@huanghaian
2020-07-21T08:29:38.000000Z
字数 6052
阅读 4860
从代码角度分析高效文本检测算法DBNet
目标检测
0 摘要
论文题目:Real-time Scene Text Detection with Differentiable Binarization
arxiv: https://arxiv.org/abs/1911.08947
github: https://github.com/MhLiao/DB
DBNet是华科白翔组AAAI2020新提出的高效文本检测算法,速度极快,性能也是非常不错的。整体思路非常简单,是一个值得尝试的优异算法。
其核心采用的是基于分割的做法进行文本检测,即将每个文本块都进行语义分割,然后对分割概率图进行简单二值化、最终转化得为box或者poly格式的检测结果。除去网络设计方面的差异,本文最大特点是引入了Differentiable Binarization(DB)模块来优化分割预测结果。常规的基于语义分割的文本检测算法都是直接输出二值语义概率图或者其他辅助信息,然后经过阈值二值化得到最终结果,要想得到比较好的文本检测效果,一般都需要复杂的后处理,例如PSENet和PANet,会导致速度很慢。本文尝试将阈值二值化过程变得可微,这一小小改动不仅可以增加错误预测梯度,也可以联合优化各个分支,得到更好的语义概率图。
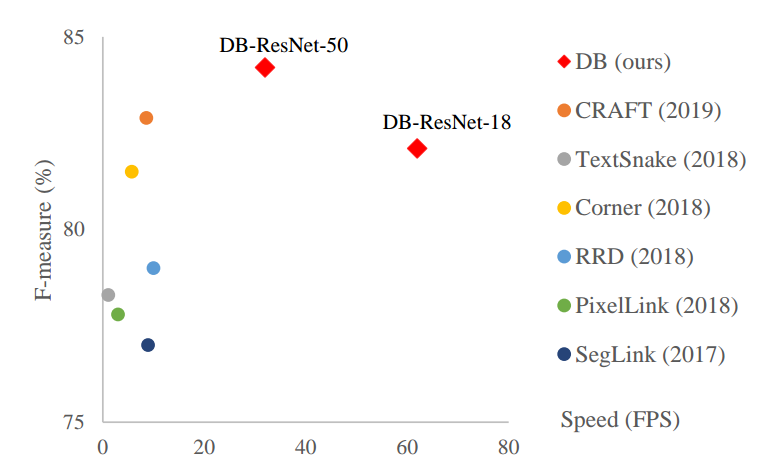
总而言之:通过引入辅助的DB可微模块,促进语义概率图分支的学习,只要分割概率图学好了,那么后处理自然也就简单了,实验结果表明,速度非常快,效果也是非常不错的,如下所示。其实目前大部分算法速度慢的原因都是各种复杂后处理,一旦后处理可以简单化,那么速度其实都可以很快。
1 算法介绍
算法核心流程如下:
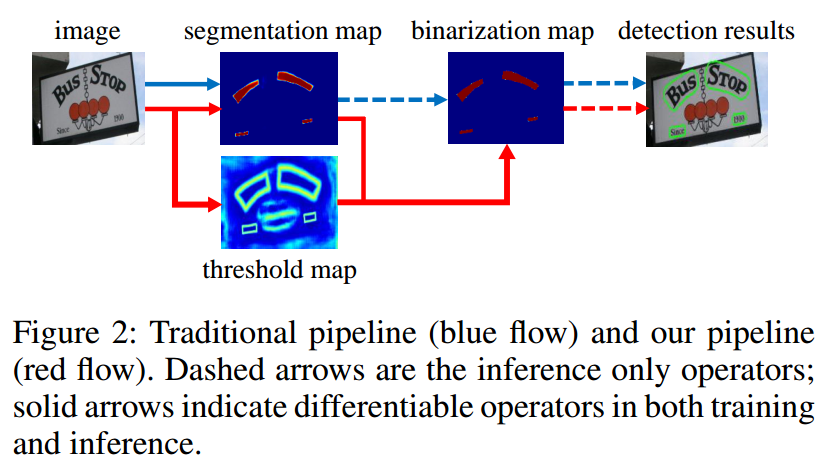
和常规基于语义分割算法的区别是多了一条threshold map分支,该分支的主要目的是和分割图联合得到更接近二值化的二值图,属于辅助分支。其余操作就没啥了。整个核心知识就这些了。
