@spiritnotes
2016-03-08T07:01:40.000000Z
字数 11151
阅读 5501
概率基础
数学
1 计数
分类计数原理(加法原理)
完成一件事,有n类方法,第i类方式中有ni种不同方法,那么完成这件事总共的方法数为
分步计数原理(乘法原理)
完成一件事,需分成n个步骤,做第i步有ni种方法,那么完成这件事的方法数为
有序的重复抽样
如果样本空间总数为n,抽样m次,则总的抽样可能性为
有序的非重复抽样
有序的非重复抽样又叫做排列(permutation)。从数学上来说,从n个样品中挑选m个,放入m个位置,总可能性为
无序的非重复抽样
无序的非重复抽样又叫做组合(combination)
无序的重复抽样
也即是考虑将m次抽样分别放入n个样本空间的组合,允许其大于等于0,也即是相当于找出n-1的间隔将抽样隔开
2 概率公理
实验
任何一个过程,如果它的结果是随机的(无法事前知道),那么该过程就称为一个实验。实验所有可能的结果组成一个集合(set),叫做样本空间(sample space),用Ω表示
事件
在实验中,我们感兴趣的往往不是单个可能,样本空间的一个子集,被称为一个事件(event)
- 补集,事件A的补集包含所有不属于A的样本空间元素
- 两个集合可以有交集和并集运算
- 空集Φ是一个不包含任何元素的集合。如果两个集合的交集为空集,即M∩N=Φ,那么这两个集合不相交。在概率论中,不相交的两个事件互斥。
概率测度
概率测度是基于样本空间ΩΩ的一个函数P。这个函数P定义了从样本空间的子集(即事件)到实数的映射,且满足下面的条件:
- P(Ω)=1P(Ω)=1
- 如果A⊂ΩA⊂Ω, 那么P(A)≥0P(A)≥0
- 如果A1A1和A2A2不相交,那么
3 条件概率
- 定义
- 如果A和B是两个事件,且P(B)≠0。那么B条件下,A的条件概率为
- 推论1
- A和B为两个事件,且P(B)≠0。那么
- 推论2
- 有事件B1,B2,...,Bn。如果⋃Bi=Ω,两个不同事件互斥(Bi∩Bj=Φ,Bi如果i≠j),且任意P(Bi)>0。那么,对于任意事件A
独立事件
两个事件可以是相互独立的 (independent)。直观的讲,如果事件A发生与否不会影响事件B的概率,那么A与B独立。
- 定义
- 两个事件A和B,P(A)≠0,P(B)≠0。如果P(A|B)=P(A),或者P(B|A)=P(B),那么事件A和B是独立事件
根据独立事件和条件概率的定义可以推知,如果P(A∩B)=P(A)P(B),那么A和B独立。独立事件和互斥事件不同。独立事件是指A发生的概率不影响B。对于互斥事件来说,如果A发生,那么B必然不发生,A的发生影响到了B,所以不是独立事件。
贝叶斯法则(Bayes' Rule)
- 贝叶斯法则
- 如果A和B1,B2,...,Bn为事件,Bi互斥,⋃Bi=Ω, 且P(Bi)>0。那么
4 随机变量
随机变量(random variable)的本质是一个函数,是从样本空间的子集到实数的映射,将事件转换成一个数值。根据样本空间中的元素不同(即不同的实验结果),随机变量的值也将随机产生。可以说,随机变量是“数值化”的实验结果。
离散随机变量
某个数字来代表样本空间的某个元素,这个数字并不是概率值。如何对样本空间的元素数值化是根据现实需求的。
P(X=x) 表示了随机变量在不同取值下的概率,称为概率质量函数(PMF, probability mass function)。
累积分布函数
我们可以用累积分布函数(CDF, cumulative distribution function)来表示随机变量的概率分布状况。在累积分布函数,我们列出的,总是随机变量X,在小于x的这个区间的概率和。当x增大时,X < x包含的结果增加,概率和也相应增加。当x为正无穷时,实际上是所有情况的概率和,那么累积分布函数为1。
连续随机变量
随机变量还可以是连续取值,这样的随机变量称为连续随机变量(continuous random variable)。比如,一个随机变量,可以随机的取0到1的任意数值。如时间、温度...
