@huanghaian
2020-12-01T07:01:11.000000Z
字数 4337
阅读 2582
移动端模型:mobilenetv1
分类
0 摘要
论文名称:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文地址:https://arxiv.org/abs/1704.04861
mobilenetv1提出的比较早,算是移动端模型的经典之作,所提出的深度可分离卷积(depthwise separable convolutions)操作是现在移动端压缩模型的基本组件,应用非常广泛。在此基础上通过引入宽度因子(width multiplier)和分辨率因子(resolution multiplier)来构建不同大小的模型以适应不同场景精度要求。但是由于精度和速度以及思想陈旧问题,目前来说mobilenetv1已经很少使用了,基本上都会首选mobilenetv2和v3。
需要提醒读者的是:阅读mobilenetv1,最主要是理解深度可分离卷积思想、具体实现以及FLOP的计算。
1 算法设计
1.1 算法核心
论文指出常用的模型小型化手段有:
(1) 卷积核分解,使用1×N和N×1的卷积核代替N×N的卷积核,例如分数Inception结构
(2) 使用bottleneck结构即大量使用1x1卷积,以SqueezeNet为代表
(3) 以低精度浮点数保存,例如Deep Compression
(4) 冗余卷积核剪枝及哈弗曼编码
首先需要明确移动端模型的要求是:在不会大幅降低模型精度的前提下,最大程度的提高运算速度。常规能够想到的做法是:
- 减少模型参数量
- 减少网络计算量
模型参数量少意味着整个模型的size比较小,非常适合移动端,试想用户下载个简单的图像分类功能app都超过100Mb,那肯定无法接受,而减少网络计算量可以使得在cpu性能有限的手机上流畅运行。
针对上述两个需求,mobilenetv1提出了两个创新:
- 轻量级移动端卷积神经网络。充分利用深度可分离卷积,其本质是冗余信息更少的稀疏化表达,在性能可接受前提下有效减少网络参数
