@spiritnotes
2016-03-14T11:43:46.000000Z
字数 5753
阅读 2844
机器学习实践 -- 短信分类
机器学习实践
数据
总共含有23734条记录,其中各类别的总数分别是 {'1': 10896, '5': 5215, '2': 4882, '4': 1930, '6': 653, '3': 158}
以下是各类别的示例:
cls 1沁园春 . 房: 婚期将到,痴男怨女,有钱别墅,没钱窝居。 望北京上海,高楼大厦; 售楼中心,房奴滔滔赵江你知道我是谁吗?我一直给你打电话你为什么不接?在火车上你说的让我到铁矿给你找活儿,现在已经找到了,可是你又不接电话。我叫屈永文。接最后就是答案.你没看完吗? 第一声是.宝贝.第二就猜不到了.请赐教.cls 2信誉贷款公司与银行合作,向本市企业及个人提供无抵押低息小额贷款,审核资料真实有效当天可放款15083608058王经理,XXXX公司可为个人及企业提供贷 款;无抵 押,好借好还,保密性高,月3%!请电13824676750张经理或刘先生!,智能GPS卡,可用于同时监*听4-5个电话,拦截信息及位置,是你商业和婚外情的好帮手,先试好,货到后付 款 电13981861837高经理cls 3尊敬的用户:您的积 分奖 品已经送 出,请拨12 5 905063并按2键领 取,48小时内有 效。客服:010-96 0 9688O,尊敬的用户您好!根据10月话费/额度调查,您将会获得50元话/费奖励机会,请拨打1259042981按5键听5分钟马上领取。,尊 敬的用 户:您2009年10月份的积 分奖 品尚未领 取,请拨I259O7612按 2键领 取(48小时内有效)咨 询95105526cls 4他的唇谁的唇吗你现在只属于我一个人的包抱你的心你的唇你的小妹妹也只能我的小弟弟进去,老公舔阴道时也需要用手撸开小米的阴毛的。小米快分开腿给老公,你个婊子,骂我家里人,没有素质,我从来没有骂过你家里的人,你做的不要脸的是,小心你女儿被人强奸,糟万人玩。个婊子,怎么当初和老子做爱时"cls 5闽通泉厦的士调度现已开通泉州至厦门往返的士专线,承接拼车,包车等业务,上门接送。乘车专线0595-28953688-13599923233集的场所。天气较冷,及时加衣,哥弟专卖店/毛利股??申购限额:1万股??发行市盈:50.96倍??2、海大集团(深:002311)??发行价:28元??发行量:5600万股??申购cls 6新年到吉星照,听我真言得福报,方法简单又明了,褪t队团党是绝招,心中铭记真z善s忍,全家安康神佛保,大f法d弟子送方舟,救d度众生为你好大陆被柏林墙禁固。此墙维护假恶暴,伟光正谎言一堂。快退共产党免天灾。此信息如阳光,把真S善S忍及法轮D大F法的美好照到你心上,伴你平安吉祥
目标
分类
简单分词 + SVM
class MessageCountVectorizer(sklearn.feature_extraction.text.CountVectorizer):def build_analyzer(self):def analyzer(doc):words = pseg.cut(doc)new_doc = ''.join(w.word for w in words if w.flag != 'x')words = jieba.cut(new_doc)return wordsreturn analyzervec_count = MessageCountVectorizer(min_df=2,max_df=0.8)data_count = vec_count.fit_transform(content)vec_count.get_feature_names()print(data_count.shape)
结果如下共有 (23734, 21959) 组数据。
频度分析
vec_count = MessageCountVectorizer(min_df=2,max_df=0.99)data_count = vec_count.fit_transform(content)>>> (23734, 21959)
以小尺度2,大尺度0.99, 共产生21959个词语,形成了对应的新向量。
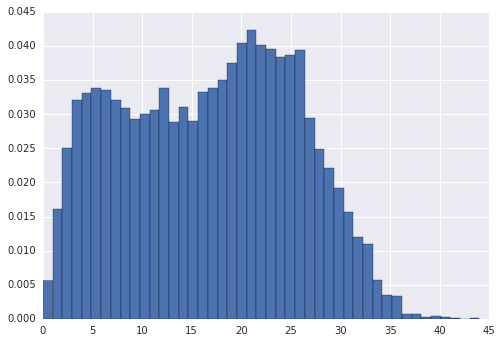
查看每条短信分词后的长度分布,如下图,大部分分词结果位于5到28之间。
