@huanghaian
2020-07-06T09:29:16.000000Z
字数 3105
阅读 1497
dynamic rcnn(eccv2020)及mmdectection代码分析
目标检测
论文地址:Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training
arxiv地址:https://arxiv.org/abs/2004.06002
github:
1. mask-rcnn benchmark: https://github.com/hkzhang95/DynamicRCNN
2. mmdetection: https://github.com/open-mmlab/mmdetection/tree/master/configs/dynamic_rcnn
0 摘要
本文是对faster rcnn的rcnn部分的训练过程进行动态分析,提出了the fixed label assignment strategy 和 动态regression loss function。分析过程很有道理,或许可以在其他目标检测网络中应用,还是蛮有意义的。
核心思想就是:随着训练进行,不断自适应增加rcnn正样本阈值,并且针对回归分支预测bbox的方差减少特点自适应修改SmoothL1 Loss参数,达到类似focal效果。通过这两个自适应操作可以进一步提高精度。整个算法过程实现非常简单,也非常好理解。非常像cascade rcnn训练过程,只不过cascade rcnn是通过多个head,而本文压缩为一个head。
本文算法仅仅影响训练过程,对测试过程没有任何影响
但是好像不太好应用于one-stage中,因为这里的动态过程只能针对rcnn这一级别,因为其预测anchor一直在变,后面才能算动态iou,如果是one-stage,由于anchor是固定的,其分配机制只能是固定的。除非是anchor-free的做法。关于这个推广应用还需要仔细思考。也就是说和ATSS还是有很大区别的,ATSS只是分配机制是基于动态iou的,但是这个动态也是基于anchor和gt的,训练过程中是不会改变的。本文和casde rcnn非常相似,但是做法更加优雅。
1 训练过程分析
rcnn的核心超参主要是正样本iou阈值,一般都是0.5,但是这个参数如果修改会如何:
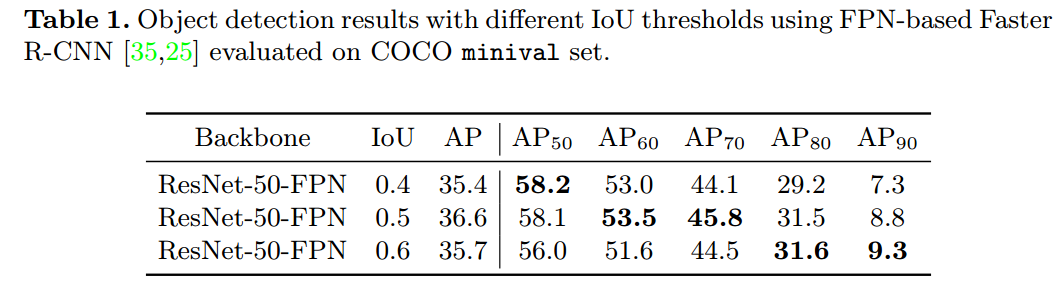
可以看出不同的固定阈值设置,AP是不一样的。并且这个现象和cascade rcnn提到的现象相同,特定的iou阈值对于分布相同的roi增益最大,其余增益比较少。也就是说如果实际项目倾向于无漏报,则iou阈值可以适当降低,反之则可以提高iou阈值。对训练过程进行可视化如下所示:
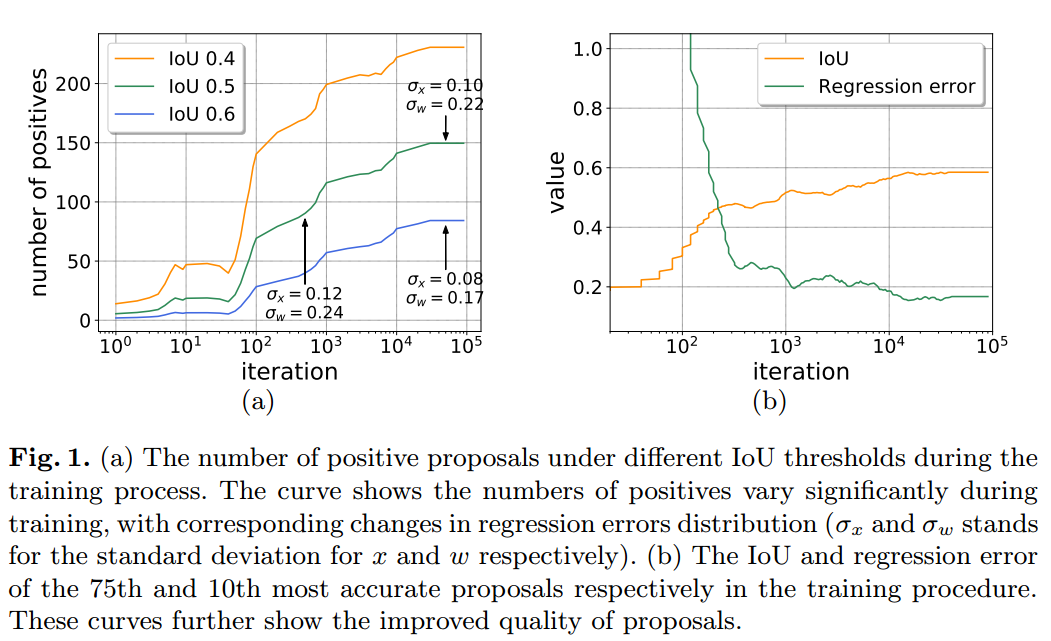