- 进一步引入两个简单超参来平衡网络延时和精度,可以针对不同的应用场景进行有效裁剪
1.2 深度可分离卷积
首先分析常规卷积流程,然后再引入深度可分离卷积。
(1) 常规卷积
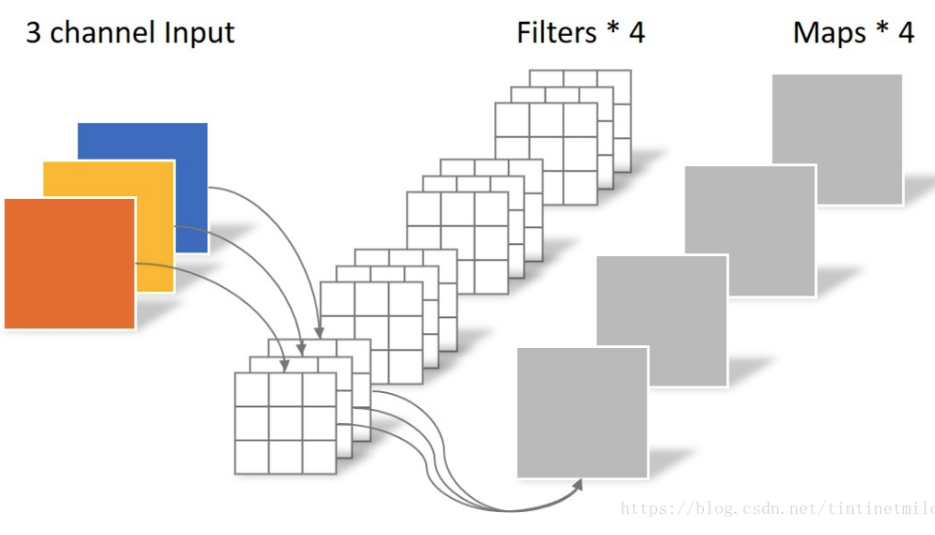
上述图片暂时没有找到出处
设输入特征图维度是,是特征图宽,并且宽和高相等,假设输出的特征图宽高和输入一致,仅仅通道数更改为,那么常规卷积的操作为:首先将N个K×K的卷积核分别作用在M个输入通道上,产生M×N个特征图,然后叠加每个输入通道对应的特征图,最终得到N个通道的输出特征图。
以上面图示为例,不考虑batch和padding,假设卷积核参数是3x5x5x4(3是输入通道,4是输出通道,5x5是kernel),输入特征图shape是(3,100,100),输出特征图shape是(4,100,100),则计算过程是:将滤波器参数3x5x5x4分成4组即[3x5x5,3x5x5,3x5x5,3x5x5],然后将4组滤波器(3,5,5)和同一个输入特征图(3,100,100)分别进行卷积操作(对于每一层滑动窗口内计算都是先对应位置相乘,然后全部加起来变成1个数输出),输出也是4组特征图[1x100x100,1x100x100,1x100x100,1x100x100],然后concat最终就得到输出特征图shape为(4,100,100)。
上述卷积操作参数量比较简单是,而计算量(乘加次数)是,这里是把一次先乘后加的操作合并了。
(2) 深度可分离卷积
深度可分离卷积实际是两次卷积操作,分别是depthwise convolution和pointwise convolution。对每个通道(深度)分别进行空间卷积(depthwise convolution),并对输出进行拼接,随后使用1x1卷积核或者说逐点进行通道卷积(pointwise convolution)以得到特征图。
依然以上面的例子为例进行分析,卷积核参数是3x5x5x4(3是输入通道,4是输出通道,5x5是kernel),输入特征图shape是(3,100,100),输出特征图shape是(4,100,100)。
第一步: depthwise convolution