下面结合代码进行详细分析。算法整体详细流程如下:
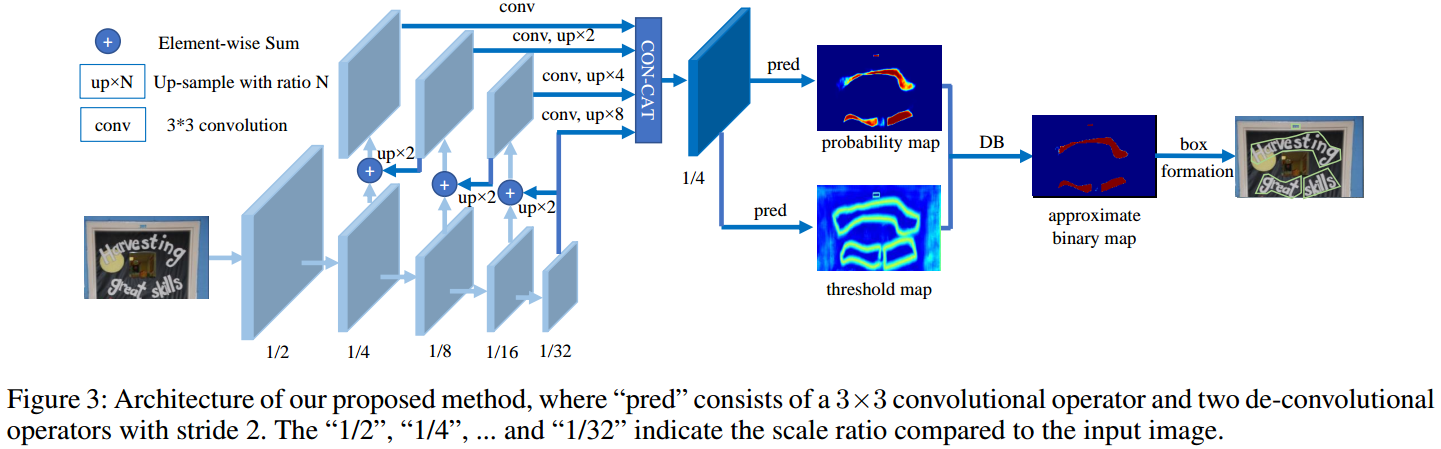
1.1 骨架网络和FPN
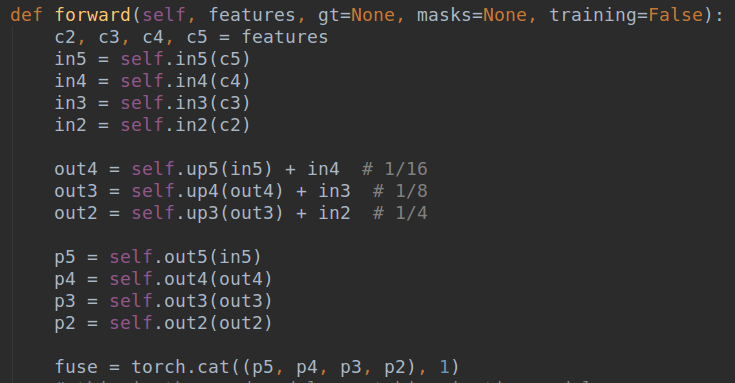
骨架网络采用的是resnet18或者resnet50,为了增加网络特征提取能力,在layer2、layer3和layer4模块内部引入了变形卷积dcnv2模块。在resnet输出的4个特征图后面采用标准的FPN网络结构,得到4个增强后输出,然后cat进来,得到1/4的特征图输出fuse。
其中,resnet骨架特征提取代码在backbones/resnet.py里,具体是输出x2, x3, x4, x5,分别是1/4~1/32尺寸。FPN部分代码在decoders/seg_detector.py里面,具体是:
1.2 head部分
输出head在训练时候包括三个分支,分别是probability map、threshold map和经过DB模块计算得到的approximate
binary map。
首先对fuse特征图经过一系列卷积和反卷积,扩大到和原图一样大的输出,然后经过sigmod层得到0-1输出概率图probability map;同时对fuse特征图采用类似上采样操作,经过sigmod层的0-1输出阈值图threshold map;将这两个输出图经过DB模块得到approximate
binary map。三个图通道都是1,输出和输入是一样大的(代码注释写错了,不是1/2,而是1)。要想分割精度高,高分辨率输出是必要的。这部分代码也在decoders/seg_detector.py里面,主流程为:

由于本文重点是DB模块,故有必要重点说明下。其实就是如下公式:
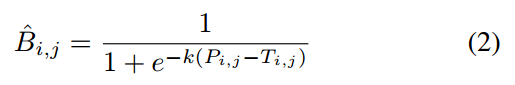
本质就是带参数K的sigmod函数,通过参数K=50来模拟hard截断二值化函数:

SB是标准二值化函数。
为了说明DB模块的引入对于联合训练的优势,作者对该函数进行梯度分析,也就是对approximate