左图可以看出,随着训练进行,在固定iou阈值下正样本个数是不断增加的,不管你设置的iou阈值为多少,同时回归误差的方差是不断变小的。看右边可以看出随着训练进行,预测值和gt的iou是慢慢增加的,回归误差是不断降低。这两幅图说明的问题是:随着训练过程中,预测的bbox质量是会变的,正样本数也是不断增加的,此时采用固定的iou阈值肯定是不完美的,同时随着训练进行,回归误差的方差是不断变小的,采用smooth l1的固定也是不完美的,这两个核心参数应该动态变化。
2 训练过程改进
(1) Dynamic Label Assignment
rcnn的默认设置是正负样本区分阈值是0.5,没有忽略样本,本文动态的思想是:在训练前期,高质量正样本很少,所以应该采用相对低的iou阈值来补偿,随着训练进行,高质量正样本不断增加,故可以慢慢增加iou阈值。其具体操作如下:
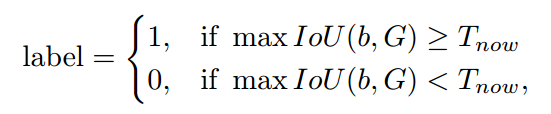
就是要动态调整的参数。作者的做法是首先计算rcnn输入即每个ROI和所有gt的最大iou值,在每张图片上选取前第个最大值,遍历所有图片,然后求均值作为T_now,并且每隔C个迭代更新一次该参数。图片示意图如下所示:
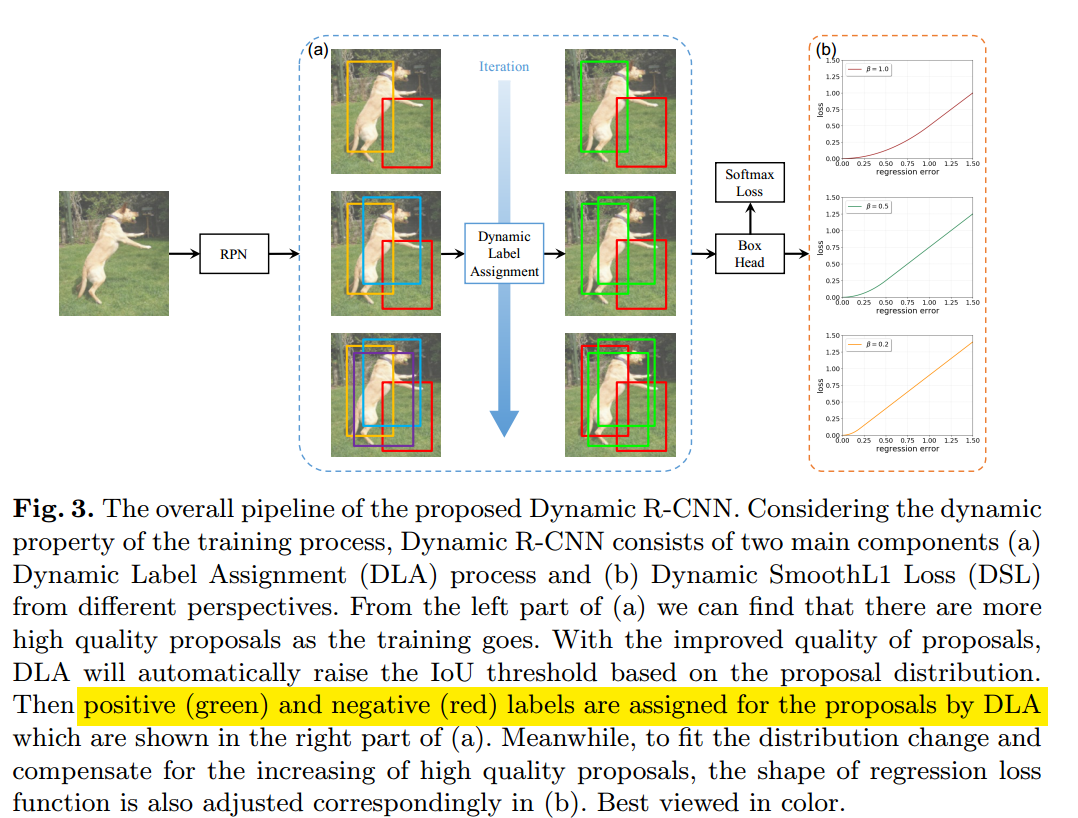
