@huanghaian
2020-10-21T08:16:33.000000Z
字数 7071
阅读 3995
mmdetection最小复刻版(六):FCOS深入可视化分析
mmdetection
0 概要
论文名称: FCOS: A simple and strong anchor-free object detector
论文地址: https://arxiv.org/pdf/2006.09214v3.pdf
论文名称: FCOS: Fully Convolutional One-Stage Object Detection
论文地址: https://arxiv.org/pdf/1904.01355v1.pdf
官方代码地址:https://github.com/aim-uofa/AdelaiDet/
FCOS是目前最经典优雅的一阶段anchor-free目标检测算法,其模型结构主流、设计思路清晰、超参极少和不错的性能使其成为后续各个改进算法的baseline,和retinanet一样影响深远,故非常有必要对其进行深入分析。
一个大家都知道的问题,anchor-base的缺点是:超参太多,特别是anchor的设置对结果影响很大,不同项目这些超参都需要根据经验来确定,难度较大。 而anchor-free做法虽然还是有超参,但是至少去掉了anchor设置这个最大难题。fcos算法可以认为是point-base类算法也就是特征图上面每一个点都进行分类和回归预测,简单来说就是anchor个数为1的且为正方形anchor-base类算法。
在目前看来,任何一个目标检测算法的核心组件都包括backbone+neck+多尺度head+正负样本定义+正负样本平衡采样+loss设计,除了正负样本平衡采样不一定有外,其他每个环节都是目前研究重点,到处存在不平衡问题,而本文重点是在正负样本定义上面做文章。
贴一下github:
https://github.com/hhaAndroid/mmdetection-mini
欢迎star
1 fcos和retinanet算法对比分析
FCOS结构和retinanet几乎相同,但是有细微差别,下面会细说。

不清楚retinanet结构的请看:https://www.zybuluo.com/huanghaian/note/1742594
retinanet的结构大概可以总结为:
- resnet输出是4个特征图,按照特征图从大到小排列,分别是c2 c3 c4 c5,stride=4,8,16,32。Retinanet考虑计算量仅仅用了c3 c4 c5。
- 先对这三层进行1x1改变通道,全部输出256个通道;然后经过从高层到底层的最近邻上采样add操作进行特征融合,最后对每个层进行3x3的卷积,得到p3,p4,p5特征图。
- 还需要构建两个额外的输出层stride=64,128,首先对c5进行3x3卷积且stride=2进行下采样得到P6,然后对P6进行同样的3x3卷积且stride=2,得到P7
下面介绍fcos和retinanet算法的区别。
1.1 resnet的style模式区别
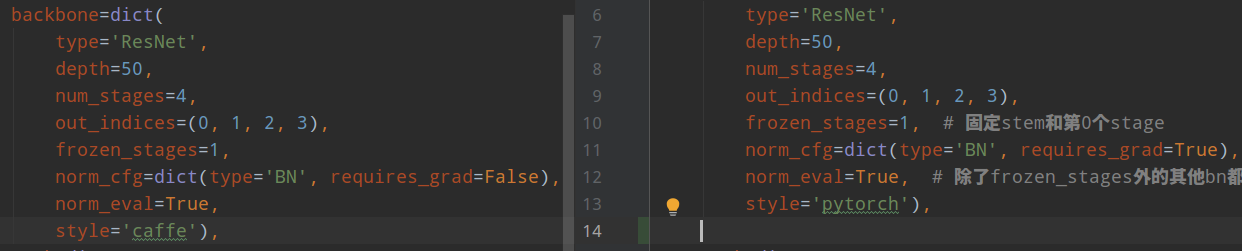
左边是fcos配置,右边是retinanet配置。
(1) resnet骨架区别
