@spiritnotes
2016-05-12T02:59:21.000000Z
字数 1539
阅读 3102
博文阅读:如何使用机器学习解决实际问题-以关键词相关性模型为例
博文笔记
原文:http://semocean.com/如何使用机器学习解决实际问题-以关键词相关性模/
机器学习任务的基本流程
- 目标设定
- 训练数据准备
- 特征选择以及筛选
- 模型训练以及优化
该模型可扩展到语意相关性模型,搜索引擎相关性及LTR学习任务的设计实现。该模型的设计调研实现,也可以很容易移植解决其他包括语义相关性的问题
目标设定:提升关键词搜索相关性
百度关键词搜索推荐系统为广告主在搜索关键词的时候显示推荐其他相关关键词,来源可能为其他广告主\搜索关键词\系统发现。
典型搜索问题:输入query,触发,排序
目标是让用户觉得该产品结果很靠谱, 所以该处我们仅考虑字面相关性,更多的语意扩展该模型并未考虑,可加入更多语意特征,例如plsa的bm25特征和word2vec的相似度特征(或者和扩展的相关性校验,例如将待推荐词扩展为baidu搜索结果的摘要扩展)提高语义特征的贡献。排序需要考虑相关性和CTR。
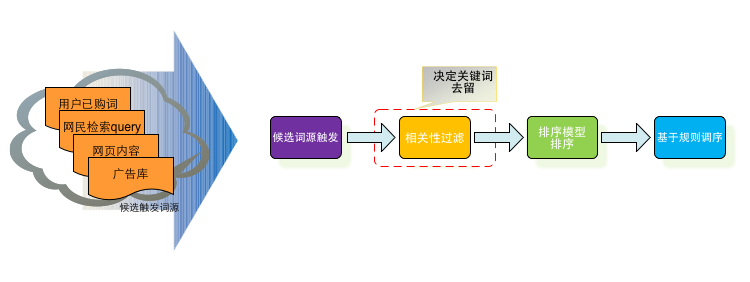
准备训练数据
训练数据的获取一般有几种方式:
- 人工标注: 优点是质量较高,噪音较少;缺点是标注结果和标注者本身的认识相关,例如在搜索引擎中,判定苹果和手机的相关性,对于年轻人,一般都认为相关;但对于比较多的老人,可能认为不相关;另外一个缺点就是人工获取标注的成本较高
- 从日志中进行挖掘:优点是数据量相对更大,获取成本较低(编写几个hadoop脚本对日志进行统计);缺点是噪音较多,例如搜索引擎中的恶意抓取访问导致的噪音数据
采用人工标注,发现负例个性化较强(相关性高,但用户不做该业务),并重新标注。
特征提取
一般特征的选择及处理会极大地影响学习任务的效果,而进行特征选择的时候,一般是先增加特征,并实验效果。 对于相关性模型, 我们可以先将传统的信息检索的特征加上,这些特征一般分为以下几类:
- query/候选词的一般结构特征: 例如query/候选词长度,term数等
- query-候选词的相关性度量:例如TF-IDF, bm25, LMIR及多重变种, plsa相似度度量,word2vec语意向量相似度等; 很多时候,关键词自身信息较少,还可以使用关键词在搜索引擎上的摘要扩展进行相似度度量
- 关键词自身在信息检索维度的重要性度量,例如关键词idf, 从语言模型方面的重要度等
采取样本数据,用随机森林进行二分类:

可使用树模型,就是直接砍掉特征贡献程度及特征重要性较低的特征
特征贡献度
使用树模型时,可以直接使用数节点特征贡献度和节点使用次数,判断是否需要去除该特征,以下为使用树模型进行选择特征的例子:
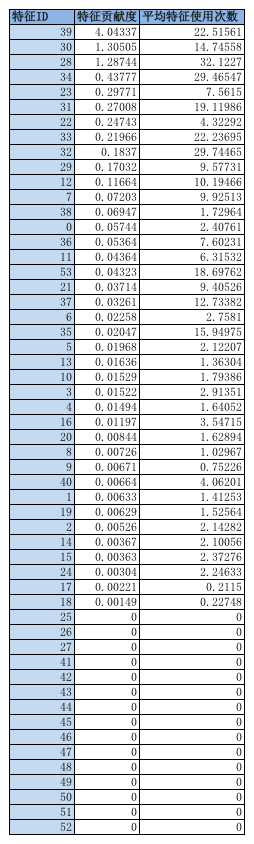
在选择特征的时候, 有一些经验值得分享:
- bm25特征及term weight特征对分类任务有极大贡献
一些单独的比值类特征并没有太大贡献,例如query,推荐词共同term与query term数,推荐词term数的比值,这些特征并没有太大贡献,但是这些特征与query,推荐词的term数结合到一起,贡献就非常多;所以有些特征需要联合在一起,才有较大作用。 - 特征选择需要和目标一致:例如word2vec是非常高大上,且非常靠谱的技术,但用在字面相关性,对目标并没有太大贡献(如果目标是语意相关,那么类似于PLSA,word2vec将会有很大贡献)
- 有些特征就就是用来解决特殊case的,虽然贡献不大,但需要保留(当然也可以直接设置为强规则与模型配合),例如query与推荐词拼音一致
模型选择
经典模型:adaboost
集成树模型:不需要特征归一化,模型自己会根据信息增益,或是基尼系数等标准选择最合适的拆分点进行树节点的拆分,考虑到准确率和速度,最终确定的参数是树的数量是20, 特征选择因子和样本选择因子均为0.65(每棵树随机选择0.65的样本和特征进行训练)
