@huanghaian
2020-10-20T00:03:49.000000Z
字数 7571
阅读 3484
mmdetection最小复刻版(五):yolov5转化内幕
mmdetection
0 摘要
在前一篇文章第四篇:mmdetection最小复刻版(四):独家yolo转化内幕中,我们已经详细分析了darknet框架训练的模型如何转化到mmdetection-mini中,这一篇文章讲解最火的yolov5如何转化到mmdetection-mini中。
这个转化就相对容易很多了,毕竟都是pytorch框架写的,但是由于他的代码比较乱,整个代码组织结构也比较乱,实在是不好用,所以我将其模型移植到mmdetection中。目前仅仅支持推理,后续会支持会模仿yolov5训练过程,支持到mmdetection-mini中。
通过本文你可以学会:
(1) yolov5整个结构的构建细节
(2) yolov5的前向推理流程
(3) 如何将yolov5模型迁移到mmdetection中
在阅读本文前,我建议你阅读我的知乎文章:进击的后浪yolov5深度可视化解析,该文对yolov5进行深入分析,包括模型设计、loss设计原则和正样本可视化等等非常详细,我相信你看完就一定能够理解yolov5了,然后在结合本文将可以了解到yolov5的每个细节。
github:https://github.com/hhaAndroid/mmdetection-mini
欢迎star和提供改进意见。
1 yolov5简要介绍
整个yolov5可以简单概况为:通过应用类似EfficientNet的channel和layer控制因子来灵活配置不同复杂度的模型,并且在正负样本定义阶段采用了跨邻域网格的匹配策略,从而得到更多的正样本anchor,加速收敛。
yolov5的结构设计是参考yolov4来的,也是包括backbone+pan+spp+yolov3 head。在知乎文章:深入浅出Yolo系列之Yolov5核心基础知识完整讲解 中有绘制的非常好看的结构图,我从里面copy出来,方便看:
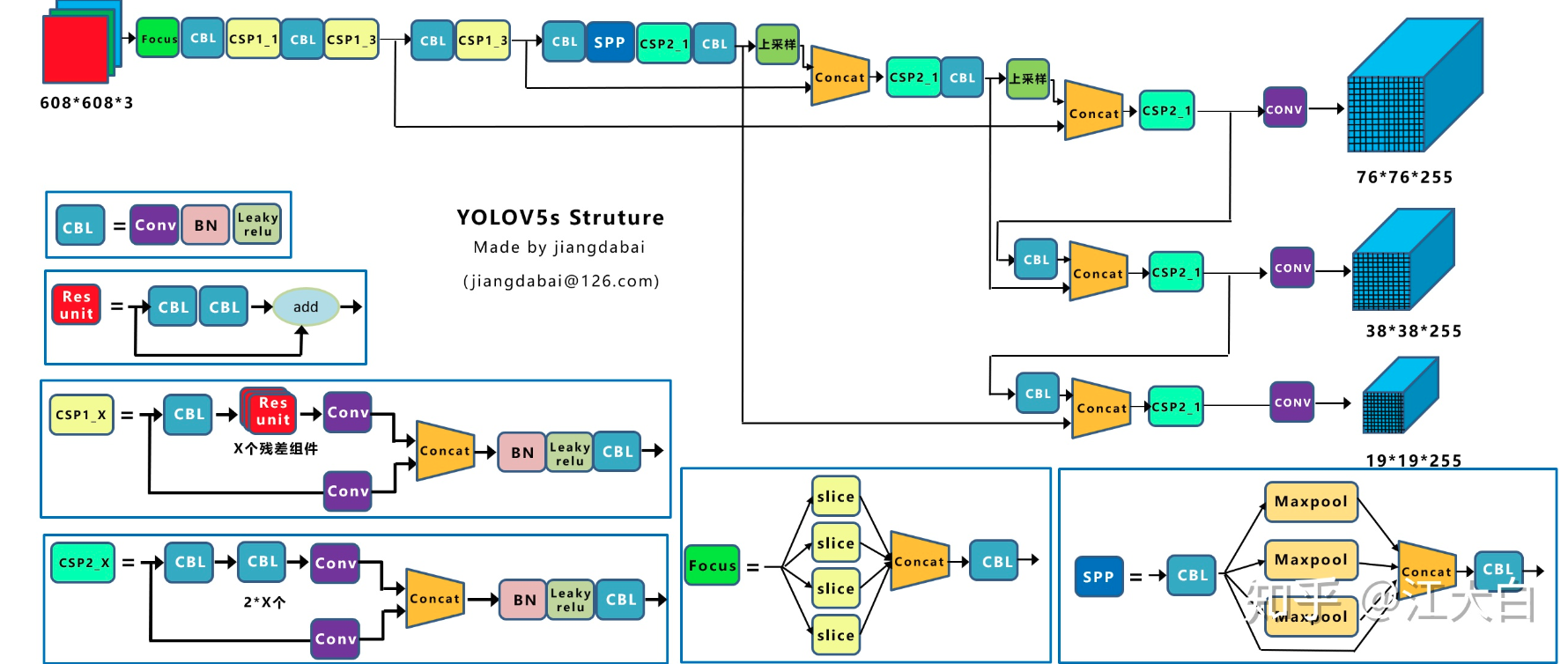
