@huanghaian
2020-04-01T03:29:28.000000Z
字数 5577
阅读 1405
HAMBox
目标检测
论文题目:HAMBox: Delving into Online High-quality Anchors Mining for Detecting Outer Faces
2019年人脸检测冠军模型,百度出品。
论文分析的现象非常好,解决办法也是非常不错,是一个通用的anchor-base补偿策略,可以应用于通用目标检测算法。
0.简介
在目标检测算法中,anchor的设计是一个非常关键的设置,在确定了anchor后,anchor匹配机制也是一个非常关键的操作。但是作者通过实验发现了一种有趣的现象,即不匹配样本anchor(包括负样本anchor和忽略样本anchor)相比正样本anchor而言,居然也有不错的回归能力,在inference时,不匹配样本anchor回归得到的与gt的IoU大于0.5的框占到所有与gt的IoU大于0.5的框中的89%!,虽然在训练过程中被忽略甚至被当做背景。
这个现象说明不匹配的anchor其实也有非常强的回归能力,但是目前的算法都没有考虑这个问题,基于该设定提出了Online High-quality Anchor Mining Strategy (HAMBox),用于显式的帮助outer faces补偿高质量的锚;并且基于高质量anchor策略,进一步提出了Regression-aware Focal Loss;最后引入了一些可以提升的操作,例如ssh等,实现了sota。
1.思想
定义:
(1) high-quality anchor: 如果某个anchor经过网络回归后的框与人脸框的ground truth的iou大于0.5,则称其为高质量anchor。
(2) outer faces:异常人脸,由于人脸尺度过小或者人脸尺度与anchor尺度不匹配,造成训练时匹配不到足够多的Anch(小于阈值K),影响了这些人脸的召回。
(3) matched anchor:在训练时,与目标人脸的 𝐼𝑜𝑈≥0.35 的anchor
(4) unmatched anchor:在训练时,与目标人脸的 𝐼𝑜𝑈<0.35 的anchor。
(5) matched high-quality anchors:指那些在训练阶段是matched anchor,且经过网络回归后是high-quality anchor的集合。
(6) unmatched high-quality anchors: 指那些在训练阶段是unmatched anchor,且经过网络回归后是high-quality anchor的集合。
(7) CPBB: Correctly Predicted Bounding Boxes,如果某个在训练阶段匹配到人脸的anchor经过回归网络后,回归框与gt的iou>0.5,则称其为CPBB,即matched high-quality anchor回归后的bounding box。
