fpn([x2_crop_resize, x3_crop_resize, x4_crop_resize])
f3_att_crop_resize, f4_att_crop_resize, f5_att_crop_resize, a3_crop_resize, a4_crop_resize, a5_crop_resize = self.apn([f3_crop_resize, f4_crop_resize, f5_crop_resize])
# feature concat
f_concate_crop_resize = self.Concate(f3_crop_resize, f4_crop_resize, f5_crop_resize)
out_concate_crop_resize = self.cls_concate(f_concate_crop_resize)
loss_concate_crop_resize = self.criterion(out_concate_crop_resize, targets)
out3_crop_resize = self.cls3(f3_att_crop_resize)
out4_crop_resize = self.cls4(f4_att_crop_resize)
out5_crop_resize = self.cls5(f5_att_crop_resize)
loss3_crop_resize = self.criterion(out3_crop_resize, targets)
loss4_crop_resize = self.criterion(out4_crop_resize, targets)
loss5_crop_resize = self.criterion(out5_crop_resize, targets)
loss_crop_resize = loss3_crop_resize + loss4_crop_resize + loss5_crop_resize + loss_concate_crop_resize
out_crop_resize = (out3_crop_resize + out4_crop_resize + out5_crop_resize + out_concate_crop_resize) / 4
_, predicted_crop_resize = torch.max(out_crop_resize.data, 1)
correct_crop_resize = predicted_crop_resize.eq(targets.data).cpu().sum().item()
可以看出,思想和ws-dan其实非常相似,只是更加复杂一点。