@spiritnotes
2016-03-10T15:11:59.000000Z
字数 18274
阅读 5615
《Spark机器学习》
Spark 机器学习 读书笔记

第1章 Spark的环境搭建与运行
1.1 本地安装与配置
直接下载预编译好的版本。
测试:MASTER=local2 ./bin/run-example org.apache.spark.examples.SparkPi
1.2 集群
由两类程序组成:一个驱动程序和多个执行程序;
单机模式的Spark集群:一个运行在Spark单机主进程和驱动程序的主节点;各自运行一个执行程序进程的多个工作节点;
MASTER=spark://IP:PORT ./bin/run-example ...
1.3 Spark编程模型
Spark程序的编写是从SparkContext开始的。SparkContext初始化需要SparkConf对象。
Scala shell:./bin/spark-shell
python shell:./bin/pyspark
弹性分布式数据集
RDD(Resilient Distributed Dataset)是Spark的核心概念。一个RDD代表一系列的“记录”(严格来说,某种类型的对象)。这些记录被分配或分区到一个集群的多个节点上。RDD具有容错性,当某个节点或任务失败时(非用户代码),RDD会在余下节点上自动重建。
创建RDD,sc.parallelize(list_)/sc.textFile("file")。
Spark编程模式下,所有的操作分为转换(transformation)和执行(action)两种。转换操作是对一个数据集中的所有记录执行某种函数,从而使其记录发生改变;而执行通常是运行某种计算或者聚合操作,并将结果返回运行SparkContext的那个驱动程序。
rdddata.map(lambda x:x.upper())
rdddata.count() 返回其个数
转换操作是延后的,调用转换操作并不会执行计算,只有执行操作被调用时才会高效的计算。大部分操作在集群上并行执行,只有必要时才计算结果并将其返回给驱动程序,提高效率。
- RDD缓存策略
- 调用rdddata.cache()会将该RDD缓存到内存中。
- 广播变量(broadcast variable)
- 为只读变量,它由运行SparkContext的驱动程序创建后发送给会参与计算的节点。
v = sc.broadcast(....) 工作节点访问时使用value方法,v.value()
rdddata.collect()是一个执行函数,数据以集合形式返回驱动程序。 - 累加器(accumulator)
- 也是一种被广播到工作节点的变量。累加器可以累加,必须是一种有关联的操作,即它得能保证正在全局范围内累加起来的值能被正确地并行计算以及返回驱动程序。每个工作节点只能访问和操作其本地的累加器,全局累加器则只允许驱动程序访问。
1.4 Spark Scala编程入门
1.5 Spark Java编程入门
1.6 Spark Python编程入门
from pyspark import SparkContextsc = SparkContext("local[2]",'APP')data = sc.....all = data.count()uniqueUses = data.map(lambda record:record[0]).distinct().count()products = data.map(lambda record:(record[1],1.0)).reduceByKey(lambda x,y:x+y).collect()#运行:#>$SPARK_HOME/bin/spark-submit pythonapp.py
1.7 在Amazon EC2上运行Spark
第2章 设计机器学习系统
现代的大数据场景包含如下需求:
- 必须能与系统的其他组件整合,尤其是数据的收集和存储系统、分析和报告以及前端应用
- 易于扩展且与其他组件相对独立,理想情况下,同时具有良好的水平和垂直可扩展性
- 支持高效完成所需类型的计算,即机器学习和迭代式分析应用
- 最好能同时支持批处理和实时处理
2.1 MovieStream介绍
一个在线电影和电视节目的内容服务。
2.2 机器学习系统商业用例
为什么要使用机器学习
- 涉及的数据规模意味着完全依靠人工处理会很快跟不上系统的发展;
- 机器学习和统计模型等基于模型的方式能发现人类(因数据集量级和复杂度过高)难以发现的模式;
- 基于模型的方式能避免个人或者情感上的偏见;
- 个性化
- 推荐是个性化的一种,常指向用户显式呈现某些产品或是内容。个性化有时也偏隐式,比如根据数据改变搜索结果,可能基于推荐的数据,或基于地理位置、搜索历史等,用户可能不会明显感觉到搜索结果的变化。
- 目标营销与客户细分
- 与推荐类似的方法从用户群中找出要营销的对象。推荐和个性化一般是一对一,而客户细分则试图将用户分成不同的组。其分组依据用户的特征,也可以是其行为数据。有助于理解各组用户的共性、同组用户之间的相似性以及不同组之间的差异。
- 预测建模与分析
- 借助活动记录、收入数据以及内容属性,可以创建回归模型来预测新电影的市场表现,也可以使用分类模型来对只有部分数据的新电影自动分配标签、关键字或分类。
2.3 机器学习模型的种类
监督学习
非监督学习
2.4 数据驱动的机器学习系统的组成
- 数据获取与存储
- 获取数据并存储,原始数据、即时处理后的数据、以及用于生成系统的最终建模结果。存储时可能涉及多种文件系统。
