@huanghaian
2020-09-16T12:01:34.000000Z
字数 8032
阅读 5306
mmdetection最小复刻版(一):整体概览
mmdetection
mmdetection最小复刻版是基于mmdetection的最小实现版本简称mmdetection-mini。其出现的目的是通过从头构建整个框架来熟悉所有细节以及方便新增新特性。计划新增的新特性例如可视化分析;核心细节加入tensorboard;darknet权重和mmdetection权重转换;新loss实现以及新增算法等等。如果各位有新的想法,可以和我交流。
github: https://github.com/hhaAndroid/mmdetection-mini
欢迎star
本文是整个框架介绍的第一篇,主要包括框架说明;整个结构说明;Resize、Registry、FileClient、GroupSampler、collate等部分的解读。下一篇步入正题:retinanet和yolo系列核心解读,可视化分析等等。
我所分析的代码,在框架中对应代码位置都有非常详细的代码注释,欢迎围观和质疑。
由于本人水平有限,有些地方理解可能有错误,欢迎指正。也欢迎对本框架细节的提问和意见,我会一直维护更新。
0 为何而生
很多人可能有疑问:mmdetection那么好用,你为啥要自己又写一遍呢?没事干?其实不然,基于我目前的理解,出于一下几点原因:
- 学习目的
mmdetection无疑是非常优异的目标检测框架,但是其整个框架代码其实非常多。我希望通过从0构建整个
结构,来彻底熟悉整个框架,而不是仅仅熟悉算法部分。只有自己写一遍才能发现一些容易忽略的细节 - 方便注释
这一点,我相信很多人都碰到过。主要原因是mmdetection发展太快了,更新特别频繁,比如今天我拉了最新分支
加入了我的一些理解注释,过了两天,一更新就发现完全变了,此时再pull就出现很多冲突。天天解决这些冲突其实蛮累的。所以我自己写一个mmdetection,然后加入注释,并且实时同步mmdetection到最新版,不仅可能清楚每次更新的
所有细节,还可以不影响注释 - 新特性方便增加
如果自己想实现一些mmdetection里面没有的新特性,就非常方便了。比如我要在debug模式下进行可视化分析,
如果直接加到mmdetection上面,会改动一些代码,一旦pull又有冲突。由于同步mmdetection过程是手动的,新增特征
也不会出现冲突
1 介绍
完全基于mmdetection框架结构,包括整个结构也是完全一样的,但是稍有不同,简称mmdet最简学习版,基于最简实现,第一原则就是简洁,不会加入一些乱七八糟的功能,一步一步构建一阶段目标检测器。
主要目的为在从0构建整个框架的基础上,掌握整个目标检测实现细, 并且方便新增自己想要实现的部分。
由于只有一张显卡,故不支持分布式训练。
总之:本项目目的是学习,希望通过从0构建每一行代码,来熟悉每个部分,而且自己写的框架,后续我新增一些新特性也非常容易。
更新可能是快时慢,在掌握每个细节后才会增加新代码,欢迎有兴趣的朋友共同学习,也欢迎提出意见。
2 mmdetection和mmdetection-mini区别
整个框架结构和mmdetection完全相同,既然自己重写,为啥要完全一样?主要目的是为了每天方便快速的和mmcv/mmdetection同步更新。如果我结构改变了,那么同步会有点点麻烦。
细节方面有些不同,主要是:
- 把mmcv嵌入其中
我不想同时维护两个库的更新,比较累。故把mmcv的核心代码全部移植到一个框架中,目录为mmdet.cv_core。 - 删除了一些代码
主要是分布式以及一些我不需要的代码 - 仅仅包括一阶段目标检测算法
当然要新增二阶段算法也是非常容易,毕竟完全一样嘛 - 新增一些自己的想法
这个是最核心的。我希望在这个基础上做一些实验,验证一些自己的想法,而不想改动mmdetection,毕竟他更新太快了
