@huanghaian
2020-11-18T06:01:18.000000Z
字数 3050
阅读 2960
mmdetection: FPN
mmdetection
0 摘要
FPN全名是Feature Pyramid Networks,特征金字塔现在可以说是必备组件了,在不同领域都有相关做法,其主要作用是提升小物体检测精度,同时也可以通过特征融合提升整体性能,属于即插即用模块,通用性非常强。
作者首先分析当前目标检测常用解决方案有:
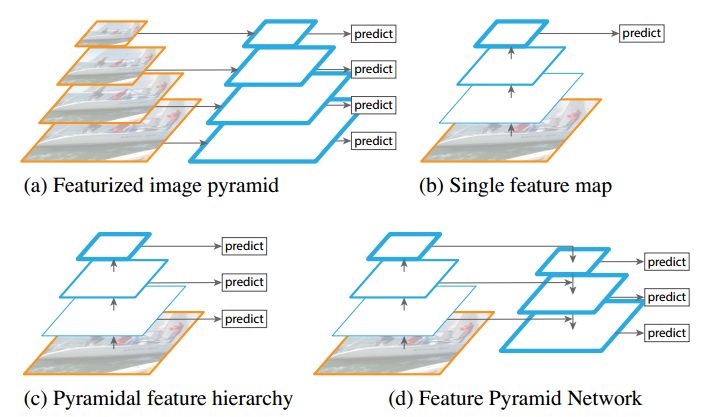
(1) 图像金字塔,也可以称为多尺度训练和测试,典型算法是DPM,如图a所示。对原始图片进行多尺度采样构成图像金字塔,然后在每个层级上面进行预测,缺点是计算量极大,无法实际使用。在实际中为了平衡,有些算法会在测试时候采用图像金字塔,而训练时候不使用;
(2) 单层预测,典型算法是RCNN系列和YOLO,如图b所示。该类算法本质是利用卷积网络具有的类似于金字塔功能的特征提取能力,然后在最高层进行预测,缺点是只使用最高层语义信息会丢失小目标精度,因为stride步骤的存在,高分辨率的低层特征很难有代表性的检测能力;
(3) 多层预测,典型算法是SSD,如图c所示。该类算法在不同层后进行预测,部分弥补了(2)类方法的不足,缺点是直接强行让不同层学习相似的语义信息会存在语义间隙。对于卷积神经网络而言,不同深度对应着不同层次的语义特征,浅层网络分辨率高,学的更多是细节特征,深层网络分辨率低,学的更多是语义特征。SSD还存在一个问题:它并没有利用较低高分辨率特征图,而是在高层特征图后面再加了几层,作者认为这样对小目标检测不利。
基于以上三种方法存在的不足,作者提出如图d所示结构,通过top-down pathway 从上到下路径和横向连接lateral connections,结合高分辨率、弱语义信息的特征层和低分辨率、强语义信息的特征融合,实现类似图像金字塔效果,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的,效果显著。
1 算法分析
1.1 FPN网络结构
FPN模块也就是我们常说的neck,其配置如下:
neck=dict(type='FPN',in_channels=[256, 512, 1024, 2048],out_channels=256,num_outs=5),
为了充分发挥FPN功效,骨架网络输出就不再是一个特征图了,而是多个尺度的特征图,配置如下所示:
backbone=dict(type='ResNet',depth=50,num_stages=4,out_indices=(0, 1, 2, 3),frozen_stages=1,norm_cfg=dict(type='BN', requires_grad=True),norm_eval=True,style='pytorch'),
核心就是out_indices参数,其表示输出4个特征图,按照特征图从大到小排列,分别是c2 c3 c4 c5,stride=4,8,16,32,而num_outs表示经过FPN后需要输出5个特征图。FPN结构的细节图如下:
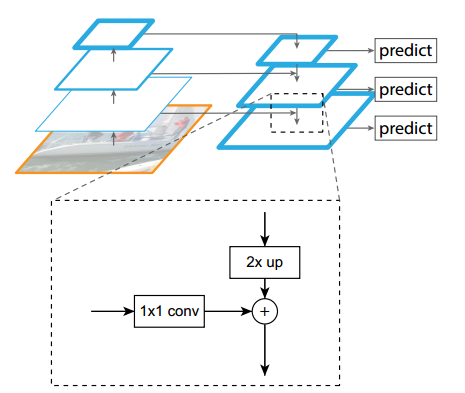
代码实现流程是:
- 将c2 c3 c4 c5 4个特征图全部经过各自1x1卷积进行通道变换变成m2~m5,输出通道统一为256
- 从m5开始,先进行2倍最近邻上采样,然后和m4进行add操作,得到新的m4
- 将新m4进行2倍最近邻上采样,然后和m3进行add操作,得到新的m3
- 将新m3进行2倍最近邻上采样,然后和m2进行add操作,得到新的m2
- 对m5和新的融合后的m4~m2,都进行各自的3x3卷积,得到4个尺度的最终输出P5~P2
- 将c5进行3x3且stride=2的卷积操作,得到P6,目的是提供一个感受野非常大的特征图,有利于检测超大物体