在resnet骨架中,style='caffe'参数和style='pytorch'的差别就在Bottleneck模块,该模块的结构如下:
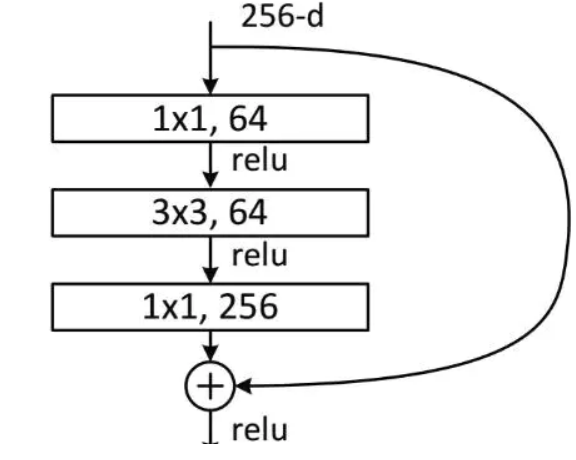
主干网络是标准的1x1-3x3-1x1结构,考虑stride=2进行下采样的场景,对于caffe模式来说,stride参数放置在第一个1x1卷积上,对于pytorch模式来说,stride放在第二个3x3卷积上:
if self.style == 'pytorch':
self.conv1_stride = 1
self.conv2_stride = stride
else:
self.conv1_stride = stride
self.conv2_stride = 1
唯一区别就是这个。至于为啥存在caffe模式,是因为早期mmdetection采用了detectron权重(不想重新训练imagenet),其早期采用了caffe2来构建模型,后续detectron2才切换到pytorch中,属于历史遗留问题。
(2) 骨架训练策略区别
注意看上面的对比配置,可以发现除了上面说的不同外,在caffe模式下,requires_grad=False,也就是说resnet的所有BN层参数都不更新并且全局均值和方差也不再改变,而在pytorch模式下,除了frozen_stages的BN参数不更新外,其余层BN参数还是会更新的。我不清楚为啥要特意区别。
总的来说,在caffe模式下训练的内存肯定会少一些,但是效果究竟谁的更好,看了下对比结果发现差不多。
1.2 FPN结构区别
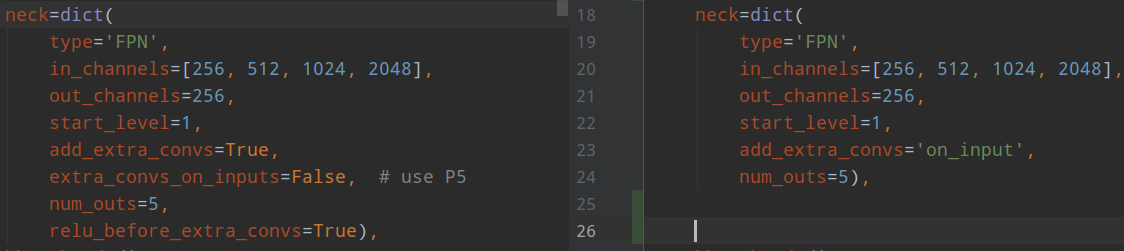
和retinanet相比,fcos的FPN层抽取层也是不一样的,需要注意。
retinanet在得到p6,p7的时候是采用c5层特征进行maxpool得到的(对应参数是add_extra_convs='on_input',),而fcos是从p5层抽取得到的(对应参数是extra_convs_on_inputs=False),而且其还有relu_before_extra_convs=True参数,也就是p6和p7进行卷积前,还会经过relu操作,retinanet的FPN没有这个算子(C5不需要是因为resnet输出最后就是relu)。从实验结果来看,从p5抽取的效果是好于c5的,baseline的mAP从38.5提高到38.9。
1.3 数据归一化区别
当切换style='caffe'时候,需要注意图片均值和方差也改变了:
# pytorch
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True
# caffe
mean=[103.530, 116.280, 123.675], std=[1.0, 1.0, 1.0], to_rgb=False
1.4 head模块区别
和retinanet相比,fcos的head结构多了一个centerness分支,其余也是比较重量级的两条不共享参数的4层卷积操作,然后得到分类和回归两条分支。
2 fcos算法深入分析
2.1 fcos输出格式

fcos是point-base类算法,对于特征图上面任何一点都回归其距离bbox的4条边距离,
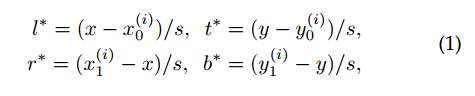
