@huanghaian
2020-09-25T10:51:59.000000Z
字数 6776
阅读 3283
mmdetection最小复刻版(二):RetinaNet和YoloV3分析
mmdetection
上一篇文章主要是分析了整体流程,知乎链接为https://zhuanlan.zhihu.com/p/252616317 ,或者公众号文章。本文开始分析具体算法,主要是RetinaNet和已经实现的YoloV3代码。下一篇分析基于mmdetection-mini的数据分析神兵利器。
说到这两个算法,我想做目标检测的没有不熟悉的,知乎分析文章不下20篇,所以我这里写的都是我认为的核心部分,不会重头解读。主要是配合mmdetection-mini代码来说,要说本文亮点的话,可以简单归纳为:
- 算法最核心部分解读,比较精简
- 结合工具进行focal loss理论分析,理论实践两不误
- mmdetection中的yolov3复现解读(目前网上还没有人写)以及我的个人看法
- 训练过程正样本可视化
本文所有内容,在代码中都有注释。
github: https://github.com/hhaAndroid/mmdetection-mini
欢迎 star
1 骨架网络中的frozen_stages
大部分目标检测算法的骨架都是resnet,而在mmdetection中通常都会采用frozen_stages参数固定前n个stage的权重。因为研究表明前几层特征都是基础通用特征,可以不用重头训练,不仅可以省点内存也可以加速收敛。那么具体实现是:
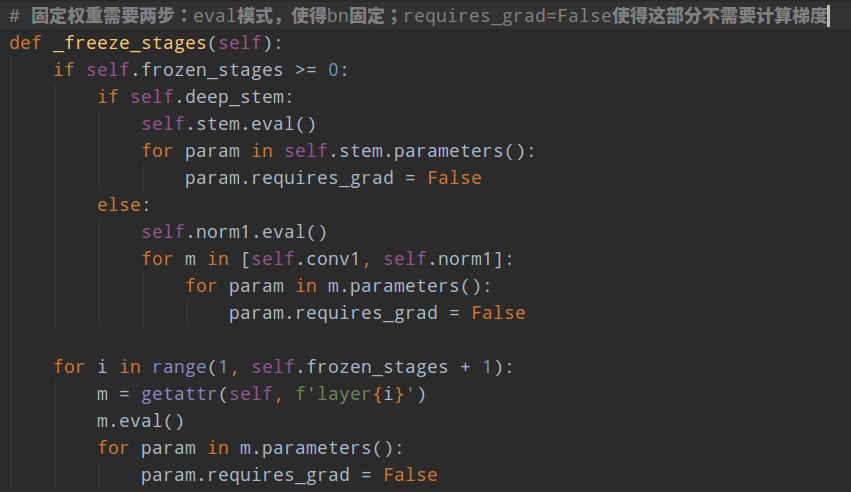
在pytorch中固定权重需要两个步骤,
第一步是开启eval模式,该模式仅仅会影响bn或者dropout等算子,对于bn,在开启eval后,BN的均值和方差参数将不再更新,而是固定采用以前训练的全局值
第二步是将梯度设置为false,也就是这部分网络不计算梯度。eval模式仅仅让bn的均值和方差不改变,但是其和卷积一样还有可训练参数,此时为了全部固定,需要把参数的requires_grad设置为false。
其中的deep_stem是resnet的改进版本,例如resnet_d。
在mmdetection的具体实现中还需要注意一个细节:
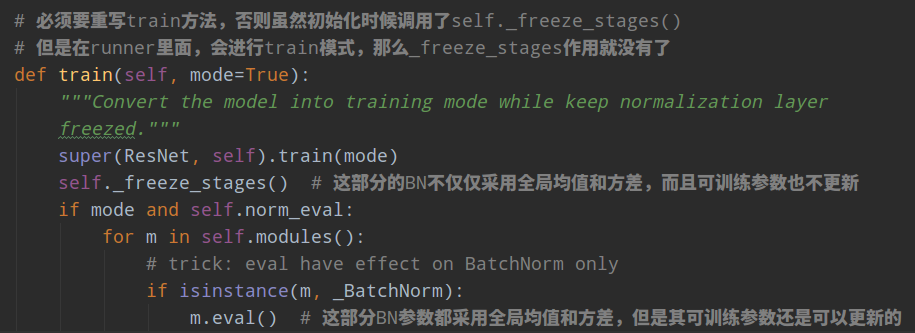
必须要重写train方法,否则虽然初始化时候调用了self._freeze_stages(),但是在runner里面,会进行train模式,那么_freeze_stages作用就没有了。
2 RetinaNet代码分析