绿色区域是正样本anchor,红色是负样本anchor。随着训练进行,iou阈值在动态增加,一些原本是相对高质量的预测慢慢变成了负样本,整个mAP在提高。mmdettection部分配置如下:
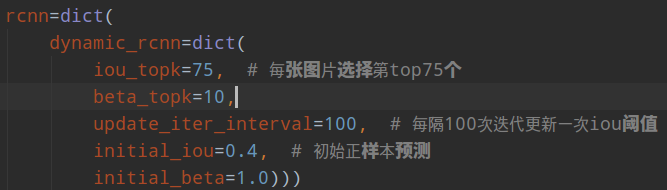
咋感觉这个75比较诡异,换个数据集这个参数如何确定呢?
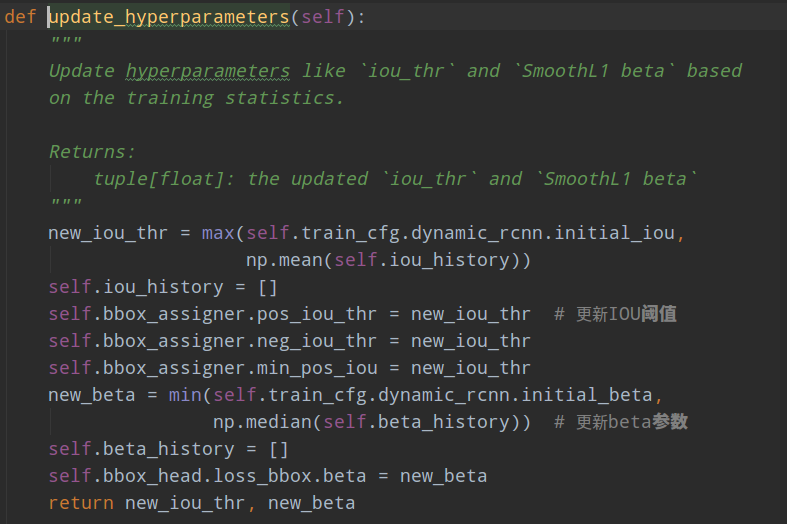
其实现过程在:mmdet/models/roi_heads/dynamic_roi_head.py

在达到update_iter_interval次数后就更新iou:
(2) Dynamic SmoothL1 Loss
前面说过随着训练的进行,bbox预测值方差会不断变小,反映出高质量预测框不断增加。可视化分析如下:
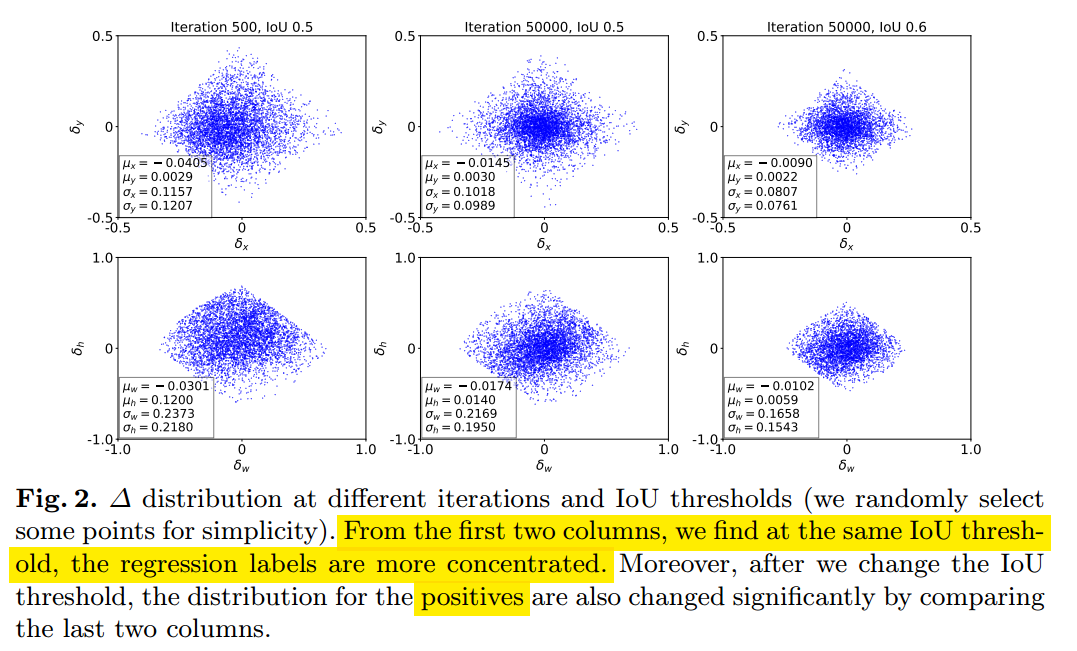
可以看出随着训练进行,回归误差的方差在变小,并且越来越集中(反映出高质量样本在增加),并且不同iou阈值下,分布差异比较大。既然iou的阈值设置会影响输出分布,那么最好在loss设计上面考虑这种变化。作者采用带参数的smooth L1 loss来自适应。
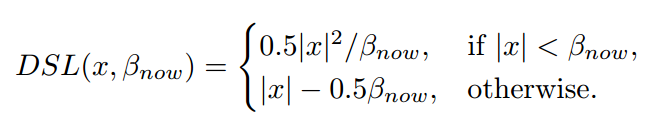
是需要动态确定的。其确定规则和前面相同,先计算预测值和Gt的回归误差,然后选择第个最小值的中位数作为设置值,不取平均值是因为外点有影响,不太好。
