@huanghaian
2020-11-18T05:39:22.000000Z
字数 9395
阅读 2487
mmdetection:RPN分析
mmdetection
0 摘要
RPN全称是Region Proposal Network区域提取网络,是Ren等人在2015年提出的一个模型,用以替代Fast RCNN 等两阶段方法中的外部region proposal算法,提高整个检测pipeline的速度。RPN和FasterRCNN是在同一篇 论文中提出的,且RPN是Faster RCNN的一个模块。 但RPN也可以单独使用,在图像上产生物体的 proposal,或者直接用于特定物体的检测。 RPN算法对于理解SSD、YOLO和RetinaNet等单阶段检测方法也有所帮助。通过对比分析可以发现RPN和SSD、RetinaNet非常类似。为了方便理解,本教程也将单独对RPN讲解。
1 算法分析
在faster rcnn算法中RPN的主要作用是提取Region Proposal,也就是图像领域中常说的roi。其主要要求是不要漏掉前景物体,且尽可能多的提取前景区域,然后输入给rcnn模块进行refine操作。RPN也可以认为是一个one-stage目标检测算法,故其也包括backbone,neck和head模块,只不过这里的neck可有可无(FPN算法的引入才有了neck)。下面先介绍anchor的基本概念和作用,然后对RPN网络进行深入分析。
1.1 Anchor
Anchor概念是在faster rcnn中第一次提到,是目前anchor-base算法中非常重要的一个超参,其参数设置对最终结果有巨大影响,理解Anchor的核心思想才能完整把握整个算法流程。
Anchor字面意思是锚,是用于固定船的部件,锚点放置在哪个位置,那么船就只能在其约束的范围内飘动。在计算机视觉中也是同一个意思,假设在图片的某个位置设置了一个锚点,该锚点不仅有位置信息还有宽高属性,那么相应的物体bbox预测就受到该锚点的约束(即正负样本属性定义),相当于提供了先验。
目标检测需要解决两个问题:物体在图片的哪个位置,以及该物体是何类别。只有先确定了物体在哪个位置才能进一步确定其属于何种类别,故物体的位置预测属性非常关键。在传统目标检测算法中,为了能够在一张图片中同时检测多个物体,会采用滑动窗口做法进行遍历,具体是:设定一个具有宽高属性的框,然后将框按照从左到右,有上到下的顺序移动,对每个窗口内的图片判断是否有物体即可。滑动窗口做法思想是不错的,但是其存在一些问题:窗口宽高设置多少?滑动密度是多少?对于存在大小和密疏不同的场景,这个设置比较难进行,为此后人提出多窗口多步长密集滑动做法,即可以设置n个不同大小、宽高比例的窗口,然后采用不同的步幅依次进行滑动检测,最终结果可以全部经过nms后得到。
以上简单思想,在现代目标检测算法中就演变为了Anchor,其做法是在原图或者特征图上铺设指定大小、宽高比的K个窗口,如果有物体落在窗口所负责范围内,则该窗口负责预测该物体。只要anchor铺设的够多,够密,能够覆盖几乎所有gt bbox分布,那么由于提供了anchor先验,从而将滑动窗口分类问题变成了基于anchor的可学习变换问题,整个anchor-base目标检测算法训练就更加容易,理论上就可以构建完美目标检测器。
举个简单例子说明anchor的作用。假设某一张图片就一个gt bbox,其x1y1wh坐标是(200,300,100,120),如果采用固定宽高滑动窗口方法,假设窗口wh是(100,100),那么最好的预测情况也仅仅是(200,300,100,100),如果采用anchor做法,在原图上均匀铺设wh为(100,100)的anchor,那么假设在所有anchor中,存在一个cxcywh坐标为(200+100/2=250,300+120/2=360,100,100)的anchor,并且该anchor负责预测唯一的gt bbox。为了充分利用anchor的信息,我们可以设置网络输出的4个值txtytwth为anchor和gt bbox的相对值,具体做法非常多,一个非常简单的做法是txty表示gt bbox中心点和anchor中心点的相对偏移,而twth表示gt bbox的宽高除以gt bbox的宽高,这样就将gt bbox和anchor先验进行绑定了,从而能够实现又快又好收敛。
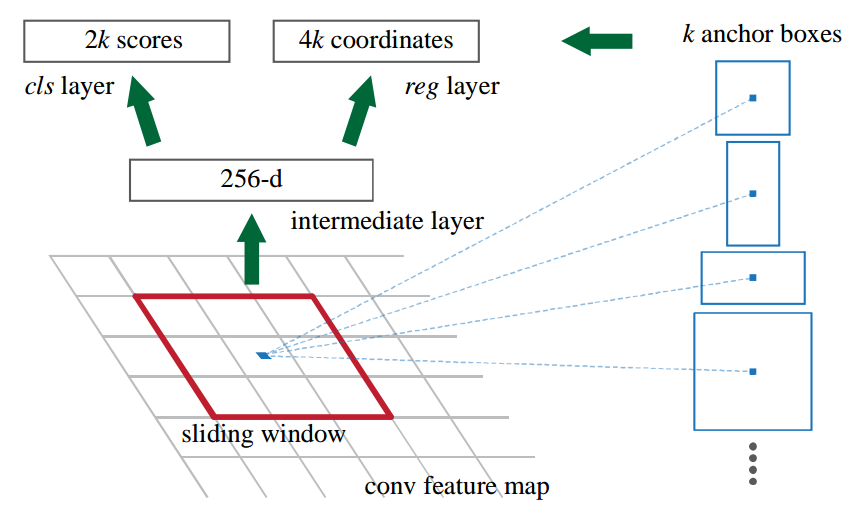
1.2 backbone
原版RPN网络采用的骨架是vgg,但是由于vgg性能以及设计思想过于陈旧,目前基本上都是采用resnet,故mmdet里面实现的RPN算法采用的是resnet50,配置如下所示:
backbone=dict(type='ResNet',depth=50,num_stages=3,strides=(1, 2, 2),dilations=(1, 1, 1),out_indices=(2, ),frozen_stages=1,norm_cfg=dict(type='BN', requires_grad=False),norm_eval=True,style='caffe'),
上述每个参数含义请参考mmdet官方文档,核心参数是out_indices=(2, ),表示backbone的输出是1个尺度,且stride为16,对于resnet50而言,输出特征图shape为(batch,1024,h//16,w//16)
1.3 head
在上述输出特征图基础上可以构建RPN head网络,输出分类和回归两个分支。
以mmdet复现为例进行分析,假设每个位置一共K个anchor,分类分支仅仅需要区分前后景即可,不需要区分具体类别(因为rcnn会进行区分),如果分类loss采用softmax+ce,那么分类分支输出shape是(batch,2*K,h/16,w//16),如果分类loss采用sigmoid+bce,那么该分支输出是(batch,1 *K,h/16,w//16),mmdet里面采用的是sigmoid+bce模式。对于回归分支,其输出shape为(batch,4*K,h/16,w//16)。其网络构建代码如下:
self.rpn_conv = nn.Conv2d(1024, 1024, 3, padding=1)self.rpn_cls = nn.Conv2d(1024,self.num_anchors * 1, 1)self.rpn_reg = nn.Conv2d(1024, self.num_anchors * 4, 1)
head网络前向推理也非常简单:
# 通道变换x = self.rpn_conv(x)x = F.relu(x, inplace=True)# 输出Headrpn_cls_score = self.rpn_cls(x)rpn_bbox_pred = self.rpn_reg(x)return rpn_cls_score, rpn_bbox_pred
1.4 正负样本定义
在介绍正负样本定义前,需要先说明RPN网络的Anchor设定规则,其配置如下:
anchor_generator=dict(type='AnchorGenerator',scales=[2, 4, 8, 16, 32],ratios=[0.5, 1.0, 2.0],strides=[16]),
其中strides参数不能随便更改,应该和网络stride一致,scales表示缩放尺度,ratios表示高宽比例,通过scales和ratios可以看出每个位置一共5x3=15个anchor,基本范围是,可以覆盖各种大小比例的物体,注意原论文是9个anchor,scale仅仅有(8,16,32)。假设输入图片大小是(800,600),且anchor个数为9,则整个效果如下所示:
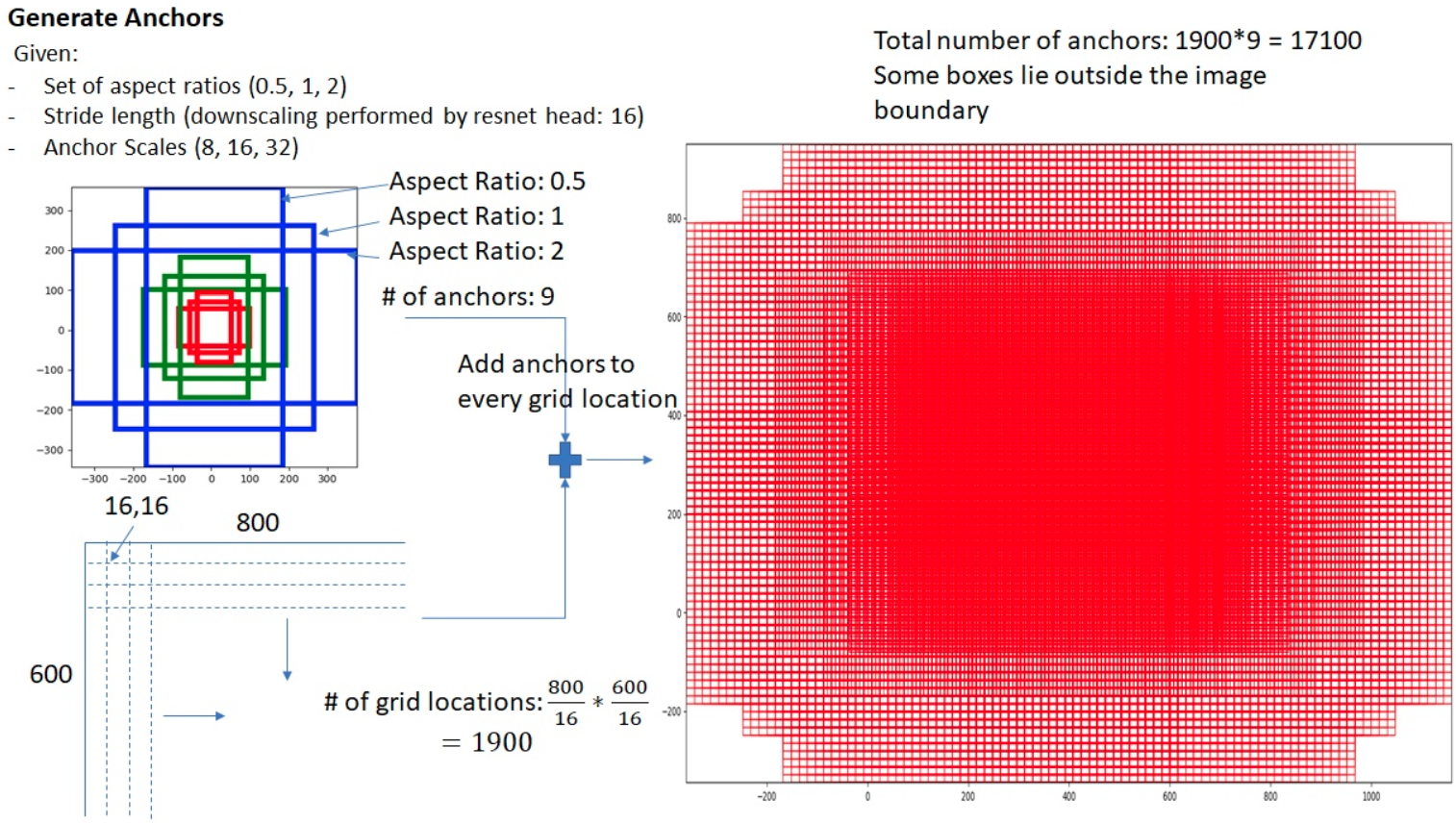
图片来源:https://zhuanlan.zhihu.com/p/31426458
AnchorGenerator代码实现分析如下所示:
(1) 先对单个位置(0,0)生成base anchors
# base_size=strides=16w = base_sizeh = base_size# 计算高宽比例h_ratios = torch.sqrt(ratios)w_ratios = 1 / h_ratios# base_size乘上宽高比例乘上尺度,就可以得到5x3=15个anchor的原图尺度wh值ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)# 得到x1y1x2y2格式的base_anchor坐标值base_anchors = [x_center - 0.5 * ws, y_center - 0.5 * hs, x_center + 0.5 * ws,y_center + 0.5 * hs]# 堆叠起来即可base_anchors = torch.stack(base_anchors, dim=-1)
(2) 利用输入的特征图大小加上base anchors,得到每个特征图位置的对于原图的anchors
# 特征图大小,这里是(h//16,w//16)feat_h, feat_w = featmap_size# 遍历特征图上所有位置,并且乘上stride,从而变成原图坐标shift_x = torch.arange(0, feat_w, device=device) * stride[0]shift_y = torch.arange(0, feat_h, device=device) * stride[1]shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)shifts = shifts.type_as(base_anchors)# (0,0)位置的base_anchor,假设原图上坐标shifts,即可得到特征图上面每个点映射到原图坐标上的anchorall_anchors = base_anchors[None, :, :] + shifts[:, None, :]all_anchors = all_anchors.view(-1, 4)return all_anchors
在生成了h//16xw//16x5x3个anchor后,需要定义每个样本的正负属性,因为目标检测包括分类和回归分支,既然是分类问题那就肯定需要定义每个anchor样本的正负属性。RPN网络采用的正负样本定义规则为MaxIoUAssigner,其核心匹配规则是iou交并比,其配置如下:
assigner=dict(type='MaxIoUAssigner',pos_iou_thr=0.7,neg_iou_thr=0.3,min_pos_iou=0.3,ignore_iof_thr=-1),
MaxIoUAssigner的操作包括4个步骤:
- 首先初始化每个anchor的mask都是-1,表示都是忽略anchor
- 将每个anchor和所有gt bbox计算iou,找出最大iou,如果该iou小于neg_iou_thr,则该anchor的mask设置为0,表示是负样本(背景样本)
- 将每个anchor和所有gt bbox计算iou,找出最大iou,如果其最大iou大于等于pos_iou_thr,则设置该anchor的mask设置为1,表示该anchor负责预测该gt bbox,且是高质量anchor
- 3的设置可能会出现某些gt bbox没有分配到对应的anchor(由于iou低于pos_iou_thr),故下一步对于每个gt bbox还需要找出和最大iou的anchor位置,如果其iou大于min_pos_iou,将该anchor的mask设置为1,表示该anchor负责预测对应的gt。通过本步骤,可以最大程度保证每个gt bbox都有相应的anchor负责预测,如果其最大iou值还是小于min_pos_iou,那就没办法了,只能当做忽略样本了。从这一步可以看出,3和4有部分anchor重复分配了,即当某个gt bbox和anchor的最大iou大于等于pos_iou_thr,那肯定大于min_pos_iou,此时3和4步骤分配的同一个anchor。
从上面4步分析,可以发现每个gt可能和多个anchor进行匹配,每个anchor不可能存在和多个gt bbox匹配的场景。在第4步中,每个gt最多只会和某一个anchor匹配,但是实际操作时候为了多增加一些正样本,通过参数gt_max_assign_all可以实现某个gt和多个anchor匹配场景。通常第4步引入的都是低质量anchor,网络训练有时候还会带来噪声,可能还会起反作用。
简单总结来说就是:如果anchor和gt的iou低于neg_iou_thr的,那就是负样本,其应该包括大量数目;如果某个anchor和其中一个gt的最大iou大于pos_iou_thr,那么该anchor就负责对应的gt;如果某个gt和所有anchor的iou中最大的iou会小于pos_iou_thr,但是大于min_pos_iou,则依然将该anchor负责对应的gt;其余的anchor全部当做忽略区域,不计算梯度。该最大分配策略,可以尽最大程度的保证每个gt都有合适的高质量anchor进行负责预测。
下面结合代码进行分析:主要就是assign_wrt_overlaps函数,核心操作和注释如下:
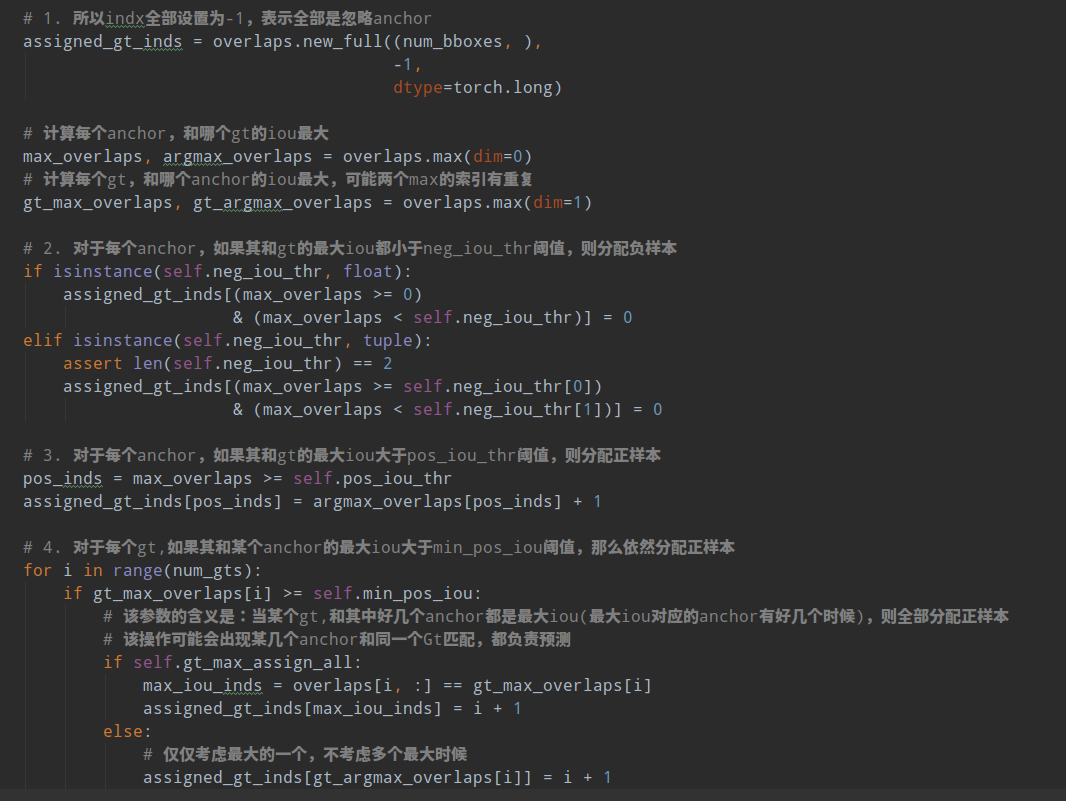
在RPN中由于anchor非常多,所以设置pos_iou_thr值比较大为0.7,保证正样本基本上都是高质量的,如果设置为0.5,则会增加大量正样本,其中含有很多低质量样本。
1.5 正负样本采样
正负样本定义环节可以区分正负和忽略样本,但是依然存在大量的正负样本不平衡问题,解决办法可以通过正负样本采样或者loss来解决,RPN网络是通过正负样本采样解决上述问题。其配置如下:
sampler=dict(type='RandomSampler',num=256,pos_fraction=0.5,neg_pos_ub=-1,add_gt_as_proposals=False)
其采样器比较简单,就是随机采样。num表示采样后每张图片的样本总数,不包括忽略样本,pos_fraction表示其中的正样本比例,这里意思是正负样本各自采样128个。add_gt_as_proposals是为了防止正样本太少而加入的,可以保证前期收敛更快、更稳定,属于技巧。neg_pos_ub表示正负样本比例,用于确定负样本采样个数上界,例如我打算采样1000个样本,正样本打算采样500个,但是可能实际正样本才200个,那么正样本实际上只能采样200个,如果设置neg_pos_ub=-1,那么就会对负样本采样800个,用于凑足1000个,但是如果设置为neg_pos_ub比例,例如1.5,那么负样本最多采样200x1.5=300个,最终返回的样本实际上不够1000个,默认情况neg_pos_ub=-1。
其代码非常简单:
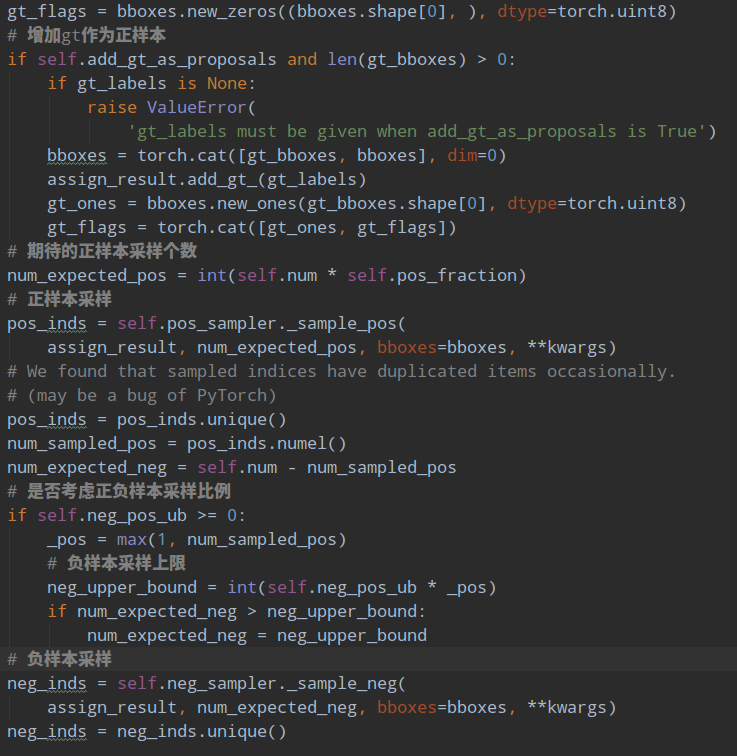
# 随机采样正样本def _sample_pos(self, assign_result, num_expected, **kwargs):"""Randomly sample some positive samples."""pos_inds = torch.nonzero(assign_result.gt_inds > 0, as_tuple=False)if pos_inds.numel() != 0:pos_inds = pos_inds.squeeze(1)if pos_inds.numel() <= num_expected:return pos_indselse:return self.random_choice(pos_inds, num_expected)# 随机采样负样本def _sample_neg(self, assign_result, num_expected, **kwargs):"""Randomly sample some negative samples."""neg_inds = torch.nonzero(assign_result.gt_inds == 0, as_tuple=False)if neg_inds.numel() != 0:neg_inds = neg_inds.squeeze(1)if len(neg_inds) <= num_expected:return neg_indselse:return self.random_choice(neg_inds, num_expected)
对正负样本单独进行随机采样就行,如果不够就全部保留。
1.6 bbox编解码
为了能够利用anchor信息进行更好的收敛,RPN会对head输出的bbox分支4个值进行编解码操作,作用有两个:1.更好的平衡分类和回归分支loss;2.训练过程中引入anchor信息。RPN采用的编解码函数是DeltaXYWHBBoxCoder,其配置如下:
bbox_coder=dict(type='DeltaXYWHBBoxCoder',target_means=[.0, .0, .0, .0],target_stds=[1.0, 1.0, 1.0, 1.0]),
target_means和target_stds相当于对bbox回归的4个txtytwth进行额外变换,目的是更好的平衡4个输出值。先不考虑target_means和target_stds,其编码公式如下:
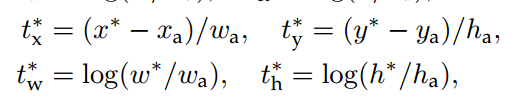
是gt bbox的中心xy坐标,是gt bbox的wh值,是anchor的中心xy坐标,是anchor的wh值,是bbox分支输出的4个值对应targets,此过程相当于gt bbox编码。容易看出其txty的预测值表示gt bbox中心相对于anchor中心点的偏移,并且通过处于anchor的wh进行归一化;而twth的预测值表示gt bbox的wh除以anchor的wh,然后取log非线性变换即可。
有了上述公式,对预测值进行bbox解码也非常容易,此处就不写了。
编码过程核心代码:
dx = (gx - px) / pwdy = (gy - py) / phdw = torch.log(gw / pw)dh = torch.log(gh / ph)deltas = torch.stack([dx, dy, dw, dh], dim=-1)# 最后减掉均值,处于标准差means = deltas.new_tensor(means).unsqueeze(0)stds = deltas.new_tensor(stds).unsqueeze(0)deltas = deltas.sub_(means).div_(stds)
解码过程核心代码:
# 先乘上std,加上meanmeans = deltas.new_tensor(means).view(1, -1).repeat(1, deltas.size(1) // 4)stds = deltas.new_tensor(stds).view(1, -1).repeat(1, deltas.size(1) // 4)denorm_deltas = deltas * stds + meansdx = denorm_deltas[:, 0::4]dy = denorm_deltas[:, 1::4]dw = denorm_deltas[:, 2::4]dh = denorm_deltas[:, 3::4]# wh解码gw = pw * dw.exp()gh = ph * dh.exp()# 中心点xy解码gx = px + pw * dxgy = py + ph * dy# 得到x1y1x2y2的gt 预测坐标x1 = gx - gw * 0.5y1 = gy - gh * 0.5x2 = gx + gw * 0.5y2 = gy + gh * 0.5
1.7 loss计算
在确定了每个anchor的正负属性,并且已经得到每个正样本anchor所负责gt bbox的bbox编码值,就可以计算loss了。对于分类分支mmdet采用的是bce loss,对于回归分支mmdet采用的是l1 loss(原论文是smooth l1 loss,实验效果表示l1 loss好一些),并且回归分支仅仅计算正样本的loss,配置如下:
loss_cls=dict(type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),loss_bbox=dict(type='L1Loss', loss_weight=1.0)))
2 推理流程
配置如下所示:
rpn=dict(nms_across_levels=False,nms_pre=12000,nms_post=2000,max_num=2000,nms_thr=0.7,min_bbox_size=0))
推理流程如下所示:
1.遍历每张图片,经过backbone+head后输出分类rpn_cls_score和回归预测值rpn_bbox_pred,然后对分类rpn_cls_score进行sigmoid操作得到概率值
scores = rpn_cls_score.sigmoid()
2.对rpn_cls_score值进行降序排列,提取前nms_pre个位置预测值,防止后续nms操作由于输入样本过多导致耗时
if cfg.nms_pre > 0 and scores.shape[0] > cfg.nms_pre:ranked_scores, rank_inds = scores.sort(descending=True)topk_inds = rank_inds[:cfg.nms_pre]scores = ranked_scores[:cfg.nms_pre]rpn_bbox_pred = rpn_bbox_pred[topk_inds, :]anchors = anchors[topk_inds, :]
3.对保留的位置进行bbox解码,得到原图尺度bbox
proposals = self.bbox_coder.decode(anchors, rpn_bbox_pred, max_shape=img_shape)
4.对所有解码后bbox进行nms操作,并取分值排名前cfg.nms_post个输出
nms_cfg = dict(type='nms', iou_threshold=cfg.nms_thr)dets, keep = batched_nms(proposals, scores, ids, nms_cfg)return dets[:cfg.nms_post]
3 总结
RPN网络虽然看起来比较简单,但是其也属于one-stage算法,只不过没有区分类别而已,可以说后面的SSD和RetinaNet以及后续算法都参考了RPN的设计思路,其包含了目标检测算法常用的多个模块:backbone、head、正负样本定义、正负样本采样、bbox编码码和Loss设计,其规范化的算法流程深深的影响了整个one-stage目标检测算法发展。深入理解RPN网络非常有助于理解目前主流的RetinaNet算法。