一目了然,yolov5现在已经发展到第3个版本了,其说明见链接:https://github.com/ultralytics/yolov5/releases/tag/v3.0 。相比第2版本,主要是将大部分激活函数全部换成mobilenetv3里面的nn.Hardswish(),大概在coco数据上可以提高1个点的mAP,特别是yolov5s小模型,提升很大。其余没有啥改变。不同大小模型通过depth_multiple和width_multiple两个参数控制,width_multiple是用来控制全局的通道数的,depth_multiple是用来控制BottleneckCSP模块的个数。
yolov5的模型构建仿照了darknet中采用的cfg模式,即通过配置文件来构建网络,但是考虑到darknet中的cfg文件细粒度过高,对于重新构建网络来说是很累人的,可读性比较差,本文作者借鉴了cfg思想,但是进行了适当改进即不再细分到conv+bn+act层,而最细粒度是模块,为后续模型构建、结构理解有很大好处,但是这种写法缺点是不再能直接采用第三方工具例如netron进行网络模型可视化了。
如果你看了前一篇文章,熟悉了darknet里面的cfg组织格式,那么yolov5网络构建模式应该很容易就理解了,这里就不说了。
2 yolov5转化为mmdetection
2.1 mmdetection中构建模型
首先yolov5中涉及到的几个模块都比较简单,基本上就是BottleneckCSP、Focus、SPP和卷积模块,而且本身就是pytorch写的,故我直接copy过来了。
在构建具体模型时候,为了后面简单(待会会说为啥),我也是按照配置文件格式来构建模型,例如yolov5骨架构建如下:
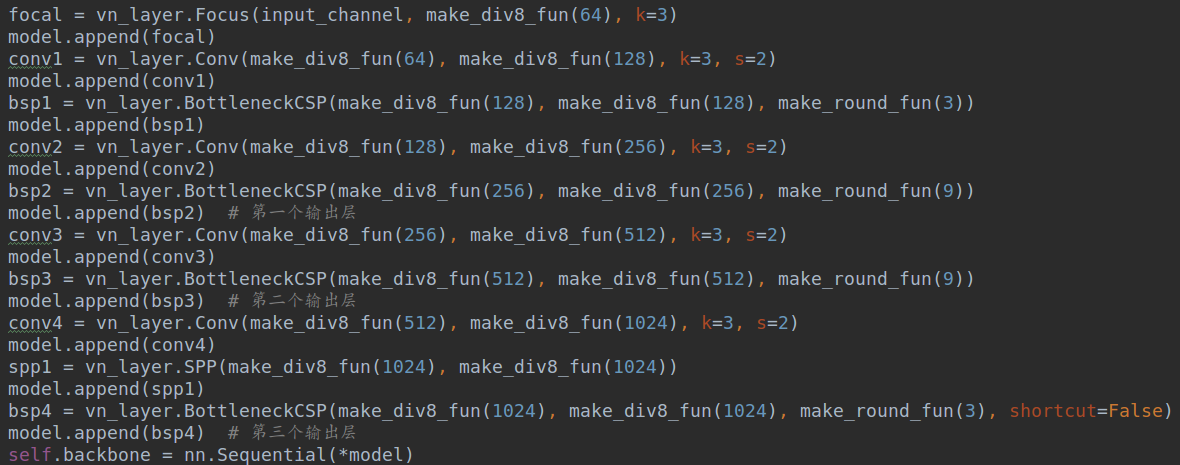
通过append方式构建,然后全部转化为Sequential对象。
按照规范的结构拆分原则,此处应该有neck模块,用于存放pan+spp模块,但是作者直接放置在head部分了,所以我也暂时按照他的写法构建,后面可能会更改。
head部分的代码构建也是类似,如下所示:
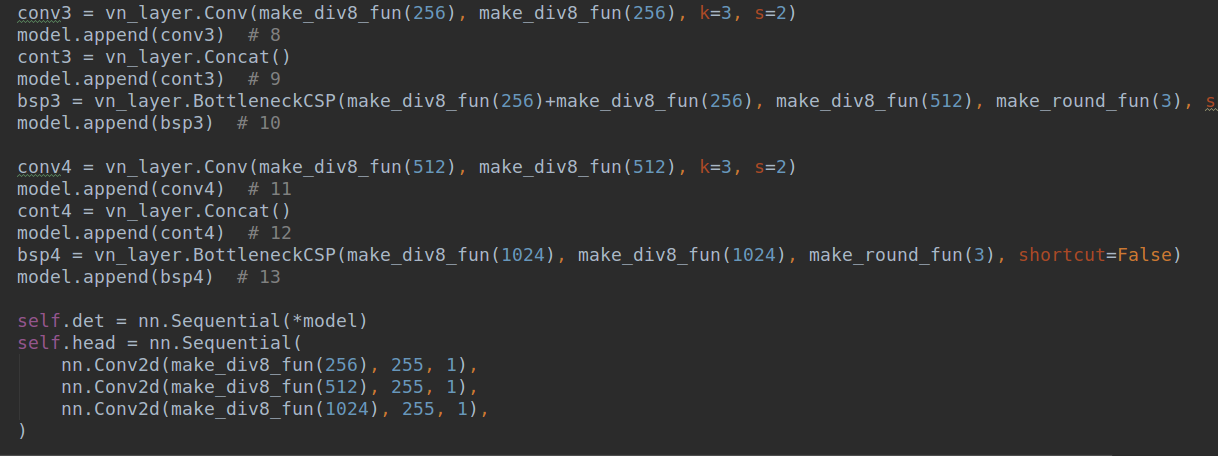
