@huanghaian
2020-04-28T07:48:25.000000Z
字数 2492
阅读 2531
darknet转pytorch的坑
目标检测
tiny-yolov3
目的:将darknet里面的tiny-yolov3.cfg配置和对应权重直接可以导入到新框架中,进行推理。好处是验证新框架里面的模型代码写的是否正确。
经过两天仔细校对,总是是实现了,记录下碰到的坑。
(1) 网络写错了
cfg里面的tiny-yolov3,有一个maxpool操作其参数是:
[maxpool]
size=2
stride=1
而其他的maxpool参数都是2,这个细节开始没发现,导致预测的bbox会存在偏移。
考虑到特征图尺寸可能不能被整除,不然运行会报错,故在pytorch里面实现是:

tiny-yolov3在第二个head前有一个cat操作,而我们的cat顺序错误了,导致第二个输出层完全预测不出来
stage5 = self.layers[2](torch.cat((stage5_upsample, middle_feats[1]), 1))
正确写法是上面的。这个细节一定要注意,因为cat错误不会报错,很难排除问题的。一定要非常小心。
(2) darknet权重顺序导入错误了
这个细节要非常注意,因为darkent里面保存的权重是整个参数,没有开始标志,在你网络复现正确情况下,导入权重也可能出错,一定要理解darknet权重的保存顺序
darkent里面的权重,保存顺序完全按照cfg从上到下的顺序,而不是网络实际运行顺序。如果你的解析顺序不正确,那么即使网络结构写对了,导入的权重也可能是错误的,因为不会报错。
以tiny-yolov3为例:
def __init__(self, pretrained=False):
super(TinyYolov3Backbone, self).__init__()
# Network
layer0 = [
# Sequence 0 : input = image tensor
# output redutcion 16
# backbone
OrderedDict([
('0_convbatch', vn_layer.Conv2dBatchLeaky(3, 16, 3, 1)),