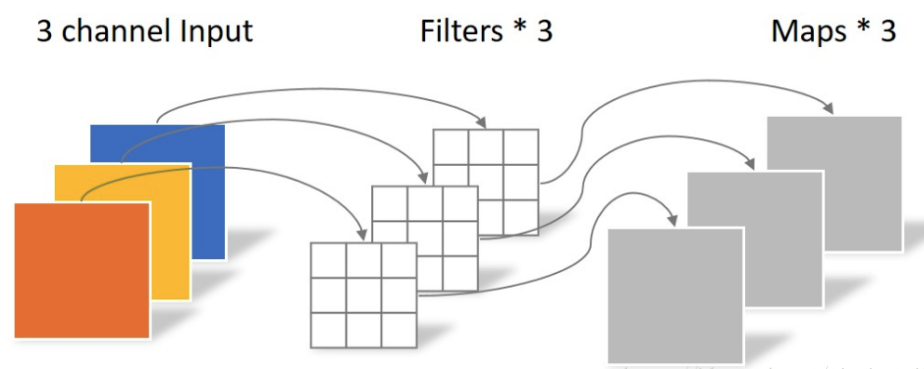
上述图片暂时没有找到出处
该部分的卷积参数是3x5x5x1,具体计算过程是:将滤波器参数3x5x5x1分成3组即[5x5x1,5x5x1,5x5x1],
同时将输入特征图也分成三组即[100x100x1,100x100x1,100x100x1],然后将3组滤波器(5,5,1)和3组特征图100x100x1进行一一对应的计算卷积操作,输出三组即[100x100x1,100x100x1,100x100x1],concat后输出是3x100x100。
可以看出其参数量是,而计算量(乘加次数)是。
第二步: pointwise convolution
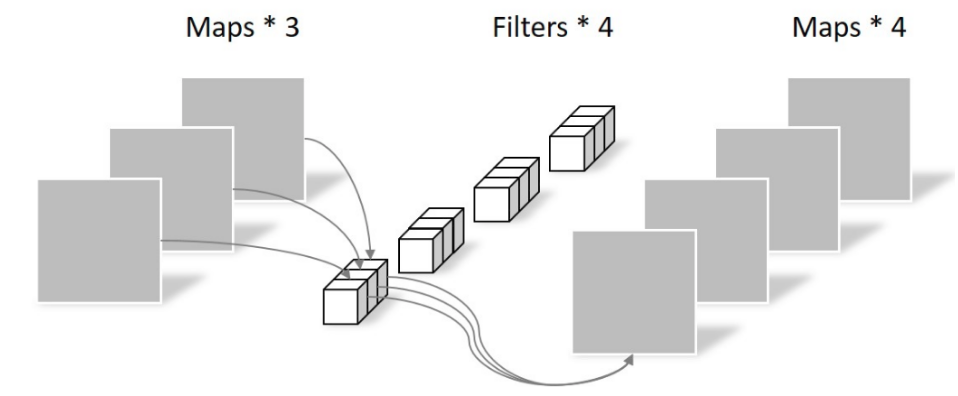
上述图片暂时没有找到出处
这步骤其实是标准卷积,只不过kernel比较特殊是1x1的。故其卷积操作参数量比较简单是,而计算量(乘加次数)是。
故深度可分离卷积的总参数量是,计算量是
对比常规卷积计算量是:
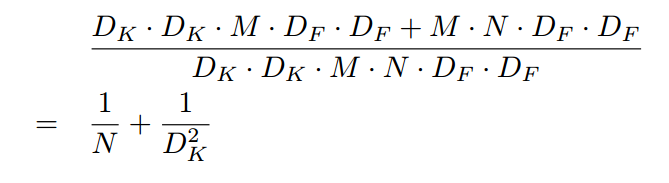
分子是通道可分离卷积计算量,分母是常规卷积计算量。可以看出,如果取3,那么理论上可以加速8到9倍,当然参数量也要显著下降。
通过对卷积进行分步改进,则将标准的conv+bn+relu变成了如下所示:
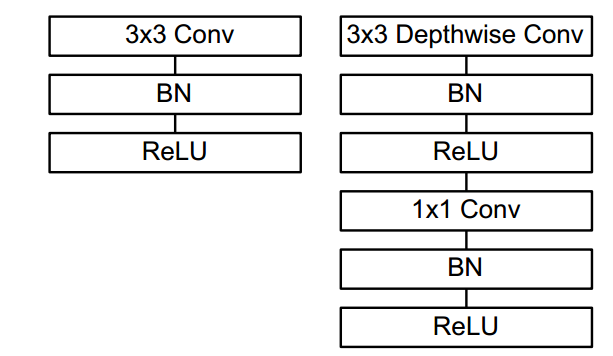
代码层面实现也比较简单:
class _conv_dw(nn.Module):def __init__(self, inp, oup, stride):super(_conv_dw, self).__init__()self.conv = nn.Sequential(# dwnn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),nn.BatchNorm2d(inp),nn.ReLU6(inplace=True),# pwnn.Conv2d(inp, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),nn.ReLU6(inplace=True),)self.depth = oupdef forward(self, x):return self.conv(x)