概率密度函数(PDF,probability density function)。粗糙的讲,我们在某个点附近取一个“无穷小”段,该小段的区间长度为dx,而这个“无穷小”段对应的概率为dF,那么该点的概率密度为dF/dx。概率密度函数可以代替累积分布函数,来表示一个连续随机变量的概率分布:
5 离散分布
伯努利分布
伯努利分布(Bernoulli distribution)是很简单的离散分布。在伯努利分布下,随机变量只有两个可能的取值: 1和0。随机变量取值1的概率为p。相应的,随机变量取值0的概率为1-p。
二项分布
进行n次独立测试,每次测试成功的概率为p(相应的,失败的概率为1-p)。这n次测试中的“成功次数”是一个随机变量。这个随机变量符合二项分布(binomial distribution)。二项分布可以从计数的角度来理解。n次测试,如果随机变量为k,意味着其中的k次成功,n-k次失败。从n次实验中挑选k个,根据计数原理,共有C(n,k)种可能。其中的每种可能出现的概率为
泊松分布
泊松分布(Poisson distribution)是二项分布的一种极限情况,当p→0,n→+∞而np=λ时,二项分布趋近于泊松分布。这意味着我们进行无限多次测试,每次成功概率无穷小,但n和p的乘积是一个有限的数值。
λ决定了泊松分布的“重心”所在
几何分布
假设我们连续进行独立测试,直到测试成功。每次测试成功的概率为p。那么,到我们成功时,所进行的测试总数是一个随机变量,可以取值1到正无穷。这样一个随机变量符合几何分布(geometric distribution)。随机变量取值为k时,意味前面的k-1次都失败了。因此,我们可以将几何分布表示成:
负二项分布
几何分布实际上是负二项分布(negative geometric distribution)的一种特殊情况。几何分布是进行独立测试,直到出现成功,测试的总数。负二项分布同样是进行独立测试,但直到出现r次成功,测试的总数k。r=1时,负二项分布实际上就是几何分布。在连续的r次测试时,我们只需要保证最后一次测试是成功的,而之前的k-1次中,有r-1次成功。这r-1次成功的测试,可以任意存在于k-1次测试。因此,负二项分布的表达式为:
6 连续分布
指数分布
指数分布(exponential distribution)的密度函数随着取值的变大而指数减小。指数分布的密度函数为:
指数分布是无记忆(memoryless)的。我们以原子衰变为例。任意时刻往后,都需要10年的时间,会有一半的原子衰变。已经发生的衰变对后面原子衰变的概率分布无影响
正态分布
正态分布(normal distribution)是最常用到的概率分布。正态分布又被称为高斯分布(Gauss distribution),因为高斯在1809年使用该分布来预测星体位置。正态分布的发现来自于对误差的估计。早期的物理学家发现,在测量中,测量值的分布很有特点:靠近平均值时,概率大;远离平均值时,概率小。
正态分布的密度函数如下:
Gamma分布
Gamma分布在统计推断中具有重要地位。它的密度函数如下:
7 联合分布
联合分布(joint distribution)描述了多个随机变量的概率分布,是对单一随机变量的自然拓展。联合分布的多个随机变量都定义在同一个样本空间中。
离散随机变量的联合分布
从一个样本空间,可以同时产生多个映射。比如,我们的实验是连续三次投硬币,样本空间为
- X: 投掷为正面的总数,可以取值0,1,2,3
- Y: 最后一次出现负面的总数,可以取值0,1
- Z: 将正面记为10,负面记为5,第一次与第三次取值的差,可以有5, -5, 0
这三个随机变量可以看作一个有三个分量的矢量。所以定义在同一样本空间的多随机变量,是一个从样本空间到矢量的映射。
对于X=x,Y=y,我们寻找样本空间中满足这两个取值的所有元素。这些元素构成一个样本空间的子集,该子集的概率就是P(X=x,Y=y)的联合概率。p(x,y)=P(X=x,Y=y)称为联合概率质量函数(joint PMF, joint probability mass function)。联合概率可以看做两个事件同时发生时的概率,事件A为X=x,事件B为Y=y,即P(A∩B)。
连续随机变量的联合分布
在单变量情况下,概率是一个“面积”,是由区间的“长度”和密度函数(一条曲线)围成的。这里的“体积”是二维区间的“面积”和密度函数(一个曲面)围成的。我们可以使用联合概率密度函数(joint PDF, joint probability density function)来表达多随机变量的分布。对于双变量的联合分布来说,它等于无穷小块的概率,除以无穷小块的面积。用微积分的语言来说,就是
边缘概率
联合分布包含了多个随机变量的分布信息。我们当然可以从联合分布中,提取出任意一个单一随机变量的分布,也就是所谓的边缘分布(marginal distribution)。对于离散随机变量,可以获得边缘概率质量函数(marginal pmf):