假设x是特征图上任意点坐标,x0y0x1y1是某个gt bbox在原图上面的坐标,那么4条边的边界(都是正数)其实很好算,公式如上所示。需要注意的是由于大小bbox且数值问题,一般都会对值进行变换,也就是除以s,主要目的是压缩预测范围,容易平衡分类和回归Loss权重。
如果某个特征图上面点处于多个bbox重叠位置,则该point负责小bbox的预测。
2.2 正负样本定义
一个目标检测算法性能的优异性,最大影响因素就是如何定义正负样本。而fcos的定义方式非常mask sense,通俗易懂。主要分为两步:
(1) 设置regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),用于将不同大小的bbox分配到不同的FPN层进行预测即距离4条边的最大值在给定范围内
(2) 设置center_sampling_ratio=1.5,用于确定对于任意一个输出层距离bbox中心多远的区域属于正样本,该值越大,扩张比例越大,正样本区域越大
为了说明其重要性,作者还做了很多分析实验。
(1) 为啥需要第一步?
regress_ranges的意思是对于不同层仅仅负责指定范围大小的gt bbox,例如最浅层输出,其范围是0-64,表示对于该特征图上面任何一点,假设其负责的gt bbox的label值是left、top、right和bottom,那么这4个值里面取max必须在0-64范围内,否则就算背景样本。
为啥需要限制层回归范围?目的应该有以下几点:
1. 在SNIP论文中说到,CNN对尺度是非常敏感的,一个层负责处理各种尺度,难度比较大,采用FPN来限制回归范围可以减少训练难度
2. 提高best possible recall
通常我们知道anchor设置的越密集,理论上召回率越高,现在fcos是anchor-free,那么需要考虑理论上的最好召回率是多少,如果理论值都比较低,那肯定性能不行。best possible recall定义为训练过程中所有GT的最大召回率,如果训练过程中一个GT被某个anchor或者location匹配上那么就认为被召回了。

low-quality matches意思是retinanet配置中的min_pos_iou参数,默认是0。在不使用low-quality matches时候,对于某些gt,如果其和anchor的最大iou没有超过正样本阈值,那么就是背景样本,一开启low-quality matches则可能能够捞回来,开启这个操作可以显著提高BPR,从表中也可以看出,从88.16变成99.32。至于在ALL模式下为啥不是1,作者分析原因是有些bbox特别小并且挨着,经过下采样后在同一个位置,导致出现相互覆盖。
对于FCOS,即使在不开启FPN时候,其BPR也很高,因为其bbox中心范围内都算正样本,BPR肯定比较高,在开启FPN后和retinanet相比差别不大,对最终性能没有影响。
为了强调FPN层的作用性,作者还对模糊样本数进行分析:
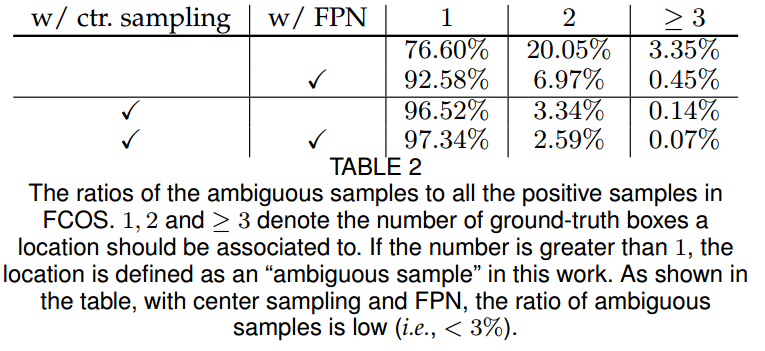
模糊样本就是某个特征图位置处于多个gt bbox重叠位置,也就是图表中的大于1个数。可以发现在开启FPN后,模糊样本明显减少,因为不同大小的gt bbox被强制分配到不同层预测了,当结合中心采样策略后可以进一步提高。
(2) 为啥需要第二步?
