@huanghaian
2020-11-01T02:30:51.000000Z
字数 5710
阅读 3637
mmdetection最小复刻版(十九):yolov3算法详解
mmdetection
0 摘要
yolov3总体思想和yolov2没有任何区别,只不过引入了最新提升性能的组件,从而将yolov2提升到一个非常强的高度,属于yolov2的改进版本,只有在彻底理解了yolov2后才好理解yolov3。其相比v2主要改进可以简单归纳为:
(1) 基于retinanet算法引入了FPN和多尺度预测
(2) 基于主流resnet残差设计思想提出了新的骨架网络darknet53
(3) 不再将所有loss都认为是回归问题,而是分为分类和回归loss,更加符合主流设计思想
虽然yolov3是前yolo系列的改进,但是由于其以下突出特性,使其实际应用程度远远大于前yolo系列。可以说目前提到yolo,基本都是指的yolov3了。
- 提供高速高精度的yolov3模型和极速版本的tiny-yolov3模型,可以适用于复杂和简单场景
- 全部代码采用darknet所写,纯c构建,容易训练和部署
- 更加符合现代目标检测算法思想,大家接受程度比较高
由于其突出的重要性,故本文会结合mmdet中yolov3代码进行讲解,力图在熟悉算法原理的同时能够深入理解代码。而且mmdet目前还在快速发展,故解读的mmdet版本是2.5.0,截止时间是2020.10.31。
1 算法分析
1.1 网络设计
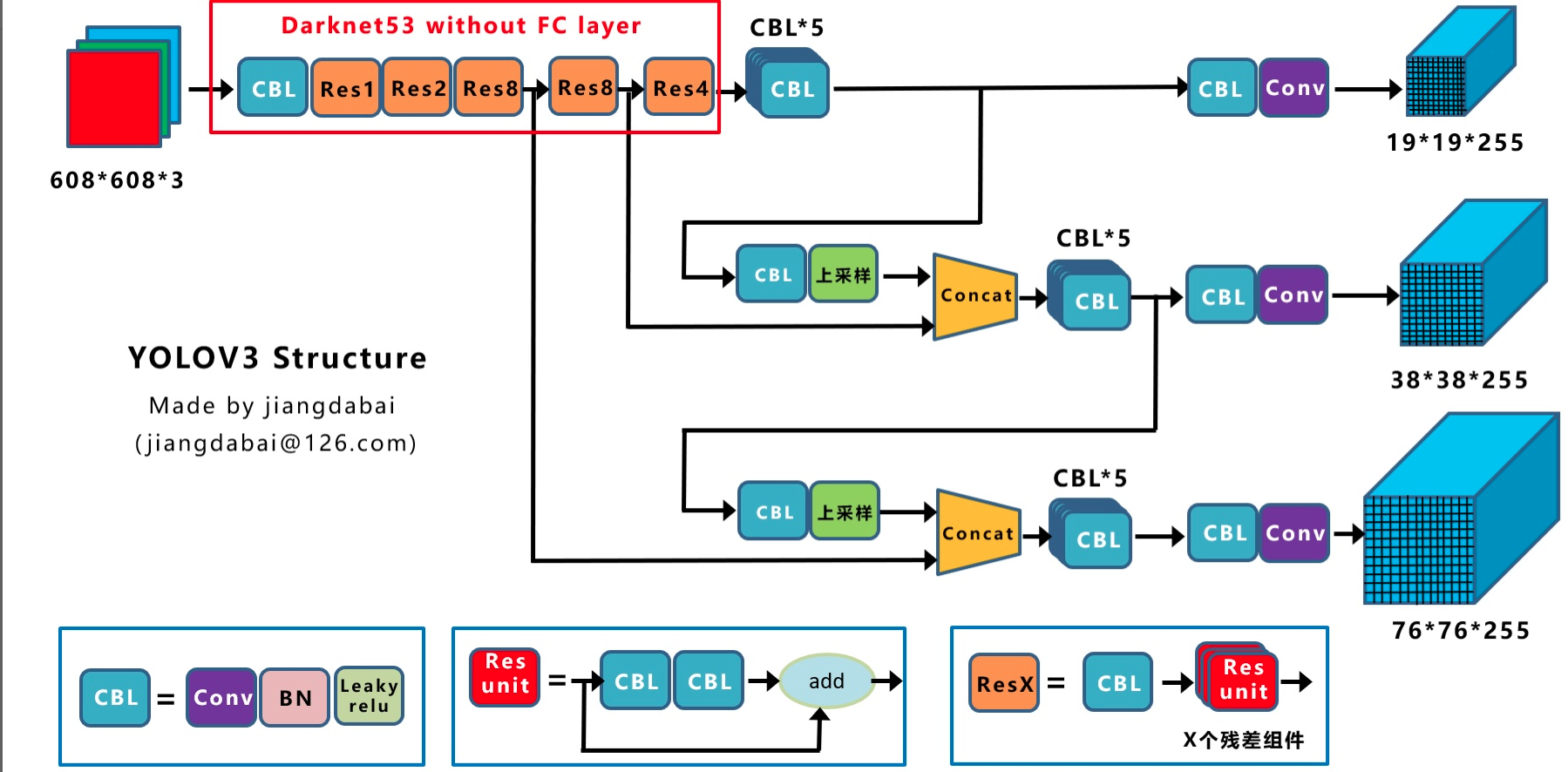
(上图可能要重画)
整个yolov3网络包括标准的backbone、neck和head三个部分。
CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu三者组成
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深
ResX:由一个CBL和X个Res unit构成,是Yolov3中的大组件。每个Res unit前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小
(1) backbone
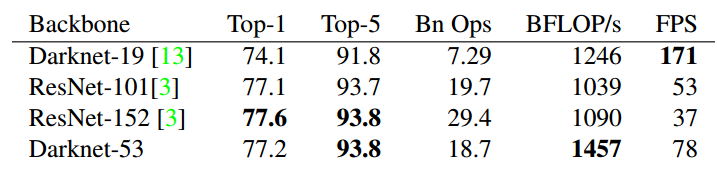
每个ResX中包含1+2*X个卷积层,因此整个主干网络Backbone中一共包含,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。将avgpool+fc部分去掉就是常说的darknet53骨架网络。
相比其余主流网络,性能如下:
代码层面darknet53配置为:
arch_settings = {
53: ((1, 2, 8, 8, 4), ((32, 64), (64, 128), (128, 256), (256, 512),
(512, 1024)))
}
darknet53和标准的resnet一样,也是分为stem+stage+head三个部分
- stem就是一层CBL模块
- 然后经过5个stage,每个stage都包括1+2*X个卷积层,X的配置是(1, 2, 8, 8, 4),而(32, 64), (64, 128)表示每个stage的输入和输出通道,其stride为2、4、8、16和32
- head部分就是常说的avg pool+fc分类模块。
yolov3只需要最后三个stage的输出,故backbone输出是三个不同大小的特征图,其stride=8,16,32。整个darknet53配置如下:
backbone=dict(type='Darknet', depth=53, out_indices=(3, 4, 5))
out_indices表示最后三个stage的特征图输出索引。
(2) neck
这里的neck模块是指FPN层,其输入是backbone的三个尺度输出特征图,输出也是和输入wh一样的三个尺度,只不过内部进行了从高层特征和相邻低层特征进行上采样后concat进行融合操作,从而对输入特征图进行增强。其配置为:
neck=dict(
type='YOLOV3Neck',
num_scales=3,
in_channels=[1024, 512, 256],
out_channels=[512, 256, 128]),
其结构简图如下:
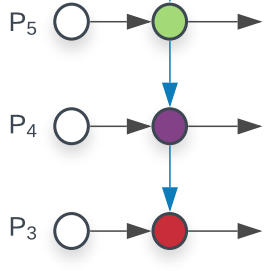
假设输入的三个特征图命名为P3~P5,stride分别是8/16/32。
(1) 对P5直接采用5个CBL模块得到O5输出,输出通道是通过out_channels指定的
(2) 对O5先进行1x1卷积将通道变换成和P4一样,然后进行2倍最近邻上采样,然后和P4特征进行concat融合,最后也是经过5个CBL模块得到O4输出
(3) 对O4先进行1x1卷积将通道变换成和P3一样,然后进行2倍最近邻上采样,然后和P3特征进行concat融合,最后也是经过5个CBL模块得到O3输出
此时就得到三个不同尺度的经过融合后的特征图O3~O5,stride分别是8/16/32。
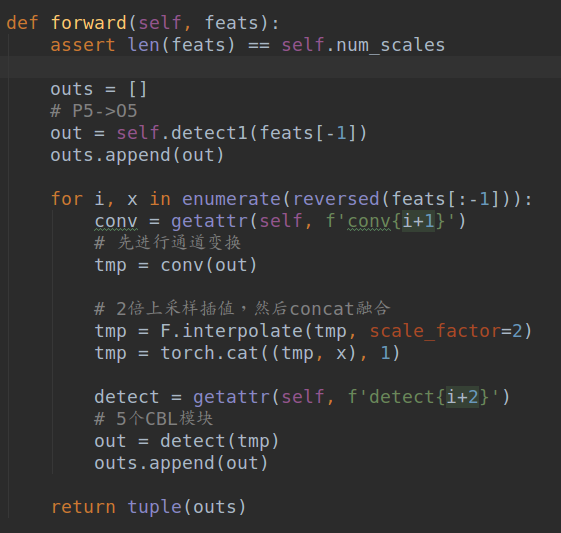
(3) head
对neck模块输出的O3~O5都采用3x3的CBL模块+1x1的卷积进行通道变换即可,此时就可以得到三个尺度预测层了。每一层输出特征图shape为(b,num_anchor*(xywh+conf+cls_num))。yolov3每个预测层都是3个anchor,是通过kmean聚类算出来的,按照从大到小anchor尺度排列,分别检测大物体和小物体。
可以发现相比yolov2,其将单尺度预测修改为了多尺度输出,并且额外引入了FPN进行特征融合增强。
1.2 正负样本定义
其规则和yolov2完全相同,只不过任何一个gt bbox和anchor计算iou的时候是会考虑三个预测层的anchor,而不是将gt bbox和每个预测层单独匹配。假设某个gt bbox和第二个输出层的某个anchor是最大iou,那么就仅仅该anchor负责对应gt bbox,其余所有anchor都是负样本。同样的yolov3也需要基于预测值计算忽略样本。
在coco数据集上通过kmean算法聚类得到的9个anchor如下所示:
base_sizes=[[(116, 90), (156, 198), (373, 326)],
[(30, 61), (62, 45), (59, 119)],
[(10, 13), (16, 30), (33, 23)]]
可以看出其是原图尺度,每个输出层的每个特征图位置都包括三个anchor,并且按照预测从大到小物体的输出层顺序排列,对应特征图stride是从大到小即O5~O3。假设输入图片大小是608x608,那么一共包括19x19x3+38x38x3+76x76x3=22743个anchor。
为了详细说明yolov3的正负样本定义规则,需要先回顾下yolov2的规则,其可以简要归纳为:
- 遍历每个gt bbox,首先判断其中心点落在哪个网格,然后和那个网格内的所有anchor计算iou,iou最大的anchor就负责匹配即正样本
- 考虑额外规则:当每个gt bbox和最大iou的anchor匹配完成后,对剩下的anchor再次和对应网格内的gt bbox进行匹配(必须限制在对应网格内,否则xy预测范围变了),当该anchor和gt bbox的iou大于一定阈值例如0.7后,也算作正样本,即该anchor也负责预测gt bbox
- 遍历每个负anchor的预测值,如果anchor预测值和其余所有gt bbox的所有iou值中(不需要网格限制),只要有一个iou值大于阈值,则该anchor预测值忽略,不计算loss
这样就得到了每个anchor的正负和忽略样本属性,其中正样本用于训练分类和回归分支,正负样本用于训练置信度分支,忽略样本忽略。
现在从yolov2的单尺度预测变成了yolov3多尺度预测,其匹配规则为:
- 遍历每个gt bbox,首先判断其中心点落在哪3个网格(三个输出层上都存在),然后和那3个网格内的所有anchor(一共9个anchor)计算iou,iou最大的anchor就负责匹配即正样本,其余8个anchor都暂时是负样本。可以看出其不允许gt bbox在多个输出层上都预测
- 考虑额外规则:当每个gt bbox和最大iou的anchor匹配完成后,对剩下的anchor再次和对应网格内的gt bbox进行匹配(必须限制在对应网格内,否则xy预测范围变了),当该anchor和gt bbox的iou大于一定阈值例如0.7后,也算作正样本,即该anchor也负责预测gt bbox
- 遍历每个负anchor的预测值,如果anchor预测值和其余所有gt bbox的所有iou值中(不需要网格限制),只要有一个iou值大于阈值,则该anchor预测值忽略,不计算loss
可以发现相比yolov2,仅仅是第一步有一点点区别。但是需要特别注意的是mmdet中的yolov3的正负样本分配策略和原始论文不太一样,具体是:
assigner=dict(
type='GridAssigner', pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0)
- 初始化所有anchor的标志都是-1,表示全部是忽略样本
- 遍历每个anchor,计算每个anchor和所有gt的iou,如果其中最大iou小于neg_iou_thr则表示是该anchor是负样本(背景样本),因为他和任何gt bbox的重合率都比较低
- 遍历每个anchor和其对应的网格索引,首先判断是否有gt bbox落在该网格内部,如果没有直接跳过,如果有gt bbox,则计算该anchor和所有落在对应网格的gt bbox的iou,找出最大iou值,如果其最大iou大于等于pos_iou_thr,则设置该anchor标记为正样本,且该anchor负责预测对应gt bbox
- 遍历每个gt bbox,首先计算其落在哪3个网格上(3个输出层),然后和那3个网格内的所有anchor(一共9个anchor)计算iou,iou最大的anchor就负责匹配即正样本
看起来比较复杂,我们可以仔细分析下
- 假设设置pos_iou_thr>1,neg_iou_thr>1,那么第三步其实就失效了,且第二步中所有anchor都是负样本,此时的分配策略就是yolov3规则中的第1个步骤了
- 假设设置pos_iou_thr=0.5,neg_iou_thr>1,那么此时分配规则就是yolov3中的第1和2步骤了
- 如果按照原始配置pos_iou_thr=0.5, neg_iou_thr=0.5,则不存在忽略样本,并且分配规则也是yolov3中的第1和2步骤
通过上面的分析,我们可以知道mmdet中的实现始终缺少了第3步:忽略样本定义。我猜测原因是为了复用mmdet的max iou assigner策略。
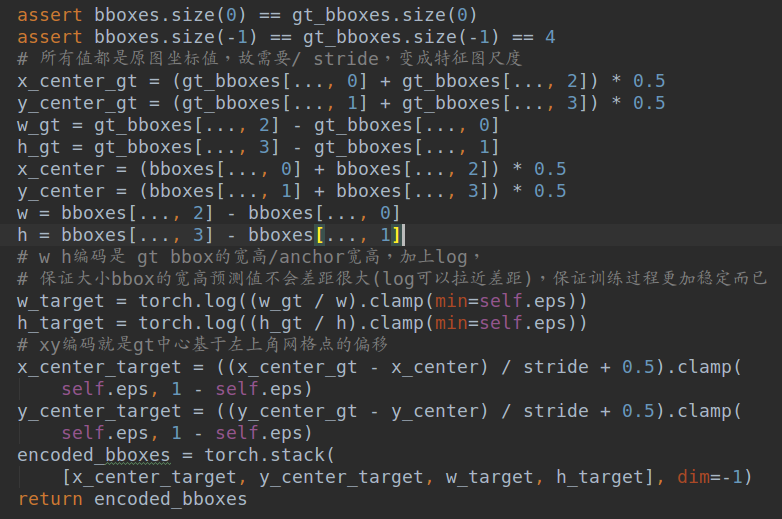
1.3 bbox编解码
这个规则和yolov2完全相同。正样本的xy预测值是相对当前网格左上角的偏移,而wh预测值是gt bbox的wh除以anchor的wh(注意wh是在特征图尺度算还是原图尺度算是一样的,解码还原时候注意下就行),然后取log得到。
1.4 loss设计

和yolov2不同的是,对于分类和置信度预测值,其采用的不是l2 loss,而是bce loss,而回归分支依然是l2 loss。
疑问:为啥要将分类和置信度预测值的loss将l2 loss换成bce loss?
解答:首先这是主流做法,分类问题一般都是用ce或者bce loss,而在retinanet里面提到采用bce loss进行多分类可以避免类间竞争,对于coco这种数据集是很有好处的;其次在机器学习中知道对于逻辑回归问题采用bce loss是一个凸优化问题,理论上优化速度比l2 loss快;而且分类输出就是一个概率分布,采用分类常用loss是最常规做法,没必要统一成回归问题
和yolov2一样,置信度分支的label可以设置为1或者iou值。但是在标准yolov3配置中,默认是1。通过第三方用户对比实验发现原因可能是:在训练时,有些预测框与真实框的iou极限值很难达到1,假设置信度以0.7作为标签,最后学到的数值是0.5,0.6,那么假设推理时的分值阈值就不能设置的比较高,否则对于coco这类存在大量小物体的数据很容易出现漏检。而如果设置label设置为1可以提高召回率,此时置信度就不具有反映预测的准确率的作用了,有利有弊吧!在mmdet的yolov3代码中,置信度分支的label为1。
到目前为止,我们可以发现相比原始yolov3,mmdet中的复现少了以下操作:
- 置信度分支的所有负样本全部算是背景,不存在忽略样本
- 对于正样本anchor,其回归loss没有大小物体自适应wh加权
按我个人理解,这两个策略还是有用的,特别是第二个对于小物体的mAP应该有很大提升。
2 训练流程
yolov3的训练过程和v2完全相同。
3 推理流程
推理流程为:
- 遍历每个输出层,对xy预测值采用sigmoid变成0~1,然后进行解码,具体是对遍历每个网格,xy预测值加上当前网格坐标,然后乘上stride即可得到预测bbox中心坐标,对于wh预测值先进行指数计算,然后直接乘上anchor的wh即可,此时就可以还原得到最终的bbox
- 对置信度分支采用sigmoid变成0~1,分类分支由于是bce loss故也需要采用sigmoid操作
- 利用置信度预测将置信度值低于预测的预测值过滤掉
- 如果剩下的预测bbox数目多于设置的nms前阈值个数1000,则直接对置信度值进行从大到小topk排序,提取前1000个,三个输出层最多构成3000个预测bbox
- 对所有预测框进行nms即可
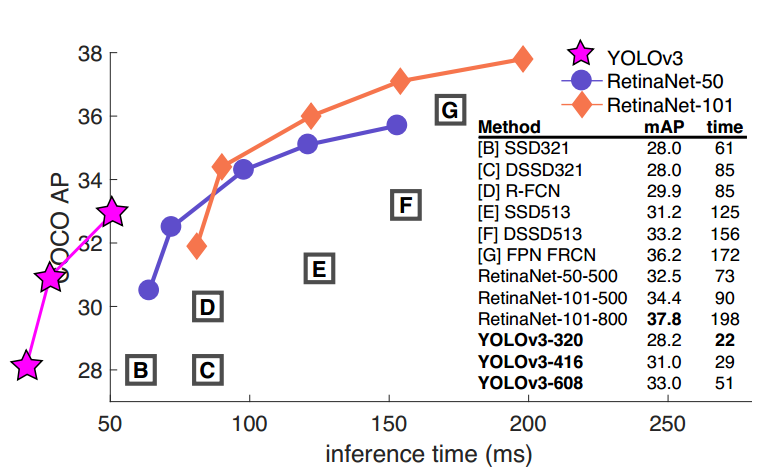
4 实验结果
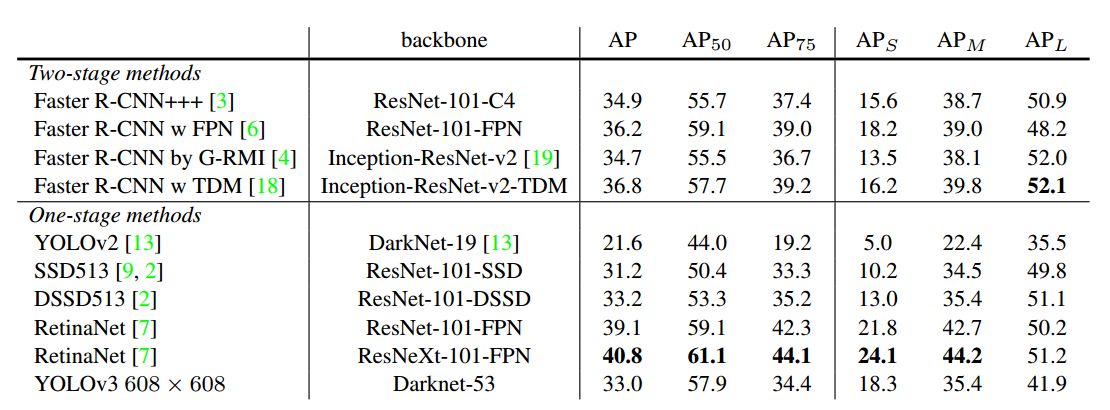
可以看出,yolov3性能强于ssd系列,但是比faster rcnn差,这是正常的,yolo系列算法的主打是高速,在如此快的检测速度下依然有不错的mAP。
5 总结
yolov3可以认为是当前目标检测算法思想的集大成者,其通过引入主流的残差设计、FPN和多尺度预测,将one-stage目标检测算法推到了一个速度和精度平衡的新高度。由于其高速高精度的特性,在实际应用中通常都是首选算法。
参考
- YOLOv3: An Incremental Improvement
- https://zhuanlan.zhihu.com/p/143747206