就是这么简单就把模型构造好了。
还有一个细节:pytorch1.6内部自带了nn.Hardswish()和nn.Identity()算子,而pytorch1.3是没有的,所以为了兼容,我重写了这两个类,效果是一样的,但是可能效率不如原生的。
2.2 yolov5模型转化
(1) 自动下载权重
要转化的前提应该是下载权重,你可以自己去官方地址下载,当然也可以去浏览器上下载,作者写的attempt_download函数可以自动下载权重。
下载后你可以发现权重长这样:

(2) 模型转换为pytorch1.3可读权重
作为对比,yolov3的后缀是pth,但是yolov5s是pt,这是因为yolov5采用的pytorch版本是1.6,其采用全新的存储方式,你如果采用pytorch1.3读取是会报错的,必须也是pytorch1.6及其以上才行。
还有一个比较坑的,作者存储的模型里面包括了模型对象,而不仅仅是状态字典,即使你采用pytorch1.6读取权重,但是一旦你读取的代码不是放在yolov5对应的工程路径下也是会报错的,内部会报pickle对象无法Load的错误。
所以你只能把我写的tools/darknet/convert_yolov5_weights_step1.py代码放在yolov5路径下运行,为了后面mmdetection能采用pytorch1.3进行读取,需要采用:
torch.save(data, save_name, _use_new_zipfile_serialization=False)
方式保存,这样就可以向前兼容了。
注意:yolov5训练好的pt文件里面存储了大量有用信息,而不仅仅是权重,包括anchor等等信息。为啥要保存呢?因为yolov5代码中有自动计算anchor和参数搜索的操作,如果他不保存起来,那么程序停止后就没有了,只保存状态字典无法在前向时候使用。这是一个不错的方式,即使代码修改了,参数也不会丢。
(3) 转化权重
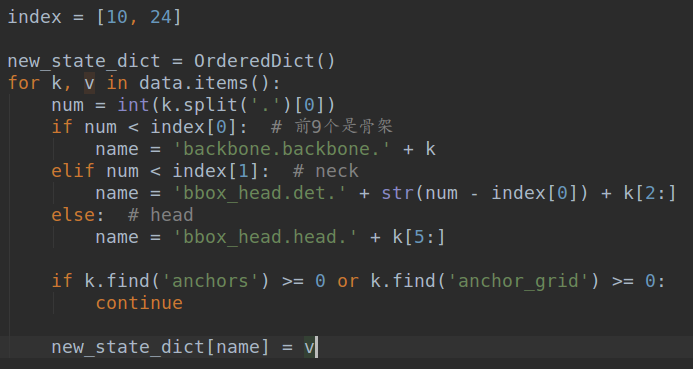