中心采样的作用有两个
1. 减少模糊样本数目
2. 减少标注噪声干扰
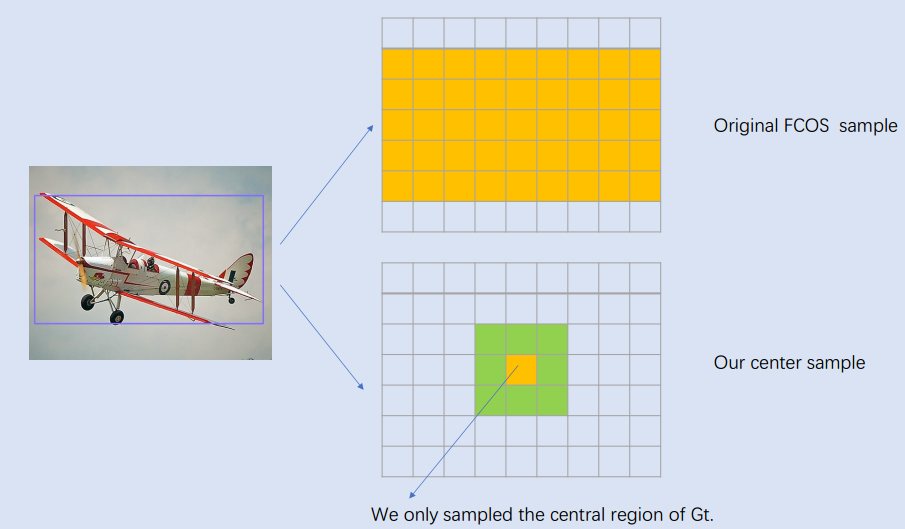
bbox标注通常都有噪声或者会框住很多无关区域,如果这些无关区域也负责回归则比较奇怪,这其实是目前非常常用的处理策略,在文本检测领域广泛应用。

(a)是早期做法也就是对于本文不采用中心采样策略的做法;(b)是本文做法;(c)是centernet做法;(d)是centernet改进论文做法。从这里可以看出,(d)的做法应该比fcos更加mask sense,可解释性更强。
总的来说,作者认为FCOS的功臣可以归功于FPN层的多尺度预测和中心采样策略。
(3) 核心代码分析
为了方便理解中心采样策略代码,我对代码进行了分解,具体在tools/fcos_analyze/center_samper_demo.py。其核心代码逻辑是:
(1) 利用meshgrid函数获取特征图上面每个点的2d坐标
(2) 扩展维度,使得所有参数计算的tensor维度相同,方便后续计算
(3) 如果不采用中心采样策略,则直接对特征点上面每个点计算和所有gt bbox的left/top/right/bottom值。然后取4个值中的最小值,如果小于0,则该point至少有一条边不再bbox内部,属于背景point样本,否则就是正样本
(4) 如果采用中心采用策略,则基于gt bbox中心点进行扩展出正方形,扩展范围是center_sample_radius×stride,正方形区域就当做新的gt bbox,然后和(3)步骤一样计算正样本即可。还需要注意一个细节:如果扩展比例过大,导致中心采样区域超过了gt bbox本身范围了,此时需要截断操作
以上操作就可以确定哪些区域是正样本了,我仿真的结果如下所示:
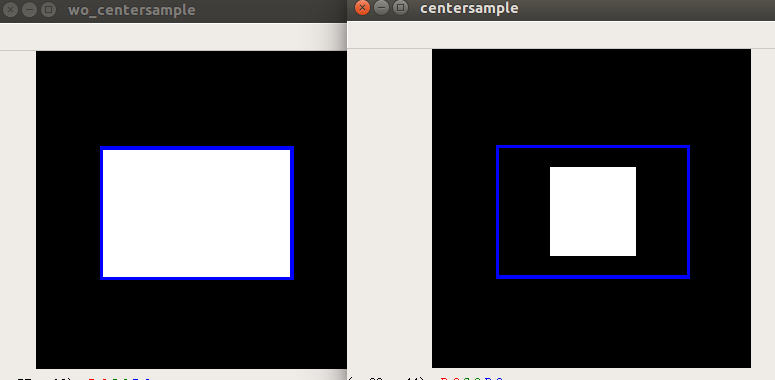