3 核心代码解读(截止20200916)
以下分析的内容是基于目前最新更新日期20200916,对代码的分析。由于mmdetction会实时更新,可能我这里说的一些特性后续会更改。所有分析都有对应的代码注释,都在mmdetection-mini中。
mmdetection源码分析千千万万,我没有必要重复劳动,再写一遍。故这里写的都是我自认为比较关键的,需要理解的部分。做个记录也不错。
一旦mmdetection进行更新,且和本文不一致,我会实时同步。
由于是个人学习记录笔记,故可能不是非常规范,啥都有。
3.1 Registry
mmdetection的一个非常大的特色是注册器机制。要理解mmdetection,第一步就是理解Registry,其有两种用法:
backbones = Registry('backbone')
@backbones.register_module()
class ResNet:
pass
定义一个类,然后在上方采用@xx..register_module()的方式注册
ACTIVATION_LAYERS.register_module(module=nn.ReLU)
直接注册自己实现或者任何地方已经实现的类到注册器中
一旦注册进去了,那么在配置里面就可以通过dict(type='类名',类参数)方式实例化指定类(具体是通过build_from_cfg函数解析并且实例化)。
这种方式的好处是:扩展性非常强,解耦性也很好。
其核心原理就是简单的装饰器。Registry类把python装饰器功能封装为了类,原因是类可以存储实例对象。真正起作用的还是装饰器函数register_module,其返回一个装饰器函数。
3.2 防止图片错误时候程序停止训练
在dataset的getitem方法里面:
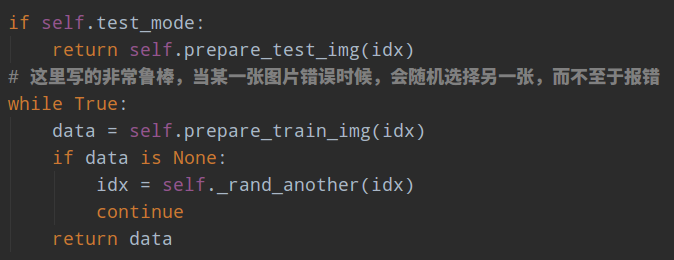
3.3 FileClient作用
fileClient也叫作文件后端,主要目的是对文件进行加速缓存读取,尽可能减少io读取耗时,特别是机械硬盘上会显著影响。以常规的LmdbBackend为例,lmdb是一个Lightning Memory-Mapped Database 快如闪电的内存映射数据库。lmdb库的使用需要将数据集先制作成lmdb的格式,然后就可以采用lmdb快速索引,图片的读取就可以省略了。
可以简单参考https://blog.csdn.net/dulingtingzi/article/details/79585180看下如何生成lmdb
lmdb会遍历图片,然后采用文件名作为key,图片字节码作为value高效存储,保存为一个文件,有点类似tfrecord。在后续get读取时候就不需要再频繁io读取了,只需要从生成的文件中读取一次,然后再进行图片字节解码即可。
但是我们常用的是pytorch自带的dataloader+dataset,采用lmdb格式的意义可能就仅仅是省略掉图片io读取的时间,但是图片解码还是需要的,就像mmdetection里面用法一样。
和我们息息相关的,mmdetection实现的主要是:
- HardDiskBackend
这个是默认使用的,其实就是啥也没有做的,没有缓存,每次都是从硬盘里面把图片字节码读取处理即可。 - MemcachedBackend
采用了python的第三方库memcached 实现对文件名和图片字节进行实时存储,内存自动管理。这个库比较庞大,功能非常强,需要提前开启缓存服务器,然后在客户端运行(服务器程序和客户端可以在同一个机器),可能在一些复杂场景会用到 - LmdbBackend
前面已经说过了。
还有支持分布式的backend,mmlab内部训练会用,由于比较高深且用不到,就不分析了。
上述代码如何使用,可以看mmcv的test文件,其有对fileclinet进行单元测试。
这里涉及一个新的知识点:mock。Mock是Python中一个用于支持单元测试的库,它的主要功能是使用mock对象替代掉指定的Python对象,以达到模拟对象的行为