- 数据清理与转换
- 特征通常是输入变量所对应的可用于模型的数值表示。预处理可能包含如下几种:
1)数据过滤:可能是最近几月的活动数据或者满足特定条件的事件数据;
2)处理数据缺失、不完整或有缺陷:过滤或填充
3)处理可能的异常、错误和异常值:过滤或修改
4)合并多个数据源:内部数据(用户属性),外部数据(地理位置、天气、经济数据)
5)数据汇总:如某些事件类型的总数目 - 模型训练与测试回路
- 模型选择、集成学习、交叉验证
- 模型部署与整合
- 找出最近模型,将其部署到生成系统
- 模型监控与反馈
- 其在新数据上的表现是否符合预期?准确度怎么样?通常还应该关注其他业务效果(比如收入、利润率)或用户体验(比如站点使用时间和用户总体活跃度)的相关指标。现实中应该同时监控模型准确度相关指标和业务指标。模型反馈是指用户的行为来对模型的预测进行反馈的过程。
- 批处理或实时方案的选择
- Spark提供了实时流处理组件 Spark Streaming。
2.5 机器学习系统架构
离线训练结果
在线模型,模型更新
第3章 Spark上数据的获取、处理与准备
3.1 获取公开数据集
- UCI机器学习知识库:300个数据集,http://archive.ics.uci.edu/ml
- Amazon AWS公开数据集:包含人类基因组项目、Common Crawl网页语料库、维基百科、google book Ngrams。http://aws.amazon.com/publicdatasets/
- Kaggle:集合了Kaggle举行的各类机器学习竞赛所用的数据集,覆盖分类、回归、排名、推荐系统以及图像分析领域。http://www.kaggle.com/competitions
- KDnuggets:详细的公开数据集列表。http://www.kdnuggets.com/datasets/index.html
3.2 探索与可视化数据
user_data = sc.textFile('ml-100k/u.user')user_data.first()user_fields = user_data.map(lambda line:line.split('|'))num_genders = user_fields.map(lambda filelds:filelds[1]).distinct().count()
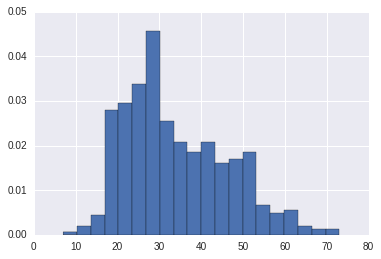
年龄可视化
ages = user_fields.map(lambda x: int(x[1])).collect()pylab.hist(ages, bins=20,normed=True)
职业分布
count_by_occuption = user_fields.map(lambda i:(i[3],1)).reduceByKey(lambda x,y:x+y).collect()count_by_occuption.sort(key=operator.itemgetter(1))xy = list(zip(*count_by_occuption))pos = np.arange(len(xy[0]))width = 1.0ax=plt.axes()ax.set_xticks(pos+(width/2))ax.set_xticklabels(xy[0])plt.bar(pos,xy[1],width,color='lightblue')plt.xticks(rotation=30)fig=plt.gcf()fig.set_size_inches(10,6)

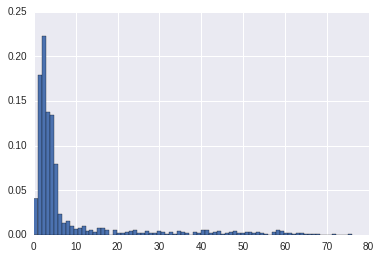
电影年龄查看
movie_ages2 = movie_fileds.map(lambda fields:1998 - covert_year(fields[2])).filter(lambda x:x!=98)movie_ages = years_filtered.map(lambda r:1998-r).countByValue()
movie_ages2 = movie_fileds.map(lambda fields:1998 - covert_year(fields[2])).filter(lambda x:x!=98).collect()pylab.hist(movie_ages2, bins=80,normed=True)
3.3 处理与转换数据
大致处理办法
- 过滤掉或者删除非规整或有缺失值的数据
- 填充非规整或缺失的数据,包括用0值、全局期望、中值来填充,或根据相邻或类似的数据点来做插值(通常针对有序数据)
- 对异常值做鲁邦处理,异常值的问题在于即使它是极值也不一定就是错的,可将其移除或者填充,也存在有些统计技术(如鲁棒回归)可用于处理异常值或是极值
- 对可能的异常值进行转换,对那些可能存在异常值或值域覆盖过大的特征,利用如对数或高斯核对其转换,这类转换有助于降低变量存在的值跳跃的影响,并将非线性关系变为线性的
3.4 从数据中提取有用特征
特征是指那些用于模型训练的变量。
- 数值特征:实数或整数
- 类别特征:有限可能状态中的一种
- 文本特征:文本内容
- 其他特征:图像、视频、音频、地理数据等
类别特征
名义(nominal)变量:各个可能取值之间没有顺序关系
有序(ordinal)变量:存在顺序关系的
1-of-k编码: 用n位的向量来保存值,相应位赋值1, [0,0,...,0,1,0,...]