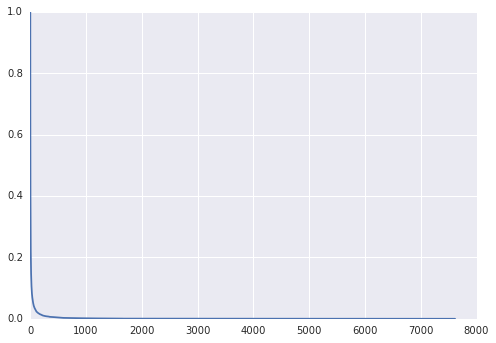
通过对单词在所有短信中的出现次数看,我们做出特征出现次数与出现次数大于等于该次的特征数目占总特征个数的比例,2的比例为1,随着次数增加比例依次减少。
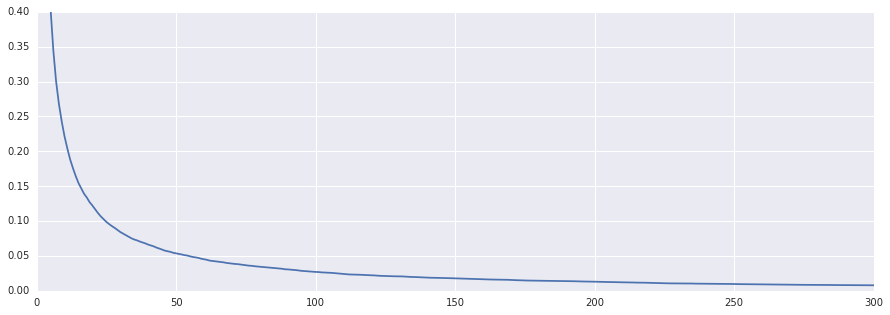
可以看到出现次数超过20次的特征仅占特征总数的10%。
SVM寻找最佳参数
采用SVM使用CV=10进行linear分类得:
| min_df | max_df | 特性向量个数 | 最佳正确率 | 最佳参数 |
|---|---|---|---|---|
| 2 | 0.8 | 21959 | 0.9609 | 0.5 |
| 5 | 0.8 | 8895 | 0.9608 | 0.5 |
| 10 | 0.8 | 4869 | 0.9576 | 0.1 |
| 50 | 0.8 | 1179 | 0.9428 | 0.5 |
分类别查看准确率
分别查看几种情况下随机10次的各分类错误率
mindf = 2
| class | 3 | 2 | 6 | 1 | 4 | 5 |
|---|---|---|---|---|---|---|
| max | 0.7647 | 0.9696 | 0.9362 | 0.9963 | 0.9245 | 0.9713 |
| min | 0.5789 | 0.9531 | 0.7619 | 0.9857 | 0.8557 | 0.9421 |
| mean | 0.6878 | 0.9624 | 0.8616 | 0.9923 | 0.9004 | 0.9541 |
mindf = 5
| class | 6 | 3 | 5 | 4 | 2 | 1 |
|---|---|---|---|---|---|---|
| max | 0.9362 | 0.8095 | 0.9679 | 0.9245 | 0.9729 | 0.9945 |
| min | 0.7778 | 0.5789 | 0.9403 | 0.8458 | 0.9440 | 0.9857 |
| mean | 0.8648 | 0.6938 | 0.9545 | 0.8993 | 0.9612 | 0.9900 |
mindf = 10
| class | 4 | 5 | 3 | 6 | 1 | 2 |
|---|---|---|---|---|---|---|
| max | 0.9096 | 0.9699 | 0.7647 | 0.9149 | 0.9953 | 0.9615 |
| min | 0.8159 | 0.9521 | 0.5455 | 0.7302 | 0.9857 | 0.9449 |
| mean | 0.8789 | 0.9621 | 0.6537 | 0.8097 | 0.9915 | 0.9567 |
mindf = 50
| class | 1 | 3 | 6 | 5 | 2 | 4 |
|---|---|---|---|---|---|---|
| max | 0.9925 | 0.8095 | 0.8333 | 0.9499 | 0.9574 | 0.9096 |
| min | 0.9777 | 0.5263 | 0.7018 | 0.9112 | 0.9351 | 0.7662 |
| mean | 0.9851 | 0.6718 | 0.7754 | 0.9365 | 0.9467 | 0.8510 |
| min df\class | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 2 | 0.9923 | 0.9624 | 0.6878 | 0.9004 | 0.9541 | 0.8616 |
| 5 | 0.9900 | 0.9612 | 0.6938 | 0.8993 | 0.9545 | 0.8648 |
| 10 | 0.9915 | 0.9567 | 0.6537 | 0.8789 | 0.9621 | 0.8097 |
| 50 | 0.9851 | 0.9467 | 0.6718 | 0.8510 | 0.9365 | 0.7754 |
从结果可以看到特征越多,准确率越高。而分类别的结果是类别3、类别4、类别6的准确率较低。
TFIDF + SVM
TFIDF分词器
