@huanghaian
2020-03-19T11:57:02.000000Z
字数 5323
阅读 1807
Libra R-CNN
目标检测
论文名称:Libra R-CNN: Towards Balanced Learning for Object Detection cvpr2019
开源地址:mmdetection
简介
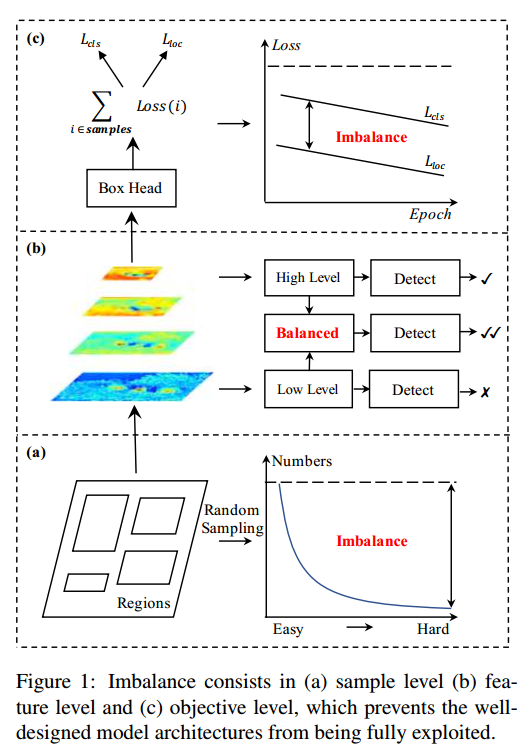
本文做的非常好,无痛涨点,实现简单,良心paper。在基本不增加参数和代码情况下,仅仅依靠训练策略就提升了2个点,非常厉害。同时论文写的非常清晰,非常容易理解,代码也容易理解。
主要是提出了三个不平衡:
- sample level
- feature level
- objective level
这就对应了三个问题:
- 采样的候选区域是否具有代表性?
- 提取出的不同level的特征是怎么才能真正地充分利用?
- 目前设计的损失函数能不能引导目标检测器更好地收敛?
对应的三个改进
- IoU-balanced Sampling
- Balanced Feature Pyramid
- Balanced L1 Loss
详情
纵观目前主流的目标检测算法,无论SSD、Faster R-CNN、Retinanet这些的detector的设计其实都是三个步骤:
- 选择候选区域
- 提取特征
- 在muti-task loss下收敛
作者在实验发现这三个阶段都可能存在不平衡,故针对不同阶段的不平衡,都提出了对应的解决办法。
1 IoU-balanced Sampling
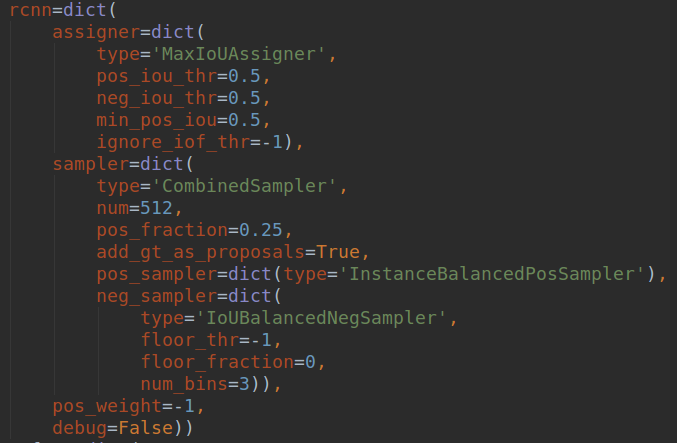
注意这里说的不平衡是指的rcnn这一级别,而不包括rpn,原因是作者的主要目的是为了涨点mAP,作者认为rpn涨几个点对作者bbox 预测map没有多大帮助,因为主要是靠rcnn部分进行回归预测才能得到比较好的mAP,所以作者加的iou 平衡采样是对rcnn而言。
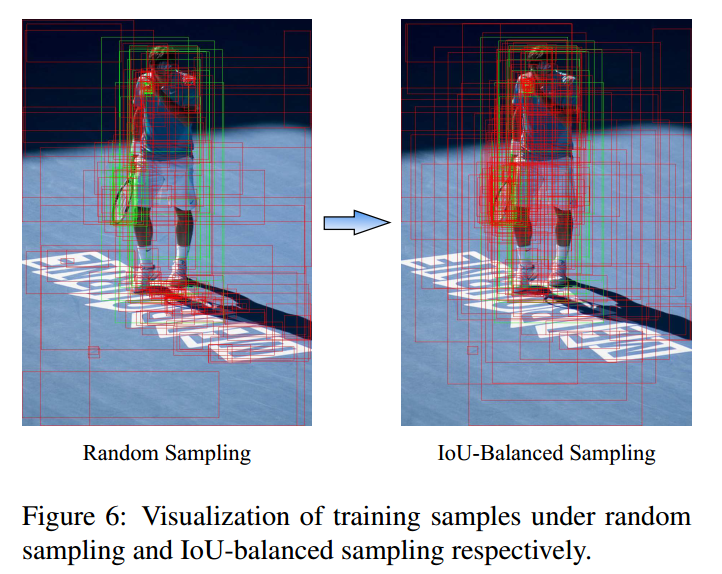
作者认为sample level的不平衡是因为随机采样造成的,OHEM(online hard example mining,在线困难样本挖掘)是一个hard negative mning 的一种好方法,但是这种方法对噪音数据会比较敏感,而且参数比较难调,不太好用。随机采样造成的不平衡可以看下图:
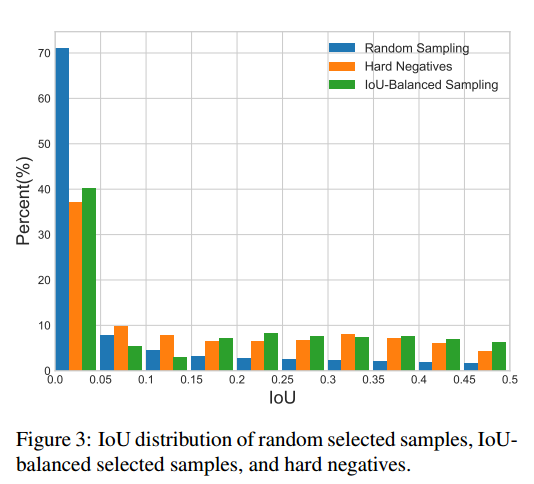
上面绘制的都是负样本,因为iou低于0.5,由于样本的本身不均匀性,作者发现了如果是随机采样的话,随机采样到的样本超过70%都是在IoU在0到0.05之间的,都是易学习负样本,作者觉得这里就是不科学的地方,统计得到的事实是60%的hard negative都落在IoU大于0.05的地方,但是随机采样只提供了30%。所以作者提出了IoU-balanced Sampling。具体公式就不贴了,反正意思就是对负样本按照iou划分k个区间,每个区间都是尽量均匀采样,保证易学习负样本和难负样本比例尽量平衡,具体做法是对所有负样本计算和gt的iou,并且划分K个区间后,在每个区间内均匀采样就可以了。假设分成三个区间,我想总共取9个,第一个区间有20个候选框,第二个区间有10个,第三个区间有5个,那这三个区间的采样概率就是9/(3x20),9/(3x10),9/(3x5),这样的概率就能在三个区间分别都取3个,因为区间内候选框多,它被选中的概率小,最终体现各个区间都选这么多框。实际代码没有这样写:首先按照iou分成k个区间,先尝试在不同区间取随机采样采相同多数目的样本,如果不够就全部采样;进行一轮后,如果样本数不够,再剩下的样本中均匀随机采样。例如假设总共有1000个候选负样本(区间1:800个,区间2:120个,区间3:80个),分为3个区间,总共想取333个,那么理论上每个区间是111个,首先第一次在不同区间均匀采样,此时区间1可以采样得到111个,区间2也可以得到111个,区间3不够,所以全部保留;然后不够的样本数,在剩下的689+9个里面随机取31个,最终补齐333个。
2 Balanced Feature Pyramid
eature level的不平衡表现在low/high level 特征的利用上,如何利用不同分辨率的特征,分为了四步:rescaling,integrating,refining,strengthening。
说的比较高端,作者的通俗解释是High-level和low-level的feature对于目标检测是complementary的。怎么样把这些feature更好的integrate起来送给后面的bbox head识别其实很重要。尤其是在不同resolution的feature share了同一个bbox head的情况下,如果他们的variance特别大,其实不利于同一个bbox head的识别(类似于normalizaiton的效果)。于是我们均衡地去把不同resolution的feature integrate起来,用这个feature来enhance最初的pyramid。注意单纯这个操作其实没有引入什么计算,全部通过插值/pooling来实现的,在最终的AP上看到了相应的提升,也证明了这种information flow的有效性。