binary map进行求导分析,由于是sigmod输出,故假设Loss是bce,对于label为0或者1的位置,其Loss函数可以重写为:
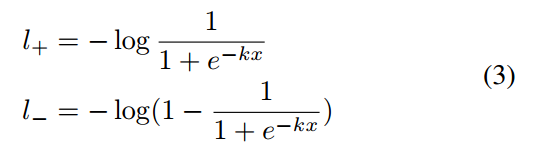
x表示probability map-threshold map,最后一层关于x的梯度很容易计算:
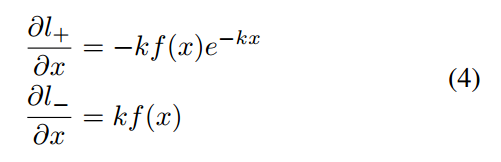
看上图右边,(b)图是当label=1,x预测值从-1到1的梯度,可以发现,当k=50时候梯度远远大于k=1,错误的区域梯度更大,对于label=0的情况分析也是一样的。故:
(1) 通过增加参数K,就可以达到增大梯度的目的,加快收敛
(2) 在预测错误位置,梯度也是显著增加
总之通过引入DB模块,通过参数K可以达到增加梯度幅值,更加有利优化,可以使得三个输出图优化更好,最终分割结果会优异。而DB模块本身就是带参数的sigmod函数,实现如下:

1.3 loss分析
输出是单个单通道图,probability map和approximate binary map是典型的分割输出,故其loss就是普通的bce,但是为了平衡正负样本,还额外采用了难负样本采样策略,对背景区域和前景区域采用3:1的设置。对于threshold map,其输出不一定是0-1之间,后面会介绍其值的范围,当前采用的是L1 loss,且仅仅计算扩展后的多边形内部区域,其余区域忽略。
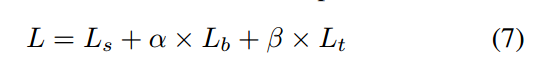
Ls是probability map,Lt是阈值图,Lb是近似二值化图,
其中平衡bce实现在decoders/balance_cross_entropy_loss.py,实现非常简单:
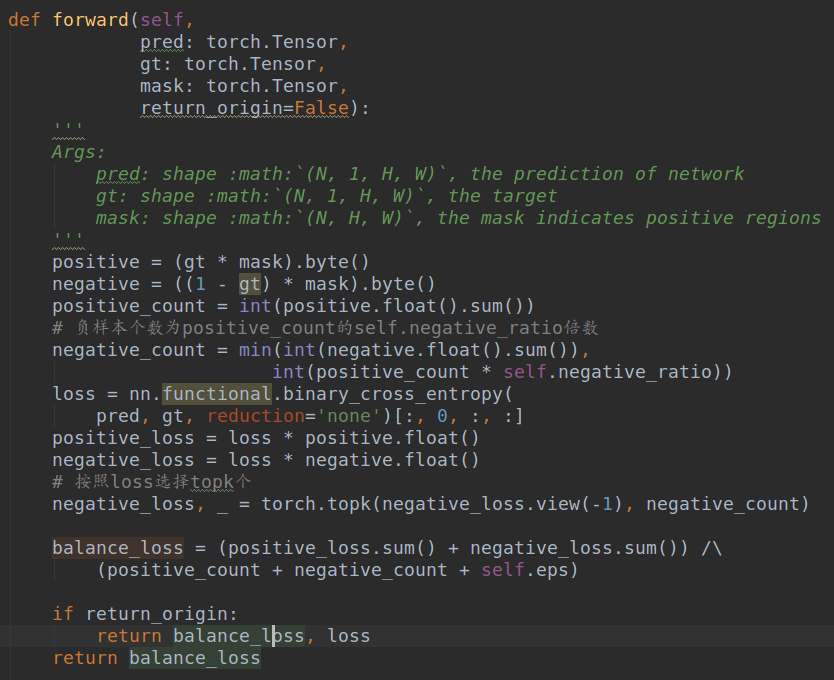
本文整个论文Loss的实现在decoders/seg_detector_loss.py的L1BalanceCELoss类,可以发现其实approximate binary map采用的并不是论文中的bce,而是可以克服正负样本平衡的dice loss。一般在高度不平衡的二值分割任务中,dice loss效果会比纯bce好,但是更好的策略是dice loss +bce loss。