('1_max', nn.MaxPool2d(2, 2)),
('2_convbatch', vn_layer.Conv2dBatchLeaky(16, 32, 3, 1)),
('3_max', nn.MaxPool2d(2, 2)),
('4_convbatch', vn_layer.Conv2dBatchLeaky(32, 64, 3, 1)),
]),
OrderedDict([
('5_max', nn.MaxPool2d(2, 2)),
('6_convbatch', vn_layer.Conv2dBatchLeaky(64, 128, 3, 1)),
]),
OrderedDict([
('7_max', nn.MaxPool2d(2, 2)),
('8_convbatch', vn_layer.Conv2dBatchLeaky(128, 256, 3, 1)),
]),
# Sequence 1 : input = sequence0
# output redutcion 32
# backbone
OrderedDict([
('9_max', nn.MaxPool2d(2, 2)),
('10_convbatch', vn_layer.Conv2dBatchLeaky(256, 512, 3, 1)),
('10_zero_pad', nn.ZeroPad2d((0, 1, 0, 1))),
('11_max', nn.MaxPool2d(2, 1)),
('12_convbatch', vn_layer.Conv2dBatchLeaky(512, 1024, 3, 1)),
('13_convbatch', vn_layer.Conv2dBatchLeaky(1024, 256, 1, 1)),
]),
]
head0 = [
OrderedDict([
('14_convbatch', vn_layer.Conv2dBatchLeaky(256, 512, 3, 1)),
('15_conv', nn.Conv2d(512, 3 * (5 + 80), 1)),
]),
OrderedDict([