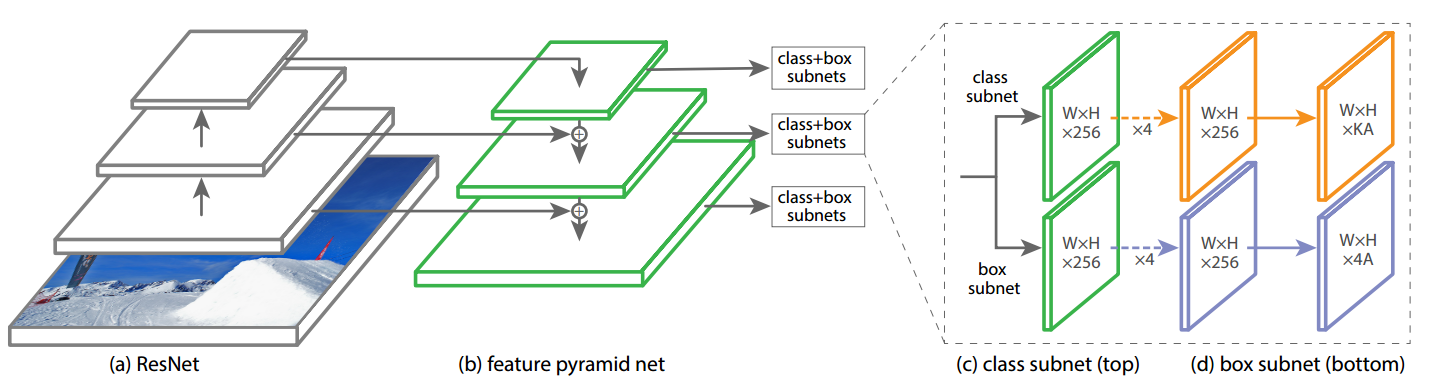
retinanet非常经典,包括骨架resnet+FPN层+输出head,一共包括5个多尺度输出层。
2.1 网络结构分析
- resnet输出是4个特征图,按照特征图从大到小排列,分别是c2 c3 c4 c5,stride=4,8,16,32。Retinanet考虑计算量仅仅用了c3 c4 c5。
- 先对这三层进行1x1改变通道,全部输出256个通道;然后经过从高层到底层的最近邻上采样add操作进行特征融合,最后对每个层进行3x3的卷积,得到p3,p4,p5特征图。
- 还需要构建两个额外的输出层stride=64,128,首先对c5进行3x3卷积且stride=2进行下采样得到P6,然后对P6进行同样的3x3卷积且stride=2,得到P7
整个FPN层都不含BN和relu,并且retinanet的head部分计算量很大,其输出头包括不进行分类和检测参数共享的4个卷积层。为啥要设置这么重的head,论文里面有说明,主要是处于性能原因吧。
2.2 anchor分析

原理就不写了,请看知乎文章:https://zhuanlan.zhihu.com/p/252616317
每个预测层都有9个anchor,其中scales参数是内部代码写死的,你只能传入个数。但是anchor高宽比例是可以设置的。
2.3 正样本anchor可视化分析
在知乎文章: https://zhuanlan.zhihu.com/p/161463275 中我们引入了可视化手段查看anchor匹配情况。
但是这篇文章分析有个弊端:没法看出anchor被分配到哪个层,故在mmdetection-mini本框架中进行了改进,并且无缝切换,不再需要大家自己新增代码。
使用方式非常简单,就两步:
- 在cfg里面的train_cfg内部把debug设置为True
- train_pipeline的Collect的meta_keys需要新增img字段
如果你是用我框架中的配置,那么只需要第一步即可。
效果如下:

白色bbox是gt 值,其余颜色是正样本anchor。从0-4是从大特征图(检测小物体)到小特征图(检测大物体)的。可以发现图中有两个gt bbox,其中网球排被分配到第1层负责预测,人分配到第2层负责预测了。当然可能存在某个gt bbox分配到多个层进行预测。
通过正样本可视化分析,一来可以确定代码是否有问题;二来可以查看anchor情况。
2.4 bias初始化分析
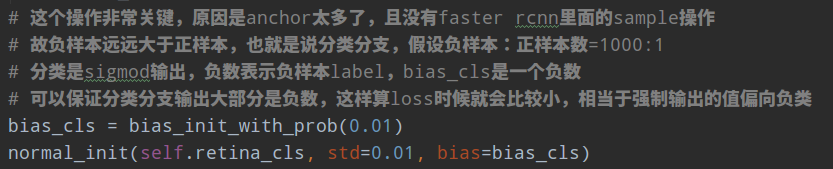
在Retinanet中,其分类分支初始化bias权重设置非常关键。那么原因是啥?