前面说了模型为啥要采用append的模式构建,是为了这一个步骤方便。因为yolov5里面是按照顺序解析配置,然后转化为Sequential的,其状态字典中各层参数名称是按照0,1,2...这种方式存储的。如果我不也这样写,那么我的权重转化过程会比较累,这样做可以节省一些工作量。如果他后续模型改了,我这边改动也不大。
转换脚本在tools/darknet/convert_yolov5_weights_step2.py中,其需要输入前面转换得到的pytorch1.3模型。并且需要注意key和anchor这些字段,我们是不要的,如下所示:
到这里为止就完成了所有模型方面的转化,m/l/x模型也是一样的流程。
2.3 mmdetection新增bbox解码函数
看过yolov5解析的朋友,应该知道yolov5的编解码方式和其余yolo系列不一样,因为其跨网格预测了,故新增了mmdet/det_core/bbox/coder/yolov5_bbox_coder.py编解码类,其解码过程为:

注意中心点预测范围变了,不是0-1,而是-0.5到1.5,wh预测也改变了,没有exp操作,而仅仅是尺度缩放了而已。作为对比,yolov3是如下:

到这里就全部完成了。下面就是测试下代码对不对了。
2.4 模型验证
第一次运行就能成功也是奇怪了,也蛮心酸的,一个人慢慢检查喽。
(1) 中心点还原代码没写对
在第一次写中心点解码时候写法是:
x_center_pred = (pred_bboxes[..., 0]*2 - 0.5) * stride + x_center
y_center_pred = (pred_bboxes[..., 1]*2 - 0.5) * stride + y_center
预测现象就是中心点预测完全不对劲,总感觉偏掉了。后面仔细思考,发现2不能乘到里面,而是外面。因为mmdetection中yolo生成的anchor其实是有0.5的偏移的,而不是0的,此时预测的中心点是正确的,但是还是有错误。
(2) 有一个anchor写错了参数
这个低级错误花费我一个下午才发现。前面说明yolov5权重里面会保存anchor的,我把anchor打印了然后复制过来,我靠,居然没有发现正好中间的一个anchor的w写错了,我检查了几遍都没有发现,尴尬啊!