连续随机变量X的边缘密度函数(marginal pdf, marginal probability density function)可以定义为
条件分布
与事件的条件概率类似,假设pY(y)≠0,在Y=y的条件下,随机变量X取值为x的概率定义为:
独立随机变量
正如事件之间可以相互独立一样,随机变量之间也可以相互独立。当X独立于Y时,我们可以相像,Y的取值,将不影响X的概率。也就是说
8 随机变量的函数
通过事件与随机变量的映射,让事件“数值化”,事件的概率值转移到随机变量上,获得随机变量的概率分布。我们使用随机变量的函数,来定制新的随机变量。随机变量的函数是从旧有的随机变量到一个新随机变量的映射。通过函数的映射功能,原有随机变量对应新的随机变量。通过原有随机变量的概率分布,我们可以获知新随机变量的概率分布。
获得新概率分布的基本方法
如果有函数关系Y=g(X1,X2,...,Xn),获得Y分布的基本方法是:
- 通过Y=g(X1,X2,...,Xn),找到对应{Y≤y}的(x1,x2,...,xn)区间I
- 在区间I上,积分f(x1,x2,...,xn),获得P(Y≤y)
- 通过微分,获得密度函数
单变量函数的通用公式
对于单变量函数来说,如果Y=g(X),g是一个可微并且单调变化的函数(在该条件,存在反函数,使得。那么我们可以使用下面的通用公式,来获得Y的分布:
多变量函数的通用公式
如果U=g1(X,Y),V=g2(X,Y),且存在反变换,使得
9 期望
描述量
描述随机变量最完备的方法是写出该随机变量的概率分布。统计学家也设计了这样的投影系统,将全面的概率分布信息量投射到某几个量上,来代表随机变量的主要特征,从而掌握该随机变量的主要“性能”。这样的一些量称为随机变量的描述量(descriptor)。比如期望用于表示分布的中心位置,方差用于表示分布的分散程度等等。这些描述量可以迅速的传递其概率分布的一些主要信息,允许我们在深入研究之前,先对其特征有一个大概了解。
期望
期望(expectation)是概率分布的一个经典描述量,它有很深的现实根源。在生活中,我们往往对未知事件有一个预期,也就是我们的期望。
在概率论中,我们更加定量的对未知结果进行预估。根据概率分布,我们以概率值为权重,加权平均所有可能的取值,来获得了该随机变量的期望(expectation):
基于相似的道理,可以用下面的积分公式,计算连续随机变量的期望:
正态分布的期望
指数分布的期望
期望的性质
- 性质1
- 如果Y=g(X),那么当X为离散随即变量,且∑|g(x)|p(x)<∞ (该条件保证下面的累加为有限值)当X为连续随机变量,且(该条件保证下面的积分为有限值)
- 性质2
- Y=g(X1,X2,...,Xn)。如果Xi是离散的,且有分布p(x1,...,xn),那么当时,有如果Xi是连续的,且有分布f(x1,...,xn),那么当时,有
- 性质3
- 如果X和Y是独立随机变量,而g和h是两个函数,如果E[g(X)],E[h(Y)]存在,那么有当gh为直接返回函数时,可容易推出如果X和Y独立,那么
- 性质4
- 如果,而Xi的期望为E(Xi),那么这说明,期望是一个线性运算。随机变量线性组合的期望,等于期望的线性组合。
条件期望
条件期望将期望用于条件概率。我们已经知道,条件概率是事件B条件下,A的概率,即P(A|B)。条件概率只不过是在一个缩小了的样本空间B上,重新计算A的概率。条件概率的A与B可以是随机变量,比如P(X|Y=y),即“随机变量Y等于y”是条件,在该条件下,随机变量X的随机分布。(在连续随机变量的情况下,我们使用条件密度函数f(x|Y=y)来描述条件分布)
对于一个已知的分布,我们可以求得条件分布的期望。对于离散随机变量:
一个随机变量的期望为一个数值。但一个条件分布的期望,比如E(X|Y=y),会随着随机变量Y的变化而变化。所以,条件期望是随机变量Y的函数。根据随机变量的函数的概念,E(X|Y=y)可以看作一个新的随机变量。我们可以进一步得到这一新的随机变量的期望E(E(X|Y))。
10 方差与标准差
方差就是分布的离散程度。方差越大,说明随机变量取值越离散。
方差
对于一个随机变量X来说,它的方差为:
方差的平方根称为标准差(standard deviation, 简写std)。我们常用σ表示标准差
- 正态分布的方差
- 可以算出正态分布方差为
正态分布的标准差正等于正态分布中的参数σ。这正是我们使用字母σ来表示标准差的原因! - 指数分布的方差
- 指数分布的方差为
Chebyshev不等式
标准差(和方差)表示分布的离散程度。标准差越大,随机变量取值偏离平均值的可能性越大。可以计算一个随机变量与期望偏离超过某个量的可能性。比如偏离超过2个标准差的可能性。即
无论μ和σ如何取值,对于正态分布来说,偏离期望超过两个标准差的概率都相同,约等于0.0455 (可以根据正态分布的表达式计算).