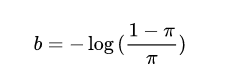
pi默认为0.01。
这个操作非常关键,原因是anchor太多了,且没有faster rcnn里面的sample操作,故负样本远远大于正样本,也就是说分类分支,假设负样本:正样本数=1000:1。分类是sigmod输出,其输出的负数表示负样本label,如果某个batch的分类输出都是负数,那么也就是预测全部是负类,这样算loss时候就会比较小,相当于强制输出的值偏向负类。
简单来说就是对于一个分类任务,一个batch内部几乎全部是负样本,如果预测的时候没有偏向,那么Loss肯定会非常大,因为大部分输出都是错误的,现在强制设置预测为负类,这样开始训练时候loss会比较小。这个操作会影响初始训练过程。
我们可以通过对分类分支的特征图进行计算norm max min,并打印操作就看出:
当bias=0,也就是没有偏向,则开始训练时候:
tensor(33.2100, device='cuda:0', grad_fn=<NormBackward0>) tensor(0.0621, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-0.0606, device='cuda:0', grad_fn=<MinBackward1>)
tensor(16.8493, device='cuda:0', grad_fn=<NormBackward0>) tensor(0.0466, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-0.0516, device='cuda:0', grad_fn=<MinBackward1>)
tensor(7.5828, device='cuda:0', grad_fn=<NormBackward0>) tensor(0.0308, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-0.0274, device='cuda:0', grad_fn=<MinBackward1>)
tensor(3.4662, device='cuda:0', grad_fn=<NormBackward0>) tensor(0.0240, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-0.0219, device='cuda:0', grad_fn=<MinBackward1>)
tensor(1.3125, device='cuda:0', grad_fn=<NormBackward0>) tensor(0.0169, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-0.0148, device='cuda:0', grad_fn=<MinBackward1>)