我来说下如何找出的吧!当其中一个anchor写错的时候,现象是有些bbox预测是正确的,而有些是错误的。我当时首先就怀疑是不是我的bbox解码过程写错了,思考了很久都感觉没有错误。又看了一遍模型代码也没有问题,为了确定bbox解码过程是否正确,我彻底抛弃了mmdetection里面的anchor,而是采用yolo系列中常规的解码方式,类似v5中如下所示:
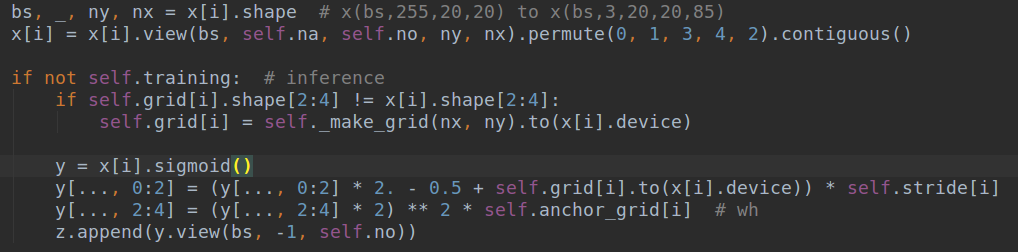
所以我重写了一个yolov5_bbox_coder.py,仿照上述写法来进行解码,结果发现改完了测试效果一模一样,我真实疯了,说明问题根本就不在解码这部分。
既然找不出问题,那就只能采用终结大招了。我把mmdetection-mini中的yolov5模型不包括解码部分移植到yolov5工程中,然后把他的模型代码替换为我自己的,类似于如下所示:

这样就可以保存输入、解码过程完全一致。接下来我要做的就是选中一张图片,分别运行yolov5模型和我的模型,保存各层输出tensor,然后比对数值是否完全相同,如果有哪一层不一样,那就说明这一层代码写错了。
结果发现居然所有层tensor完全相同,除了最后的bbox预测不一样外,此时我就知道模型肯定没有错误,问题在最后的解码层。然后仔细检查发现不一样的解码输出就是在某一层而已,其余层相同,那么所有问题肯定就是anchor了,然后我再看一眼才发现把:
(116, 90), (156, 198), (373, 326)
写成了:
(116, 90), (90, 198), (373, 326)
使出了我的终结大招才解决问题,心累啊,如果当时有个人帮我检查下anchor,就没有这个问题了。说句题外话:通过这些模型转换过程,我总结学到的最多就是如何找出Bug,如何解决一个看起来很难解决的Bug,不管你是啥bug,我总有办法解决你,虽然有些办法有点笨。有好几次我都快放弃了,然后突然又想到一种调试方法,然后接着干,最终就解决了。
(3) 其余细节
BN的两个参数不是默认值,而是
self.bn = nn.BatchNorm2d(2 * c_, eps=0.001, momentum=0.01)
虽然对推理没有啥影响,但是还是需要知道。
(4) 图片处理逻辑不一样
到这里就可以测试了。以yolov5为例,下载608x608训练的权重,采用yolov5s测试val2017,配置参数如下:
yolov5参数: conf_thres=0.001 iou_thres=0.65mmdetection:test_cfg = dict(nms_pre=1000,min_bbox_size=0,score_thr=0.05,conf_thr=0.001,nms=dict(type='nms', iou_thr=0.65),max_per_img=100)
结果如下:
orig yolov5s: 37.0@mAP0.5...0.9 56.2@mAP0.
mmdetection: 36.0@mAP0.5...0.9 56.3@mAP0.5
发现居然少了一个点,这你可以忍?
我首先猜测原因可能有:
1. 我实现的nn.Hardswish()效果不一样
2. 图片处理逻辑不一样
首先我在yolov5中把官方的写的hardswish替换,发现mAP一样,说明不是这个问题。那可能就是第2个问题了,然后我去研究了下yolov5的前向处理逻辑。
我选择bus.jpg这张图片进行单张图片测试来验证的。也就是利用这张图片分别在mmdetection(image_demo.py)和yolov5(detect.py)中运行一遍,保存预测结果,看下是否相同。由于前处理逻辑不一样,所以虽然预测的框差不多,但是其实score值不一样,这说明前处理逻辑确实不一样。
在yolov5的detect.py中采用的是letterbox方式对图片进行处理,其逻辑为:
- 计算缩放比例,假设input_shape = (181, 110, 3),输出shape=201,先计算缩放比例1.11和1.9,选择小比例。这个是常规操作,保证缩放后最长边不超过设定值
- 计算pad像素,前面resize后会变成(201,122,3),理论上应该pad=(0,79),但是内部采用最小pad原则,设置最多不能pad超过64像素故对79采用取模操作,变成79%64=15,然后对15进行/2,然后左右pad即可
和常说的letterbox操作稍微有点区别,一般的letterbox操作输出都是通过pad操作变成正方形的。早期yolov5也是变成正方形进行推理,后来在xxx中提出了矩形推理方式也就是上面的做法,输出是矩形,而不是正方形,在推理阶段可以加快速度。最小pad原则的目的是加快推理时间,细节可以参考https://github.com/ultralytics/yolov3/issues/232
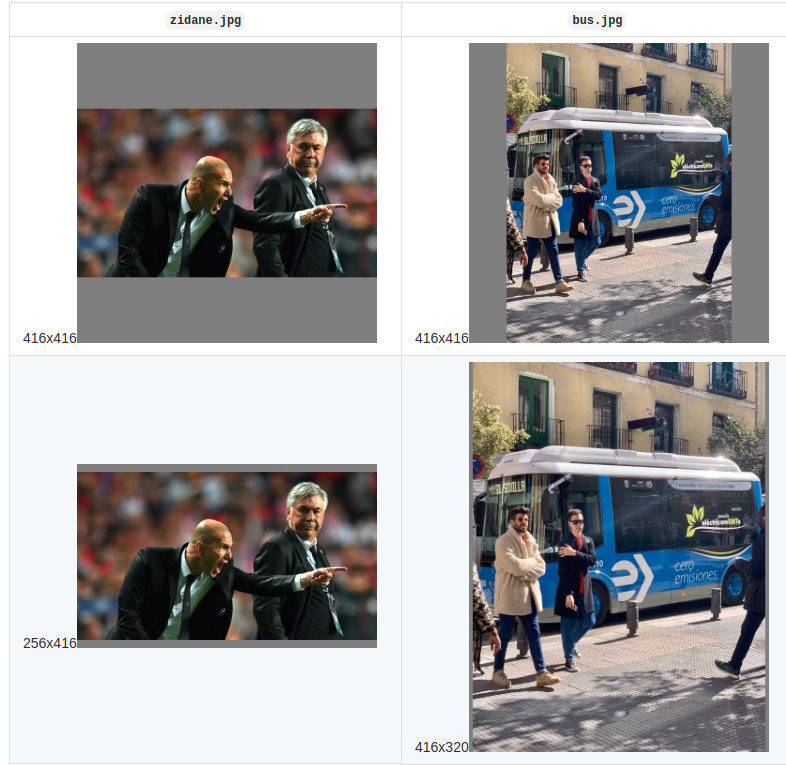
第一行是常规的正方形padding,第二行是上面介绍的最小pad原则得到的矩形图片。
然而在mmdetection中采用的是Resize函数,其是直接保持长宽比进行resize,没有pad操作,效果应该说类似吧。注意letterbox和mmdetection中的Resize函数输出都不一定是指定size,也就是说即使你指定608x608,计算完成后也不一样的是608x608输出。目前mmdetection中也集成了letterbox操作。
基于这个设定,我也对mmdetection的推理流程进行修改,采用了letterbox模式,配置如下:
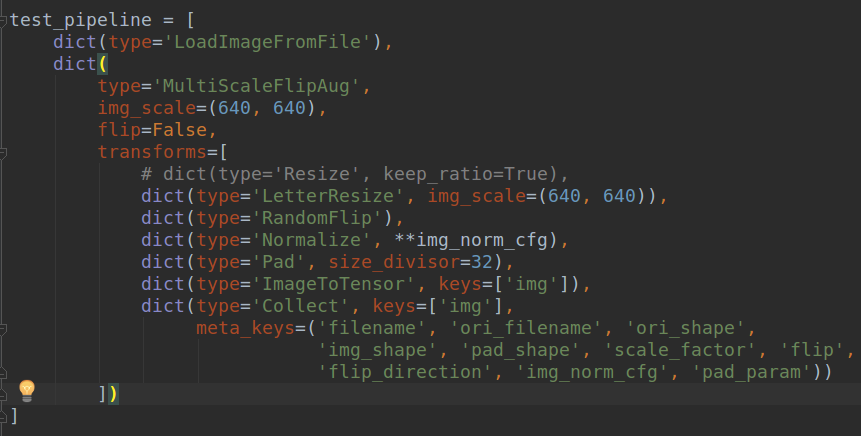
在采用demo/image_demo.py脚本进行运行,同样的bus.jpg图片,运行结果可视化,可以发现和yolov5完全一样了。说明推理时候确实如此,如下所示(左边是yolov5结果,右边是转化后mmdetection-mini结果):

当我满怀欢喜,将这个改动应用于test(对应mmdetecion中的test.py和yolov5中的test.py),重新测试mAP时候,发现居然没有啥变化,说明其实LetterResize和Resize应用于val2017没啥区别。
然后我再次审视了配置文件,发现yolov5里面没有score_thr这个参数,在mmdetection中这个参数的作用是应用conf_thr,然后应用score_thr参数删除预测对应类别的score小于预测的bbox,最后才是nms操作。但是yolov5中没有score_thr这个步骤,这会导致yolov5预测的框超级多,但是对mAP计算有利
