@huanghaian
2020-12-01T06:41:12.000000Z
字数 2743
阅读 1471
移动端模型:shufflenetv1
分类
0 摘要
论文名称:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
论文地址:https://arxiv.org/abs/1707.01083
shuffleNet是face++在mobilenetv1思想基础上提出的移动端模型。前面说过mobilenetv1主要是通过深度可分离卷积来减少参数和计算量,并且深度可分离卷积实际上包括逐通道分离卷积和1x1标准点卷积两个模块,由于通常输入和输出通道比较大,故mobilenetv1的主要参数和计算量在于第二步的1x1标准逐点卷积。
shuffleNet主要改进是对1x1标准逐点卷积的计算量和参数量进一步缩减,具体是引入了1x1标准逐点分组卷积,但是分组逐点卷积会导致组和组之间信息无法交流,故进一步引入组间信息交换机制即shuffle层。通过上述两个组件,不仅减少了计算复杂度,而且精度有所提升。
1 算法设计
1.1 channel shuffle
当直接对1x1标准逐点卷积进行改进,变成1x1标准逐点分组卷积,通过将卷积运算的特征图限制在每个组内,模型的计算量可以显著下降。然而这样做带来了明显问题:在多层逐点卷积堆叠时,模型的信息流被分割在各个组内,组与组之间没有信息交换,这将可能影响到模型的表示能力和识别精度。因此,在使用分组逐点卷积的同时,需要引入组间信息交换的机制,如下所示:
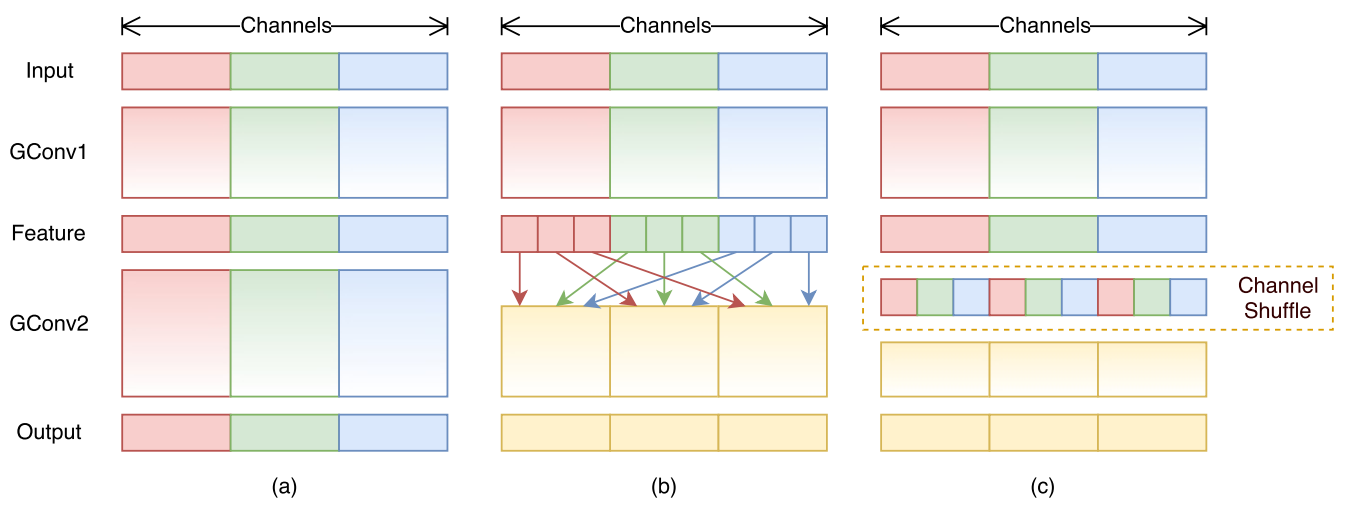
(a)图是堆叠多个分组卷积,组和组之间没有信息流通,这肯定会影响到模型的表示能力和识别精度,故可以在两个分组卷积层直接引入特征图打乱操作,如图(b)所示,而(c)是本文提出的通道shuffle层,效果和(b)等级,但是实现上更加高效,并且是可导的。
channel shuffle的实现非常简单,示意图如下:

图片来源:https://blog.csdn.net/u011974639/article/details/79200559
具体代码如下所示:
channels_per_group = num_channels // groups# 先将输入特征图为n组# (b,c,h,w)-->(b,n,c//n,h,w)x = x.view(batch_size, groups, channels_per_group, height, width)# 然后交换维度变成 (b,c//n,n,h,w),这个步骤其实相当于reshapex = torch.transpose(x, 1, 2).contiguous()# 最后重新输出为原始输入大小变成(b,c,h,w)x = x.view(batch_size, -1, height, width)
核心就是先对输入特征图按照通道维度进行分组,然后转置,最后变成原始输入尺度即可。
1.2 ShuffleNet单元
基于上述所提组件,可以构建基础的shufflenet单元:
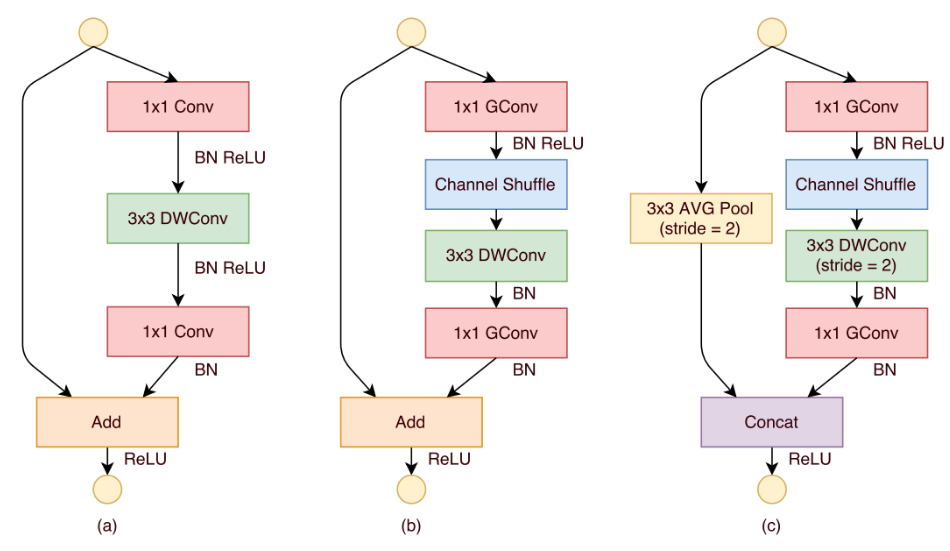
(a)是带有深度可分离卷积的bottleneck单元;(b)是设计的stride=1时候的shuffle单元;(c)是设计的stride=2时候的shuffle单元,在该单元中,使用concat来使得通道加倍,导致信息不缺失。
def _inner_forward(x):residual = x# 1x1分组卷积压缩通道out = self.g_conv_1x1_compress(x)# 逐通道卷积,其实就是分组卷积out = self.depthwise_conv3x3_bn(out)# 通道shuffleif self.groups > 1:out = channel_shuffle(out, self.groups)# 恢复或者扩展通道out = self.g_conv_1x1_expand(out)if self.combine == 'concat':# stride=2residual = self.avgpool(residual)out = self.act(out)out = self._combine_func(residual, out)else:# stride=1out = self._combine_func(residual, out)out = self.act(out)return out
1.3 shufflenet模型
基于上述单元,类似于resnet通过堆叠就可以构造整个模型:
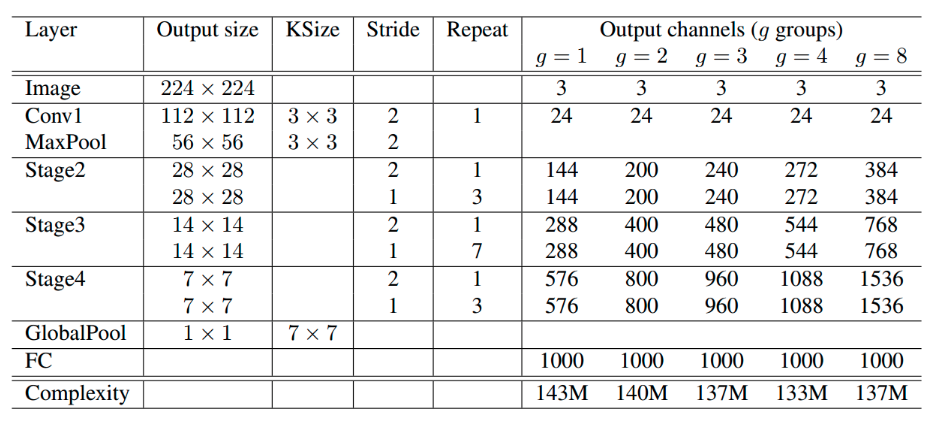