当bias采用上述公式:
tensor(30403.4023, device='cuda:0', grad_fn=<NormBackward0>) tensor(-4.5390, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-4.6472, device='cuda:0', grad_fn=<MinBackward1>)
tensor(15201.4629, device='cuda:0', grad_fn=<NormBackward0>) tensor(-4.5452, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-4.6417, device='cuda:0', grad_fn=<MinBackward1>)
tensor(7600.7085, device='cuda:0', grad_fn=<NormBackward0>) tensor(-4.5635, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-4.6303, device='cuda:0', grad_fn=<MinBackward1>)
tensor(3976.3052, device='cuda:0', grad_fn=<NormBackward0>) tensor(-4.5704, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-4.6225, device='cuda:0', grad_fn=<MinBackward1>)
tensor(2063.2097, device='cuda:0', grad_fn=<NormBackward0>) tensor(-4.5809, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-4.6108, device='cuda:0', grad_fn=<MinBackward1>)
tensor(30403.4824, device='cuda:0', grad_fn=<NormBackward0>) tensor(-4.5447, device='cuda:0', grad_fn=<MaxBackward1>) tensor(-4.6500
可以明显发现,设置0.01的参数后输出tensor的值基本上都是负数,符合预期。
2.5 focal Loss分析
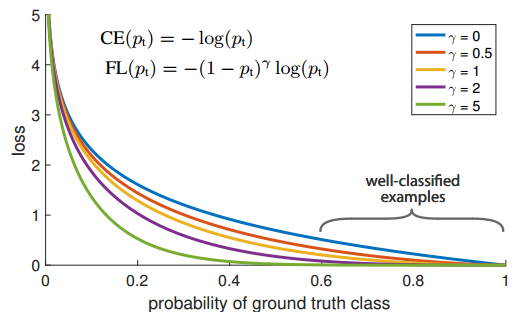
focal loss公式非常简单,但是背后的思想很牛。核心就是beta参数。