蓝色是gt bbox,白色区域是正样本区域。从这里也可以看出,其实FCOS中心采样策略还有改进空间,因为他的正样本区域没有考虑gt bbo宽高信息,对于图片中包含人这种长宽比比较大的场景,这种做法其实不好。需要注意的是为了可视化代码简单,我是直接对特征图mask进行上采样得到的,实际上在原图上对应的白色区域是一个点,而不是一个白块。
(4) 理解纠正
我们再来看下上面的一句话:
(1) 设置regress_ranges=((-1, 64), (64, 128), (128, 256), (256, 512),(512, INF),用于将不同大小的bbox分配到不同的FPN层进行预测
(2) 设置center_sampling_ratio=1.5,用于确定对于任意一个输出层距离bbox中心多远的区域属于正样本,该值越大,扩张比例越大,正样本区域越大
看起来好像没问题,后来我通过正样本可视化分析发现我上面说法是错误的。正确的应该是:
(1) 对于任何一个gt bbox,首先映射到每一个输出层,利用center_sampling_ratio值计算出该gt bbox在每一层的正样本区域以及对应的left/top/right/bottom的target
(2) 对于每个输出层的正样本区域,遍历每个point位置,计算其max(left/top/right/bottom的target)值是否在指定范围内,不再范围内的认为是背景
上面两个写法的顺序变了,结果也差别很大,最大区别是第二种写法可以使得某一个gt bbox在多个预测层都是正样本,而第一种做法先把gt bbox映射到预测层后面才进行中心采样,第二种做法相比第一种做法可以增加很多正样本区域。很明显,第二种才是正确的。
通过正样本可视化分析可以发现:
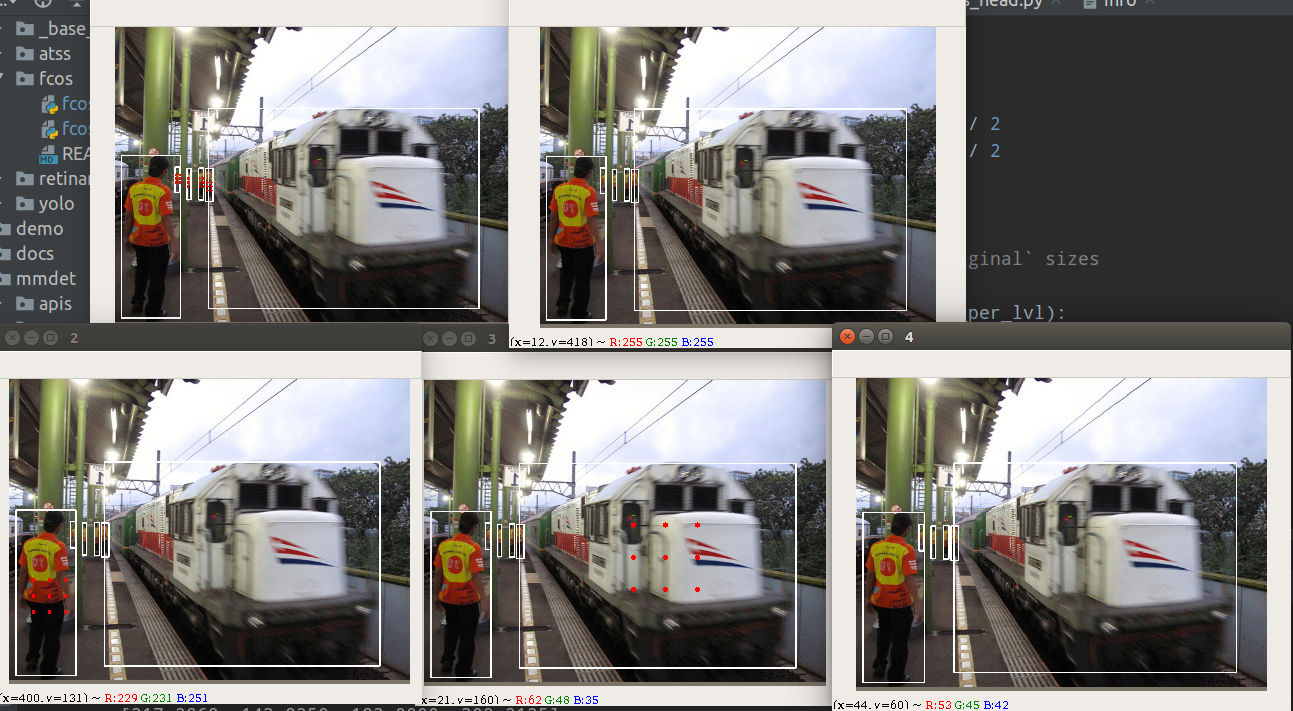
红色点表示正样本point,其中0-4表示stride=[8,16,32,64,128]的输出特征图,代表从小到大物体的预测。

可以看出,其是完全基于回归距离来定义正负样本位置的,但是从语义角度来看,这种设计不够make sense,因为红色点不是对称分布,特别是上标为2的小象内部不算正样本,比较奇怪。从语义角度理解不合理,但是从回归数值范围理解是很合理的。