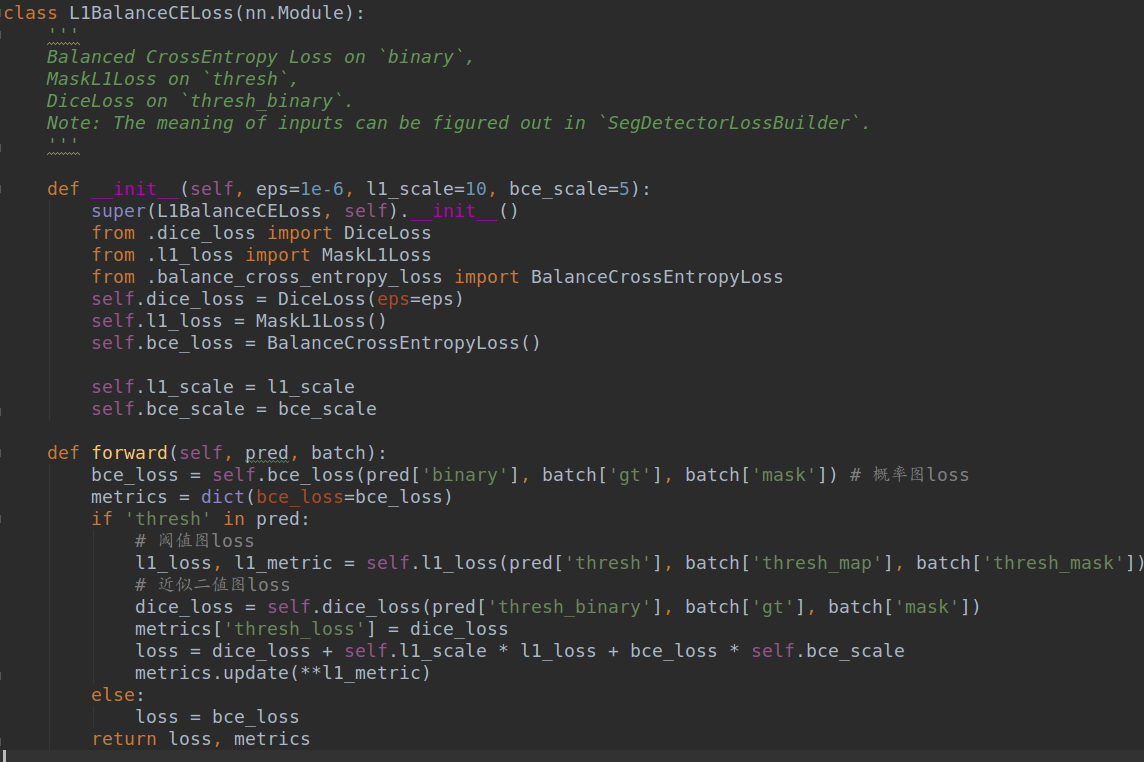
1.4 label生成
理解三个输出图label的生成过程,是本文的关键,下面结合代码详细讲,具体会结合整个dataset的生成过程分析。
首先分析配置文件,以icdar2015数据为例experiments/seg_detector/base_ic15.yaml
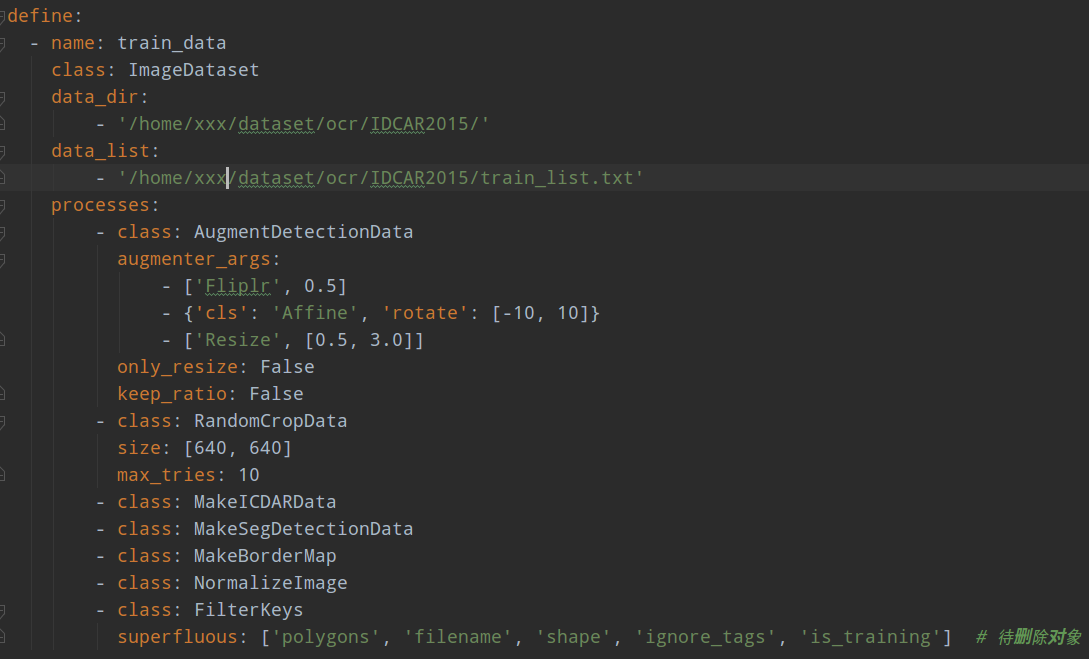
仔细看配置结构,可以发现整个项目框架结构其实解耦度很高的,代码质量比较高,和mmdetection设计思想非常类似,只不过我觉得本文yaml配置没有mmdetection那种采用py文件且注册类的实现好。但是相比大部分开源代码,本项目已经是非常良心了。可以看出,其是靠yaml配置来组装各个类,每个子模块都可以通过类名+类参数的方式替换。
我们重点分析dataset数据生成过程,从配置可以看出,除了数据的前处理外,在数据处理部分一共经过了7个处理函数,分别是:
(1) AugmentDetectionData数据增强类;
(2) RandomCropData 数据裁剪类,因为数据裁剪涉及到比较复杂的多变形标注后处理,所以单独列出来
(3) MakeICDARData 数据重新组织类
(4) MakeSegDetectionData 生成概率图和对应mask类
(5) MakeBorderMap 生成阈值图和对应Mask类
(6) NormalizeImage 图片归一化类
(7) FilterKeys 字典数据过滤类,具体是把superfluous里面的key和value删掉,不输入网络中
是不是和mmdetection的pipeline非常类似呀!
下面开始对每个类重点分析。
(1) 数据预处理
