@spiritnotes
2016-03-07T09:39:04.000000Z
字数 2591
阅读 3036
机器学习实践 -- Iris数据集
机器学习实践
获取
数据集本来就在sklearn,通过如下代码导入
from sklearn import datasetsdata = datasets.load_iris()
取出来的数据为字典对象,可以查看其下面的keys:
dict_keys(['data', 'feature_names', 'target', 'target_names', 'DESCR'])
样本分布为:
| 类别 | 样本数 |
|---|---|
| versicolor | 50 |
| setosa | 50 |
| virginica | 50 |
清理
通过数据分析未发现有NAN值,其值分布基本上符合正常。
data_pd = pd.DataFrame(data.data)data_pd.describe()0 1 2 3count 150.000000 150.000000 150.000000 150.000000mean 5.843333 3.054000 3.758667 1.198667std 0.828066 0.433594 1.764420 0.763161min 4.300000 2.000000 1.000000 0.10000025% 5.100000 2.800000 1.600000 0.30000050% 5.800000 3.000000 4.350000 1.30000075% 6.400000 3.300000 5.100000 1.800000max 7.900000 4.400000 6.900000 2.500000
数据都齐全,无缺失值
可视化
采用Python代码进行可视化,分别通过sb.pairplot查看特征分布

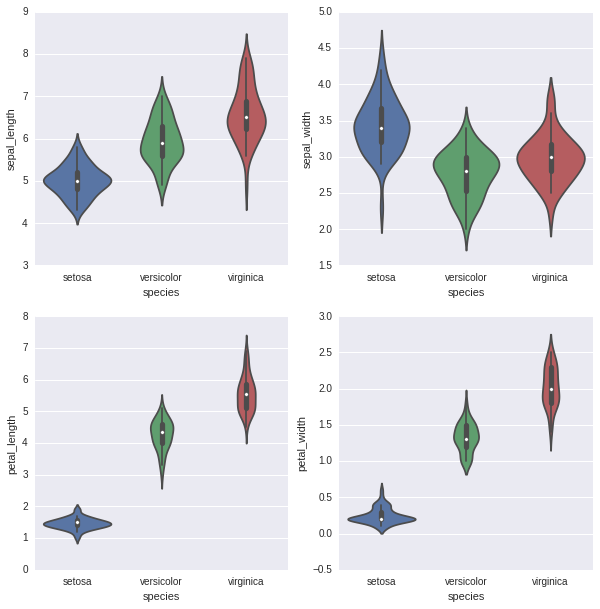
从图中可以看到
- 按照特征来说,setosa与其他两种差别较大,比较容易区分
- versicolor、vinginica两者有些交叉的部分,不易区分
同样violinplot如下:
降维
IsoMap
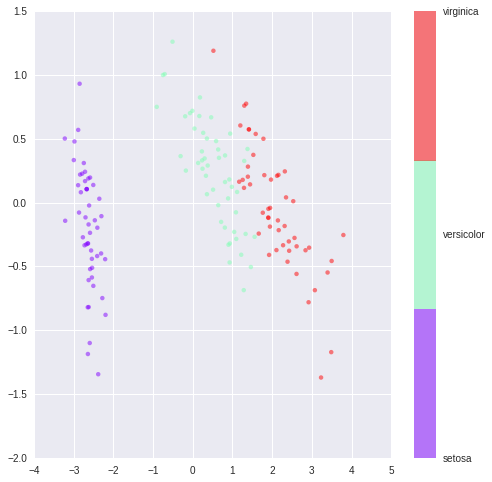
通过isomap降维后的数据如图所示:

PCA
采用2维PCA降维可见其三种不同数据之间有明显的分界,因此分类效果会很好
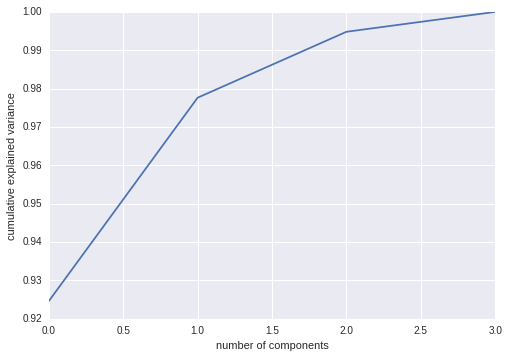
从能量图中可以看到2维已经占到接近98%了。
训练
对于该数据,我们考虑如下几种模型,寻找其最佳模型。
KNN
求解模型得
(0.97999999999999998,KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',metric_params=None, n_jobs=1, n_neighbors=15, p=2,weights='distance'),{'n_neighbors': 15, 'weights': 'distance'})
决策树
求解最佳模型
(0.96666666666666667,DecisionTreeClassifier(class_weight=None, criterion='gini', max_depth=10,max_features=None, max_leaf_nodes=None, min_samples_leaf=3,min_samples_split=2, min_weight_fraction_leaf=0.0,presort=False, random_state=None, splitter='best'),{'criterion': 'gini','max_depth': 10,'min_samples_leaf': 3,'min_samples_split': 2})
逻辑回归
求解模型为
(0.96666666666666667,LogisticRegression(C=5, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,penalty='l2', random_state=None, solver='liblinear', tol=0.0001,verbose=0, warm_start=False),{'C': 5})
SVM
求解模型为
(0.98666666666666669, SVC(C=0.5, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape=None, degree=3, gamma='auto', kernel='linear',max_iter=-1, probability=False, random_state=None, shrinking=True,tol=0.001, verbose=False), {'C': 0.5, 'kernel': 'linear'})
随机森林
求解模型为
(0.96666666666666667,RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',max_depth=None, max_features='auto', max_leaf_nodes=None,min_samples_leaf=1, min_samples_split=2,min_weight_fraction_leaf=0.0, n_estimators=120, n_jobs=1,oob_score=False, random_state=0, verbose=0, warm_start=False),{'n_estimators': 120})
汇总
可见SVM模型是最优的。
| Classifier | Mean Score | Std |
|---|---|---|
| RandomForestClassifier | 0.9667 | 0.0333 |
| LogisticRegression | 0.9667 | 0.0615 |
| KNeighborsClassifier | 0.9800 | 0.0306 |
| SVC | 0.9867 | 0.0267 |
| DecisionTreeClassifier | 0.9667 | 0.0333 |
分析
混淆矩阵
通过混淆矩阵查看发现出问题主要是第2类和第3类。
| 实际\预测 | setosa | versicolor | virginica |
|---|---|---|---|
| setosa | 16 | 0 | 0 |
| versicolor | 0 | 4 | 1 |
| virginica | 0 | 0 | 9 |
代码
GitHub: https://github.com/spiritwiki/codes/blob/master/data_iris