派生特征
派生特征可以包括:平均值、中位值、方差、和、差、最大值、最小值、计数等
电影上可以创建每个用户评分的平均值、方差等
数值特征到类别特征的转换也很常见,比如划分为区间特征。进行这类转换常见的有年龄、地理位置和时间。
例如将电影影评时间转变为小时,将小时划区间再使用1-of-k编码。
文本特征
自然语言处理是专注于文本内容的处理、表示和建模的一个领域。词袋方法
- 分词
- 删除停用词
- 提取词干
- 向量化
all_terms_bcast = sc.broadcast(all_terms_dict)term_vectors = title_terms.map(lambda terms:create_vector(terms, all_terms_bcast.value)
正则化
- 正则化特征:对单个特征进行转换,比如减去平均值(特征对齐)或标准正则转换(以使得该特征的平均值和标准差分别为0和1)
- 正则化特征向量:通常对数据某一行的所有特征进行转换,让转换后的特征向量的长度标准化,也就是缩放向量中的各个特征以使得向量的范数为1(常指1阶或2阶范数)
可借助软件包提取特征:scikit-learn、gensim、scikit-image、matplotlib、NLTK、OpenNLP、Breeze
第4章 构建基于Spark的推荐引擎
推荐引擎适合如下两类常见场景
- 可选项众多
- 偏个人爱好
4.1 推荐模型的分类
基于内容的过滤
协同过滤
矩阵分解
推荐模型中包括矩阵分解(matrix factorization)的实现
显式矩阵分解
用户-商品矩阵可以分解为2个低阶且乘积近似的矩阵,因式分解 U×I->U×K K×I
这类模型试图发现对应“用户-物品”矩阵的内在行为结构的隐含特征(这里表现为因子矩阵),所以也称为隐特征模型。隐含特征或因子不能直接解释,但它可以表示了某种含义,如对电影的某个导演/种类/风格或某些演员的偏好
对用户进行预测,则分别取对应的行(用户因子向量)和列(物品因子向量)计算点积即可。
而对于物品之间相似度的计算,则直接应用物品因子向量进行计算。
好处:模型建立后求解相对容易,表现通常比较出色
弊端:物品和用户数量多时,存储和计算较多,不好解释
隐式矩阵分解
隐式反馈数据,其中偏好没有直接给出,而是隐含在用户与物品的交互之中。比如电影是否看,看了几次
MLlib将输入的评级数据视为两个矩阵:一个二元偏好矩阵P(是否购买)与一个信心权重矩阵C(购买次数或评分)。隐式模型创建的是二元偏好矩阵的而非评级矩阵的近似。此时用户因子向量和物品因子向量的点积所得到的分数就是对某一物品偏好的估值。
最小二乘法
ALS
4.2 提取有效特征
rating_data_raw = sc.textFile('ml-100k/u.data')rating_data = rating_data_raw.map(lambda line:line.split('\t'))rating = rating_data.map(lambda line:(int(line[0]), int(line[1]), float(line[2])))
4.3 训练模型
- rank:对应ALS模型中的因子个数,也就是在低阶近似矩阵中隐含特征个数,因子个数一般越多越好,但是会影响模型训练和保存时所需的内存开销,实践中常作为调节参数,通常合理取值为10~200
- iterations:对应运行时的迭代次数,ALS能确保每次迭代时能降低评级矩阵的重建误差,但一般经过少数次数就已经能收敛为一个比较合理的模型了,大部分情况下,不需要迭代太多次(10次)
- lambda:该参数控制模型正则化过程,从而控制模型的过拟合情况,其值越高,正则化越厉害,需要进行交叉验证调整
from pyspark.mllib.recommendation import ALS, MatrixFactorizationModel, Ratingrs_model = ALS.train(rating, 50, 10)rs_model.userFeatures().count()rs_model.productFeatures().count()
使用隐式反馈数据训练模型
trainImplict,先将数据转换为隐式数据集,可以通过设置阀值实现
4.4 使用推荐模型
用户推荐
ALS初始化是随机的,因此不同模型结果不一样
rs_model.predict(789, 123)rs_model.recommendProducts(789,10)
物品推荐
衡量方法有皮尔森相关系数、针对实数向量的余弦相似度以及针对二元向量的杰卡德相似系数
rs_model.productFeatures().map(lambda x: (x[0], cossimilarity(x[1], product_567))).sortBy(lambda x:-x[1]).take(10)rs_model.productFeatures().map(lambda x: (x[0], cossimilarity(x[1], product_567))).top(10, lambda x:x[1])
4.5 推荐模型效果的评估
评估指标(evaluation metric)是指那些衡量模型预测能力或准确度的方法。有些直接度量模型的预测的目标变量的好坏(比如均方差),有些则关注模型对那些其并未针对性优化过但又十分接近真实应用场景的预测能力(比如平均准确率)。
均方差
均方差(Mean Squared Error,MSE)直接衡量用户物品评级矩阵的重建误差,也ALS的最小化目标函数。
mse = rs_model.predictAll(all_user_items).map(lambda x:((x.user, x.product), x.rating)).join(rating.map(lambda x:((x[0],x[1]),x[2]))).map(lambda y:(y[1][0]-y[1][4])**2).sum()/100000
均方根误差(Root Mean Squared Erro,RMSE)在上面结果开根号
K值平均准确率(MAPK)
整个数据集上的K值平均准确率(Average Precision at K metric,APK)的均值。更适合于评估隐式数据集上的推荐,MSE此时不那么合适。