在data/image_dataset.py,数据预处理逻辑非常简单,就是读取图片和gt标注,解析出每张图片poly标注,包括多边形标注、字符内容以及是否是忽略文本,忽略文本一般是比较模糊和小的文本。在进行上述7个类的处理前,我们可以先对数据和标注进行可视化,具体可以在getitem方法里面插入:
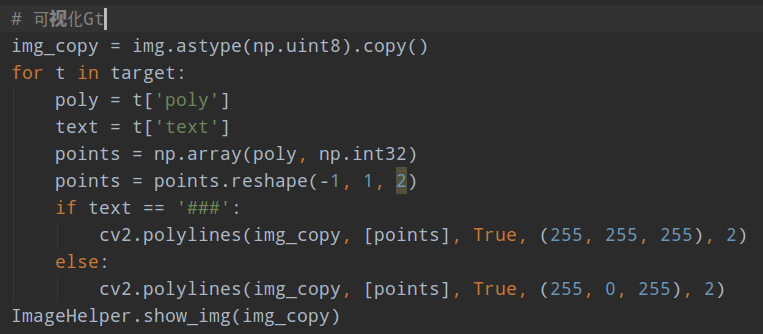
以icdar2015数据集为例,忽略文本颜色是白色显示。


(2) AugmentDetectionData
该类在data/processes/augment_data.py,其目的就是对图片和poly标注进行数据增强,包括翻转、旋转和缩放三个,参数如配置所示。本文采用的增强库是imgaug。可以看出本文训练阶段对数据是不保存比例的resize,然后再进行三种增强。
由于icdar数据,文本区域占比都是非常小的,故不能用直接resize到指定输入大小的数据增强操作,而是使用后续的randcrop操作比较科学。但是如果自己项目的数据文本区域比较大,则可能没必要采用RandomCropData这么复杂的数据增强操作,直接resize算了。
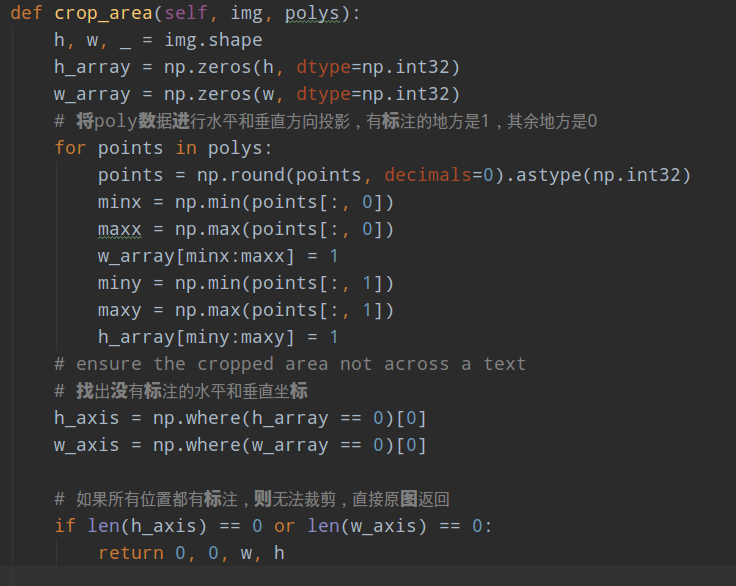
(3) RandomCropData
该类在data/processes/random_crop_data.py,其目的是对图片进行裁剪到指定的[640, 640]。由于斜框的特点,裁剪增强没那么容易做,本文采用的裁剪策略非常简单: 遍历每一个多边形标注,只要裁剪后有至少有一个poly还在裁剪框内,则认为该次裁剪有效。这个策略主要可以保证一张图片中至少有一个gt,且实现比较简单。
其具体流程是:
1 将每张图片的所有poly数据进行水平和垂直方向投影,有标注的地方是1,其余地方是0
2 找出没有标注即0值的水平和垂直坐标h_axis和w_axis
3 如果全部是1,则表示poly横跨了整图,则直接返回,无法裁剪
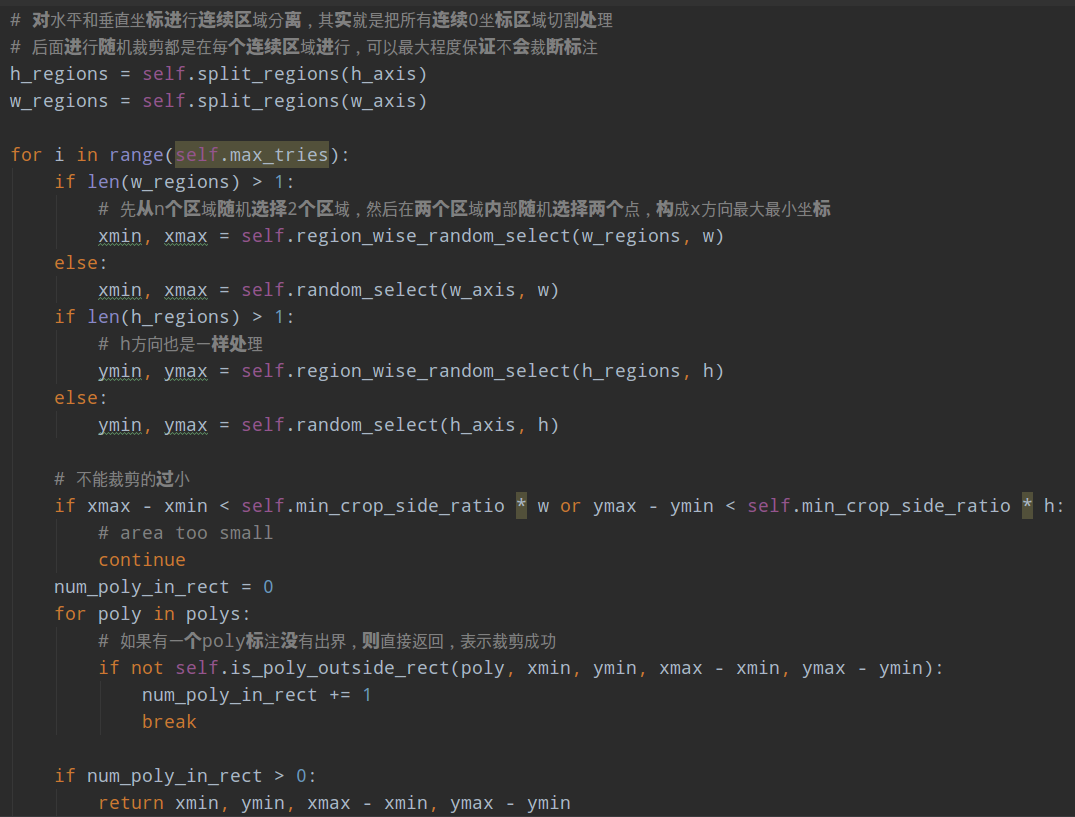
4 对水平和垂直坐标进行连续0区域分离,其实就是把所有连续0坐标区域切割处理变成List输出h_regions、w_regions