('18_convbatch', vn_layer.Conv2dBatchLeaky(256, 128, 1, 1)),
('19_upsample', nn.Upsample(scale_factor=2)),
]),
# stage5 / head
OrderedDict([
('21_convbatch', vn_layer.Conv2dBatchLeaky(256 + 128, 256, 3, 1)),
('22_conv', nn.Conv2d(256, 3 * (5 + 80), 1)),
]),
]
self.layer0 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in layer0])
self.head0 = nn.ModuleList([nn.Sequential(layer_dict) for layer_dict in head0])
self.init_weights(pretrained)
我们是采用init_weights来加载darknet权重的。上面的写法是正确的,但是如果:

那么就是错误的,虽然导入权重时候不会报错。原因是上面的写法和cfg里面的排列顺序不一致,而解析的时候是我们自己切分权重的,就会出现切分错误。
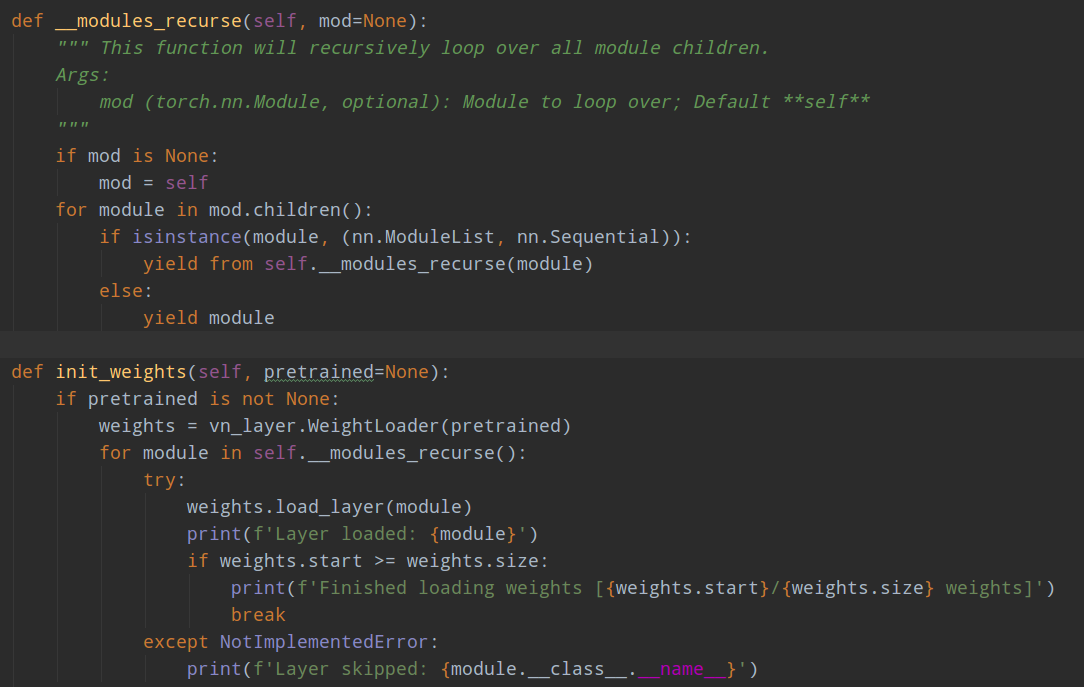
核心就是self.__modules_recurse()的顺序必须要和cfg里面完全一致,一点错误都不能有。
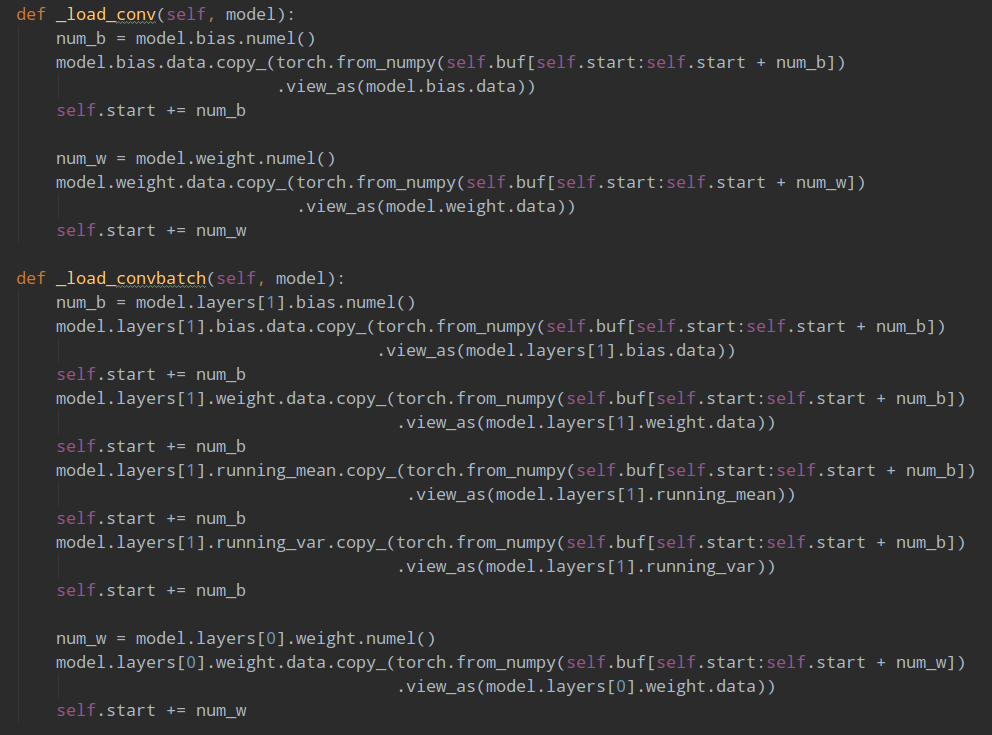
且Load权重时候,是先Load Bn参数,然后再load 卷积参数。要注意。
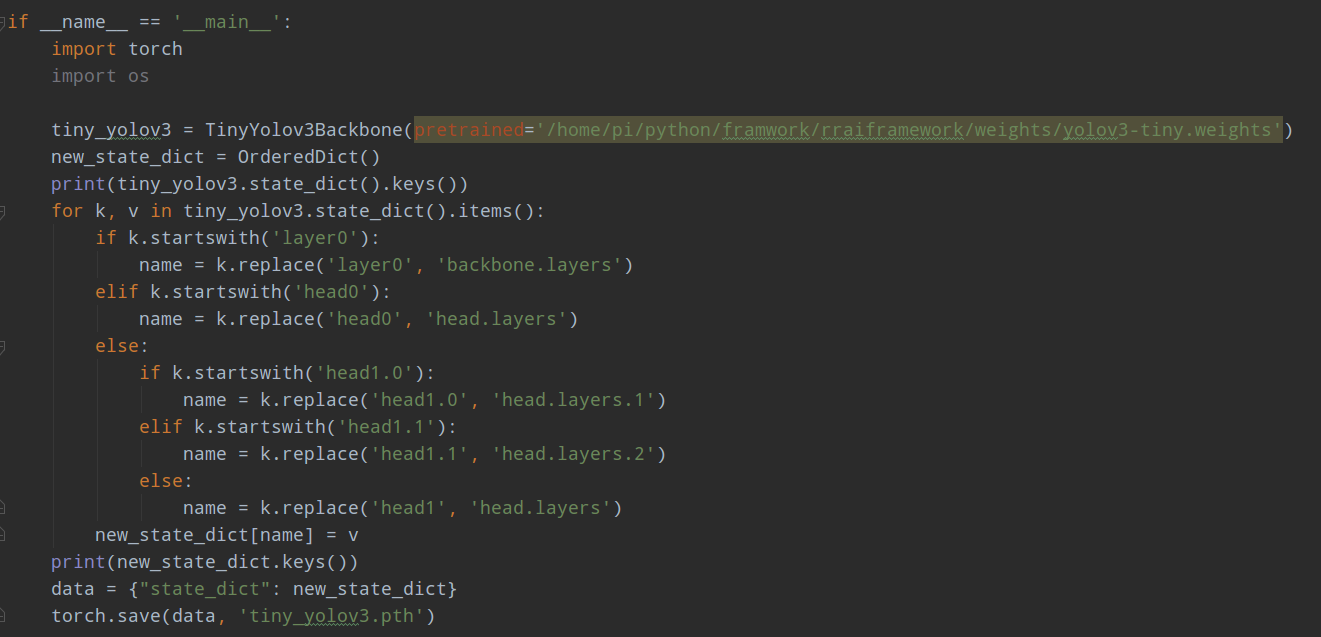
完整转化代码为:
(3) 测试图片处理流程不一致
假设输入是416x416,其测试流程是先进行pad为正方形,然后resize,但是需要注意其resize图片是采用最近邻,而我们的lettereize是线性插值。实际测试表明差距还是比较大,会导致一些框丢失,可能darknent训练时候采用的是最近邻。
且其输入是rgb格式,而我们默认是bgr格式,这个对最终结果也影响很大。