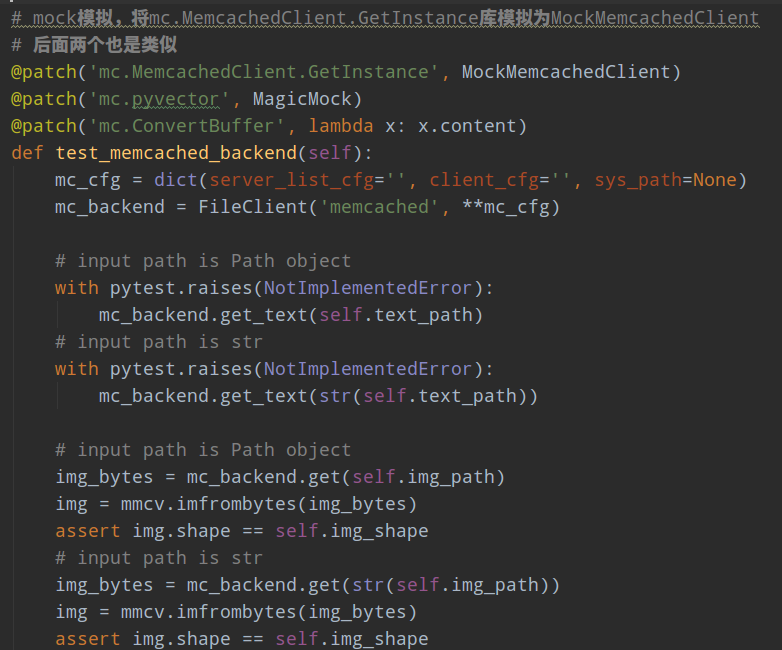
假设我要测试MemcachedBackend功能,但是这个类要成功运行需要安装一大堆库,自己内部测试还好,可以安装该库进行测试,但是如果大家都需要进行测试,比较麻烦。故可以采用python内部单元测试提供的mock功能,可以对库进行模拟。这里就是如此。测试MemcachedBackend,会用到mc.MemcachedClient.GetInstance等等共3个函数或者类,这里采用patch加入模拟库
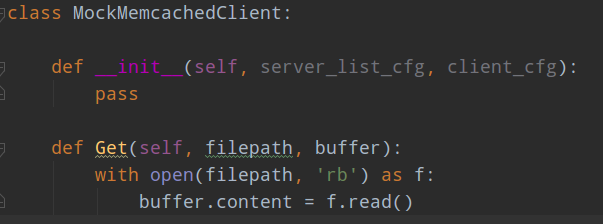
from unittest.mock import MagicMock, patch
就可以实现模拟测试。
mock测试一个非常典型的例子是:我想测试删除文件功能,如果删除了,那么下次测试就无法测试了。所以我可以mock一个删除功能,模拟测试。
简单理解有这种测试方式就行,咱们本身不做测试。简单使用说明:https://www.cnblogs.com/Zzbj/p/10594633.html
3.4 Resize
由于这个类写的功能比较多,需要总结下用法。
第一种用法:
transform = dict(type='Resize', img_scale=(1333, 800), keep_ratio=True)
将图片保持比例的resize到图片长短边都在指定的img_scale范围。不同大小的输入图片,输出的图片size是不一样的,如果不保持比例,则说明img_scale是目标图片的w,h,直接对图片resize到指定的img_scale即可,输出图片大小都是一样的。
transform = dict(type='Resize', img_scale=[(1333, 800), (1333, 600)], keep_ratio=True)
如果img_scale是list,说明是多尺度resize,内部有两种做法,通过multiscale_mode参数来控制,默认是range。如果是'range',则表示从多尺度里面随机插值一个新尺度,例如上述,其会组成短边[600,800]和长边[1333,1333],然后基于这两个list插值出新的scale;如果是‘value’模式,则是仅仅随机从多尺度列表里面选择其中一个。
transform = dict(
type='Resize',
img_scale=(1333, 800),
ratio_range=(0.9, 1.1),
keep_ratio=True)
如果指定了ratio_range,则img_scale必须是单尺度,表示对指定的img_scale进行在指定范围内的随机,得到新scale。
如果img_scale是一个数,那么就直接表示缩放系数了。
可以看出Resize函数实现了非常多的功能,包括随机版本和非随机版本。
3.5 GroupSampler用途和缺点
分组采样的作用是将长宽比大于1和小于1的图片分成两组,在组成batch的时候将同一组的图片组成batch返回,好处是后面的pad操作不会引入比较多的黑边(由于其datalayer的输出是不定shape的图片,所以需要pad)。
分组采样需要dataset里面有每个样本的flag标志。但是其实有个小问题:flag是在图片读取的时候确定的,但是如果中间的数据增强比较剧烈,导致长宽比变化了,那么可能flag表示是错误的,但是框架没有处理,也就是默认不会出现这种情况,属于一个坑。目前的mmdetection采用的数据增强很少,不会出现这种情况,但是如果我自己想试试其他模型,并且引入了比较强的数据增强的话,虽然这个类不会报错,但是用途也很少了。
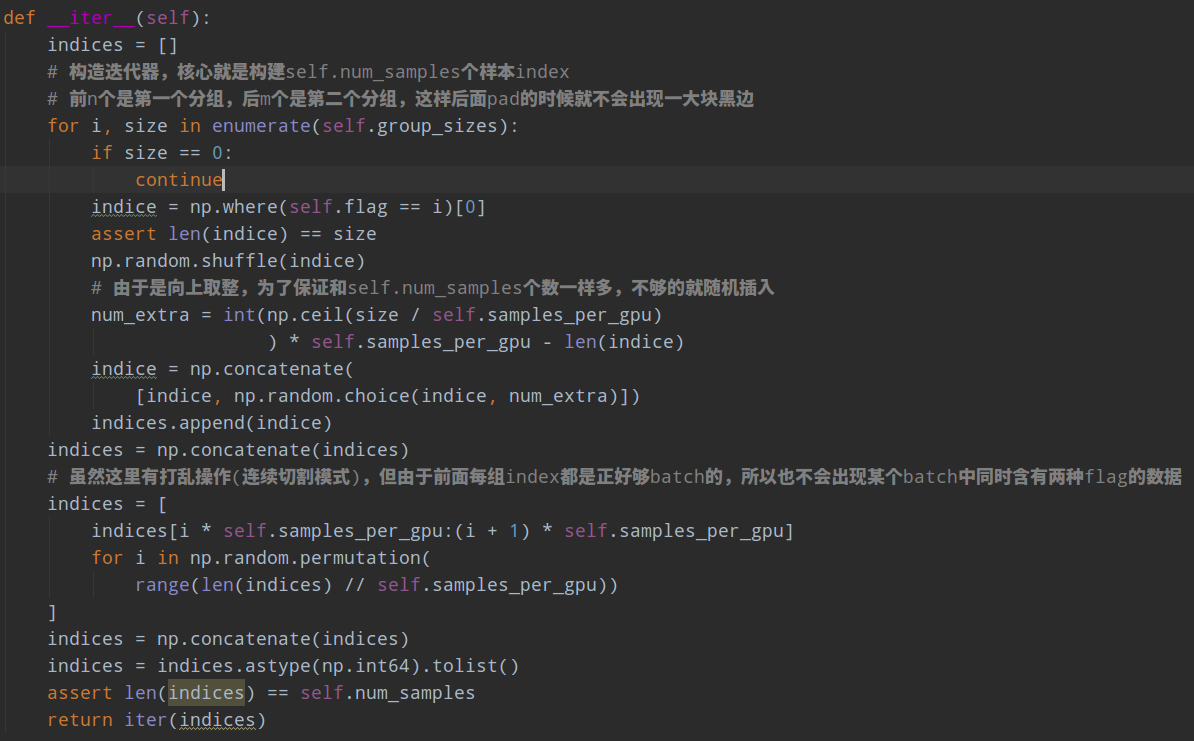
正确做法应该是对于长宽比改变的数据增强操作,其对应图片的flag也要跟着改变。这个问题或许mmdetection后面会解决。