#直接采用TFID生成对应的class MessageTfidfVectorizer(sklearn.feature_extraction.text.TfidfVectorizer):def build_analyzer(self):#analyzer = super(TfidfVectorizer, self).build_analyzer()def analyzer(doc):words = pseg.cut(doc)new_doc = ''.join(w.word for w in words if w.flag != 'x')words = jieba.cut(new_doc)return wordsreturn analyzervec_tfidf = MessageTfidfVectorizer(min_df=2,max_df=0.8)data_tfidf = vec.fit_transform(content)
寻找参数
采用min_df在[2,5,10,50],其结果如下:
| min_df | max_df | 特性向量个数 | 最佳正确率 | 最佳参数C |
|---|---|---|---|---|
| 2 | 0.8 | 21959 | 0.9629 | 2 |
| 5 | 0.8 | 8895 | 0.9622 | 2 |
| 10 | 0.8 | 4869 | 0.9595 | 3 |
| 50 | 0.8 | 1179 | 0.9438 | 2 |
其结果稍好于简单的分词器,但是其参数为2,C值越大对正错的分错就越严格。
TFIDF + SVM
使用SVM准确度如下:
[mean: 0.95816, std: 0.01185, params: {'kernel': 'linear'},mean: 0.45909, std: 0.00020, params: {'kernel': 'rbf'}](0.95816128760428076, SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape=None, degree=3, gamma='auto', kernel='linear',max_iter=-1, probability=False, random_state=None, shrinking=True,tol=0.001, verbose=False), {'kernel': 'linear'})
混淆矩阵如下:
[[2118 7 0 8 8 4]
[ 16 943 0 0 34 0]
[ 4 4 21 0 8 0]
[ 48 0 0 346 13 0]
[ 13 10 0 0 1016 0]
[ 22 0 0 0 4 100]]
计算其准确度为:
pre = clf.predict(Xtest)for i in '123456':print('score for class', i, ':', np.logical_and(pre==i, ytest==i).sum()/ (ytest==i).sum())score for class 1 : 0.987412587413score for class 2 : 0.949647532729score for class 3 : 0.567567567568score for class 4 : 0.850122850123score for class 5 : 0.977863330125score for class 6 : 0.793650793651
多次测试求其平均值可得:
| 类别 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| max | 0.9944 | 0.9663 | 0.7333 | 0.8867 | 0.9779 | 0.8872 |
| min | 0.9837 | 0.9496 | 0.4545 | 0.8371 | 0.9626 | 0.7937 |
| mean | 0.9879 | 0.9569 | 0.5866 | 0.8619 | 0.9713 | 0.8388 |
可以看到其中类别3、4、6的准确率较低。
特征优化
针对特征进行分析:
- 类似特征 '....': 直接去掉后再分词