分布推荐
items = mod.productFeatures.map().collect()ibroastcast = sc.broadcast(items_matrix)def rocommend(user_vec):scores = ibroadcast.value.mmul(user_vec).data.zipWithIndex.sortBy(lambda x:x[1]).map(_._2+ 1).toseqreturn user_id, scoresmodel.userFeatures.map(lambda line: rocommend(line))
使用MLlib内置的评估函数
import org.apache.spark.mllib.evaluation.RegressionMetricsx = RegressionMetrics(RDD[(predict, actual)])x.meanSquaredError()x.rootMeanSquaredError()
MAP
import org.apache.spark.mllib.evaluation.RankingMetrics
第5章 Spark构建分类模型
分类模型的种类
线性模型:容易扩展
决策树:非线性,性能好,
朴素贝叶斯:快速
线性模型
可用于回归和分类
分类
回归 对等连接函数I
- 逻辑回归
- 逻辑回归是一个概率模型,预测结果值域为[0,1],对于二分类,逻辑回归的输出等价于模型预测某个数据点属于正类的概率估计。y是实际的输出值,正类为1,负类为-1
使用逻辑连接
逻辑损失 - 支持向量机
- 不是概率模型,可以基于模型对正负的估计预测类别
连接函数为对等函数 ,当估计大于赋值0时,标记1,否则0
损失函数为合页损失 - 朴素贝叶斯
- 是一个概率模型,通过计算给定点在某个类别中的概率来进行预测,朴素贝叶斯假定特征之间是相互独立的
MLlib实现了多项朴素贝叶斯模型 - 决策树
- 非概率模型,可以表达复杂的非线性模型和特征相互关系,适合应用继承方法,比如决策树森林
5.2 从数据中抽取合适的特征
Mlib的分类模型通过 LabeledPoint 对象操作,构建函数为 (label:double, features:vector)
5.3 训练分类
from pyspark.mllib.classification import SVMWithSGD, SVMModelfrom pyspark.mllib.classification import LogisticRegressionWithLBFGS, LogisticRegressionModelfrom pyspark.mllib.regression import LinearRegressionWithSGD, LinearRegressionModelfrom pyspark.mllib.regression import LabeledPointfrom pyspark.mllib.regression import LabeledPoint, LinearRegressionWithSGD, LinearRegressionModelfrom pyspark.mllib.linalg import Vectorsfrom pyspark.mllib.tree import DecisionTree,DecisionTreeModelfrom pyspark.mllib.classification import NaiveBayes,NaiveBayesModelsvm_model = SVMWithSGD.train(digits, 10)log_model = LogisticRegressionWithLBFGS.train(digits,10)nb_model = NaiveBayes.train(digits)dc_model = DecisionTree.trainClassifier(digits, 2, {})
5.4 使用分类模型
svm_model.predict(p.features)all_predict = svm_model.predict(digits.map(lambda x:x.features))all_predict.take(5)
5.5 评估分类模型的性能
预测的正确率和错误率
for model in [svm_model, nb_model, log_model, dc_model]:print(model.__class__.__name__, digits.map(lambda x:1 if model.predict(x.features) == x.label else 0).sum() /digits.count()SVMModel 0.9015817223198594NaiveBayesModel 0.8963093145869947LogisticRegressionModel 0.9824253075571178
准确率和召回率
准确率与召回率基本是负相关的。
准确率-召回率曲线,从左上到右下的曲线
ROC和AUC
ROC是指的真阳性-假阳性曲线
真阳性是正样本中判为阳性的比例,如召回率
假阳性是负样本中判为阳性的比例,误诊率
from pyspark.mllib.evaluation import BinaryClassificationMetricsfor model in [svm_model, nb_model, log_model, dc_model]:pre = model.predict(features).zip(label)metric_ = BinaryClassificationMetrics(pre)print(model.__class__.__name__, metric_.areaUnderPR, metric_.areaUnderROC)
5.6 改进模型性能以及参数调整
from pyspark.mllib.linalg.distributed import RowMatrixsummary = metric2.computeColumnSummaryStatistics()?