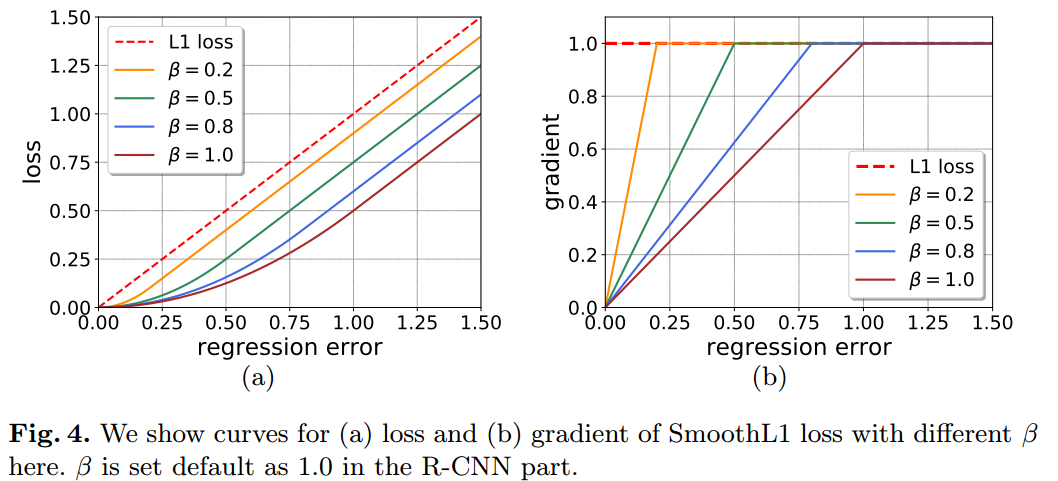
Dynamic SmoothL1 Loss (DSL) to change the shape of loss function to gradually focus on high quality samples。
可以肯定的是随着训练进行肯定是减少,从右边曲线可以看出,因为随着训练进行,高质量样本越来越多,而常规smooth l1 loss在此时梯度非常少,导致高质量样本无法进一步提高,故通过动态减少,来增加高质量部分样本的梯度,从而将高质量样本梯度和其余样本质量梯度平衡。
基于smooth l1 loss特点,其能从两个方面限制梯度:
当预测框与GT差别过大时,梯度值不至于过大;
当预测框与GT差别很小时,梯度值足够小。
其梯度公式是:
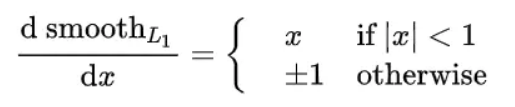
当绝对误差小于,则误差就是绝对误差,当大于则始终为1,梯度不会过大。考虑上述动态loss,随着训练进行,回归误差会越来越小,并且高质量的预测框其误差会更小,作者引入了动态来修正,让这部分的误差梯度增加一点,不会太小。可看出随着训练进行会越来越小,可以不断突出高质量预测框的回归误差。
具体实现方面也非常简单:
首先计算回归误差E,其实际上有4个误差,分别是xywh方向,但是看代码只取了xy方向两个然后取平均作为E,在整个batch里面选择出第beta_topk个小的值作为当前batch的E,然后不断训练保存历史E值,在达到指定迭代次数后再求所有E的中位数即可。
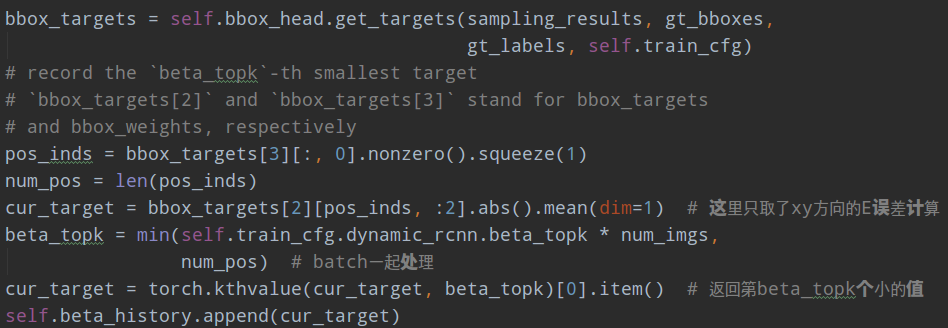
整体算法流程:

3 实验分析
可以发现本实验会引入三个超参:
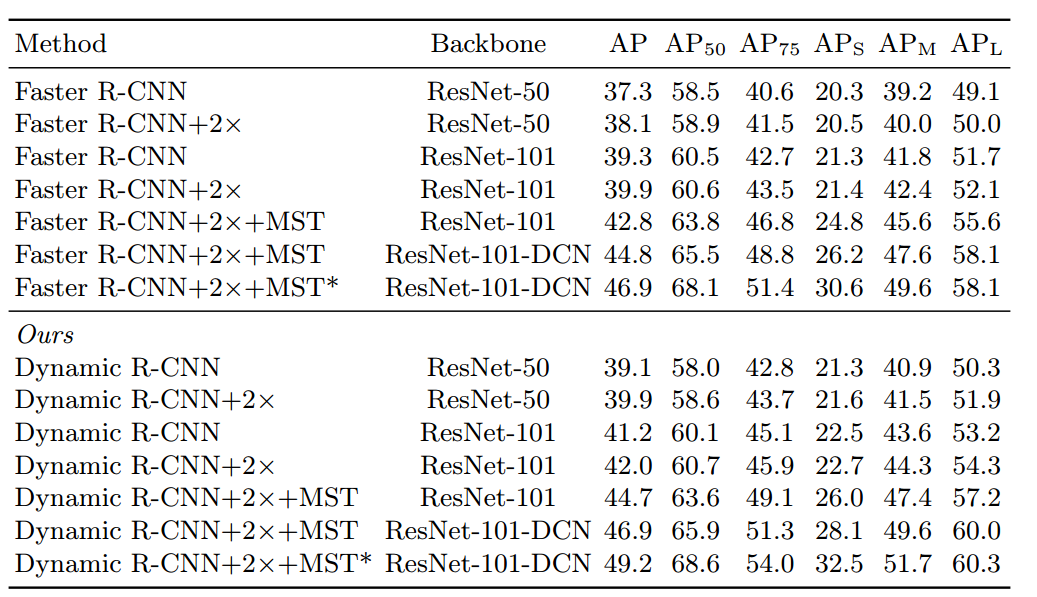
效果蛮好的,MST是多尺度测试。
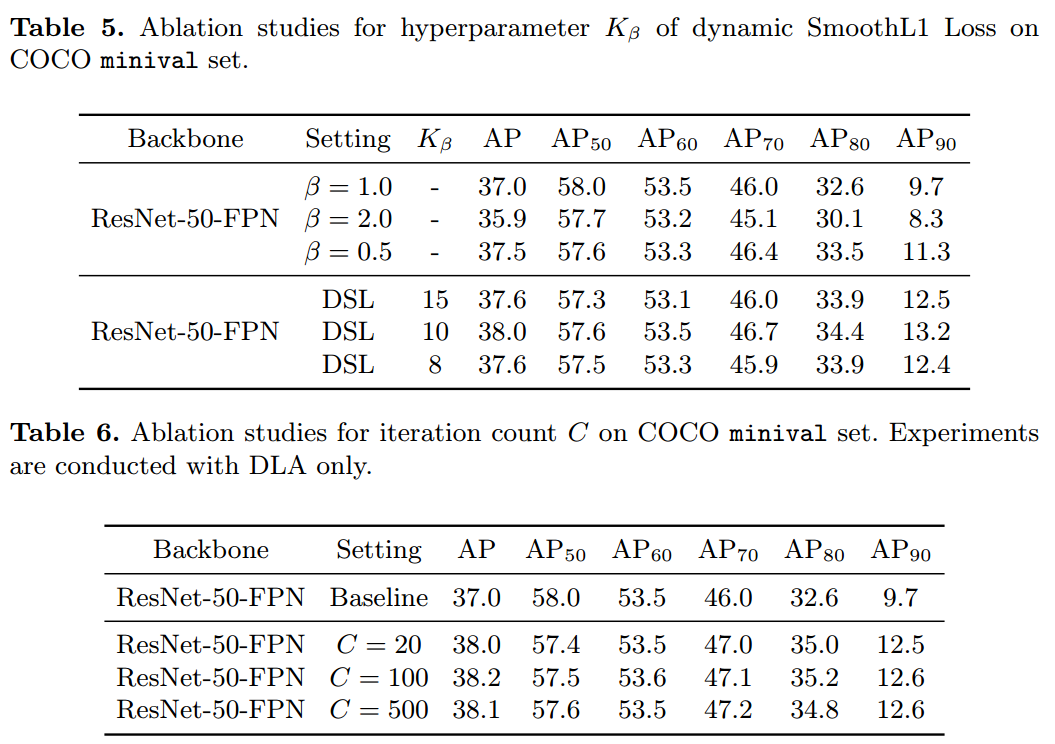
按照论文的说法,三个参数鲁棒,但是实际上可能要测试才知道。
其实我觉得这些超参还是比较重要的,应该没有那么鲁棒。随着训练进行,参数都是偏向高质量的roi部分,这应该就是一个head想做cascade rcnn3个head才能做到的事情的弊端吧,导致mAP50部分性能其实有下降。
4 总结
其实仔细思考,可以发现:本文就是利用训练过程来模拟cascade rcnn的过程。cascade rcnn是通过增加head部分,并且不同stage head采样不同阈值来实现,而本文是采用一个head,但是head的阈值是动态调整的。本质上做的都是同一个事情,做法不一样而已。相对而言本文比cascade rcnn更加make sense,但是单纯考虑精度,肯定不如cascade rcnn,毕竟cascade rcnn相当于本文做法的上限了