到目前为止就实现了c2~c5 4个特征图输入,P2~P6 5个特征图输出。
1.2 RPN改动
原始faster rcnn的RPN部分是一个输出特征图,现在变成了5个输出图了,为了适应这种变换,anchor的设置进行了适当修改,原因是FPN输出的多尺度信息可以帮助区分不同大小的问题,也就是说有了多尺度输出后可以实现stride大的输出图仅仅检测大物体,stride小的输出图仅仅检测小物体,每一层就不再需要那么多anchor了,其配置如下:
anchor_generator=dict(type='AnchorGenerator',scales=[8],ratios=[0.5, 1.0, 2.0],strides=[4, 8, 16, 32, 64]),
一共包括5个输出特征图,且stride小的特征图负责检测小物体,那么其anchor也要设置的比较小,方便匹配感受野。可以看出,每个特征图位置都是预测3个anchor,不再是原始的15个。整个RPN网络由原来的单尺度预测变成了多尺度预测,其余地方没有进行任何修改。
1.3 RCNN改动
其改动发生在roipool层运行前。原来RPN输出就是一个特征图,假设其输出1000个roi,直接去该特征图上面切割即可,但是现在特征图变成了5个,那么对于每个roi应该切割哪个特征图呢?其可视化图如下:
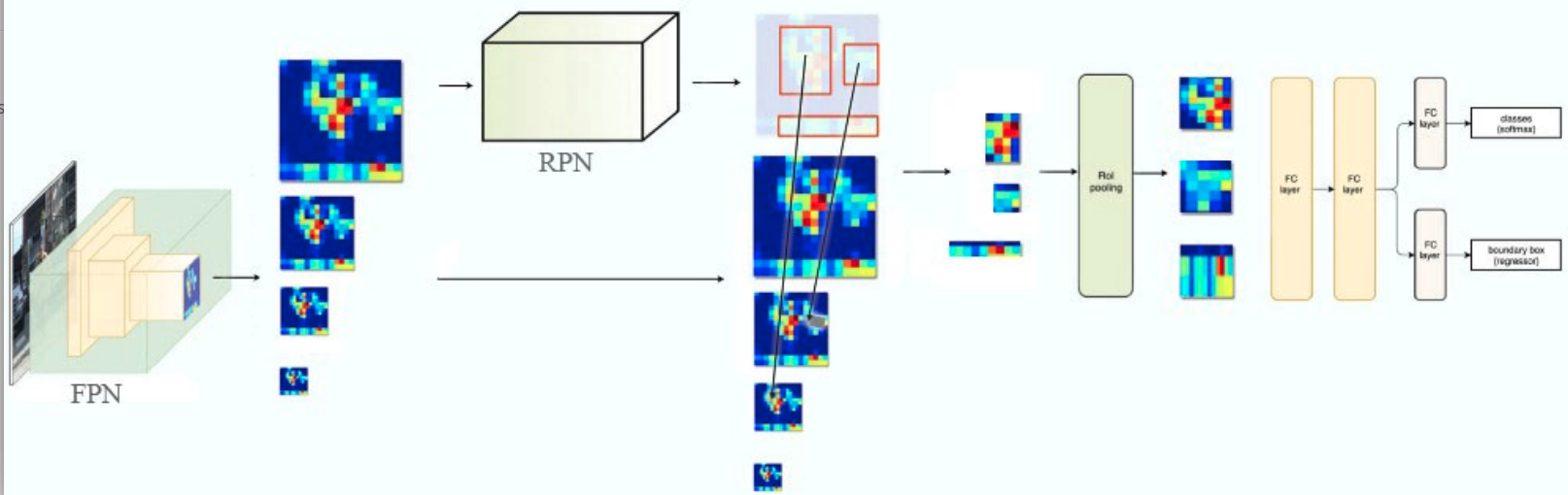
很多人可能有疑问:假设某个proposal是由第4个输出层检测出来的,为啥该proposal不是直接去该特征图层切割就行,还需要重新映射?其实原因非常简单,因为这些proposal相当于是RPN测试阶段检测出来的,大部分proposal可能符合前面设定,但是也有很多不符合的,不然为啥后面有很多论文提出自适应gt bbox分配对应预测层的改进呢?也就是说测试阶段上述一致性设定不一定满足,还需要重新映射。
本文所提映射规则公式为:

上述设置k0=4,通过公式可以算出Pk,具体是:
- wh>=448x448,则分配给P5
- wh<448x448并且wh>=224x224,则分配给P4
- wh<224x224并且wh>=112x112,则分配给P3
- 其余分配给P2
可以看出不包括P6,原因是P6在rcnn中是不用的(rpn用),原则依然是roi面积大的分配给stride大的层。
def map_roi_levels(self, rois, num_levels):"""Map rois to corresponding feature levels by scales.- scale < finest_scale * 2: level 0- finest_scale * 2 <= scale < finest_scale * 4: level 1- finest_scale * 4 <= scale < finest_scale * 8: level 2- scale >= finest_scale * 8: level 3"""scale = torch.sqrt((rois[:, 3] - rois[:, 1]) * (rois[:, 4] - rois[:, 2]))target_lvls = torch.floor(torch.log2(scale / self.finest_scale + 1e-6))target_lvls = target_lvls.clamp(min=0, max=num_levels - 1).long()return target_lvls
其中finest_scale=56,num_level=5,后面的操作就没有任何区别了。
2 总结
faster rcnn引入FPN后整个算法就比较成熟了,也就是我们现在经常看到的模样。一旦引入FPN,那么多尺度预测就自然而然会考虑,对整个目标检测算法都带来了巨大的提升,特别是小物体检测性能,并且FPN作为一个通用即插即用组件不仅可以应用于目标检测,还可以应用于其余领域。不得不佩服FAIR的论文,简洁优雅且通用。