Chebyshev不等式让我们摆脱了对分布类型的依赖。对于任意随机变量X,如果它的期望为μ,方差为σ2,那么对于任意t>0,
11 协方差与相关系数
协方差
协方差(covariance)表达了两个随机变量的协同变化关系。
- 协方差的定义
- 如果X和Y是联合分布的随机变量,且分别有期望μX,μY,那么X和Y的协方差为
根据期望的性质,我们可以改写协方差的表达形式:
当X和Y独立时,有E(XY)=E(X)E(Y),Cov(X,Y)=0。(注意,Cov(X,Y)=0并不意味着X和Y独立)
相关系数
正的协方差表达了正相关性,负的协方差表达了负相关性。对于同样的两个随机变量来说,计算出的协方差越大,相关性越强。
相关系数(correlation coefficient)。相关系数是“归一化”的协方差。它的定义如下:
双变量正态分布
双变量正态分布是一种常见的联合分布。它描述了两个随机变量X1和X2的概率分布。概率密度的表达式如下:
12 矩与矩生成函数
斜度
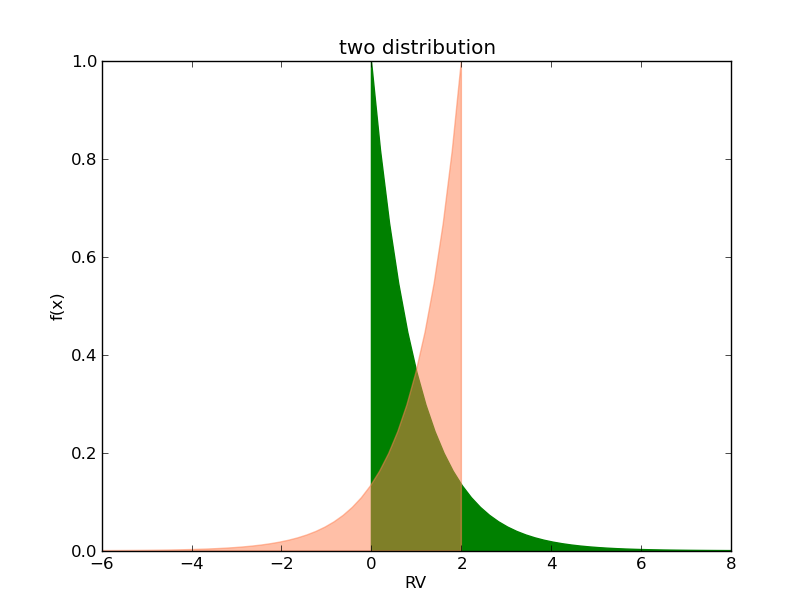
如该图中,两个期望和方差均一样。引入一个新的描述量,斜度(skewness)
矩
方差和斜度都可以归为“矩”(moment)的一族描述量。类似于方差和斜度这样的,它们都是(X−μ)乘方的期望,称为中心矩(central moment)。
原点矩(moment about the origin),是X乘方的期望。
期望是一阶原点矩:
矩生成函数
幂级数(power series)。幂级数是不同阶数的乘方(比如的加权总和:
将解析函数分解为幂级数的过程,就是泰勒分解(Taylor)
将幂级数的x看作随机变量X,并求期望。根据期望可以线性相加的特征,有:
另一方面,我们可否通过解析函数来获得矩呢?我们观察下面一个指数函数,写成幂级数的形式:
矩生成函数的性质
矩生成函数的另一面,是它的指数函数的解析形式。即
- 性质1
- 如果X的矩生成函数为,且,且,那么
(将Y写成指数形式的期望,很容易证明该结论) - 性质2
- 如果X和Y是独立随机变量,分别有矩生成函数MX,MY。那么对于随机变量Z=X+Y,有(基于独立随机变量乘积的期望,等于随机变量期望的乘积)
13 中心极限定律
中心极限定律(central limit theorem)
随机变量X1,X2,...,Xn是相互独立的随机变量,并有相同的分布(IID, independent and identically distributed)。分布的期望为μ,方差为σ^2,μ,σ都为有限值,且σ≠0。这些随机变量的均值为。让,那么
简单来说,我们寻找n个IID随机变量的均值。当n趋进无穷时,这个均值(一个新的随机变量)趋近一个正态分布。
证明
假设Xi−μ的矩生成函数为M(t)。因此,。
当n趋近无穷时,趋近0。M(t)可以展开为:
当n趋近于无穷时,上面的表达式趋近:
