@huanghaian
2020-10-29T12:11:57.000000Z
字数 3313
阅读 4249
从代码角度分析CenterNet改进模型TTFNet
目标检测
0 摘要
论文名称: Training-Time-Friendly Network for Real-Time Object Detection
arxiv: 1909.00700v3
github: https://github.com/ZJULearning/ttfnet
在上一篇文章从代码角度分析高效优雅检测模型CenterNet中详细分析了实时高效目标检测算法,其中也说到了其存在的一些不那么友好的问题,而本文就是针对这些小问题进行了改进,主要贡献就是极大的减少了训练时间,大概减少了7倍时长。如果想理解本文,建议你先阅读centernet那篇文章,否则很多细节不清楚。
从本文题目就可以看出来Training-Time-Friendly Network,主要目的是缩短训练时间。其核心思想是:从BBOX框中编码更多的训练样本,主要是增加高质量正样本数,与增加批量大小具有相似的作用,这有助于扩大学习速度并加快训练过程。主要是通过高斯核函数实现。其实很简单,我们知道centernet的回归分支仅仅在中心点位置计算loss,其余位置忽略,这种做法就是本文说的训练样本太少了,导致收敛很慢,需要特别长的训练时间,而本文采用高斯核编码形式,对中心点范围内满足高斯分布范围的点都当做正样本进行训练,可以极大的加速收敛。本文做法和FCOS非常类似,但是没有多尺度输出,也没有FPN等复杂结构,我个人认为是简化版本的FCOS,属于实践性很强的算法。
1 算法分析
CenterNet的优点是简单,但是他这种简单设计会导致训练时长非常长,原因是仅仅关注对象中心,失去了利用中心点附近的信息生成更多训练样本的机会。其性能主要来自于较多的数据增强和极长的训练时长。 为了证明这一点,作者做了个简单实验,如下:
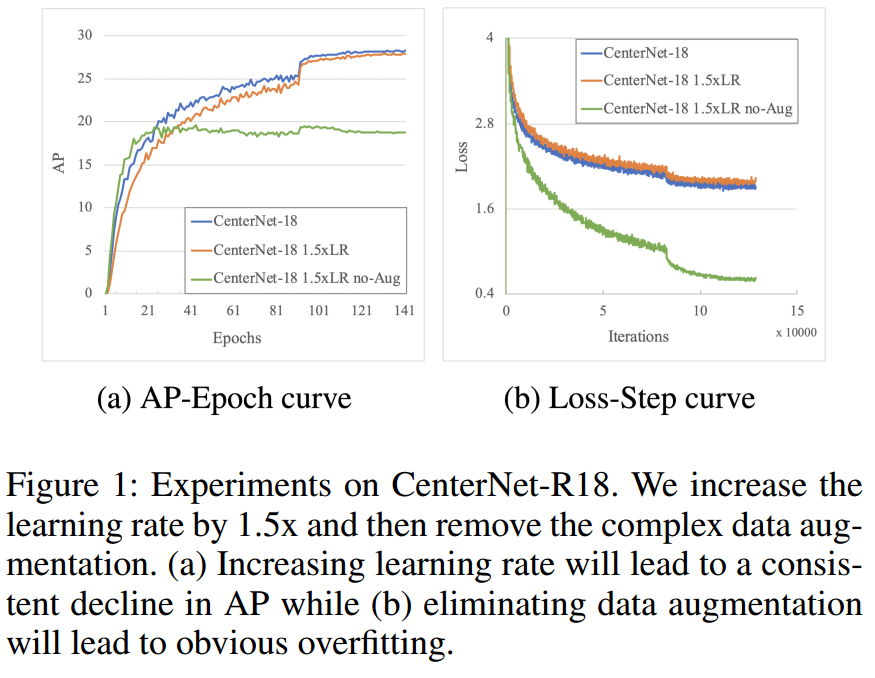
采用centernet-r18作为研究对象,首先在增加学习率时候也没法加速收敛,性能还稍微有下降,同时如果去掉数据增强,那么性能就下降非常明显了,这主要是过拟合了。通过这个简单实验可以发现centernet由于利用的训练样本非常少或者说监督位置非常少,要想取到好的性能,则只能靠大量数据增强和训练时长。
本文方法可以简单总结为:将高斯分布概率作为样本权重来加权那些靠近目标中心的样本,并进一步应用归一化手段来平衡大小bbox回归问题(注意centernet的wh回归分支是没有任何归一化的)。该方法可以在不需要FPN的情况下,减轻anchor-free探测器中常见的难以处理的模糊性。此外,它可以不需要任何offset偏移预测来提供更精确的中心点回归结果。整个算法结构也比较简单。
仔细分析,其实这个算法和FCOS非常类似,但是更加简单。FCOS也是bbox中心点附近当做正样本,不过其采用的是设置半径来确定正样本范围,而本文是高斯核函数,而且是基于WH自适应的椭圆高斯核,更加make sense一些。
在论文的开始,作者首先做了一些证明:提供更多高质量的训练样本与增加批次大小具有类似的作用,可以提供更多的监督信号,从而加速收敛。
基于我们在图像分类里面的知识,了解到:如果批量越大,可以采用更大的学习率,并且在大多数情况下,学习率与批量大小呈线性关系。采用大batch size可以明显加速训练,减少训练时间。作者通过对SGD更新公式进行简单修改,就可以证明出在目标检测领域,在一个mini batch内部增加有效训练样本数就可以等价于在图像分类中增加batch size,在同时增加学习率lr的情况下就可以加速目标检测训练。当然我认为这种等价只能算是近似等价,或者说在只是在一定程度上是正确的。不是很严谨。知道上述概念就行了,对算法理解其实没啥有用帮助。
最终本算法在采用高斯核编码模式的基础上,去掉了复杂的数据增强,同时增加了学习率来加快收敛速度。
1.1 网络结构
网络方面,和centernet差不多,使用了ResNet和DarkNet作为骨干,也是上采样到输入的1/4倍作为输出,区别是:为了减少小物体在下采样的时候丢失特征,引入了额外的挑层连接,类似Unet,假设高低层特征融合,可以有效缓解小物体精度较低的不足,如下所示:
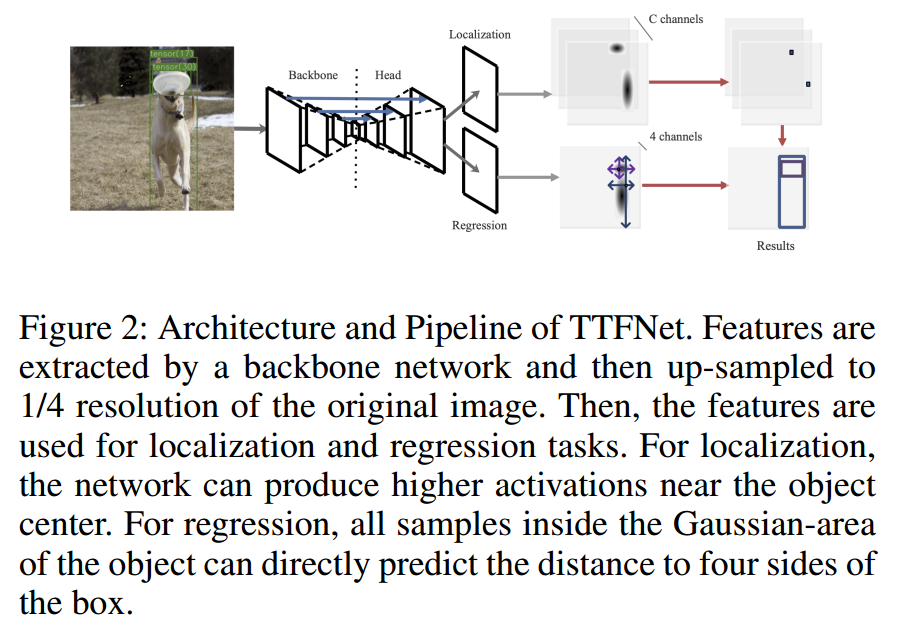
注意可以发现其offset回归分支,作者觉得没有很大必要。目前只有两个分支输出,localization分支用于表示哪些区域有物体,和centernet里面含义相同,shape=(h/4,w/4,num_cls)。另一个是Regression分支,用于回归wh高,在centernet中,宽高回归分支的目标是基于中心点位置回归上距离,由于这种简单的设置,导致其只能在中心点位置才能计算loss,本文目的是增加正样本数,那么就不能采用这种目标编码方式了,本文采用的是FCOS的格式即回归的target是当前位置相对gt bbox的4条边的距离,故输出shape是(h/4,w/4,4)。
本文算法采用mmdetection框架写的,所以比较容易理解。骨架网络包括三个,分别是resnet、dla和darknet53,...
