@huanghaian
2020-11-18T06:03:48.000000Z
字数 4126
阅读 2220
mmdetection: Mask RCNN
mmdetection
0 摘要
mask rcnn是faster rcnn的扩展版,通过新增mask掩码分支可以实现实例分割任务。不仅如此,实际上mask rcnn是一个简单、优雅、扩展性极强的框架结构,其最大特点是任务扩展性强,这是很多one-stage目标检测算法所无法比拟的,通过新增不同分支就可以实现不同的扩展任务,例如还可以将mask分支替换为关键点分支即可实现多人姿态估计。其主要创新点可以归纳如下:
- 基于FPN+Faster rcnn结构,通过新增mask或者关键点分支,可以实现实例分割或者多人姿态估计
- 为解决特征图与原始图像上的RoI不对准的问题,提出了ROIAlign模块
1 算法分析
1.1 roialign模块
为了理解roialign,你需要先阅读faster rcnn中提到的roipool操作,假设输出大小是2x2,其可视化如下:
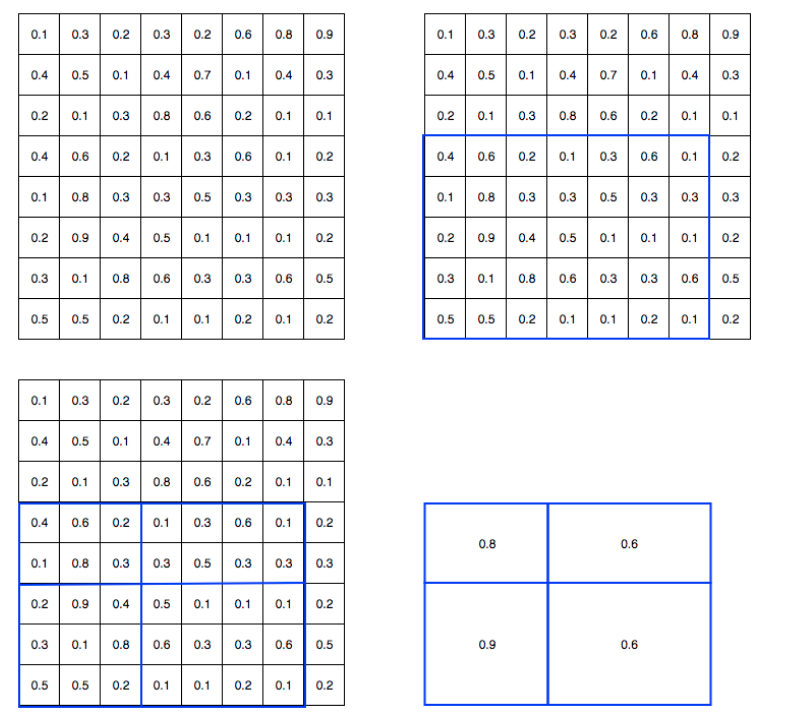
roipool存在两次取整操作:
- 将候选框边界转化为整数点坐标值。
- 将整数化后的边界区域平均分割成 k x k 个单元(bin),对每一个单元的边界进行整数化。
经过上述两次整数化,此时的候选框已经和最开始回归出来的位置有一定的偏差,对整数化后切割的roi特征图就已经不是我们想要的了,这个偏差会影响检测或者分割的准确度。在论文里作者把它总结为“不匹配问题”(mis-alignment)。
举个简单例子说明,假设输入图片大小是800x800,在原图的x1y1x2y2为(10,10,675,675)坐标处有gt bbox。图片经过resnet骨架网络,stride=16,映射到特征图上x1y1x2y2是(0.625,0.625,42.18,42.18),由于无法取整,故其会进行第一次坐标量化(假设是四舍五入)变成(1,1,42,42),可以发现现在x1坐标就偏移了0.375,对于到原图是偏差6个像素。接下来需要把框内的特征池化为7x7大小,因此将上述roi平均分割成7x7个矩形区域,每个矩形区域的边长为5.85,其含有小数,此时roipool会进行第二次量化,再次把它整数化到5,此时就出现了0.85个偏差了。可以简单粗略计算经过两次量化,就已经出现了0.85+0.375=1.225,对应到原图上是19.6个像素误差。这个偏差对于小物体来说不容小觑,对于需要精细mask预测任务来说那其实就是灾难了。
为了解决这个问题,ROI Align方法取消两次整数化操作,保留了小数,每个小数位置都采用双线性插值方法获得坐标为浮点数的特征图上数值。其可视化如下所示:
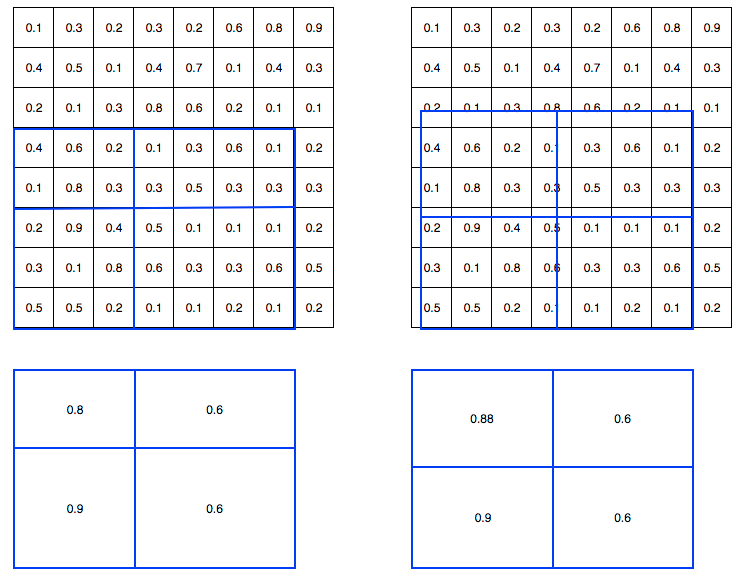
左边是roipool,右边是roialign。其具体操作可视化如下:

假设黑色大框是要切割的bbox,并且打算统一成2x2输出,则是先把黑色大bbox均匀切割为4个小bbox,然后在每个小bbox内部均匀采4个点(相当于每个小bbox内部再次均匀切割为2x2共4个小块,取每个小块的中心点即可),首先对每个采样点利用双线性插值函数得到该浮点值处的值(插值的4个整数点是上下左右最近的4个点),然后对4个采样点采样值取max操作得到该小bbox的最终值。采样个数4是超参,实验发现设置为4最合适,速度和精度都是最合适的。