FL本质上解决的是将大量易学习样本的loss权重降低,但是不丢弃样本,突出难学习样本的loss权重,但是因为大部分易学习样本都是负样本,所以还有一个附加功能即解决了正负样本不平衡问题。其是根据交叉熵改进而来,本质是dynamically scaled cross entropy loss,直接按照loss decay掉那些easy example的权重,这样使训练更加bias到更有意义的样本中去,说通俗点就是一个解决分类问题中类别不平衡、分类难度差异的一个 loss。
注意上面的公式表示label必须是one-hot形式。只看图示就很好理解了,对于任何一个类别的样本,本质上是希望学习的概率为1,当预测输出接近1时候,该样本loss权重是很低的,当预测的结果越接近0,该样本loss权重就越高。而且相比于原始的CE,这种差距会进一步拉开。由于大量样本都是属于well-classified examples,故这部分样本的loss全部都需要往下拉。
完整的focal loss为:
有两个参数:alpha和beta。核心就是beta,为了研究这两个参数的作用,我在mmdetection-mini中嵌入了loss分析工具,具体见框架说明文档。
代码跑完会出现:
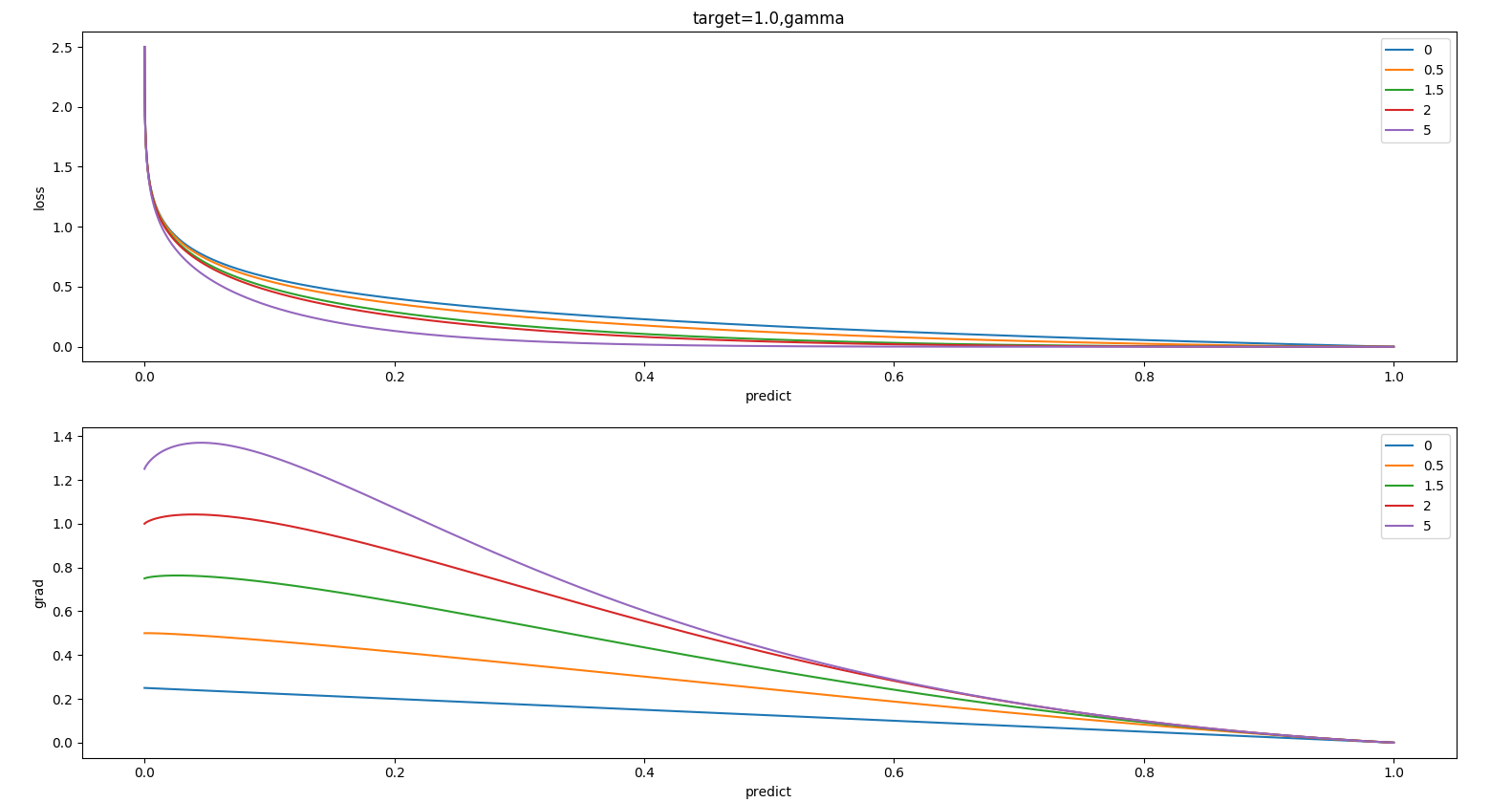
先看alpha,随着alpha增加,整个梯度会变大,也就是alpha属于正负样本的加权参数,值越大,正样本的权重越大。再看beta,其有focal效应,可以控制难易样本权重,值越大,对分类错误样本梯度越大(难样本权重大),focal效应越大,这个参数非常关键。
后面会有问题专门对这些工具进行文章详细说明。主要包括实现原理、使用方法和扩展方式。
3 YoloV3代码分析
这里分析的yolov3是mmdetection复现的,而不是原版的。实现上有区别,我后面会细说。由于yolov3实在是太多解读了,我这里只说和原版的区别。其最大区别就是正负样本定义上面,其不是采用标准的分配策略,而是结合标准分配策略+faster rcnn里面的max_iou_assigner,其本意是增加更多的正样本,加快收敛。但是他有几个关键细节没有实现。
3.1 正负样本定义
首先要说明下yolov3的正负样本定义。具体参考知乎文章:https://zhuanlan.zhihu.com/p/138824387
总结来说匹配规则是:保证每个bbox一定有一个唯一的anchor进行对应,匹配规则就是IOU最大。具体就是:对于某个ground truth,首先要确定其中心点要落在哪个cell上,然后计算这个cell的5个anchor与ground truth的IOU值,计算IOU值时不考虑坐标,只考虑形状(因为anchor没有坐标xy信息),所以先将anchor与ground truth的中心点都移动到同一位置(原点),然后计算出对应的IOU值,IOU值最大的那个先验框anchor与ground truth匹配,对应的预测框用来预测这个ground truth。
