@huanghaian
2020-12-02T02:01:33.000000Z
字数 4359
阅读 1749
移动端模型:mobilenetv2
分类
0 摘要
论文题目:MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文地址:https://arxiv.org/abs/1801.04381
mobilenetv2是v1的改进,随后shufflenetv1又对mobilenetv1进行了改进,并且结合resnet构建思想采用了botttleneck结构,相比之下,mobilenetv1设计思想就显得比较陈旧了(没有block的概念,也没有残差连接),故这些问题都在mobilenetv2中进行了改进,效果提升非常明显。主要创新点是:
- 提出线性瓶颈层Linear Bottlenecks,也就是去掉了1x1降维输出层后面的非线性激活层,目的是为了保证模型的表达能力
- 提出反转残差块Inverted Residual block,该结构和传统residual block中维度先缩减再扩增正好相反,因此shotcut也就变成了连接的是维度缩减后的feature map
简单来说,mobilenetv2是基于mobilenetv1的通道可分离卷积优势,然后再加入了残差模块功能,最后通过理论分析和实验证明,对残差模块进行了一定程度的修改,使其在移动端发挥最大性能。
1 算法设计
1.1 算法核心
mobilenetV1主要是引入了depthwise separable convolution代替传统的卷积操作,实现了spatial和channel之间的解耦,达到模型加速的目的,但是整个模型非常类似vgg,思想比较陈旧,最主流的做法应该是参考resnet设计思想,引入block和残差设计。
而且作者通过实验发现mobilenetV1结构存在比较大的缺陷。在实际使用的时候, 发现Depthwise 部分的kernel比较容易训废掉即训完之后发现depthwise训出来的kernel有不少是空的即大部分输出为0,这个问题在定点化低精度训练的时候会进一步放大。针对这个问题,本论文进行了深入分析。
假设经过激活层后的张量被称为兴趣流形(manifold of interest),shape为HxWxD。根据前人研究,兴趣流形可能仅分布在激活空间的一个低维子空间里,或者说兴趣流形是可以用一个低维度空间来表达的,简单来说是说神经网络某层特征,其主要信息可以用一个低维度特征来表征。一般来说我们都会采用类似resnet中的bottlenck层来进行主要流形特征提取,在具体实现上,通常使用1x1卷积将张量降维,但由于ReLU的存在,这种降维实际上会损失较多的信息,特别是在通道本身就必须小的时候。