5 以w_regions为例,长度为n,先从n个区域随机选择2个区域,然后在这两个区域内部随机选择两个点,构成x方向最大最小坐标,h_regions也是一样处理,此时就得到了xmin, ymin, xmax - xmin, ymax - ymin值
6 判断裁剪区域是否过小;以及判断是否裁剪框内部是否至少有一个标注在内部,没有被裁断,如果条件满足则返回上述值,否则重复max_tries次,直到成功
代码如下:
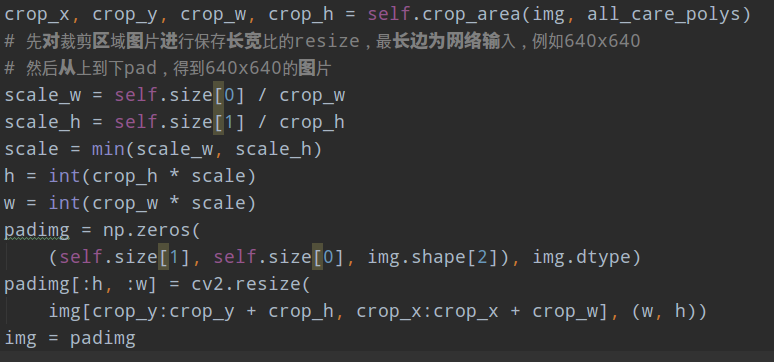
在得到裁剪区域后,就比较简单了。先对裁剪区域图片进行保存长宽比的resize,最长边为网络输入,例如640x640, 然后从上到下pad,得到640x640的图片
如果进行可视化,会显示如下所示:


可以看出,这种裁剪策略虽然简单暴力,但是为了拼接成640x640的输出,会带来大量无关全黑像素区域。
(4) MakeICDARData
该类在data/processes/make_icdar_data.py,就是简单的组织数据而已
OrderedDict(image=data['image'],
polygons=polygons,
ignore_tags=ignore_tags,
shape=shape,
filename=filename,
is_training=data['is_training'])
(5) MakeSegDetectionData
该类在data/processes/make_seg_detection_data.py,该类的功能是:将多边形数据转化为mask格式即概率图gt,并且标记哪些多边形是忽略区域
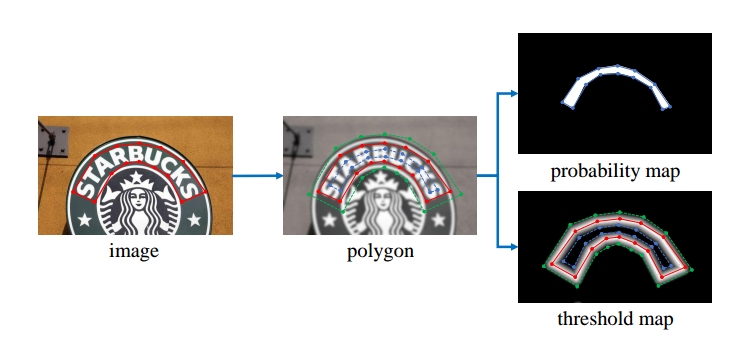
为了防止标注间相互粘连,不好后处理,区分实例,目前做法都是会进行shrink即沿着多边形标注的每条边进行向内缩减一定像素,得到缩减的gt,然后才进行训练;在测试时候再采用相反的手动还原回来。
缩减做法采用的也是常规的Vatti clipping algorithm,是通过pyclipper库实现的,缩减比例是默认0.4,公式是