正则化
from pyspark.mllib.feature import StandardScalerlabel = digits.map(lambda x: x.label)features = digits.map(lambda x: x.features)std_ = StandardScaler(withMean = True, withStd=True).fit(features)scaled_data= label.zip(std_.transform(features))
模型参数调优?
iterresults = sc.para([1,2,3,4,5]).map(lambda para: trainwith ....)
SGD 随机梯度下降
- 迭代次数:在增加到特定次数后,再增大迭代次数对结果影响不大了
- 步长:步长大收敛快,可能到局部最优解
- 正则化:实际数据中一般都是必须的
- SimpleUpdater:相当于无正则化
- SquaredL2Updater:L2正则化
- L1Updater:L1正则化
交叉验证
第6章 Spark构建回归模型
6.1 回归模型的种类
两个回归模型:
- 线性模型
- 决策树模型
标准的最小二乘回归不使用正则化,但是应用到错误预测值的损失函数会将错误做平方,从而放大损失。因此在实际中往往使用一定的正则化。岭回归,Lasso回归
决策树在回归使用的不纯度度量是方差。
6.2 从数据中抽取合适的特征
将2到9列转变为二元编码的多列格式
为线性模型创建特征向量
def get_mapping(rdd, idx):return rdd.map(lambda x:x[idx]).distinct().zipWithIndex().collectAsMap()mappings = [get_mapping(bk_table, i) for i in range(2,10)]from pyspark.mllib.regression import LabeledPointimport numpy as npdef extract_features(record):cat_vec = np.zeros(cat_len)i, step = 0, 0for field in record[2:9]:m = mappings[i]idx = m[field]cat_vec[idx+step] = 1i = i+1step += len(m)num_vec = np.array([float(field) for field in record[10:14]])return np.concatenate((cat_vec, num_vec))def extract_label(record):return float(record[-1])bk_data_re = bk_table.map(lambda x:LabeledPoint(extract_label(x), extract_features(x)))
为决策树创建特征向量
决策树只需要使用原数据就可以了
def extract_featrues_dt(r):return np.array([float(i) for i in r[2:14]])bk_data_dt = bk_table.map(lambda r:LabeledPoint(extract_label(r), extract_featrues_dt(r)))
6.3 回归模型的训练和应用
from pyspark.mllib.regression import LinearRegressionWithSGDfrom pyspark.mllib.tree import DecisionTreebk_re_model = LinearRegressionWithSGD.train(bk_data_re, iterations=10, step=0.1, intercept=False)bk_re_true_vs_pre = bk_data_re.map(lambda x:(x.label, bk_re_model.predict(x.features)))bk_dt_model = DecisionTree.trainRegressor(bk_data_dt, {})preds = bk_dt_model.predict(bk_data_dt.map(lambda p:p.features))actual = bk_data_dt.map(lambda p:p.label)bk_dt_true_vs_pre = actual.zip(preds)
6.4 评估回归模型的性能
均方误差与均方根误差(MSE、RMSE)
平均绝对误差
均方根对数误差
适用于目标变量值域很大,并且没有必要对预测值和目标值的误差进行惩罚的情况。适用于计算误差的百分率而不得hi误差的绝对值
R-平方系数
也称判定系数,用来评估模型拟合数据的好坏。
6.5 改进模型性能和参数调优
变换目标变量
原始目标变量
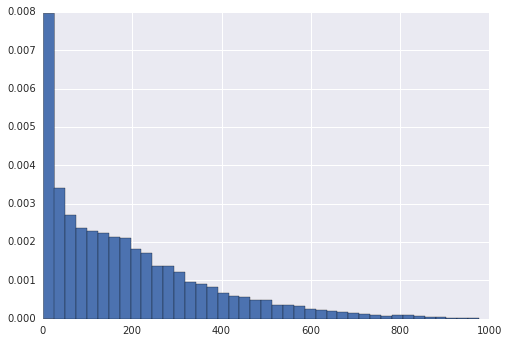
是非正态分布的
log后的目标变量
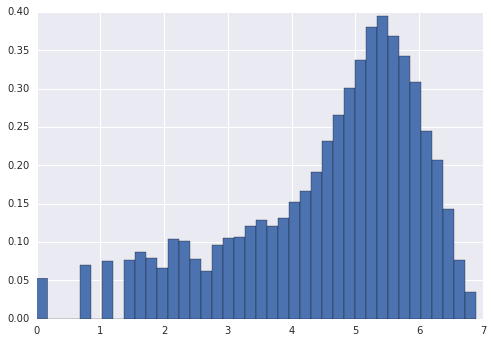
取平方根后的目标变量
对数变换影响
线性回归提高了RMSLE,对MSE和MAE无提升。
决策树模型性能下降
模型参数调优
- 迭代
- 性能达到一定次数后,性能增长缓慢
- 步长
- L2正则化
- L1正则化
- 截距
- 数据已经归一化,理论上不需要使用截距
- 决策树深度
- 决策树的深度过深存在过拟合,过浅存在欠拟合
- 最大划分数
- 划分数与深度对性能的影响雷同
第7章 Spark构建聚类模型
聚类的应用:
- 基于行为特征或者元数据将用户或者客户分成不同的组
- 对网站的内容或者零售店中商品进行分组
- 找到相似基因的类
- 在生态学中进行群体分割
- 创建图像分割用于图像分析的应用,如物体检测
7.1 聚类模型的类型
K-均值聚类
形式化的目标函数为类簇内的方差和(within cluster sum of squared errors,WCSS)
K均值结束条件为达到最大的迭代次数或者收敛。收敛意味着类分配后不再改变。
模糊K-均值 (fuzzy K-means)
混合模型:模糊K-均值的扩展
层次聚类(hierarchical clustering)
: 凝聚聚类(agglomerative clustering):每个样本为一个类,合并相近的类,一次一个
分裂式聚类(divisive clustering):将所有样本作为一个类,每次选择最好的分配方式,分配为两个类
7.2 从数据中提取正确的特征
MovieLens数据集
获取电影与类别对应关系
def get_movie_gen(line):movie_id = int(line[0])gens = []for i, gen in enumerate(line[5:]):if gen == '1':gens.append(ml_gen_map[str(i)])return (movie_id, gens)ml_title_gen = ml_lines.map(lambda x:x.split('|')).map(get_movie_gen)
训练推荐模型
from pyspark.mllib.recommendation import ALSfrom pyspark.mllib.recommendation import Ratingml_rating_lines = sc.textFile('ml-100k/u.data')ml_rating = ml_rating_lines.map(lambda x:x.split('\t')).map(lambda x:Rating(int(x[0]),int(x[1]),float(x[2])))ml_rating.cache()ml_rating_rs_model = ALS.train(ml_rating, 50, 10, 0.1)ml_movie_factors = ml_rating_rs_model.productFeatures()ml_movie_vec = ml_movie_factors.map(lambda x:x[1])ml_user_factors = ml_rating_rs_model.userFeatures()ml_user_vec = ml_user_factors.map(lambda x:x[1])
归一化
7.3 训练聚类模型
K均值提供了随机和K-means||两种初始化方法,后者默认初始化。K-均值通常都不能收敛到全局最优解,所以实际应用中需要多次训练并选择最优的模型。
from pyspark.mllib.clustering import KMeansml_model_movie_kmeans = KMeans.train(ml_movie_vec, 5, 100, 100)
7.4 使用聚类模型进行预测
ml_model_movie_kmeans.predict(ml_movie_vec.first())ml_model_movie_kmeans.predict(ml_movie_vec).take(5)
用数据集解释类别预测
7.5 评估聚类模型的性能
内部评价指标
WCSS、Davies-Bouldin指数、Dunn指数、轮廓系数(silhouette coefficient)
外部评价指标
Rand measure、F-measure、雅卡尔系数(Jaccard index)
ml_model_movie_kmeans.computeCost(ml_movie_vec)
7.6 聚类模型参数调优
交叉验证选择K
划分训练集和测试集,在训练集上采取不同的K值进行计算在测试集上进行验证
随着K的增加,WCSS会下降,但是在下降到某个拐点后,下降变得很缓慢
第8章 Spark应用于数据降维
降维方法从一个D维的数据输入提取出k维表示,k一般远远小于D。降维方法本身是一种预处理方法,或者说是一个特征转换的方法,而不是模型预测的方法。
降维中尤为重要的是,被抽取出的维度表示应该仍能捕捉大部分原始数据的变化和结构。这源于一个基本想法:大部分数据源包含某种内部结构,这种结构一般来说是未知的(常称为隐含特征或者潜在特征),但如果能发现结构中的一些特征,我们的模型就可以学习这种结构并从中预测,而不用从大量无关的充满噪声特征的原始数据中去学习预测。缩减维度可以排除数据中的噪声并保留数据原有的隐含结构。
数据降维使用场景
- 探索性数据分析
- 提取特征去训练其他机器学习模型
- 降低大型模型在预测阶段的存储和计算需求
- 将大量文档缩减为一组隐含话题
- 当数据维度很高时,使得学习和推广模型更加容易
8.1 降维方法的种类
mllib提供了两种相似的降低维度的模型:PCA与SVD
PCA
PCA处理一个数据矩阵,提取矩阵中的k个主向量,主向量彼此不相关,计算结果中,第一个主向量表示输入数据的最大变化方向。之后的每个主向量依次代表不考虑之前计算过的所有方向时最大的变化方向。
每个主成分向量上有着与原始数据矩阵相同的特征维度,需要使用映射来做一次降维,将原来的数据被投影到主向量表示的k为空间
SVD
#
都是矩阵分解技术,将原来的矩阵分解为一些维度(或秩)较低的矩阵
聚类作为降维的方法
将高维的特征向量使用K均值聚类为K个中心,根据原数据与K个聚类中心的远近(也就是计算出每个点到中心的距离)表示这些数据,结果就是一组k元距离。
通过使用不同的聚类矩阵,可以实现数据降维和非线性变化,或者可以通过高效的线性模型计算学习更复杂的模型。如使用高斯和指数距离函数可以实现非常复杂的非线性变换。
8.2 从数据中抽取合适的特征值
pics_all = sc.wholeTextFiles('lfw/*/*')plt.imshow(plt.imread(pic_paths.first()))plt.imshow(array(Image.open(pic_paths.first()).convert('L').resize((100,100))))
第9章 Spark高级文本处理技术
9.1 文本处理的特殊之处
文本和语言有隐含的结构信息,使用原始的文本很难捕捉到
文本数据的有限维度一般都非常巨大甚至是无限的
9.2 从语言中抽取合适的特征
自然语言处理(NLP)领域研究文本处理的技术包括特征提取、建模和机器学习。
短语加权表示
TF-IDF:
tf(t,d)是指t在文档d中出现的频率或次数
N是文档的总数,d是出现过单词t的文档数量
特征哈希
特征哈希是一种处理高维数据的技术,并经常应用在文本和分类数据上。使用1-of-k方法需要建立表格。特征哈希通过使用哈希方程对特征向量赋予向量下标。
- 缺点
- 因为我们没有创建特征到下标的映射,也就不能做逆向转换将下标转换为特征
因为限制了特征向量的大小,当两个不同的特征被哈希到同一个下标时会产生哈希冲突,如果特征向量维度选择合理的话,对于模型的影响不太大
从20groups获取数据
news_all = sc.wholeTextFiles('newsgroup/*/*/*')news_train = news_all.filter(lambda x:'train' in x[0] )news_test = news_all.subtractByKey(news_train)white_space_splits = news_train.map(lambda x: x[1]).flatMap(lambda x:x.split()).map(lambda x:x.lower())white_space_splits = news_train.flatMap(lambda x: (i.lower() for i in x[1].split()) )white_space_splits = news_train.flatMap(lambda x: (i.lower() for i in re.findall(r'\w+',x[1])))white_space_splits = news_train.flatMap(lambda x: (i.lower() for i in re.findall(r'\w+',x[1]))).filter(lambda x:re.fullmatch('[^0-9]*', x) is not None)
移除停用词,过滤掉单个字符的词语
white_space_splits = news_train.flatMap(lambda x: (i.lower() for i in re.findall(r'\w+',x[1]))).filter(lambda x:re.fullmatch('[^0-9]*', x) is not None)temp= white_space_splits.countByValue()temp2 = sorted(temp.items(), key=operator.itemgetter(1),reverse=True)stopwords = [i[0] for i in temp2[:30]]tokens = white_space_splits.distinct().filter(lambda x: len(x)!= 1).filter(lambda x: x not in stopwords).filter(lambda x:x not in onewords)
基于频率去掉词语
tokens_ = tokens.collect()
提取词干
def tokenize(doc):return sc.parallelize([i.lower() for i in re.findall(r'\w+', doc)]).filter(lambda x:re.fullmatch('[^0-9]*', x) is not None).filter(lambda x: len(x)!= 1).filter(lambda x: x not in stopwords)z = tokenize(news_train.first()[1])z.collect()
train_tokens = (news_train.map(lambda x: re.findall(r'\w+', x[1])).map(lambda x:[i.lower() for i in x if i.strip()]).map(lambda x:[i for i in x if re.fullmatch('[^0-9]*', i) is not None]).map(lambda x:[i for i in x if len(i)!= 1]).map(lambda x:[i for i in x if i not in stopwords]))
TF-IDF处理
from pyspark.mllib.linalg import SparseVectorfrom pyspark.mllib.feature import HashingTF,IDFhash_tf = HashingTF(2**18)tf = hash_tf.transform(train_tokens)idf = IDF().fit(tf)tfidf = idf.transform(tf)minMaxValues = tfidf.map(lambda x:(max(x.toArray()), min(x.toArray())))
9.3 使用TF-IDF模型
计算相似度
def cosine(a,b):return np.dot(a,b)/np.linalg.norm(a)/np.linalg.norm(b)cosine(np.array([1,2]),np.array([2,2]))x = hockey_tfidf.take(2)cosine(x[0].toArray(), x[1].toArray())
训练文本分类器
from pyspark.mllib.regression import LabeledPointfrom pyspark.mllib.classification import NaiveBayesfrom pyspark.mllib.evaluation import MulticlassMetricsnews_group = news_train.map(lambda x: x[0].split('/')[-2])new_group_map = news_group.distinct().zipWithIndex().collectAsMap()group_tfidf = news_group.zip(tfidf).map(lambda x: LabeledPoint(new_group_map[x[0]], x[1]))group_tfidf.cache()model = NaiveBayes.train(group_tfidf, lambda_=0.1)test_tf = hash_tf.transform(news_test.map(lambda x: re.findall(r'\w+', x[1])).map(lambda x:[i.lower() for i in x]).map(lambda x:[i for i in x if re.fullmatch('[^0-9]*', i) is not None]).map(lambda x:[i for i in x if len(i)!= 1]).map(lambda x:[i for i in x if i not in stopwords]))test_tfidf = idf.transform(test_tf)test_labels = news_test.map(lambda x: x[0].split('/')[-2]).map(lambda x:new_group_map[x])test_pred = model.predict(test_tfidf)pre_with_actual = test_pred.zip(test_labels)pre_with_actual.filter(lambda x:int(x[0])==int(x[1])).count()/pre_with_actual.count()#80.12%metrics = MulticlassMetrics(pre_with_actual)metrics.weightedFMeasure()?
9.4 评估文本处理技术的作用
原始方法也不错
9.5 Word2Vec模型
把一个单词表示成一个向量
分布向量表示,使用skip-gram模型,考虑了单词上下文来学习词向量表示的模型
from pyspark.mllib.feature import Word2Vecw2v = Word2Vec()w2v.setSeed(42)w2v_model = w2v.fit(train_tokens)list(w2v_model.findSynonyms('hockey',20))
第10章 Spark Streaming在实时机器学习上的应用
10.1 在线学习
在线学习以对训练数据进行完全增量的形式顺序处理一遍为基础(一次只训练一个样例)。
10.2 流处理
流处理是当数据产生时就开始处理
两种方式
- 单独处理每条记录,并在记录出现时立刻处理
- 把多个记录组合为小批量任务,可以通过记录数量或者时间长度划分出来
streaming使用第二种方式,核心概念是离散化流(DStream、Discretized Stream)。一个DStream是一个小批量作业的序列,每一个小批量作业表示为一个Spark RDD。
输入源:接收端负责从数据源接受数据并转换成由Spark RDD组成的DStream,支持多种输入源,包括文件、网络等
转换:提供了一个可以在DStream上使用的转换集合;与RDD上的类似,该转换操作RDD包含的数据