- 电话号码 ‘13699759265’: 创建一个新的特征,其定义为数字的个数,必须要后处理,产生15维后,长于该数默认为15维之上
- 浮点数 ‘1.22’: 创建一个新的特征,是否含有浮点数形式的字串
- 英文字母:连续的英文字母提取出来作为特征
- 英文字母与中文交杂:
- 英文字母与数字交杂:
- 繁体字
- 拆分字
繁体字
在现实生活中肯定有用户使用繁体字,因此在进行处理的时候可以考虑在进行处理之前先进行繁体字的替换,对当前短信的处理结果如下,可以看到其中有几个问题
{('來', '来'),...('堆', '栈'), --------('太', '酞'), --------...('霉', '酶'), ------('黃', '黄')}
- 繁体字表中有错误,需要将错误去掉
- 从替换出来的繁体字可以看到其对结果影响很小
拆分字
通过对样本空间进行分析,找到了不少拆分字
{('女免', '娩'),...('禾兑', '税')}
连续数字转变为维度
采用正则表达式,取出连续的数字,依次按照其维度分别赋值,共设置16个维度,1~15以及15以上。对于日常短信来说,许多垃圾短信是含有电话号码之类的,如果只以实际的电话作为维度,则遇到不同的电话号码,不能识别,因此设置该维度
### 将连续的数字转变为长度的维度def process_cont_numbers(content):digits_features = np.zeros((len(content),16))import refor i,line in enumerate(content):for digits in re.findall(r'\d+', line):length = len(digits)if 0 < length <= 15:digits_features[i, length-1] += 1elif length > 15:digits_features[i, 15] += 1return digits_features
SVM 训练结果
对短信进行繁体体转换然后再拆分字处理后,TFIDF分词后与数字长度矩阵合并后SVM训练,其结果如下:
| C | kernel | best | std |
|---|---|---|---|
| 0.1000 | linear | 0.8901 | 0.0237 |
| 0.5000 | linear | 0.9504 | 0.0144 |
| 0.7500 | linear | 0.9577 | 0.0124 |
| 1 | linear | 0.9609 | 0.0115 |
| 2 | linear | 0.9655 | 0.0100 |
| 3 | linear | 0.9655 | 0.0102 |
| 5 | linear | 0.9646 | 0.0103 |
| 10 | linear | 0.9632 | 0.0103 |
| 30 | linear | 0.9624 | 0.0105 |
以C为2进行10次随机看一下各分类准确率:
| class | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Count+SVM mean | 0.9923 | 0.9624 | 0.6878 | 0.9004 | 0.9541 | 0.8616 |
| TFIDF+SVM mean | 0.9879 | 0.9569 | 0.5866 | 0.8619 | 0.9713 | 0.8388 |
| CURR mean | 0.9922 | 0.9665 | 0.7097 | 0.8953 | 0.9714 | 0.8751 |
子类专项调整
由于第3类样本空间数比较少,只有158,那么是不是由于样本空间数不够的问题导致的呢?因此对第3类产生去一验证法,看一下样本空间足够的情况下的准确率。
其准确率只有63%。看一下分错的短信,发现分错的信息基本上都是SP的广告或者运营商的营销广告,其本身特性不较明显。
代码以及ipython路径
github:https://github.com/spiritwiki/codes/tree/master/messageclassifieranalysis
coding.net:https://coding.net/u/spiritwiki/p/codes/git/tree/master/messageclassifieranalysis