不同于 general object detectors 的是,人脸往往 aspect ratios 变化较小(一般是1:1,1:1.5),但是 scale variations 很大,人脸在图片中可能占据大量像素,也可能就几个像素而已。针对这一问题,有的方案是采用 FPN + Dense Anchors 的策略,但这会极大的增加推理耗时。从效率上来说,你设计的 Anchor 越简单高效越好, 论文中采用单一尺度和高宽比的Anchor,这看起来可能会比较简单高效,但实际用的时候选择合适的锚定尺度仍然是一个很大的挑战。
人脸检测比较特殊,其anchor scale设置的不同会出现以下情形:

(a)表明可以通过增加Anchor的尺度来增加GT匹配的Anchor的数量,这其实和我自己做的实验是一致的(小目标匹配的 Anchor数量少,大目标匹配的Anchor数量多);(b) 则表明,单纯的增加Anchor 的尺度到后期会导致匹配失败(一般是小目标无法匹配)的数量增加。因此,我们在设计 Anchor 的时候可以参考这两个方面。
上述现象应该是人脸检测数据集特有的现象,在通用目标检测中不一定如此。
通过降低匹配阈值强制行为 outer face 匹配足够数目的 Anchor(后面会细说);EMO 论文中则通过 Expected Maximum Overlap 策略来获得合适的 anchor stride and receptive field。然而,通过实验观察到,这些补偿方法引入了大量低质量的anchor,其实表现也不是很好。
以流行的PyramidBox算法为基准,分析结果:
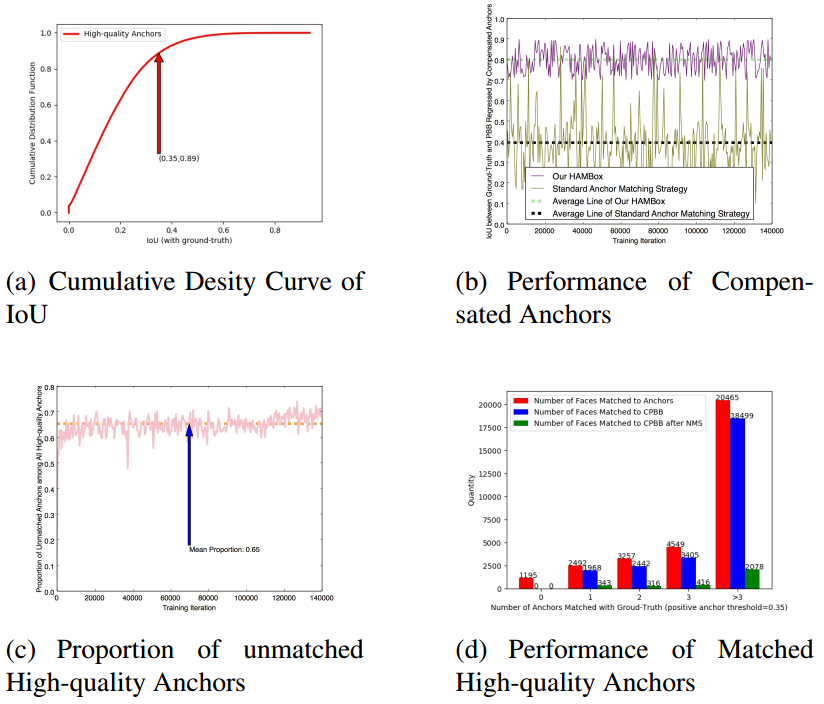
如图(a) 所示,横坐标是匹配阶段 high-quality anchor 与 GT 的 IoU,纵坐标是累计概率分布F(x)。可以看到匹配 𝐼𝑜𝑈≤0.35 的 high-quality anchor 占所有 high-quality anchor 的 89%。也就是说,如果以 0.35 为匹配阈值,所有 Anchor 经过 regression 之后,high-quality-anchor 中只有 11% 的框是来源于匹配 Anchor,89% 的高质量 Anchor 竟然来源于负 Anchor(这些 Anchor 实际上并没有参与回归训练),这是一个非常神奇的事情。
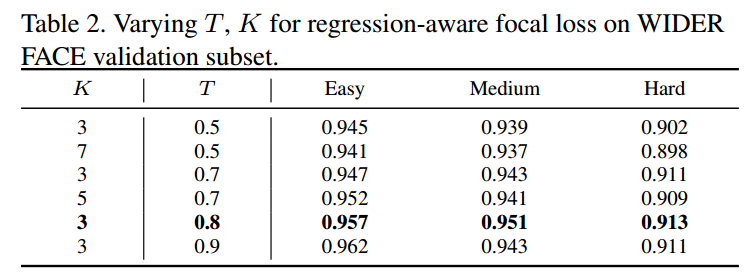
如图(b)所示,传统的匹配策略由于Anchor的质量不高,平均回归 IoU 只有 0.4;作者提出的 HAMBox 方法,平均回归 IoU 可以达到 0.8(紫色线)!
如图(c)所示 ,在训练阶段,所有 high-quanlity anchor 中,有65%是由 unmatched anchor 回归得到的。
如图(d)所示,进一步统计了 Matched Anchors 的表现:以横坐标为 1 的一组柱状图为例,以 0.35为阈值的话,能匹配到2个 Anchor 的 GT 数量是2492,这些匹配的 Anchor 经过回归后能与 GT 𝐼𝑜𝑈≥0.5,即 matched high-quality anchor 的数量变成了 1968,也就是说有 524 个 GT 由于原始匹配的框质量较差,难以通过回归网络来提升 IoU,因此无法召回。
2 Online High-quality Anchor Compensation Strategy
首先我们来分析下论文中提到的常用的两步匹配策略:
(1) 对于每个face,计算face和所有anchor的iou,将Iou大于阈值的anchor位置样本定义为匹配正样本
(2) 由于face尺度变化很大,可能有些face没有任何anchor进行匹配成功,故采用max iou原则将iou最大的anchor作为该face的匹配正样本
当然本文指出,强行补充正样本,效果其实没啥用,对于hard face召回率也提高不了。本质原因是补充的anchor质量太差了,one-stage难以回归到比较好的结果。为了方便对比,我们介绍下通用目标检测中常用的匹配策略(以mmdetection代码为准),具体分析细节见文章目标检测正负样本区分策略和平衡策略总结:
(1) faster rcnn或者retinanet或者ssd算法采用的分配策略是max iou assigner,即:对于每个gt,将高于正样本阈值的并且是max iou位置的anchor设置为正样本;将低于负样本阈值的anchor设置为负样本,考虑到有些gt和anchor的iou不高,故还设置了最小正样本阈值,当某个gt和anchor的max iou大于最小正样本阈值时候,则依然将该anchor设置为正样本。
对比上述流程,可以发现思路相同,但是细节不同,主要区别是上述两步策略采用的是iou assigner原则,而这里是max iou assigner原则,对于第二步,上述是采用强制分配原则,而这里依然有阈值控制,防止引入过差质量anchor。其余样本全部认为是忽略样本
(2) yolo系列是对于每个gt,将max iou位置的anchor设置为正样本,不管阈值多大(先要确定哪一预测层负责预测),这种操作对anchor设置要求较高,因为如果anchor设置不合理,就只能用大量低质量anchor负责回归了。对于正样本附近的anchor预测值,其可能和gt的iou也很高,故需要将这些位置的anchor预测值设置为忽略样本,默认阈值是0.7。对比上述流程,可以看出yolo的分配策略,第一步采用了max iou assigner,第二步则是和上述两步匹配策略中的第二步是一致的。
(3) fcos是第一步也是和yolo一样,要确定某个Gt在第几个层负责预测,第二步是需要确定在每个输出层上面,哪些空间位置是正样本区域,哪些是负样本区域。原版的fcos的正负样本策略非常简单粗暴:在bbox区域内的都是正样本,其余地方都是负样本,而没有忽略样本区域。可想而知这种做法不友好,因为标注本身就存在大量噪声,如果bbox全部区域都作为正样本,那么bbox边沿的位置作为正样本负责预测是难以得到好的效果的,显然是不太靠谱的(在文本检测领域,都会采用shrink的做法来得到正样本区域),所以后面又提出了center sampling的做法来确定正负样本,具体是:引入了center_sample_radius(基于当前stride参数)的参数用于确定在半径范围内的样本都属于正样本区域,其余区域作为负样本,依然没有定义忽略样本。对比上述两步匹配策略,相似度不高,但是整体思想是一致的。
一个简单思考:对于anchor-base算法的anchor匹配策略,到底是max iou assigner好还是iou assigner好?首先各有各的好处,max 原则可以保证每个负责预测的anchor都是高质量的,但是对应的正样本会少一些,对于two-stage算法来说,max iou还是iou,可能影响不会很大,因为rcnn一级可以得到大量好的roi输入,但是从atss论文来看,应该是iou assigner更好,只要设置合理,就可以保证正样本更多,且每个正样本都会是高质量样本。