yolov3的核心就是保证每个gt bbox一定有一个唯一的anchor进行对应,不需要考虑多个anchor和某个gt bbox匹配情况,也不存在某个gt bbox在多层上面预测,属于最简策略。这种分配策略的好处是简单,但是缺点是正样本太少了,收敛非常慢。
而mmdetection-mini实现的策略属于原版yolov3+faster rcnn中的max_iou_assigner策略。简单来说就是主要采用了max_iou_assigner策略,但是有一个额外的gtbbox中心必须网格中心的限制。其余地方就没有区别了。
大家可以看我的代码注释,核心就是多了一个字段box_responsible_flags,用于判断哪些位置是有gt bbox中心落在的位置,所有的max_iou_assigner策略都需要同时满足box_responsible_flags属性。这种设置的好处是正样本会更多,缺点嘛?暂时不知道。
还有一个细节需要注意:在是否需要对齐anchor和gt bbox上面,本文实现不一样,其采用了max iou assigner类似的原则,其anchor是有坐标xy信息,故其没有将anchor和gt bbox中心对齐后再进行iou的操作,而是直接计算含有xy坐标的anchor和gt bbox的iou。虽然没有对齐,但是由于每个位置的3个anchor中心点是相同的,计算iou的时候是公平的,故可能这两种算法得到的结果没有啥区别。
同样,我们可以通过开启debug模式来直观理解其分配策略:
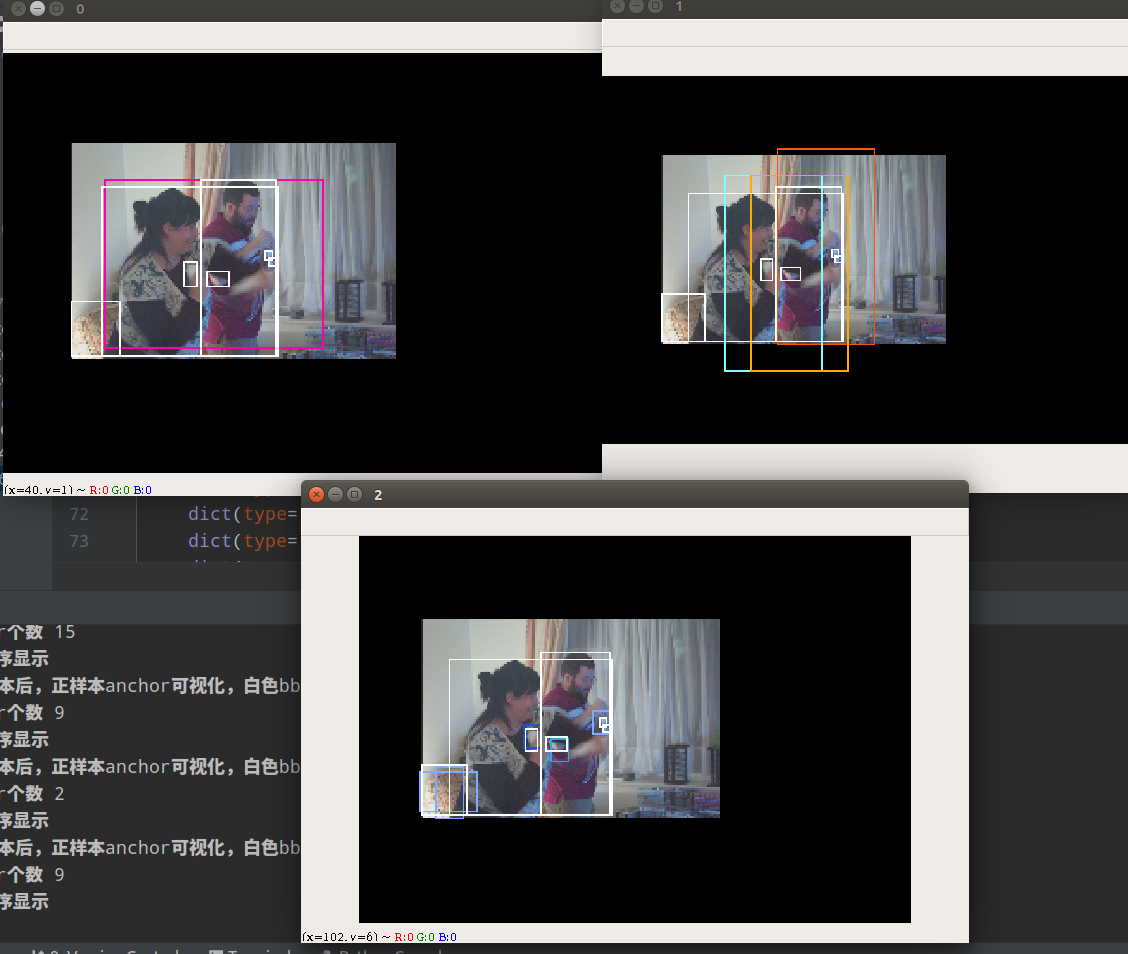
通过这个图可以明显看出其设计思想:
- 对gt bbox没有限制只能在某个层预测
- 对anchor没有限制,可以多个anchor预测同一个物体
从0-2是从小特征图(检测大物体)到大特征图(检测小物体)顺序显示
但是mmdetection中的yolov3有两个核心特性没有实现:
- confidence分支的所有负样本全部算是背景,当iou比较大,通常是0.75,但不是该网格负责的情况下,也是当做负样本,但是在原版yolo中是会当做忽略样本的
- 大小物体没有进行加权
在原版中由于bbox的宽高不一致,表现在数值上就会时大时小,对于l1或者l2来说,梯度就不一样大,这是不好的,因为极端情况就是网络只学习大物体,小物体由于梯度太小被忽略了。虽然前面引入了log,但是还可以进一步克服,具体就是在基于gt的宽高, 给大小物体引入一个不一样大的系数,具体是 (2 - truth.w*truth.h)(这里w和h都归一化到(0,1)),这样对于尺度较小的boxes其权重系数会更大一些,可以放大误差,该项权重和上再乘上一个可变因子。
我个人觉得这两个策略还是很关键的,现在粗暴的丢弃,我觉得不妥。
纵观整个yolov3代码,写的还是蛮好的,和mmdetection的设计思想完全贴合了,代码可读性比较高。后面我会进行一些实验来验证我的想法。
再次贴一下
github: https://github.com/hhaAndroid/mmdetection-mini
欢迎 star