如上图所示,利用MxN的矩阵T将张量(2D,即dim=2)变换到M(M可以任意设置)维的空间中,通过ReLU后(y=ReLU(Bx)),再用此矩阵T的逆恢复原来的张量。可以看到,当M较小时,恢复后的张量坍缩严重,M较大(30)时则恢复较好。这意味着,在较低维度的张量表示(兴趣流形)上进行ReLU等线性变换会有很大的信息损耗。显然,当把原始输入维度增加到15或30后再作为ReLU的输入,输出恢复到原始维度后基本不会丢失太多的输入信息;相比之下如果原始输入维度只增加到2或3后再作为ReLU的输入,输出恢复到原始维度后信息丢失较多。因此在MobileNet V2中,执行降维的卷积层后面不会接类似ReLU这样的非线性激活层,也就是所提的linear bottleneck。总结如下:
- 对于ReLU层输出的非零值而言,ReLU层起到的就是一个线性变换的作用
- ReLU层可以保留输入兴趣流形的信息,但是只有当输入兴趣流形是输入空间的一个低维子空间时才有效。
如果上述不好理解的话,那么通俗理解就是:当采用1x1逐点卷积进行降维,如果原始降维前输入通道本身就比较小,那么经过Relu层后会损失很多信息,导致不断堆叠层后有效信息越来越小,到最后分类性能肯定会下降,就会表现出很多kernel出现全0的现象,特别是逐深度卷积+1x1逐点卷积时候现象更加明显,因为逐深度卷积表达能力不如标准卷积。
1.2 Linear Bottlenecks
基于上述分析,为了保证信息不会丢失太多,在Bottlenecks层的降维后不在接relu,图示如下:
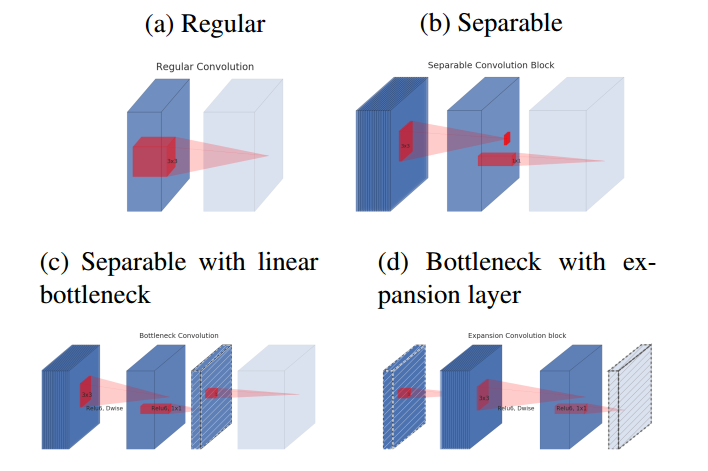
蓝色块表示特征图,浅色块表示下一个block的开始,红色块表示卷积或者Relu操作,含有斜线的块表示不包括非线性层
- (a)为标准卷积
- (b)为逐深度可分离卷积
- (c)为在(b)后面加入“bottlenck layer”,即在后面接了一个不含有relu层的1x1卷积进行通道扩张,防止信息丢失过多
- 考虑到block是互相堆积的,调整一下视角,将“bottlenck layer”看成block的输入,那么这种结构也等价于(d),block中开始的1x1卷积层称为“expansion layer”,它的通道大小和输入bottleneck层的通道大小之比,称为扩展比(expansion ratio)。扩展层之后是depthwise卷积,然后采用1x1卷积得到block的输出特征,这个卷积后面没有非线性激活
1.3 Inverted residuals
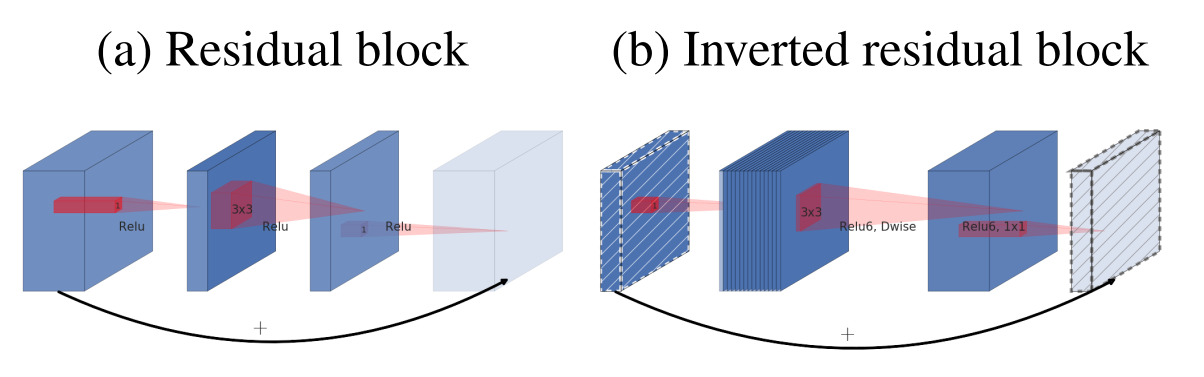
(a)为标准的残差块,而(b)为所提出的反转残差块,为啥叫做反转?原始是残差块一般先采用bottleneck layer(1x1卷积)进行降维,最后在采用bottleneck layer进行扩展,而反转的做法是先采用bottleneck layer(1x1卷积)进行升维,最后在采用bottleneck layer进行降维,是相当于残差块的反向操作,其中斜线块表示在该特征图上面没有采用relu激活函数,通过实验表明反转残差块可以在实现上减少内存的使用,并且精度更少。

请注意:上图(b)应该是绘制错误,论文里面说过在1x1降维层不采用relu激活函数,故实际上应该是1x1conv升维度(有relu)+3x3d conv+1x1conv降维(没有relu),但是上面图明显绘制错误了。通过下面图示也可以看出来:
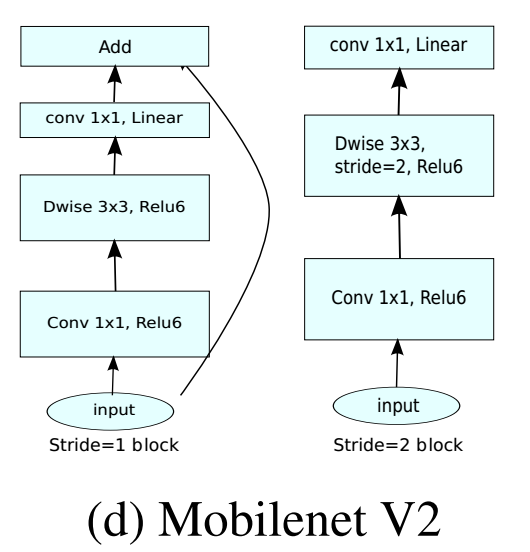
当stride=2的时候没有采用残差设计,代码如下:
class InvertedResidual(nn.Module):def __init__(self,in_channels,out_channels,stride,expand_ratio,conv_cfg=None,norm_cfg=dict(type='BN'),act_cfg=dict(type='ReLU6')):super(InvertedResidual, self).__init__()self.stride = stride# 扩张后通道维度hidden_dim = int(round(in_channels * expand_ratio))layers = []if expand_ratio != 1:# 1x1卷积先扩展维度,有relu6layers.append(ConvModule(in_channels=in_channels,out_channels=hidden_dim,kernel_size=1,conv_cfg=conv_cfg,norm_cfg=norm_cfg,act_cfg=act_cfg))layers.extend([#3x3 dw卷积,有relu6ConvModule(in_channels=hidden_dim,out_channels=hidden_dim,kernel_size=3,stride=stride,padding=1,groups=hidden_dim,conv_cfg=conv_cfg,norm_cfg=norm_cfg,act_cfg=act_cfg),# 1x1 pw卷积,没有reluConvModule(in_channels=hidden_dim,out_channels=out_channels,kernel_size=1,conv_cfg=conv_cfg,norm_cfg=norm_cfg,act_cfg=None)])self.conv = nn.Sequential(*layers)def forward(self, x):if self.use_res_connect:return x + self.conv(x)else:return self.conv(x)