1.2 训练样本生成策略
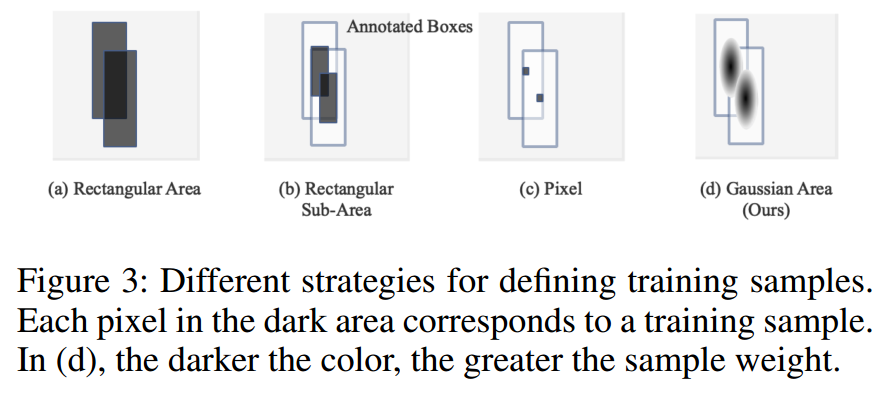
上图是一个直观的理解。假设图片中存在两个有交集的bbox,(a)是将bbox内部的所有区域都当做训练样本(一般就是值正样本),这种策略属于早期论文做法,现在基本不会这么做了;(b)是带shrink操作的样本定义方式,考虑bbox标注的不准确性,只考虑内部一定范围内的区域是训练样本,大部分anchor-free论文都是这种做法;(c)是centernet特有的做法,仅仅在中心点处才是训练样本,其余位置忽略;(d)是本文基于高斯核来定义确定训练样本区域。一眼看起来比其他三种更加科学。
(1) Object Localization
这个其实是分类分支,shape=(h/4,w/4,num_cls),label生成过程和centernet差不多,只不过centernet的高斯核是正方形核,而本文是椭圆形。而且前一篇文章说过centernet的高斯核半径计算方法比较复杂,而本文就比较简单暴力了:
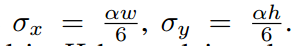
默认取0.54,该分支的Loss计算和centernet中的完全相同,也是修改版本的focal loss。
(2) Size Regression
前面说过,其target不是和centernet一样,而是预测到4条边的距离,shape是(h/4,w/4,4)。训练样本区域和Object Localization一样,高斯核范围内的就是了。
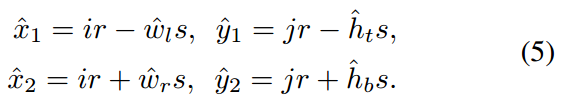
(ir,jr)是样本区域内的任意一点坐标,(w,h)是缩放了s倍,定义在特征图尺度的bbox的宽高值,对于任何一点其预测的bbox位置可以采用上述式子确定,也就是说,对于任意一点(ir,jr),网络预测输出是(wl,ht,wr,hb),注意这4个值是原图尺度,而不是特征图尺度哦!代表距离4条边的距离。这里的s不是stride=4,而是作者设置的16,目的是加快收敛。centernet回归wh时候是没有归一化的,本文也没有进行归一化,但是为了方便优化,对宽高预测分支乘上了s=16,缩小预测范围,训练更加稳定一些。有些算法会将这个s设置为可学习参数,目的都是一样的。
和FOCS一样,对于多个bbox重叠区域,其target是取最小bbox的标注。
该分支采用的回归loss是最新的GIOU,
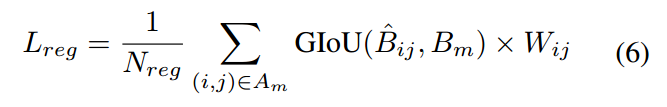
B是原图尺度的bbox坐标(xmin,ymin,xmax,ymax),是基于预测值进行解码还原后的bbox预测坐标。为了体现距离中心点远近,对loss的影响,引入了W权重。这个和FCOS的centerness分支左右差不多。
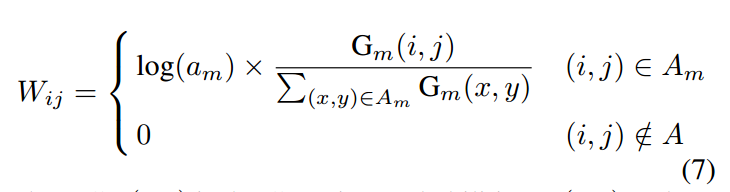
A是shrink后的矩形面积,G是前面得到的高斯核函数分布值,不考虑log(a)这一项,则就是简单的归一化加权而已,远距离的位置权重小,中心点附近权重大。而乘上log(a)则可以反映出bbox的大小属性了。
总的loss包括两个,一个是Object Localization,一个是Size Regression,权重设置比例为1:5。
1.3 laebl生成代码分析
1.4 网络推理
实验和结果分析