3.6 collate分析
为啥要有samples_per_gpu参数?
原因:为了分布式多卡训练而设置。单卡训练模式没有意义
假设一共4张卡,每张卡8个样本,故dataloader吐出来的batch=32,但是分组采样时候是对单batch而言的,也就是说这里收集到的32个batch其实分成了4组,4组里面可能存在flag不一样的组,如果这里不对每组进行单独操作,那么其实前面写的分组采样GroupSampler功能就没多大用途了。本函数写法会出现4个组输出的shape不一样,但是由于是分配到4块卡上训练,所以大小不一样也没有关系,保持单张卡内shape一样就行。
所以对于单卡训练场景,len(batch)=samples_per_gpu,这里的for循环没有意义,可以删掉。但是需要注意的是在batch 测试模式下,最后一个batch可能不会相等,但是不影响测试。
3.7 MMDataParallel
这个类是继承至DataParallel,本来应该也是支持多卡训练的,但是由于mmdetection里面强制将多卡训练设置为分布式,故这个类只能用于单卡训练。
其作用: 将dataloader吐出来的含有dc格式的数据去掉,变成网络能够吃的数据。
train/val和test的运行逻辑有区别。
在train或者val模式下,运行逻辑是:
1. 首先在runner里面
outputs = self.model.train_step(data_batch, self.optimizer,
**kwargs)
2. 其首先调用MMDataParallel.train_step
这个函数的核心功能就是把dc格式的数据去掉,变成tensor
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
3. 然后调用model本身的train_step,位于base.py里面
losses = self(**data) # 调用forward
loss, log_vars = self._parse_losses(losses)
在test模式下,运行逻辑是:
1.没有runner了,其首先调用MMDataParallel.forward,
在gpu模式下,啥也不干,直接
return super().forward(*inputs, **kwargs) # 调用DataParallel.forward
2. dataparallel.forward在单卡下,核心函数是:
inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
由于MMDataParallel复写了这个函数,故实际调用依然是MMDataParallel自己的scatter,作用也就是把
带dc格式的数据去掉,变成tensor
3. 然后调用model本身的forward,位于base.py里面
if return_loss:
return self.forward_train(img, img_metas, **kwargs)
else:
return self.forward_test(img, img_metas, **kwargs)
3.8 anchor分析
见知乎文章:https://zhuanlan.zhihu.com/p/161463275
本框架也集成了anchor分析,并且更加完善。具体是tools/anchor_analyze.py
3.9 MaxIoUAssigner匹配规则
见知乎文章:https://zhuanlan.zhihu.com/p/138824387
MaxIoUAssigner的操作包括4个步骤:
- 首先初始化时候假设每个anchor的mask都是-1,表示都是忽略anchor
- 将每个anchor和所有gt的iou的最大Iou小于neg_iou_thr的anchor的mask设置为0,表示是负样本(背景样本)