1.2 mask分支
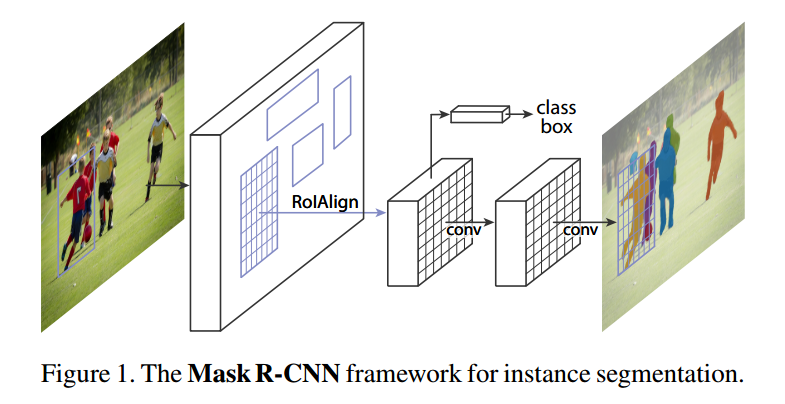
mask rcnn算法可以构建在faster rcnn或者fpn上,现在主流是采用fpn,故本文分析是基于faster rcnn+fpn的主流结构进行。其结构如下:
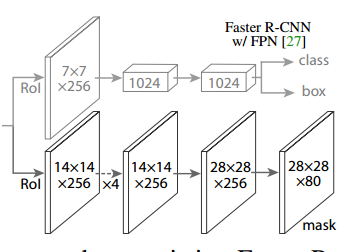
可以看出mask分支是和bbox分支并列,只不过考虑到mask分支需要更加精细特征图,故其roialign后尺寸不再是7x7,而是14x14,然后经过4个3x3卷积和反卷积上采样模块,变成28x28的特征图,最后经过1x1卷积得到nun_class个通道输出。
其核心配置如下:
mask_roi_extractor=dict(type='SingleRoIExtractor',roi_layer=dict(type='RoIAlign', output_size=14, sampling_ratio=0),out_channels=256,featmap_strides=[4, 8, 16, 32]),mask_head=dict(type='FCNMaskHead',num_convs=4,in_channels=256,conv_out_channels=256,num_classes=80,loss_mask=dict(type='CrossEntropyLoss', use_mask=True, loss_weight=1.0))))
通过配置可以发现其包括两个roialign提取器,分别作用于bbox分支和mask分支。和bbox分支运行流程类似,mask分支运行流程为:
(1) 利用RPN提出的n个roi区域,结合FPN中的映射规则,采用roialign模块在FPN输出的5个特征图上进行切割操作,变成(batch,n,256,14,14)输出
(2) 对(batchxn,256,14,14)的特征图输入到全卷积的mask head中,输出(batchxn,num_class,14,14)输出
注意由于mask分支仅仅需要计算正样本roi,故其输入的n个roi区域仅仅包括正负样本定义阶段所确定的正样本而已。
为了方便大家整体把握算法流程,下面介绍mask rcnn的rcnn部分整体核心训练流程:
# 遍历每张图片,对rpn提取的proposal_list和对应gt bbox进行正负样本定义和正负样本采样# 此时就可以确定每个proposal_list的正负和忽略样本属性了for i in range(num_imgs):assign_result = self.bbox_assigner.assign(proposal_list[i], gt_bboxes[i], gt_bboxes_ignore[i],gt_labels[i])sampling_result = self.bbox_sampler.sample(assign_result,proposal_list[i],gt_bboxes[i],gt_labels[i],feats=[lvl_feat[i][None] for lvl_feat in x])# bbox分支# 将所有rois映射到对应特征图上,并且通过roialign操作统一输出rois = bbox2roi([res.bboxes for res in sampling_results])bbox_feats = self.bbox_roi_extractor(x[:self.bbox_roi_extractor.num_inputs], rois)# 最后输入到分类和bbox回归分支进行预测cls_score, bbox_pred = self.bbox_head(bbox_feats)# mask分支# 仅仅将正样本roi映射到对应特征图上,并且通过roialign操作统一输出pos_rois = bbox2roi([res.pos_bboxes for res in sampling_results])mask_feats = self.mask_roi_extractor(x[:self.mask_roi_extractor.num_inputs], rois)# 最后输入到mask分支进行预测mask_pred = self.mask_head(mask_feats)
由于多了个mask分支,故rcnn部分的loss变成了:
注意mask分支的输出通道数num_class,并不是num_class+1,故其Loss其实是bce loss即对每个类别独立地预测一个二值mask,没有引入类间竞争,每个二值mask的类别提取依靠网络ROI分类分支给出的分类预测结果。

上图是FCIS预测结果,下图是mask rcnn预测结果。
1.3 关键点分支
将mask分支替换为关键点分支即可实现多人关键点检测(当然mask分支想保留也可以)。做法和mask分支非常类似,假设每个人检测17个关键点,那么该分支输出shape是(batchxn,17,56,56),其target设置为在56x56的特征图上如果某个位置有关键点,那么该位置为1,其余位置全部为0,优化loss是ce loss,不是bce loss,因为这本身就存在类间竞争,不可能某个位置存在两个关键点。之所以设置为56x56,而不是28x28是因为实验发现高分辨输出特征图对关键点检测精度影响很大。

2 推理流程
以实例分割为例分析,流程如下:
(1) 对于单张图片输入到resnet和fpn中,输出5个不同大小的特征图
(2) 对5个输出图都经过rpn head,分别预测前后景和bbox坐标
(3) 采用rpn测试配置对预测结果进行解码,并且经过nms得到proposal_list
(4) 利用fpn映射规则,确定proposal_list中每个proposal应该切割哪个特征图层
(5) 对每个proposal在指定特征图层进行roialign切割操作,变成统一大小
(6) 组成batch输入到rcnn bbox head进行类别分类和proposal refine回归
(7) 对预测结果再次进行nms操作得到优化后的最终bbox_list
(8) 对上述得到的bbox_list(可以认为是新的proposal_list),利用fpn映射规则,确定bbox_list中每个bbox应该切割哪个特征图层
(9) 对每个bbox在指定特征图层进行roialign切割操作,变成统一大小
(10) 组成batch输入到rcnn mask head进行mask预测,得到每个bbox的掩码
需要特别注意的是在测试阶段,mask分支的输入不是RPN预测输出的proposal_list,而是经过bbox分支refine后得到的bbox_list,这样才能保证bbox和mask完全一致。
3 总结
mask rcnn是一个非常通用的two-stage框架,通过简单的扩展即可实现不同的任务。虽然提出时间比较早,但是依然是目前的主流算法。