看下图就一目了然了:
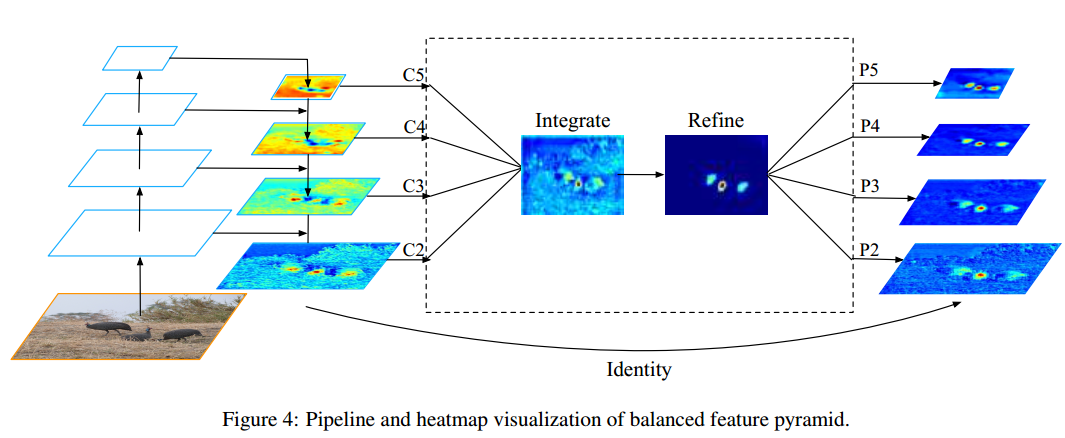
其中refine模块作者采用的是Non-local模块,但是后来在实验中发现其实采用卷积也可实现类似性能
直接看代码吧,比较简单
@NECKS.register_module
class BFP(nn.Module):
"""BFP (Balanced Feature Pyrmamids)
BFP takes multi-level features as inputs and gather them into a single one,
then refine the gathered feature and scatter the refined results to
multi-level features. This module is used in Libra R-CNN (CVPR 2019), see
https://arxiv.org/pdf/1904.02701.pdf for details.
Args:
in_channels (int): Number of input channels (feature maps of all levels
should have the same channels).
num_levels (int): Number of input feature levels.
conv_cfg (dict): The config dict for convolution layers.
norm_cfg (dict): The config dict for normalization layers.
refine_level (int): Index of integration and refine level of BSF in
multi-level features from bottom to top.
refine_type (str): Type of the refine op, currently support
[None, 'conv', 'non_local'].
"""
def __init__(self,
in_channels,
num_levels,
refine_level=2,
refine_type=None,
conv_cfg=None,
norm_cfg=None):
super(BFP, self).__init__()
assert refine_type in [None, 'conv', 'non_local']
self.in_channels = in_channels
self.num_levels = num_levels
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.refine_level = refine_level
self.refine_type = refine_type
assert 0 <= self.refine_level < self.num_levels
if self.refine_type == 'conv':
self.refine = ConvModule(
self.in_channels,
self.in_channels,
3,
padding=1,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg)
elif self.refine_type == 'non_local':
self.refine = NonLocal2D(
self.in_channels,
reduction=1,
use_scale=False,
conv_cfg=self.conv_cfg,
norm_cfg=self.norm_cfg)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
xavier_init(m, distribution='uniform')
def forward(self, inputs):
assert len(inputs) == self.num_levels
# step 1: gather multi-level features by resize and average
feats = []
gather_size = inputs[self.refine_level].size()[2:]
for i in range(self.num_levels):
if i < self.refine_level:
gathered = F.adaptive_max_pool2d(
inputs[i], output_size=gather_size)
else:
gathered = F.interpolate(
inputs[i], size=gather_size, mode='nearest')
feats.append(gathered)
bsf = sum(feats) / len(feats)
# step 2: refine gathered features
if self.refine_type is not None:
bsf = self.refine(bsf)
# step 3: scatter refined features to multi-levels by a residual path
outs = []
for i in range(self.num_levels):
out_size = inputs[i].size()[2:]
if i < self.refine_level:
residual = F.interpolate(bsf, size=out_size, mode='nearest')
else:
residual = F.adaptive_max_pool2d(bsf, output_size=out_size)
outs.append(residual + inputs[i])
return tuple(outs)
其实就是对5个输出特征图进行聚合操作,然后对聚合特征进行加强(non local),然后恒等变换返回到合并前的5个特征图上。
3 Balanced L1 Loss
Fast R-CNN中是通过multi-task loss解决Classification(分类)和Localization(定位)的问题的,目标检测本质上还是一个多任务task,既要识别相应的类别,也要精准定位,那么他们两个在训练过程总的balance就比较tricky,但一味的提高regression的loss其实会让outlier的影响变大(类似于OHEM中的noise label)。于是我们通过特定的enhance比较重要部分的梯度来让这个过程更加smooth,在几个方面寻找一个相对balance的case。单纯的loss在Faster R-CNN上其实可以提升1.2个点,还算是比较明显。作者解释是之所以会提出Balanced L1 loss,是因为这个损失函数是两个loss的相加,如果分类做得很好地话一样会得到很高的分数,而导致忽略了回归的重要性,一个自然的想法就是调整权重的值。我们把样本损失大于等于1.0的叫做outliers,小于的叫做inliers。由于回归目标是没有边界限制的,直接增加回归损失的权重将会使模型对outliers更加敏感。对于outliers会被看作是困难样本(hard example),这些困难样本会产生巨大的梯度不利于训练得过程,而inliers被看做是简单样本(easy example)只会产生相比outliers大概0.3倍的梯度。
作者设计平衡loss的目的是即不要受到外点影响,又要对难内点样本增加权重。即想要得到一个梯度当样本在 附近产生稍微大点的梯度
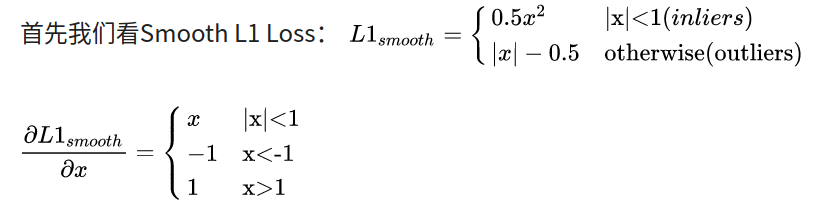
首先L _loc可以定义为如下通用表达式子,更新求导法则,可以得到(6)的关系,为了让1附件的梯度大一点,作者想到了公式(7),然后反算,就可以得到 L _ loss表达式了。

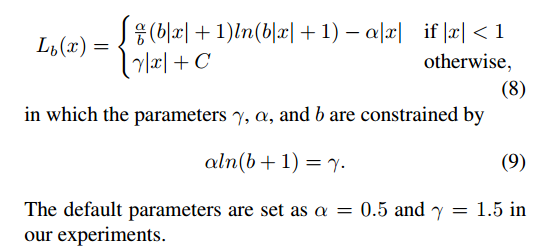
为了函数的连续性,作者设置了(9)的约束。
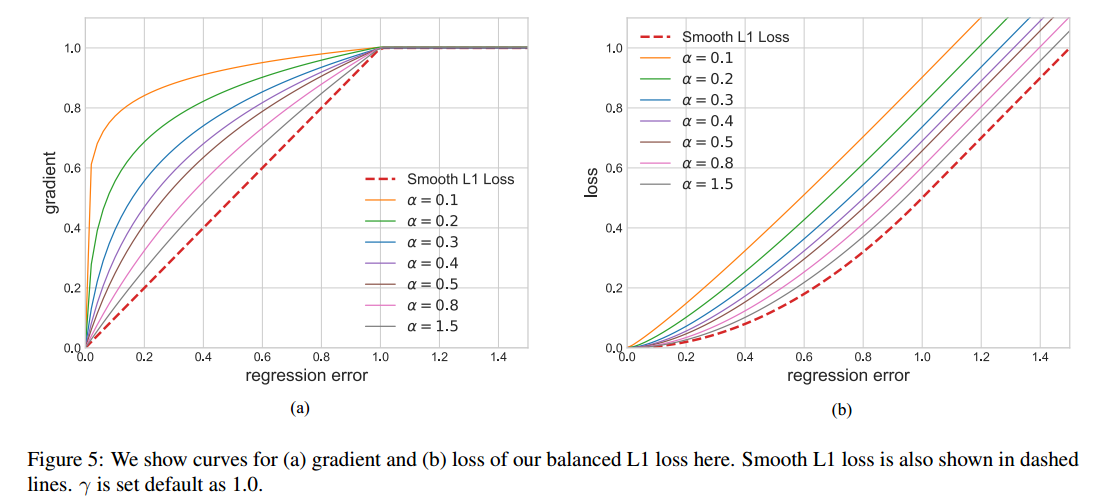
左边是梯度曲线,右边是loss曲线,可以看出非常巧妙。
实验结果
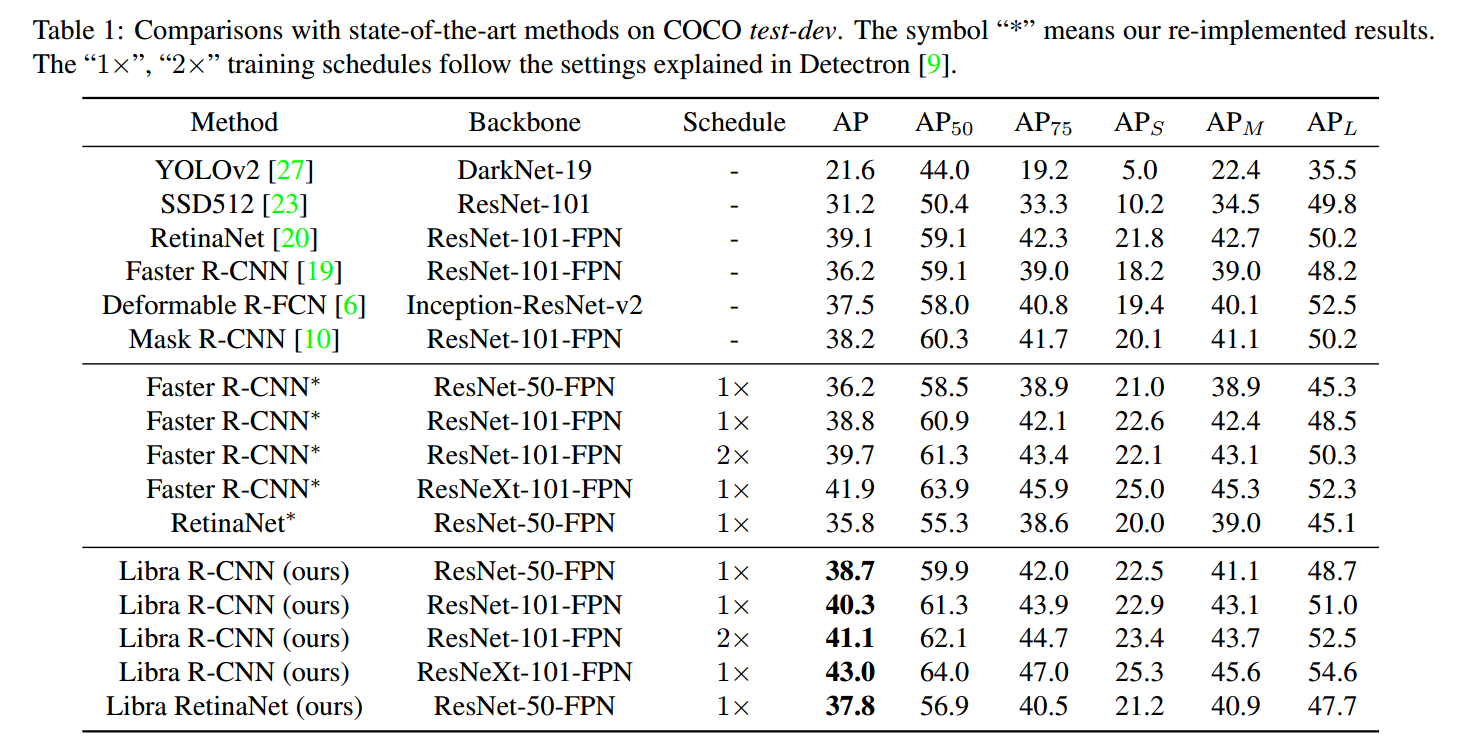
不可谓不强。

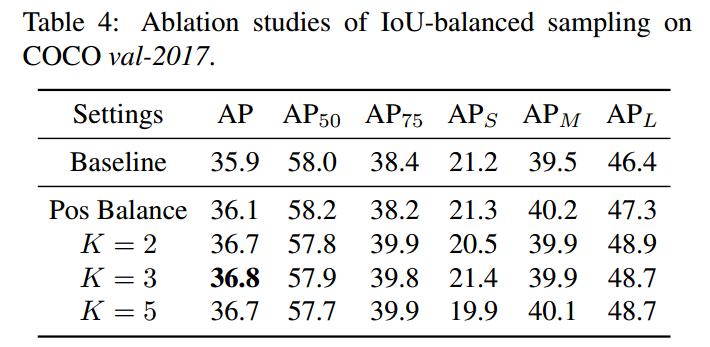
对K不敏感,作者设置为3.
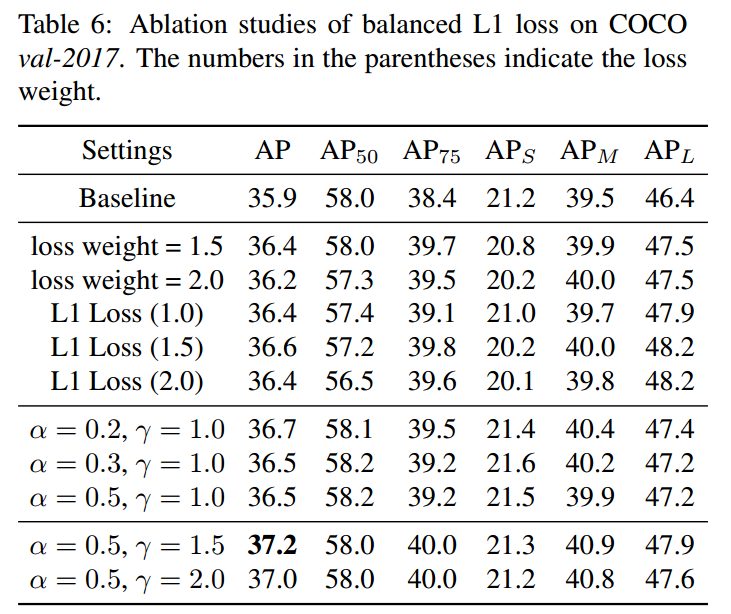
该参数设置还是对性能有些影响。
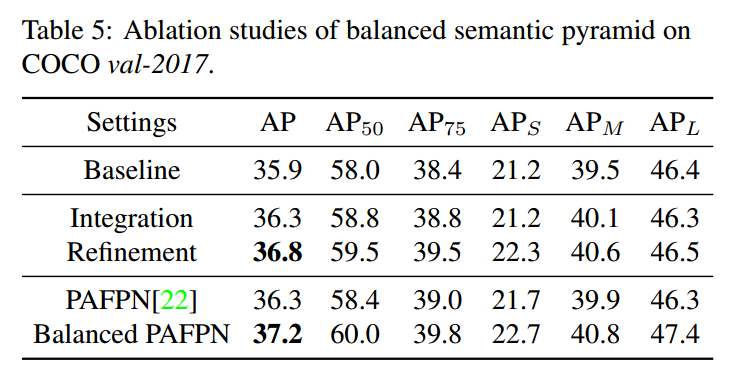
可以看出即使没有refine模块,仅仅是合并和分离操作也可以提升。加了refine可以进一步提升。
总结
可以看出是良心论文,在几乎不改变结构情况下,通过新增3个改善不平衡策略,普遍提高2个点,实在难得。