我于是把这个参数值设置的超级小,相当于没有再次测试,如下所示:
test_cfg = dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.0000001,
conf_thr=0.001,
nms=dict(type='nms', iou_thr=0.6),
max_per_img=300)
这个配置就是和yolov5里面完全相同了。mAP再次测试结果如下:
orig yolov5s: 37.0@mAP0.5...0.9 56.2@mAP0.
mmdetection: 36.6@mAP0.5...0.9 56.6@mAP0.5
此时可以发现mAP就没有差那么多了,但是还差了0.4个点。现在的差距就又要说到letterresize函数了,因为我在单张图片测试时候明显预测值完全相同,理论上mAP肯定是完全相同,现在居然不一样,说明哪里还是有不同?我检查了下yolov3的测试逻辑和单张图推理逻辑的区别,发现差别在于dataset。
后来检查发现:yolov5中letterresize虽然是用了,但是其输入shape是自适应的,其保证了训练和测试的数据处理逻辑一样(除了mosaic逻辑外),也就是说yolov5测试模式下,每个batch内部shape是一样的,但是不同batch之间的shape是不一样的,这会造成最终结果有差异。虽然他是指定的608x608进行推理,但是其内部还是相当于有个基于当前数据集进行自适应操作。而在detertor代码里面,是直接调用letterresize,而输入shape是指定的,所以才会出现在对某一张图进行demo测试时候,结果完全相同但是test代码时候mAP不一致。
总结来说,yolov5采用dataloader进行测试时候,实际上是有自适应的,虽然你设置的是608x608的输入,其流程是:
- 遍历所有验证集图片的shape,保存起来
- 开启Rectangular模式,对所有shape按照h/w比例从小到大排序
- 计算所有验证集,一共可以构成多少个batch,然后对前面排序后的shape进行连续截取操作,并且考虑h/w大于1和小于1的场景,因为h/w不同,pad的方向也不同,保存每个batch内部的shape比例都差不多
- 将每个batch内部的shape值转化为指定的图片大小比例,例如打算网络预测最大不超过608,那么所有shape都要不大于608
- 对batch内部图片进行letterbox操作,测试或者训练时候,不开启minimum rectangle操作,也就是输出shape一定等于指定的shape。这样可以保证每个batch内部输出的图片shape完全相同
而mmdetection中test时候实现的逻辑是:
- 将每张图片LetterResize到640x640(输出不一定是640x640)
- 将图片shape pad到32的整数倍,右下pad
- 在collate函数中将一个batch内部的图片全部右下pad到当前batch最大的w和h,变成相同shape
可以看出yolov5这种设置会更好一点,应该就是这个差异导致的mAP不一样,后面我把这个策略应用到mmdetection中。
3 总结
本文一步一步,从0开始讲解如何将yolov5模型转化到mmdetection中,其中对于我踩得每一个坑,我都详细说明了,希望下次其他朋友碰到同样问题可以快速跳过。
github:https://github.com/hhaAndroid/mmdetection-mini
欢迎star和提供改进意见。