由于stage2的输入通道比较少,故该阶段的第一个1x1逐点卷积层中不适用分组卷积操作。其中g表示分组数,参数g控制逐点卷积的连接稀疏性(即分组数)。可以发现,当卷积运算的分组数越多,模型的计算量就越低,这就意味着当总计算量一定时,较大的分组数可以允许设置较多的通道数,作者认为这将有利于网络编码更多的信息,提升模型的识别能力。
和mobilenet一样,采用了缩放尺度因子s控制全局通道数,默认提供了0.25x、0.5x和1x参数:
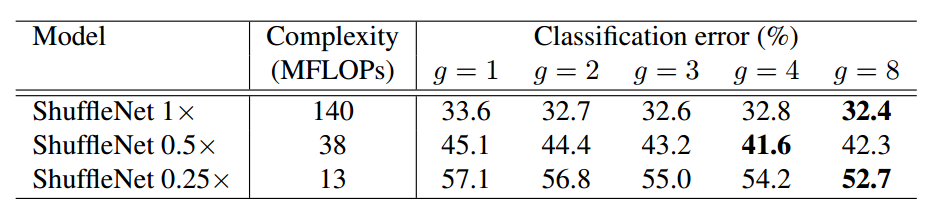
如上表所示,当计算量一定情况下,增加分组数意味着要增加通道数,可以带来更好的性能,但是并不是绝对的,因为在0.5x的shufflenet中,当g=8时候性能没有g=4的时候好,可能是分组太多,导致每个组卷积的输入特征通道过少。但是在0.25x的shufflenet中,是g=8时候最好的,这说明在特别小的网络中,应该要把分组数增加。需要注意的是:虽然深度卷积可以减少计算量和参数量,但在低功耗设备上,与密集的操作相比,计算/存储访问的效率更差,故在ShuffleNet中只在bottleneck上使用深度卷积,尽可能的减少开销。
2 实验结果
实验在ImageNet的分类集上做评估,大多数遵循ResNeXt的设置,除了两点:
- 权重衰减从1e-4降低到了4e-5
- 数据增强使用较少的aggressive scale 增强
这样做的原因是小型网络在训练过程通常会遇到欠拟合而不是过拟合问题。

上表可以看出,使用了shuffle通道可以有效的减低错误率,且在小网络分组组增加的情况下提升最明显。
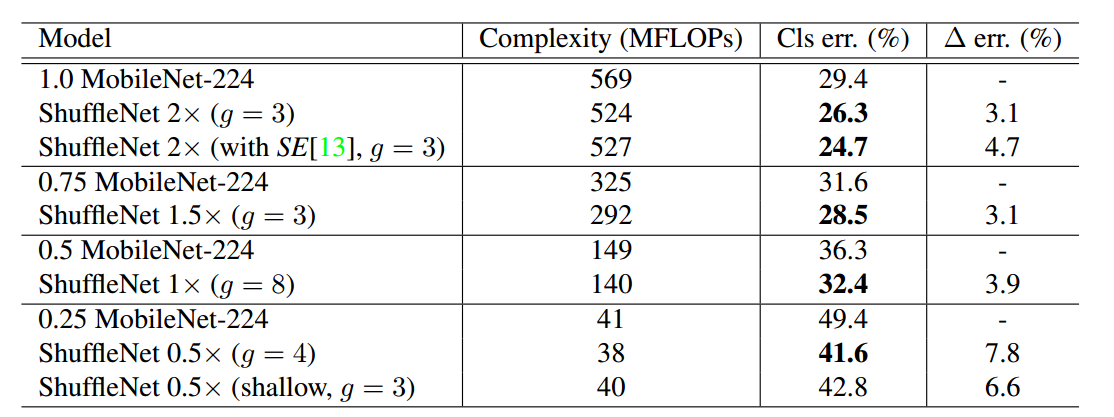
通过对比,可以看出shufflenet性能远远好于Mobilenet。
其实可以看出shufflenetv1好于mobilenetv1,原因是:
(1) 引入了残差结构
(2) 用了很多分组卷积,导致在同样FLOPS情况下,通道数可以多一些,模型复杂度比mobilenet低
3 总结
shufflenet核心改进就是针对1x1逐点分组卷积存在的组内信息无法交互问题而提出了通道shuffle操作,并且通过实验发现在分组数增加情况下,可以显著减低计算复杂度,从而可以通过增加通道来实现比mobilenet精度更高且速度更快的模型功能。由于后续有新提出的shufflenetv2,故shufflenetv1现在用的也比较少。