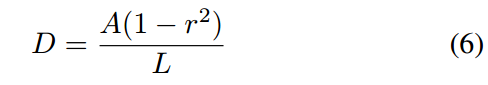
r=0.4,A是多边形面积,L是多边形周长,通过该公式就可以对每个不同大小的多边形计算得到一个唯一的D,代表每条边的向内缩放像素个数。
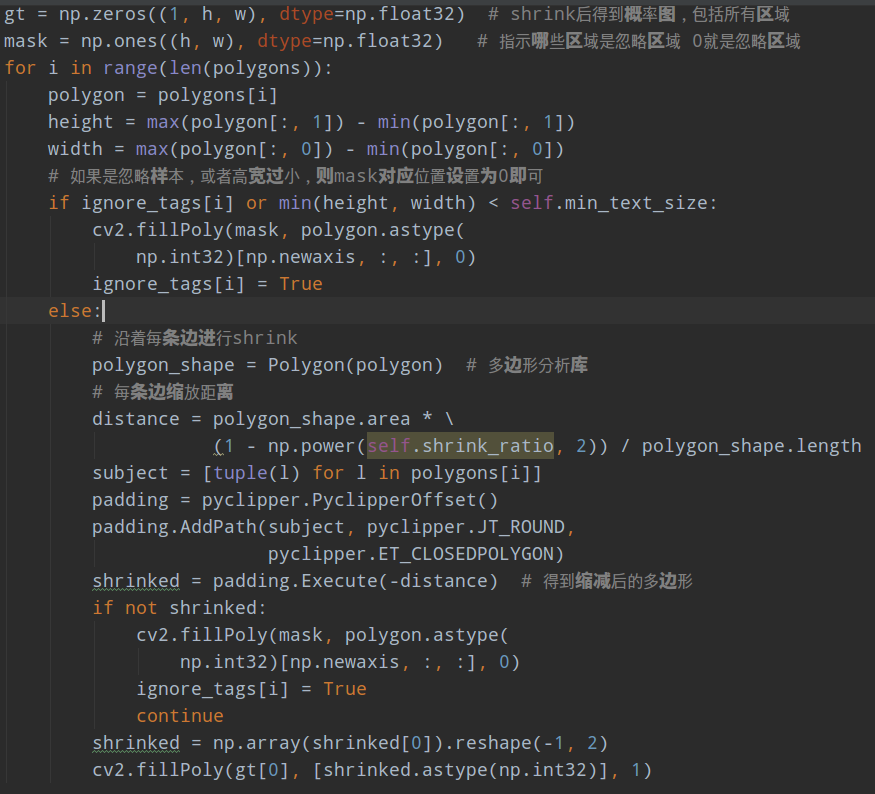
如果进行可视化,如下所示:

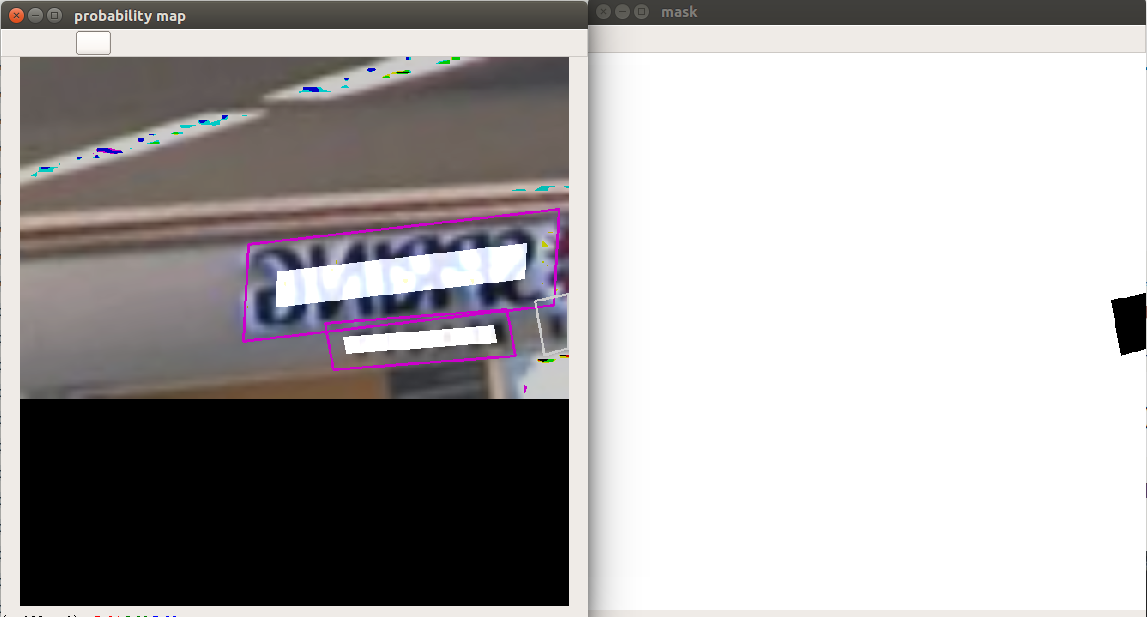
概率图内部全白区域就是概率图的label,右图是忽略区域mask,0为忽略区域,到时候该区域是不计算概率图loss的。
(6) MakeBorderMap
该类在data/make_border_map.py,目的是计算阈值图和对应mask。
仔细看阈值图的标注,首先红线点是poly标注;然后对该多边形先进行shrink操作,得到蓝线; 然后向外反向shrink同样的距离,得到绿色;阈值图就是绿线和蓝色区域,以红线为起点,计算在绿线和蓝线区域内的点距离红线的距离,故为距离图。
其代码的处理逻辑是:
1 对每个poly进行向外扩展,参数和向内shrink一样,然后对扩展后多边形内部填充1,得到对应的mask
2 为了加快计算速度,对每条poly计算最小包围矩,然后在裁剪后的图片内部,计算每个点到poly上面每条边的距离
3 只保留0-1值内的距离值,其余位置不用
4 把距离图贴到原图大小的图片上,如果和其余poly有重叠,则取最大值
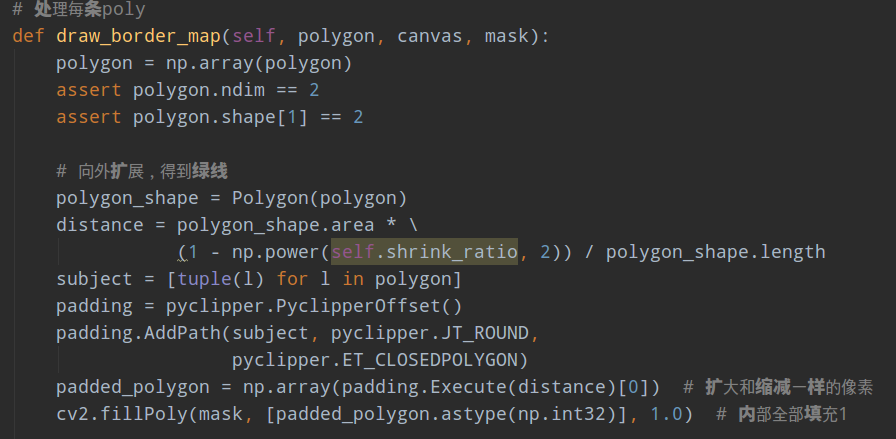
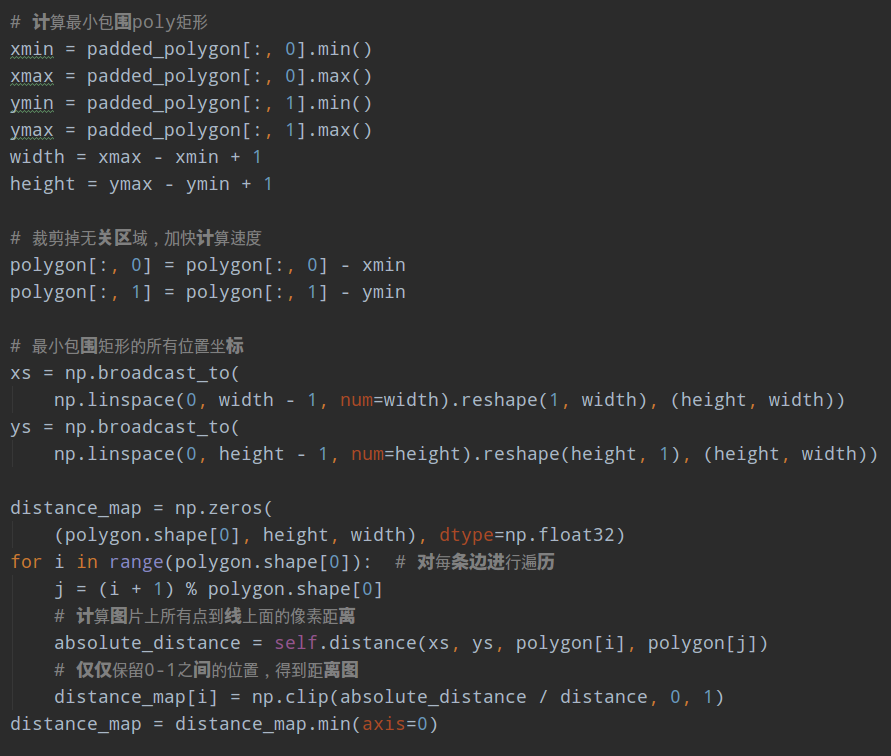
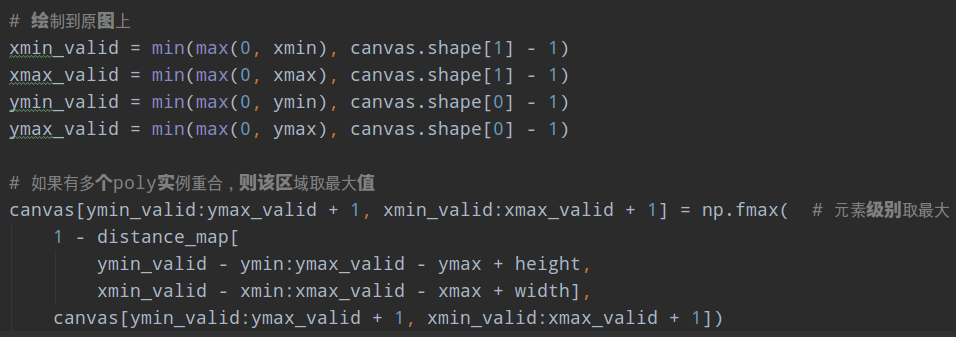
5 为了使得后续阈值图和概率图进行带参数的sigmod操作,得到近似二值图,需要对阈值图的取值范围进行变换,具体是将0-1范围变换到0.3-0.6范围
可视化如下所示:
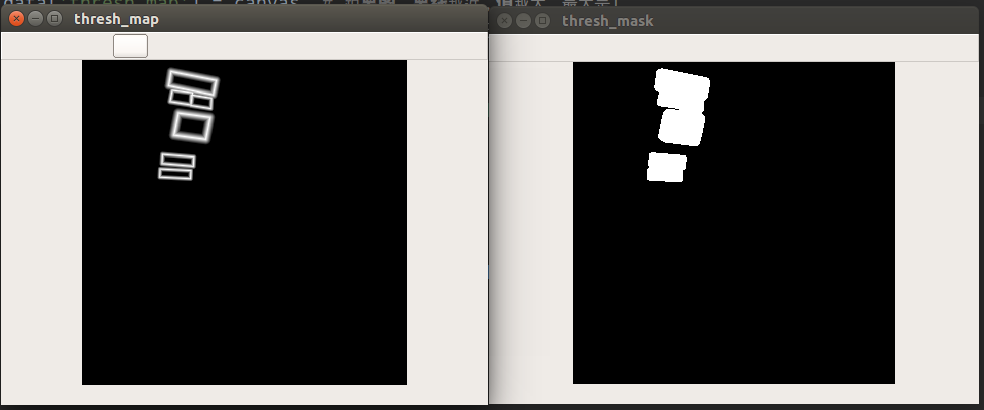
采用matpoltlib绘制距离图会更好看