正样本可视化代码我已经新增到mmdetection-mini中了,只需要对应train_cfg里面的debug设置为True即可可视化。
2.3 loss计算
在确定了每一层预测层的正负样本后就可以计算loss了,对于分类分支(class_num,h',w'),其采用的是FocalLoss,参数和retinanet一样。对于回归分支(4,h',w'),其采用的是GIou loss,也是常规操作,回归分支仅仅对正样本进行监督。
在这种设置情况下,作者发现训推理时候会出现一些奇怪的bbox,原因是对于回归分支,正样本区域的权重是一样的,同等对待,导致那些虽然是正样本但是离gt bbox中心比较远的点对最终loss产生了比较大的影响,其实这个现象很容易想到,但是解决办法有多种。

现象应该和(b)图一致,在靠近物体中心的四周会依然会产生大量高分值的输出。
作者解决办法是引入额外的centerness分类分支(1,h',w')来抑制,该分支和bbox回归分支共享权重,仅仅在bbox head最后并行一个centerness分支,其target的设置是离gt bbox中心点越近,该值越大,范围是0-1。虽然这是一个回归问题,但是作者采用的依然是ce loss。很多人反映该分支训练时候loss下降的特别慢,其实这是非常正常的,这其实是整图回归问题,在每个点处都要回归出对应值其实是一个密集预测问题,难度是很大的,loss下降慢非常正常。
需要特别注意的是centerness分支也是仅仅对正样本point进行回归。
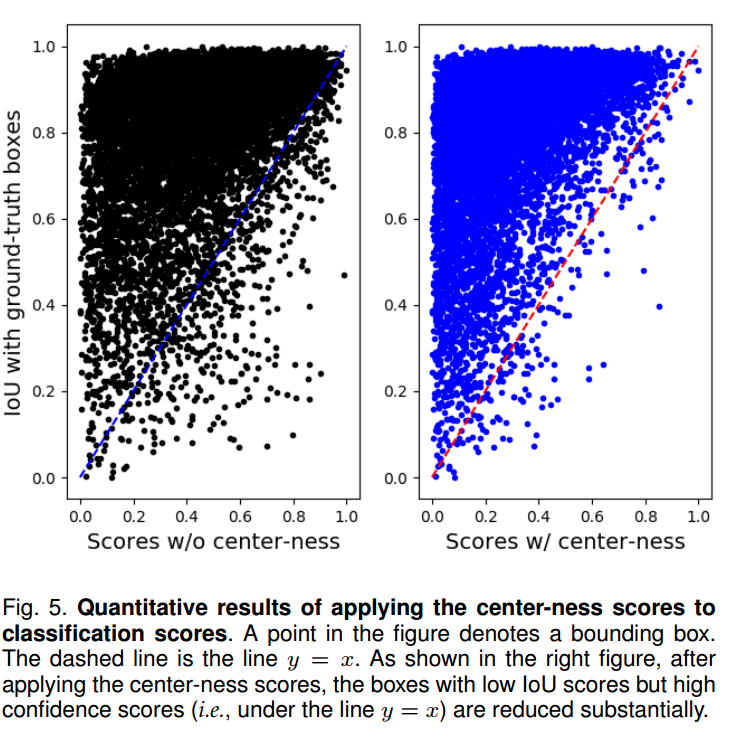
通上图可以看出,在引入centerness分支后,将该预测值和分类分支结果相乘得到横坐标分支图,纵坐标是bbox和gt bbox的iou,可以明显发现两者的一致性得到了提高,对最终性能有很大影响。至于这个图自己如何绘制,有个比较简单的办法:
(1) 利用框架进行测试,保存coco验证集的预测json格式
(2) 在写一份离线代码读取该预测json和标注的json,遍历每张图片的预测bbox和gt bbox
(3) 对于每张图片的结果,遍历预测bbox,然后和所有gt bbox计算最大iou,该值就是纵坐标,横坐标就是预测分值(cls*centerness)
(4) 所有数据都处理完成就可以上述图表
由于代码比较简单,我这里就不写了。
对于任何一个点,其centerness的target值通过如下公式计算:
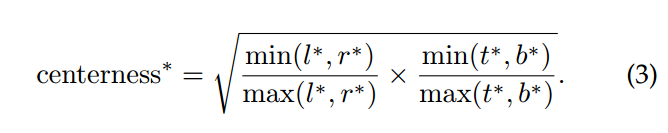
tools/fcos_analyze/center_samper_demo.py仿真效果如下所示:
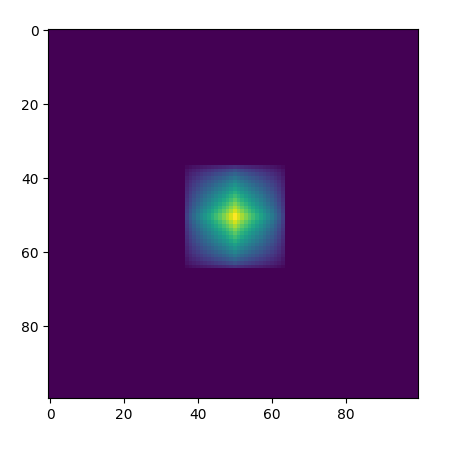
越靠近中心,min(l,r)和max(l,r)越接近1,也就是越大。
2.4 附加内容
fcos代码在第一版和最终版上面修改了很多训练技巧,对最终mAP有比较大的影响,主要是:
(1) centerness 分支的位置
早先是和分类分支放一起,后来和回归分支放一起
(2) 中心采样策略
早先版本是没有中心采样策略的
(3) bbox预测范围
早先是采用exp进行映射,后来改成了对预测值进行relu,然后利用scale因子缩放
(4) bbox loss权重
早先是所有正样本都是同样权重,后来将样本点对应的centerness target作为权重,离GT中心越近,权重越大
(5) bbox Loss选择
早先采用的是iou,后面有更优秀的giou,或许还可以尝试ciou
(6) nms阈值选取
早先版本采用的是0.5,后面改为0.6
这些trick,将整个coco数据集mAP从38.6提高到42.5,提升特别大,新版本的论文中有非常详细的对比实验报告,有兴趣的可以自行阅读。
再次贴一下github:
https://github.com/hhaAndroid/mmdetection-mini
欢迎star