总结一下,本文主要是提出了linear bottleneck,和inverted residual两个改进,其中针对1x1点卷积后接relu会丢失大量信息,而提出了linear bottleneck,在该改进基础上配合残差块的设计思想,最终提出了inverted residual block。
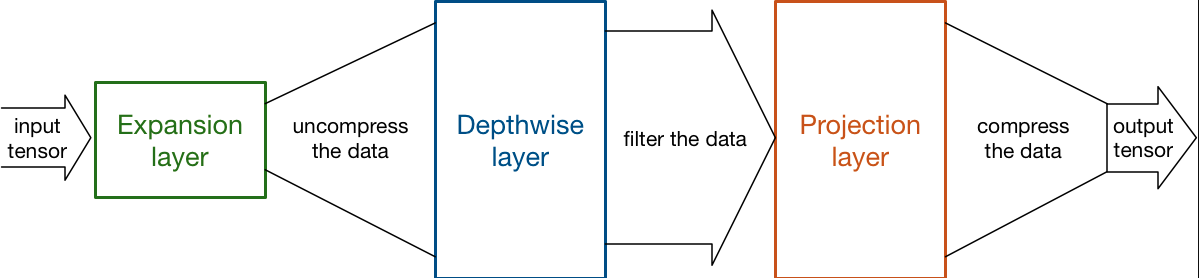
图片来源:MobileNet version 2,该博客认为反转残差块的设计思想可以将expansion layer可以看做解压器,类似unzip,将特征恢复到高维空间,而 depthwise layer可以看成过滤器,筛选比较重要的特征,最后projection layer将其压缩到低维空间。
1.4 网络设计
基于inverted residual block就可以构建整个mobilenetv2了。
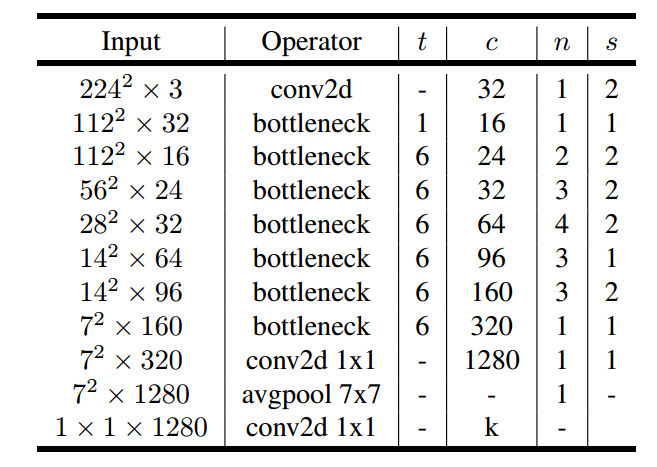
t是扩张系数,c是输出通道数,n是重复次数,s是stride。可以看出这个基础网络都没有pool操作,而是采用stride代替。
实际上v2也设计了宽度因子和分辨率因子两个超参数控制网络的参数量,默认是默认宽度因子是1.0,输入大小是224x224,分辨率因子影响的是特征图空间大小,而宽度因子影响的是特征图channel大小。输入大小可以从96到224,而宽度因子可以从0.35到1.4。值得注意的一点是当宽度因子小于1时,不对最后一个卷积层的channel进行调整以保证性能,即维持1280。
2 实验结果
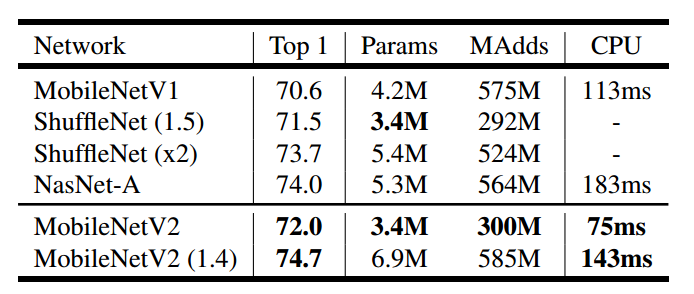
在imagenet图像分类任务上面进行训练,结果如上,在同样参数大小下,MobileNetv2比MobileNetv1和ShuffleNet要好,而且速度也更快一些。
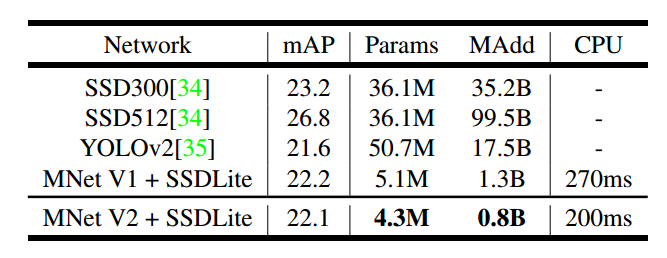
上表可以看出MobileNet V2+SSDLite达到了极高的性能,且速度非常块。
3 总结
mobilnetv2主要是对v1进行针对性改进,针对dwconv+pwconv后经过relu激活层会丢失大量信息,导致dw很多kernel都失活,提出了线性瓶颈层,主要是pw卷积降维时候不采用relu,接着在该基础上结合残差设计思想提出了反转残差块,通过堆叠反转残差块实现了在移动端上又快又好的模型。多个任务benchmark平台结果表明比mobilenetv1和shufflenetv1更加优异。