- 对于每个anchor,计算其和所有gt的iou,选取最大的iou对应的gt位置,如果其最大iou大于等于pos_iou_thr,则设置该anchor的mask设置为1,表示该anchor负责预测该gt bbox,是高质量anchor
- 3的设置可能会出现某些gt没有分配到对应的anchor(由于iou低于pos_iou_thr),故下一步对于每个gt还需要找出和最大iou的anchor位置,如果其iou大于min_pos_iou,将该anchor的mask设置为1,表示该anchor负责预测对应的gt。通过本步骤,可以最大程度保证每个gt都有anchor负责预测,如果还是小于min_pos_iou,那就没办法了,只能当做忽略样本了。从这一步可以看出,3和4有部分anchor重复分配了,即当某个gt和anchor的最大iou大于等于pos_iou_thr,那肯定大于min_pos_iou,此时3和4步骤分配的同一个anchor。
从上面4步分析,可以发现每个gt可能和多个anchor进行匹配,每个anchor不可能存在和多个gt匹配的场景。在第4步中,每个gt最多只会和某一个anchor匹配,但是实际操作时候为了多增加一些正样本,通过参数gt_max_assign_all可以实现某个gt和多个anchor匹配场景。通常第4步引入的都是低质量anchor,网络训练有时候还会带来噪声,可能还会起反作用。
简单总结来说就是:如果anchor和gt的iou低于neg_iou_thr的,那就是负样本,其应该包括大量数目;如果某个anchor和其中一个gt的最大iou大于pos_iou_thr,那么该anchor就负责对应的gt;如果某个gt和所有anchor的iou中最大的iou会小于pos_iou_thr,但是大于min_pos_iou,则依然将该anchor负责对应的gt;其余的anchor全部当做忽略区域,不计算梯度。该最大分配策略,可以尽最大程度的保证每个gt都有合适的高质量anchor进行负责预测,
3.10 tensorflow的same模式在pytorch中的实现
一定要注意:tf的same模式并不是左右两边都补0的,
如果你以为:pytorch中,如果kernel已知,然后pading设置为(kernel-1)//2,实现的输入和输出相等的操作,虽然实现了和tf的same相同的功能,但是其实效果是不一样的。pytorch中设置的pad参数,是只能实现左右两边同时填充的,而tf的same可能并不是。例如
输入是512x512,stride=2,kernel=3,按照tf的same模型,输出是256x256的,但是其补充的0其实是只是在右边和下面补充了1个像素,先pad成513x513的,然后conv后向上取整变成了256x256的输出;如果采用pytorch实现,pad=1,会先pad成514x514的输入,然后conv变成256x256的输出,可以看出如果按照上面实现,虽然输出一样了,但是pytorch的实现其实偏了两个像素。
也就是说如果你想直接用tf的权重,然后迁移到pytorch中,那么一定要注意same的实现,必须要手动先算出pad参数,利用F.pad函数先实现same功能,然后在进行conv,这样复现的结果才是完全一致的。
具体可以参考:https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch/blob/master/efficientnet/utils_extra.py
mmcv也有实现: https://github.com/hhaAndroid/mmdetection-mini/mmdet/cv_core/cnn/bricks/conv2d_adaptive_padding.py,我框架里面也同步了这个类。
再次贴链接 github: https://github.com/hhaAndroid/mmdetection-mini
欢迎star