实现比较巧妙,通过分组卷积(分组数正好等于输入通道数)就可以实现深度方向卷积,后面再接一个普通的1x1卷积即可。
1.3 基本网络模型
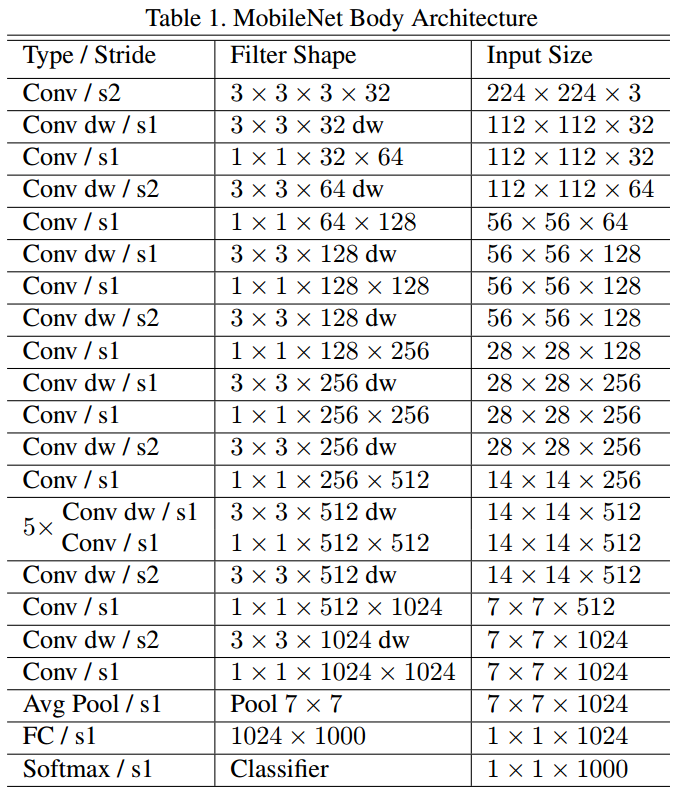
将depthwise convolution和pointwise convolution认为是独立的一层卷积,那么mobilenet网络一共28层,如上表所示,dw是depthwise convolution,s1表示stride为1。
在具体底层实现上,作者指出depthwise convolution结合1x1的pointwise convolution代替传统卷积不仅在理论上会更高效,而且由于大量使用1x1卷积,可以直接使用高度优化的数学库来完成这个操作。以Caffe为例,如果要使用这些数学库,要首先使用im2col的方式来对数据进行重新排布,从而确保满足此类数学库的输入形式,但是1x1方式的卷积不需要这种预处理。并且深度可分离卷积的计算量几乎全部在pointwise convolution上,现在不需要重排了,故所提卷积不仅在理论上,而且在实现上都是非常高效的。
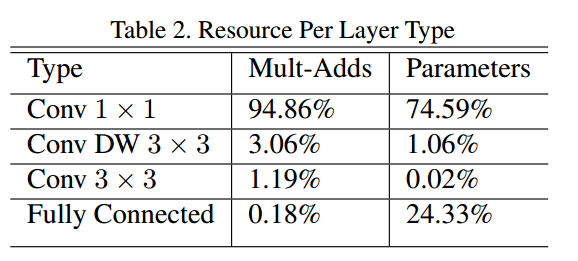
从上表可以看出,在一次通道可分离卷积运算中,pointwise convolution占了94.86%,参数量占了74.59%,可想而知网络是非常高效的。
1.4 宽度因子和分辨率因子
作者指出,尽管上述MobileNet在计算量和模型尺寸方面具备很明显的优势,但是在一些对运行速度或内存有极端要求的场合,还需要更小更快的模型,如何能够在不重新设计模型的情况下,以最小的改动就可以获得更小更快的模型呢?故本文提出的宽度因子和分辨率因子就是解决上述问题的配置参数。
宽度因子是一个属于(0,1]之间的数,常用配置为{1,0.75,0.5,0.25},附加于网络的通道数上,使得整个mobilenet模型的计算量和参数数量约减到的平方倍,计算量如下:
分辨率因子的取值范围在(0,1]之间,是作用于每一个模块输入尺寸的约减因子,简单来说就是将输入数据以及由此在每一个模块产生的特征图都变小了,结合宽度因子,计算量如下:
就是标准的mobilenet,会对输入进行缩减,常见的网络输入是{224, 192, 160,128},通过参数可以非常有效的将计算量和参数数量约减到的平方倍。
注意:使用宽度和分辨率参数调整网络结构之后,都要从随机初始化重新训练才能得到新网络。
2 训练细节
作者基于TensorFlow训练MobileNet,使用RMSprop算法优化网络参数。考虑到较小的网络不会有严重的过拟合问题,因此没有做大量的数据增强工作。在训练过程中也没有采用训练大网络时的一些常用手段,例如:辅助损失函数,随机图像裁剪输入等。而且depthwise卷积核含有的参数较少,作者发现这部分最好使用较小的weight decay或者不使用weightdecay。
3 实验结果
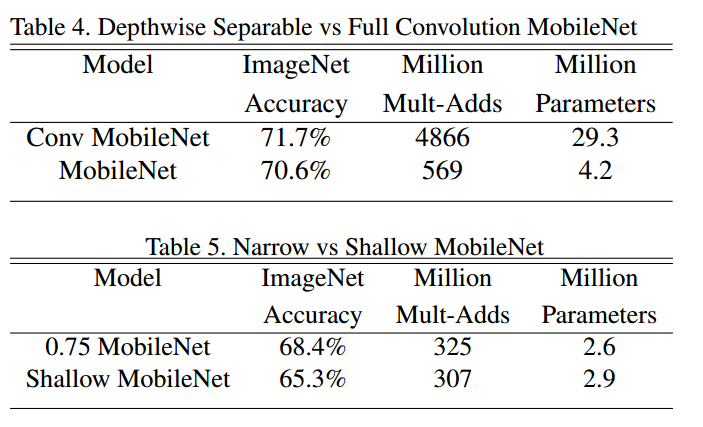
- 从表4可以看出:和普通卷积对比,深度可分离卷积的分类性能仅仅下降了1%,但是计算量下降了一个量级
- 从表5可以看出:0.75mobilenet是指宽度因子是0.75,shallow是指把网络的前6层去掉的浅层网络,可以看出使用宽度因子效果明显好于浅层网络,且计算量相同
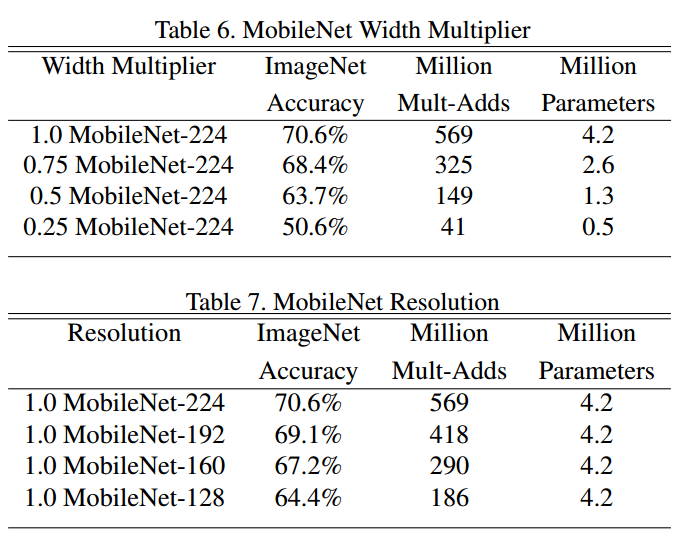
从表6和表7可以看出:不同的宽度因子和分辨率因子对网络性能有影响,在实际应用中需要自己平衡。
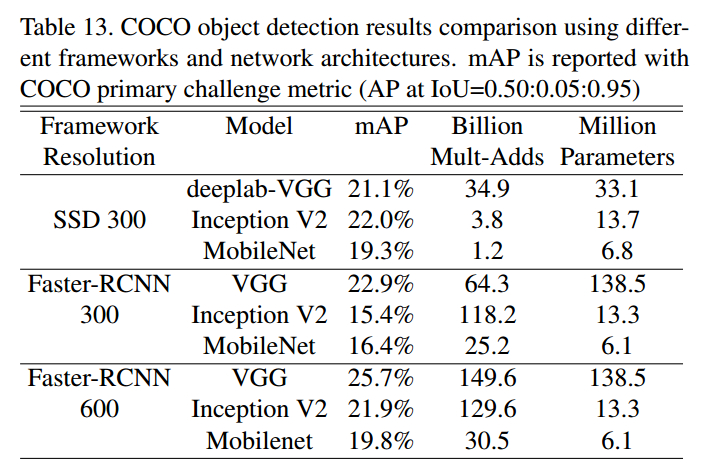
将mobilnet应用于ssd目标检测算法中作为骨架网络,可以看出,mobilenet性能有所下降,但是计算量下降非常大,整体而言还是可以接受的。
4 总结
本文核心是提出了深度可分离卷积操作,可以在仅仅牺牲一点点参数量的基础上显著减少参数量和计算量,同时为了能够适用不同资源的移动设备,还引入了宽度因子和分辨率因子来复合缩放基础mobilenet。