但是纵观全文,感觉上还是本文的策略更好。以上分析仅仅代表本人浅陋的看法,不一定正确。
oham其实非常简单,核心思想就是:在保证iou质量的前提下,尽可能保证每个face都有指定数目的K个anchor进行匹配(并没有保证一定要K个)。
具体是:
(1) 将每张脸匹配到那些与它的iou大于某个阈值的anchor,对于outer face不进行补偿。
(2) 在训练的每次前向传播之后,每个anchor通过回归得到的坐标计算出回归框,我们将这些回归框记作,异常脸outer face记作。最后,对于每个outer face,我们计算它与的IOU值,然后对每张outer face补偿N个unmatched anchor。记所有的IOUs为, 这些补偿的N个anchor通过下面方式选择:
(a)IOU要大于阈值T(在线正anchor匹配阈值)
(b)对(a)中得到的anchor进行排序,选择IOU最大的top-K个anchor做补偿。K是一个超参数,表示每个outer face能matched的最多anchor数目。使用M表示在步骤1中已经匹配的anchor数目。如果N > -M,则选取top(K-M)个unmatched anchor来补偿。
简单总结下:对于任何一个face,如果在第一步中匹配到了K个正样本,那么就不需要补充;如果不够,假设只匹配到了M个,就利用预测的bbox和face计算iou,选择前最多top(k-M)个anchor作为补充样本,加入训练中;如果补充的样本不满足(a)条件,则不进行补充,达到自适应目的。T和K是通过实验选择的超参数
3 Regression Aware Focal loss
新加入的补充anchor,所以被认为是正样本,但是其质量还是比匹配规则1得到的anchor样本有些差距,为了突出这种差距或者说更加合理的设计,应该对补充样本引入一个自适应权重,为此作者对focal loss进行了自适应加权操作。
作者对满足以下三个条件的anchor不进行自适应加权:
1 属于high-quality-anchors
2 在anchor匹配的第一步骤时,label被分配为0
3 在anchor补偿中,没有被选中
新的focal loss为:
表示iou, com表示补偿的anchor, norm表示普通样本。表示matched和unmatched low-quality anchor, 表示新补偿的anchor。
上式的含义是对补偿的anchor采用iou加权的focal loss,对于matched和unmatched low-quality anchor则使用普通的focal loss,注意对于落选的unmached high-quality anchor,这里是忽略其loss的。同时,也将补偿的HAMBox anchor加入回归loss,
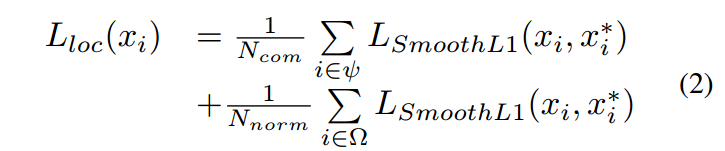
实验
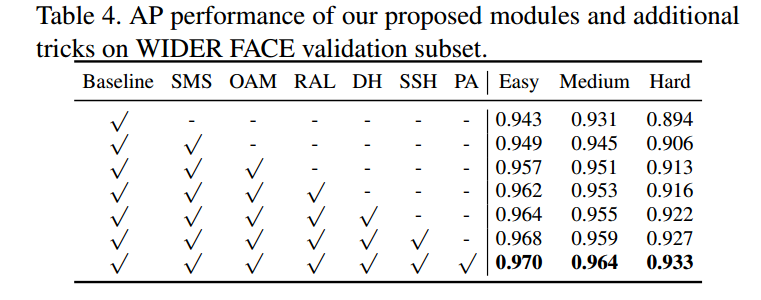
OAM表示online anchor mining, RAL表示regression-aware focal loss为本文最重要的创新点,可以看出其对AP提升明显(hard 分别提升0.7%, 0.3%),叠加其他trick后(Deep Head, SSH, PyramidAnchor),该算法达到SOTA。
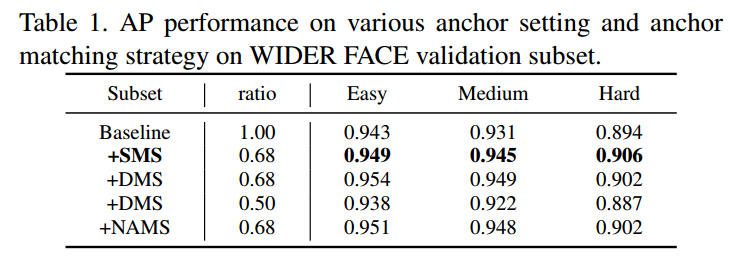
SMS是指第一步匹配策略;DMS是两步匹配策略,通过第3行和第4行,可以看出,两步补偿策略补充的anchor其实作用不是很大,提升很小,在hard小脸上效果还更差(但是easy上面还是提升明显的),说明由于补偿的anchor质量太差,导致性能没啥上升。而降低ratio值,会导致匹配的anchor质量更加不高,性能会下降。上面的图表是说明采用简单的SMS策略得到的效果其实和目前引入的补偿策略,差别不大。而采用本文的补偿策略,效果提升明显。值得尝试。