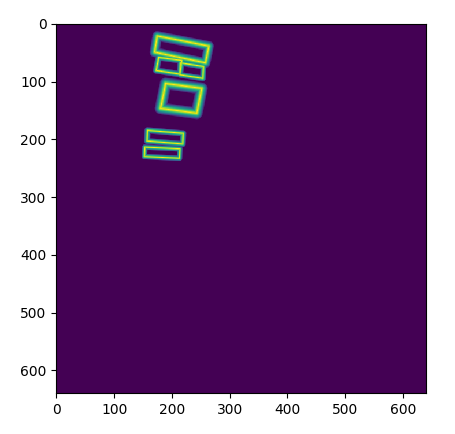
(7) NormalizeImage和FilterKeys
这两个类就没啥说的了,就是归一化图片和删除后续不用的字段而已。
至此,就可以得到概率图、概率图对应mask,阈值图和阈值图对于的mask,而近似二值化图的label也是概率图。
1.5 推理逻辑
配置如下:
如果不考虑label,则其处理逻辑和训练逻辑有一点不一样,其把图片统一resize到指定的长度进行预测。
前面说过阈值图分支其实可以相当于辅助分支,可以联合优化各个分支性能。故在测试时候发现概率图预测值已经蛮好了,故在测试阶段实际上把阈值图分支移除了,只需要概率图输出即可。
后处理逻辑在structure/representers/seg_detector_representer.py,本文特色就是后处理比较简单,故流程为:
1 对概率图进行固定阈值处理,得到分割图
2 对分割图计算轮廓,遍历每个轮廓,去除太小的预测;对每个轮廓计算包围矩形,然后计算该矩形的预测score
3 对矩形进行反向shrink操作,得到真实矩形大小;最后还原到原图size就可以了

采用作者提供的训练好的权重进行预测,可视化预测结果如下所示:


测试icdar2015数据,可以得到如下输出:
[INFO] [2020-07-10 10:11:57,999] precision : 0.877384 (500)
[INFO] [2020-07-10 10:11:57,999] recall : 0.775156 (500)
[INFO] [2020-07-10 10:11:57,999] fmeasure : 0.823108 (1)
符合论文里面的指标。论文中指标截图:
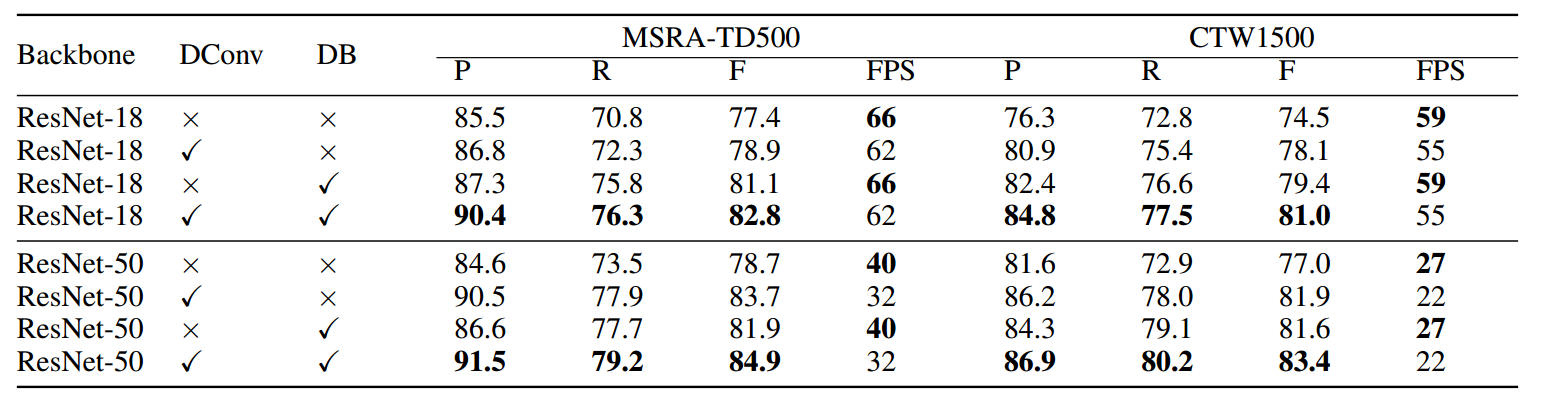
可以看出变形卷积和阈值图对整个性能都有比较大的促进作用。

2 总结
本文通过从原理和实现细节方面详细讲解了本算法。可以看出,本文思路还是非常清晰的,代码质量也比较高,效果也很不错,推荐大家可以去看看。由于本人水平有限和码子比较多,可能有些小错误,欢迎批评和指正。
