@huanghaian
2020-10-28T07:15:51.000000Z
字数 1757
阅读 1897
目标检测算法通用流程
mmdetection
训练流程
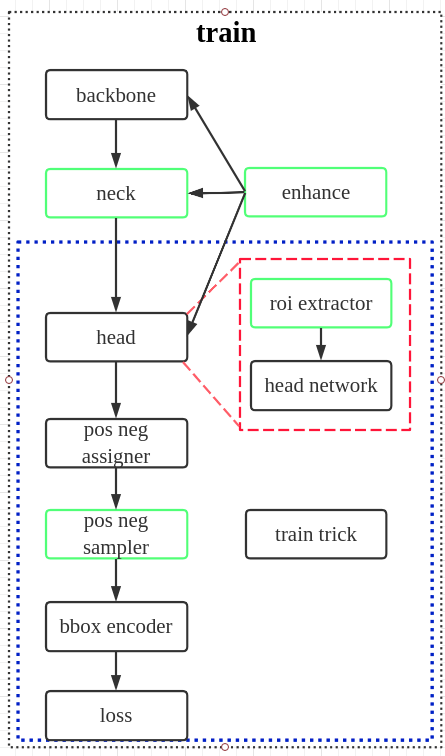
基于目前对主流目标检测流程梳理,大概可以将训练流程划分为以下几个步骤:
(1) backbone设计
骨架的设计至关重要,神经网络的神奇之处就在于自动特征提取。
输入流: 通常是一系列图片数据
输出流: 1个或者n(n>1)个不同大小的特征图
(2) neck设计
neck表示对backbone的输出特征图进行各种变换,这个操作可以是特征融合、特征增强等等。最常用的neck模块是特征金字塔网络FPN
输入流: 1个或者n(n>1)个不同大小的特征图
输出流: 1个或者m(m>1)个不同大小的经过变换后的特征图
(3) head设计
这里的head设置主要指的网络设计,通常来说就是包括分类和回归分支。
输入流:1个或者m(m>1)个不同大小的经过变换后的特征图
输出流:1个或者m(m>1)个不同大小的输出特征图,通常包括两条分支:分类和回归
其中对于两阶段目标检测算法,会额外包括一个区域提取器roi extractor,用于将不同大小的roi特征图统一成相同大小
(4) enhance设计
该模块属于锦上添花,用于对backbone、neck和head部分进行特征增强。最常用的enhance模块是注意力,例如se模块
输入流:任何多个特征图
输出图:任何多个经过增强后的特征图
(5) pos neg assigner
该模块作用是进行正负样本定义或者正负样本分配,正样本就是常说的前景样本(可以是任何类别),负样本就是背景样本。因为目标检测是一个同时进行分类和回归的问题,对于分类场景必然需要确定正负样本,否则无法训练。该模块至关重要,不同的正负样本分配策略会带来显著的性能差异。
输入流:任意多个待区分正负属性的样本和gt bbox相关属性
输出流:任意多个已经确定正负属性和对应gt bbox的分配结果
待区分正负属性的样本可以是多种形式:可以是一系列anchor list,可以是一系列特征图上点,也可以是一系列roi
(6) pos neg sampler
在确定每个样本的正负属性后,可能还需要进行样本平衡操作。本模块作用是对前面定义的正负样本不平衡进行采样,克服该问题。一般在目标检测中gt bbox都是非常少的,所以正样本:负样本是远远小于1的。而基于机器学习观点:在数据极度不平衡情况下进行分类会出现预测倾向于样本多的类别,出现过拟合,为了克服该问题,适当的正负样本采样策略是非常必要的
输入流:任意多个已经确定正负属性和对应gt bbox的分配结果
输出流:重新采样后的任意多个已经确定正负属性和对应gt bbox的分配结果
(7) bbox encoder
为了更好的收敛和平衡多个Loss,一般都需要对预测输出结果进行解码,对应的就需要对正样本的gt bbox采用某种编码变换。最典型的编码就是对gt bbox除以图片wh进行归一化。
输入流:重新采样后的任意多个正样本的分配结果,包含了gt bbox信息
输出流:任意任意多个正样本的经过编码的targets
(8) loss
loss通常都分为分类和回归loss,其是对网络head输出的预测值和(7)得到的targets进行梯度下降迭代训练。
输入流:任意多个已经确定正负属性的样本targets
输出流:loss值
(9) train trick
为了更好的训练模型,到目前为止出现了大量的训练技巧,其也是模型效果的关键因素。对于相同模型采用不同的训练技巧可能会带来非常大的性能差异。训练技巧非常多,例如数据增强、分布式训练、多尺度训练等等。
测试流程
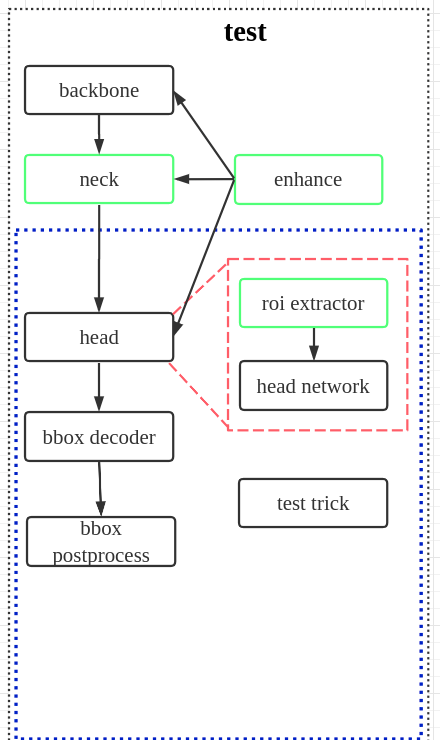
测试流程比训练流程简单很多,这里仅仅分析不同的模块
(1) bbox decoder
训练时候进行了编码,那么对应的测试环节需要进行解码。根据编码的不同,解码也是不同的。举个简单例子:假设训练时候对wh是直接除以图片wh进行归一化的,那么解码过程也仅仅需要乘以图片wh即可
输入流:回归分支输出结果
输出流:解码后回归分支输出结果
(2) bbox postprocess
在得到原图尺度bbox后,由于可能会出现重叠bbox现象,故一般都需要进行后处理。最常用的后处理就是非极大值抑制以及其变种。
输入流:解码后回归分支输出结果和对应类别
输出流:经过后处理后的检测bbox信息
(3) test trick
为了提高性能,通常也会对测试过程采用技巧,最常用的是多尺度测试技巧。
